CVPR 2022 部分行人重识别
Posted 等待破茧
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了CVPR 2022 部分行人重识别相关的知识,希望对你有一定的参考价值。
转载自CVPR 2022【行人/车辆重识别】相关论文和代码(更新中...) - 知乎
Person Re-identification
1. Learning with Twin Noisy Labels for Visible-Infrared Person Re-Identification
2. Part-based Pseudo Label Refinement for Unsupervised Person Re-identification
3. Camera-Conditioned Stable Feature Generation for Isolated Camera Supervised Person Re-IDentification
4. Large-Scale Pre-training for Person Re-identification with Noisy Labels
5. Cloning Outfits from Real-World Images to 3D Characters for Generalizable Person Re-Identification
6. Clothes-Changing Person Re-identification with RGB Modality Only
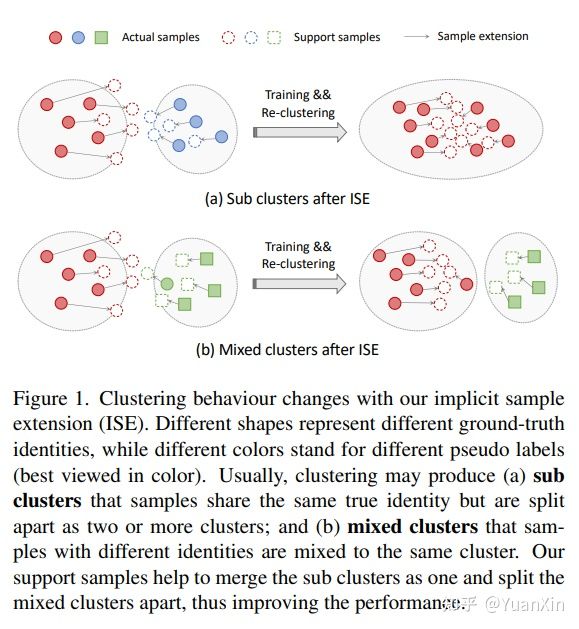
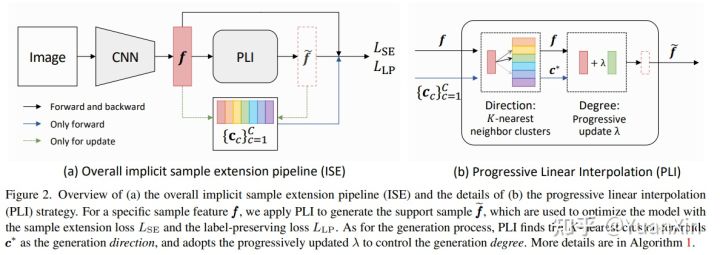
7. Implicit Sample Extension for Unsupervised Person Re-Identification
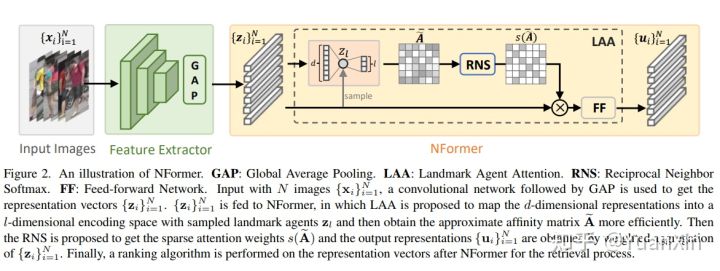
8. NFormer: Robust Person Re-identification with Neighbor Transformer
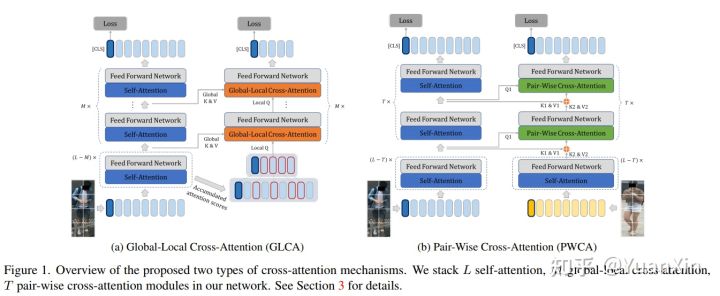
9. Dual Cross-Attention Learning for Fine-Grained Visual Categorization and Object Re-Identification
10. Graph Sampling Based Deep Metric Learning for Generalizable Person Re-Identification
11. Lifelong Unsupervised Domain Adaptive Person Re-identification with Coordinated Anti-forgetting and Adaptation
