NodeJS深度探秘:通过爬虫用例展示callback hell的处理方法以及高并发编程的几个有效模式
Posted tyler_download
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了NodeJS深度探秘:通过爬虫用例展示callback hell的处理方法以及高并发编程的几个有效模式相关的知识,希望对你有一定的参考价值。
高并发和异步模式往往需要支持一种机制,那就是消息模式。当某个情况发送或是某种状态改变时,系统需要通知所有关注者,让他们及时进行处理,于是系统就会发送一个特定消息,所有监听该消息的对象在信号发出后,他们的处理函数会得到相应的调用,这种做法也是典型的观察者模式,消息机制在NodeJS程序设计中有着非常重要且广泛的作用。
NodeJS专门设计了一个类EventEmmiter来处理消息的传播和处理,它的基本结构如下图:
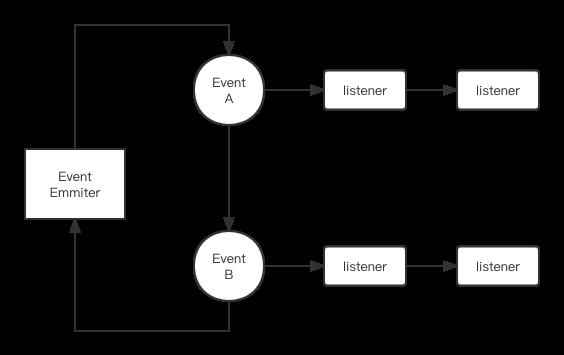
EventEmitter导出的几个接口值得关注,一个是on(event, listener),该接口用于注册一个对给定事件或信号进行相应的处理接口,第二个是once(event, listener), 它与前者区别在于,第二个接口注册的处理接口只要响应过一次给定事件就会被删除,也就是说如果event产生第二次时,通过once注册的接口将不会被调用,而通过on接口注册的对象只要给定事件产生了,他就会被调用。第三个需要关注的接口是emmit(event),它用来发送一个特定事件,最后一个是removeListener(event, listener),它用来删除监听特定事件的特定处理对象,我们通过一个给定例子来理解Event Emitter的使用。
首先在本地目录创建两个文件1.txt, 2.txt,其内容为hello world!和hello my friend。然后创建文件index.mjs,其代码内容如下:
import EventEmitter from 'events'
import readFile from 'fs'
let findRegex = (files, regex) =>
const emitter = new EventEmitter()
for (let file of files)
readFile(file, 'utf8', (err, content) =>
if (err)
return emitter.emit('error', err)
emitter.emit('fileread', file)
const match = content.match(regex)
if (match)
match.forEach(elem => emitter.emit('found', file, elem))
)
return emitter
findRegex(['1.txt', '2.txt'], /hello \\w+/g)
.on('fileread', file=> console.log(`$file was read\\n`))
.on('found', (file, match) => console.log('found ' , match, 'in file: ', file, "\\n"))
.on('error', err => console.log('error : ', err.message))
程序的基本逻辑是将文件名传入findRegex函数,然后给定要查找的正则表达式。findRegex函数读取文件内容,然后使用给定的正则表达式在读取的内容中进行匹配,如果查找到匹配则发布事件found,最后它返回emitter对象。
拿到emitter对象后我们分别监听它发出的fileread, found, error三个事件,一旦对应事件发生时则调用我们提供的函数,注意到on函数调用后会再返回emitter对象,于是我们能使用串链的方式来进行连续调用,上面代码运行后所得结果如下:
1.txt was read
found hello world in file: 1.txt
2.txt was read
found hello my in file: 2.txt
这里有一点需要注意,如果emit出的是错误,也就是error,如果错误对应的事件没有对应响应函数的话,整个程序就会自动退出。
使用event emitter 一个问题在于容易导致内存泄露,如果我们使用on来注册一个事件响应函数,但是如果某个事件不再需要处理后,我们忘记使用RemoveListner将其删除,那么响应函数所使用的内存就不会得到释放。一般情况下如果某个事件对应的响应函数超过了10个,NodeJS就会通知我们有可能产生内存泄露。
接下来我们看看异步控制流的设计模式。异步执行的代码非常容易出错,而且不好理解和调试。因为它的执行顺序有可能是随机的,你很难判断哪个函数先执行。另外我们通常使用回调来相应异步处理结果,这有可能造成深层次的回调嵌套,造成所谓的callback hell。为了更鲜明的展示这个问题,我们看一个具体例子:网页爬虫。首先使用如下命令安装需要使用的包:
npm install --save superagent