12. Feature Erasing and Diffusion Network for Occluded Person Re-Identification
Person Search
1. Cascade Transformers for End-to-End Person Search
2. PSTR: End-to-End One-Step Person Search With Transformers
Person Re-identification
1. Learning with Twin Noisy Labels for Visible-Infrared Person Re-Identification
作者:M. Yang, Z. Huang, P. Hu, T. Li, J. Lv, X. Peng
背景:给定行人的可见光(或红外)相机照片,跨模态行人重识别(VI-ReID)旨在从数据库匹配出该行人的红外(或可见光)照片。一个流行的VI-ReID范式是利用行人标注提高不同行人间判别性,同时构建跨模态正负样本对并进行跨模态学习以缩减模态间鸿沟。由于红外模态下的识别度较差,行人训练数据中将不可避免地存在一些噪声标注(Noisy Annotation,NA)。我们发现,这些NA将进一步导致所构建的跨模态正负样本呈现噪声关联(Noisy Correspondence,NC [1-2])。换言之,跨可见光-红外行人重标识任务将面临孪生噪声标签(Twin Noisy Labels,TNL)挑战。针对该挑战,论文[3]提出了一种新的鲁棒VI-ReID方法,名为双重鲁棒训练器(DuAlly Robust Training,DART),其首先利用神经网络的记忆效用来计算标注的置信度。基于置信度,DART将跨模态正负样本分为不同子集并进一步校正其中的关联。最后,DART利用所设计的双重鲁棒损失函数来实现对孪生噪声标签鲁棒的跨模态行人重识别。需要说明的是,过去多年,针对分类任务中“噪声标注”问题(Learning with Noisy Labels)已有许多卓有成效的解决方案。然而,过去多年的大多研究主要针对单模态的图像分类任务,忽视了跨模态任务中潜在的错误关联问题(Learning with Noisy Correspondence)[1-2],更没有实际需求出发,对噪声标注伴生噪声关联的孪生噪声标签现象的揭示和研究。
创新:一方面,本论文在国际上率先揭示了跨模态Re-ID学习中存在但一直被忽略的一个问题——孪生噪声标签学习。其与噪声标签存在以下显著区别:简要地,与传统的噪声标注不同,孪生噪声标签指的是训练数据中同时存在单一样本的标注错误和成对数据的关联错误。另一方面,为解决孪生噪声标签问题,该文提出了一种新的鲁棒学习方法,即双重鲁棒训练(DART)。DART的一个主要创新点是,利用所估计的标注置信度将样本对自适应地划分为四个不同子集并校正其中的关联,从而实现鲁棒的跨模态行人重识别。DART在跨模态行人重识别的两个数据集上进行了大量实验,较为充分验证了提出方法在对孪生噪声标签的鲁棒性。