npm install --save mkdirp
npm install --save slug
npm i cherrio
我们先介绍一些上面模块的基本用处,首先是slug,它是一个特定称谓,用来指url中说明页面内容的字符串,这些字符串的特点是单词之间使用"-"连接,例如:
https://www.kindacode.com/article/how-to-generate-slugs-from-titles-in-node-js
其中”how-to-generate-slugs-from-titles-in-node-js“就叫slug.上面所用到的包slug作用就是把含有空格的字符串转换成用"-"连接的形式,当然它支持很多其他操作,例如去掉一些不能在文件名中出现的特定字符,例如* , [ ] : ; / \\等,我们看一个例子:
let filename = slug("https://www.baidu.com/this;is[illegal*path]")
console.log(filename)
上面代码输出的结果就是:
httpswwwbaiducomthisisillegalpath
我们要做的是一个简单爬虫,它下载网页后会使用其url作为文件名并将网页内容存储在本地,但url中有可能会包含一些不能出现在文件名中的字符,因此我们需要使用slug处理掉.下面我们看看如何构造网页爬虫,在spider.mjs中写入代码如下:
import fs from 'fs'
import path from 'path'
import superagent from 'superagent'
import mkdirp from 'mkdirp'
import urlToFileName from './util.mjs'
export function spider(url, cb)
const file_name = urlToFileName(url)
console.log("spider file name: ", file_name)
fs.access(file_name, err=>
console.log("fs access err: ", err)
if (err && err.code === 'ENOENT')
//检测给定网页是否已经下载,如果没有则进行下载
console.log(`downloading $url into $file_name`)
superagent.get(url).end((err, res)=>
if (err)
cb(err)
else
//根据网页形成的文件名生成多个层级的文件夹
mkdirp(path.dirname(file_name)).catch(err=>
console.log('mkdirp err: ', err)
cb(err)
).then(p=>
//将网页内容写入给定文件夹
fs.writeFile(file_name, res.text, err=>
if (err)
cb(err)
else
cb(null, file_name, true)
)
)
)
else
cb(null, file_name, false)
)
最后我们创建一个main.js在其中通过读取控制台参数后调用上面导出的函数对给定网页进行下载,main.mjs代码如下:
import spider from "./spider.mjs";
spider(process.argv[2], (err, file_name, downloaded) =>
if (err)
console.log(err)
else if (downloaded)
console.log(`Completed the download of "$file_name"`)
else
console.log(`"$file_name" was already downloaded`)
)
完成上面代码后我们在控制台输入:
node main.mjs https://juicefs.com/docs/zh/community/architecture/
执行后我们可以看到如下输出:
downloading https://juicefs.com/docs/zh/community/architecture/ into juicefs.com/docs/zh/community/architecture.html
Completed the download of "juicefs.com/docs/zh/community/architecture.html"
同时能在当前文件夹下看到下载的文件。纵观上面spider.mjs的代码,我想大家会有一个感觉那就是乱,这种乱其实是因为回调函数的不断嵌套造成的。代码一个特点是我们会调用一个异步函数,然后传入一个回调作为参数,同时在回调中又再次调用异步函数,于是又得在里面再次嵌套回调函数。由于NodeJS的异步加回调特性,代码很容易形成大量回调函数嵌套,这种情况也叫callback hell。由于过分的回调函数嵌套,我们甚至都分不清大括号是如何配对的,因此这种代码不但容易出问题,而且可维护性非常差。
要改进这种大括号嵌套得让人看的头晕的问题有几个有用技巧,第一就是尽可能少用if…else,将其改成:
if (err)
return cb(err)
//处理正常情况
可以看到去掉else我们就少了一个大括号对。第二种改进方法是将具有“工具属性”的代码块拿出来单独形成一个辅助函数,例如在上面代码中,网页下载和写入本地文件是两个具有“工具属性”的代码,他们与业务逻辑没有强联系因此可以分别单独拿出来自成一格工具函数,于是我们就可以在util.mjs里面添加两个函数分别为download何saveFile,于是uitls.mjs修改如下:
function saveFile(file_name, contents, cb)
mkdirp(path.dirname(file_name)).catch(err=>
return cb(err)
).then(p =>
writeFile(file_name, contents, cb)
)
export function download(url, file_name, cb)
console.log(`downloading $url`)
superagent.get(url).end((err, res) =>
if (err)
return cb(err)
saveFile(file_name, res.text, err =>
if (err)
return cb(err)
console.log(`Downloaded and saved: $url`)
cb(null, res.text)
)
)
然后修改spider.mjs如下:
import urlToFileName, download from './util.mjs'
import fs from 'fs'
export function spider(url, cb)
const file_name = urlToFileName(url)
fs.access(file_name, err=>
if (!err || err.code !== 'ENOENT')
//对应文件路径已经存在
return cb(null, file_name, false)
download(url, file_name, err=>
if (err)
return cb(err)
cb(null, file_name, true)
)
)
从代码看到可读性是不是改进巨大!
目前我们的爬虫功能太简单,它仅仅下载了给定链接的网页,我们需要它能分析下载网页所包含的内部链接,然后再使用异步模式去进行下载。如果给定网页包含一百个链接,那么我们需要分发出一百个异步任务进行异步并发下载。所以基本做法是,先把用户输入链接对应网页下载到本地,然后分析网页内容获得网页包含的所有链接并把它们放到一个数组中,然后遍历数组分别下载数组中链接对应的网页。这里我们还需注意一个问题,如果我们下载了网页1,通过它的内部链接下载网页2,然后用通过网页2的内部链接下载网页3,如此循环下去会很容易撑爆我们的硬盘,因此要注意防范抓爬的深度不能过大。
我们看看改进爬虫的实现,首先是修改spider函数如下:
import urlToFileName, download , getPageLinks from './util.mjs'
import fs from 'fs'
export function spider(url, nesting, cb)
//nesting用来决定抓爬的深度
const file_name = urlToFileName(url)
fs.readFile(file_name, 'utf8', (err, content)=>
if (err)
if (err.code !== 'ENOENT')
//文件读取错误而且错误不是文件已存在,那么直接返回
return cb(err)
//url对应网页没有下载过,则下载
return download(url, file_name, (err, content)=>
if (err)
return cb(err)
//读取下载网页,取出包含的链接做下一步抓爬
spiderLinks(url, content, nesting, cb)
)
//如果网页已经下载过,那么读取网页内容取出内部链接进行下载
spiderLinks(url, content, nesting, cb)
)
function spiderLinks(current_url, body, nesting, cb)
if(nesting === 0)
/*
已经达到给定深度,不能继续往下抓爬,注意这里要使用nextTick实现异步执行回调函数
不然我们会出现zalgo问题
*/
return process.nextTick(cb)
//解析页面包含的所有链接并放入数组links
const links = getPageLinks(current_url, body)
if (links.length === 0)
//没有内部链接可供抓爬
return process.nextTick(cb)
function iterate(index)
if (index === links.length)
//这里没有用nextTick来异步执行回调,是因为iterate函数是在异步回调函数中被执行的
return cb()
//使用spider函数抓爬给定连接的网页
spider(links[index], nesting - 1, function(err)
if (err)
return cb(err)
//遍历网页内部链接,然后执行异步抓爬
iterate(index + 1)
)
iterate(0)
然后修改util.js添加辅助函数:
function getLinkUrl(current_url, element)
//抓取的内部链接对应域名要与当前网页域名一样,这样才能保证抓取的是内部链接
const parsedLink = new URL(element.attribs.href || '', current_url)
const currentParsedUrl = new URL(current_url)
if (parsedLink.hostname !== currentParsedUrl.hostname ||
!parsedLink.pathname)
return null
return parsedLink.toString()
export function getPageLinks(current_url, body)
/*
使用cheerio解析html获得所有链接对象
*/
return Array.from(cheerio.load(body)('a'))
.map(element =>
return getLinkUrl(current_url, element)
)
.filter(Boolean)
最后修改main.mjs:
import spider from "./spider.mjs";
const url = process.argv[2]
const nesting = Number.parseInt(process.argv[3], 10) || 1
spider(url, nesting, (err) =>
if (err)
console.error(err)
process.exit(1)
console.log('Download complete')
)
完成上面代码后,在命令行启动程序时,第三个参数就是抓爬的深度。在执行上面代码时切记要尽快使用ctrl+c结束程序,原因在于爬虫会给被抓取的网站带来流量压力,其次爬虫程序在我国具有不合法性,我们这里只是使用它进行技术探讨而已。
上面代码有一点非常值得注意,那就是iterate函数的实现方式,它通过递归的方式遍历数组,取得数组元素后将其交给一个异步执行函数,这个模式叫顺序执行的异步并发。为了更好的理解这个设计模式,我们看一个非常简单的例子:
let numbers = [1, 2, 3, 4, 5, 6]
let final_callback = ()=>
console.log("numbers are over")
let visit_callback = (number, index, cb)=>
console.log("visit number: ", number)
cb(index+1)
let iterate = (index)=>
if (index >= numbers.length)
//这里千万不用忘了使用return
return process.nextTick(final_callback)
process.nextTick(visit_callback, numbers[index], index, iterate)
iterate(0)
上面代码使用异步模式顺序的读取数组中每个元素,同学们可以仔细品味一下。在这个模式中每个元素(或者说是任务)虽然被异步读取,但元素被读取的顺序却是给定的,所以才叫异步顺序并发,如果我们将元素的读取分配到多个cpu核上同时执行,那么就形成了并行异步模式,我们可以修改一下上面例子:
let numbers = [1, 2, 3, 4, 5, 6]
let visit_callback = (number ,index)=>
console.log("visit number: ", number)
let iterate = ()=>
numbers.forEach(number =>
process.nextTick(visit_callback, number)
)
iterate()
你可能会有疑问,不是说NodeJS是单线程模式吗。事实上我们自己写的代码,例如回调函数等都会在主线程中执行,但是异步任务可以利用操作系统的多核多线程模式来实现平行执行,假设我们要读取10个文件,那么我们可以使用上面forEach的方式启动readFile,nodejs会把读取文件的请求提交给操作系统,操作系统会把读取请求分发给多个内核,于是文件读取就可以在不同cpu内核上同时运行,当文件内容读取完毕后,nodejs再使用它的主线程将读取到的内容分别提交给我们提供的回调函数,我们用一个图来表示上面两个模式的特点:
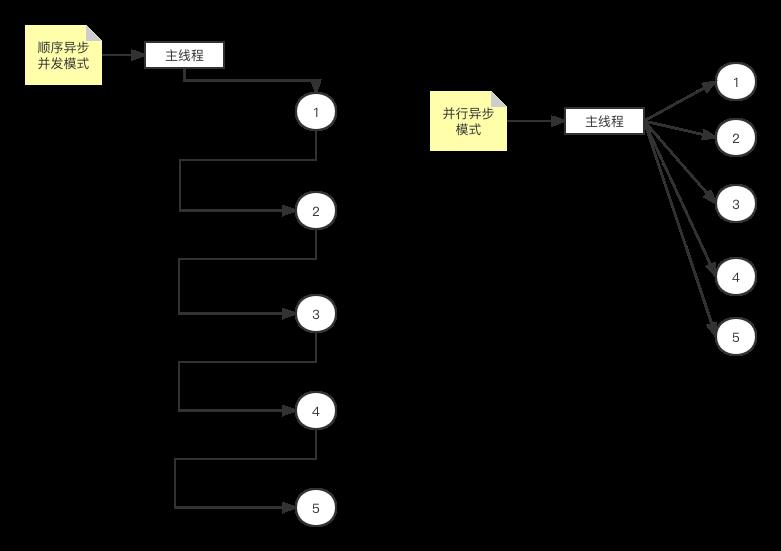
我们可以推测,第二种模式处理任务的速度上会比第一种快,因为它能让多个任务同时进行,而第一种模式其实是完成一个任务后再进行第二个,因此本质上还是顺序执行,只不过它防止了任务过多而阻塞主线程。但第二个模式也有问题,假设我们不是简单的打印数字而是打开文件,如果程序以第二种模式同时打开上千个文件,那么就会耗尽进程的文件句柄上限而导致奔溃,因此在使用第二种模式时,我们需要现在并行任务的数量。
因此我们把第二种模式修改一下,限制代码同时只能同时执行5个任务:
let numbers = []
let init =()=>
for (let i = 0; i < 20; i++)
numbers.push(i)
init()
const cocurrency = 5 //同时运行的任务数量
let running = 0
let completed = 0
let index = 0
let print_number = (number)=>
console.log(number)
let finish = ()=>
console.log('all numbers read')
let next =()=>
while (running < cocurrency && index <= numbers.length)
/*
我们每次都在主线程中对资源进行操作,所以不用加锁
*/
let number = numbers[index++]
process.nextTick(()=> //分发多个能同时运行的任务
if (completed++ === numbers.length)
return finish()
print_number(number) //执行任务
running-- //完成任务后将当前正在运行的任务数减一
next()
)
running++
next()
最后我们结合上面所说的知识点,创建一个任务队列模式,从而完成一个最终改进版的爬虫。首先我们先创建任务队列的代码,添加文件task_queue.mjs,其内容如下:
export class TaskQueue
constructor(concurrency)
//将允许同时并发执行的任务放入队列
this.concurrency = concurrency
this.running = 0
this.queue = []
pushTask = (task)=>
//将要运行的任务压入队列,并发时任务从队列中获取
this.queue.push(task)
process.nextTick(this.next)
return this
next = ()=>
/*
如果当前并发执行的任务小于设定值,那么从队列中取出任务进行执行
*/
while (this.running < this.concurrency && this.queue.length)
const task = this.queue.shift()
task(()=>
this.running--
process.nextTick(this.next)
)
this.running++
在上面代码中,我们把要执行的任务加入队列,next函数负责将任务从队列中取出并执行。它在取出队列时,首先检测当前有多少个任务正在执行,如果并发执行的任务数没有超出限制,那么就取出给定数量的任务进行执行。上面代码模式比较明了,但还有不足的就是没有及时的通知调用者任务的运行状态,例如有多少个任务结束了,有哪个任务执行出错了,相关信息要及时发送给调用者进行处理。为了满足任务运行状态传达的需求,我们借助前面讲过的EventEmittr,将任务状态以消息的方式分发出去,调用者只要监听相应消息就能及时获取任务的处理状态,因此修改如下:
import EventEmitter from 'events'
export class TaskQueue extends EventEmitter
constructor(concurrency)
//将允许同时并发执行的任务放入队列
this.concurrency = concurrency
this.running = 0
this.queue = []
pushTask = (task)=>
//将要运行的任务压入队列,并发时任务从队列中获取
this.queue.push(task)
process.nextTick(this.next)
return this
next = ()=>
if (this.running === 0 && this.queue.length === 0)
//通知调用者所有任务执行完毕
return this.emit('empty')
/*
如果当前并发执行的任务小于设定值,那么从队列中取出任务进行执行
*/
while (this.running < this.concurrency && this.queue.length)
const task = this.queue.shift()
task((err)=>
if (err)
//通知调用者任务执行出错
this.emit('error', err)
this.running--
process.nextTick(this.next)
)
this.running++
上面代码增加了消息机制,一旦任务队列清空,或者是任务运行出错,任务队列都会发出相应消息,调用者只要监听相应消息就能及时进行处理,下面我们看看如何实现要执行的任务,在spider.mjs中添加代码如下:
import urlToFileName, download , getPageLinks from './util.mjs'
import fs from 'fs'
//增加一个queue参数
export function spiderTask(url, nesting, queue, cb)
//nesting用来决定抓爬的深度
const file_name = urlToFileName(url)
fs.readFile(file_name, 'utf8', (err, content)=>
if (err)
if (err.code !== 'ENOENT')
//文件读取错误而且错误不是文件已存在,那么直接返回
return cb(err)
//url对应网页没有下载过,则下载
return download(url, file_name, (err, content)=>
if (err)
return cb(err)
//读取下载网页,取出包含的链接做下一步抓爬
//增加一个queue参数
spiderLinks(url, content, nesting, cb, queue)
)
//如果网页已经下载过,那么读取网页内容取出内部链接进行下载
spiderLinks(url, content, nesting, cb)
)
//增加一个queue参数
function spiderLinks(current_url, body, nesting, cb, queue)
if(nesting === 0)
/*
已经达到给定深度,不能继续往下抓爬,注意这里要使用nextTick实现异步执行回调函数
不然我们会出现zalgo问题
*/
return process.nextTick(cb)
//解析页面包含的所有链接并放入数组links
const links = getPageLinks(current_url, body)
if (links.length === 0)
//没有内部链接可供抓爬
return process.nextTick(cb)
//将抓爬到的链接作为要执行的任务加入到队列
links.forEach(link => spider(link, nesting - 1, queue))
/*
将被抓爬的链接缓存起来,当有新链接需要抓爬时,先从缓存里查看,如果链接已经抓爬过
那么忽略链接,如果链接没有在缓存中则进行抓爬
*/
const spidering = new Set()
export function spider(url , nesting, queue)
if (spidering.has(url))
return //链接已经抓爬过
spidering.add(url)
queue.pushTask((done) =>
spiderTask(url, nesting, queue, done)
)
上面代码中,spider函数负责抓爬给定url,它首先检测给定链接是否已经在缓存中,如果是,那么链接已经被抓爬过于是就忽略它,如果不是,那么就启动一个抓爬任务,也就是spiderTask,该函数负责将网页抓取并存储成本地文件。
spiderTask将网页下载到本地后,分析其中的html内容,获取内部链接并将他们存储到一个数组中,然后使用forEach遍历数组中每个链接,调用spider函数再去抓爬给定连接,最后我们看main.mjs的实现:
import spider from "./spider.mjs";
import TaskQueue from "./task_queue.mjs";
const url = process.argv[2]
const nesting = Number.parseInt(process.argv[3], 10) || 1
const concurrency = Number.parseInt(process.argv[4], 10) || 2
const spiderQueue = new TaskQueue(concurrency)
spiderQueue.on('error', console.error)
spiderQueue.on('empty', ()=>console.log('Donwnload complete'))
spider(url, nesting, spiderQueue)
上面代码从控制台获取首个要抓爬的链接,同时获得并发数和链接抓爬深度。接下来创建任务队列,然后监听队列发出的相应消息,最后调用spider函数抓爬用户给定的链接,当我们把代码运行起来后,代码会快速抓爬给定网站网页,我们要迅速ctrl+c结束程序,要不然会给目标网站带来不必要的流量压力。
更多干货
代码下载:链接: https://pan.baidu.com/s/157WLY63_Qwux7Zd-EQlaIQ 提取码: lgfa
以上是关于NodeJS深度探秘:通过爬虫用例展示callback hell的处理方法以及高并发编程的几个有效模式的主要内容,如果未能解决你的问题,请参考以下文章
Nodejs深度探秘:event loop的本质和异步代码中的Zalgo问题
Nodejs深度探秘:event loop的本质和异步代码中的Zalgo问题