方法:具体地,针对标签含噪的可见光输入数据和红外光输入数据,通常将不同模态下同一行人(即相同标签)的样本作为正样本对,不同行人(即不同标签)的样本作为负样本对。然而,由于标签含噪,所以正、负样本对中可能分别存在假阳性和假阴性样本对,即错误关联。为处理含噪标签及其所导致的错误关联,得到鲁棒的跨模态行人重识别模型,如图1所示,利用互学习(Co-teaching)思想,本文分别训练两个相同结构但不同初始化的神经网络,通过模型预热、样本置信度建模、样本对划分及关联修正,和双重鲁棒训练五个阶段的建模和训练得到两个鲁棒的神经网络模型,融合两个模型得到最终模型,并用于跨模态行人重识别。
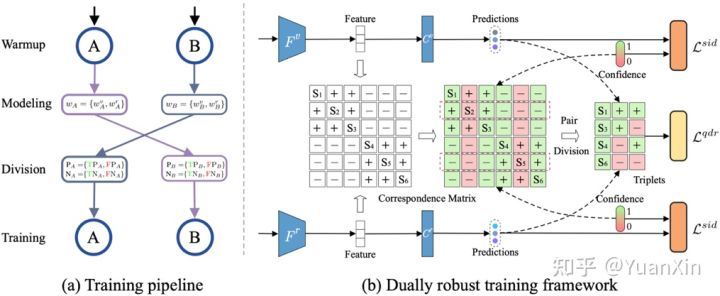
图1. 训练流程和模型架构
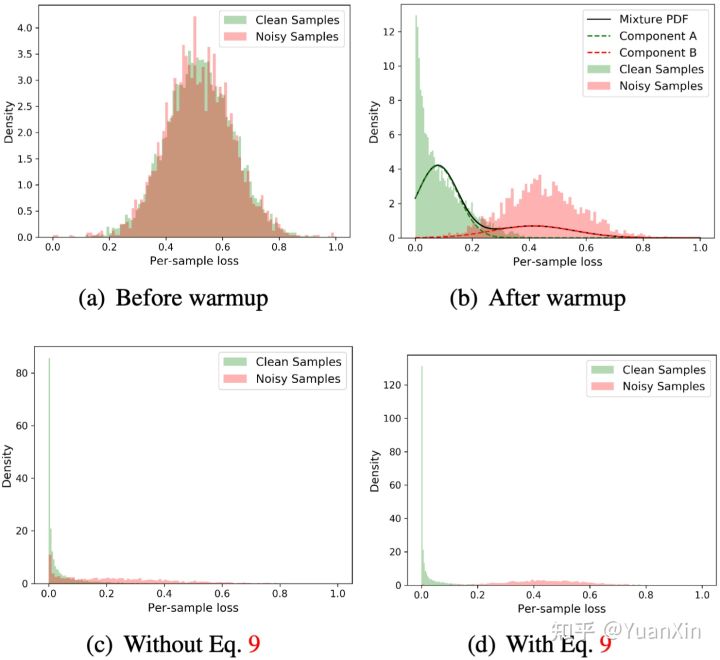
1. 模型预热阶段:使用行人重识别中常用的交叉熵损失函数进行模型的初始训练。
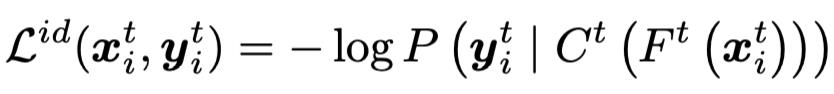
具体地,该步骤基于神经网络的记忆效应,即神经网络在拟合复杂的噪声样本之前倾向于优先拟合简单的干净数据样本。利用该效应,在初始的第1个epoch利用上述loss进行模型训练,可得到每个样本的损失值。
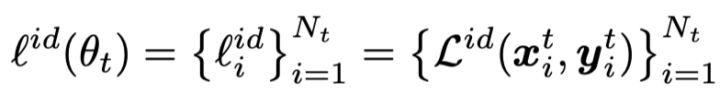
2. 样本置信度建模:利用一个二成分的高斯混合模型(GMM),对模型预热后得到的所有训练数据的样本损失函数值进行拟合。
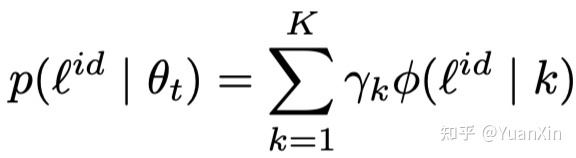
为优化GMM,采用了期望最大化算法(EM)。基于记忆效应。将均值较低(即损失较小)的成分作为干净数据集,另一个作为噪声数据集集,同时将每个样本属于较小成分的后验概率作为第i个样本的干净置信度,计算如下:
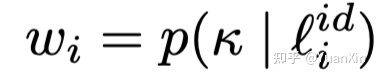
3. 样本对划分及关联修正:对于构成的跨模态样本对,DART通过设置一阈值(实验中固定为0.5),将它们划分成如下干净和噪声集合:
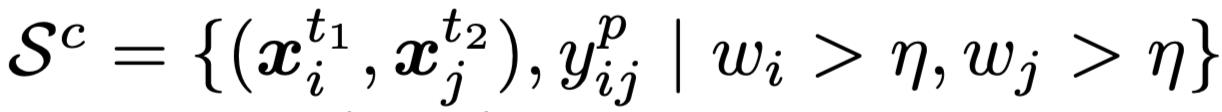
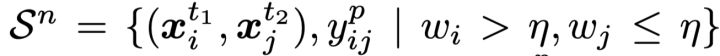
使用如下操作修正样本对的关联:
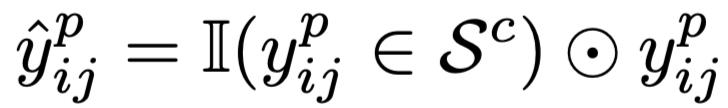
进一步地,使用如下操作召回可能误判的假阴性样本对:
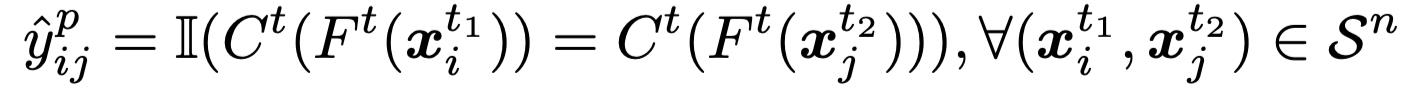
4. 双重鲁棒训练:使用如下的损失函数进行训练
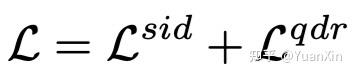
其中,
是针对噪声标注的损失函数,其主要利用所估计的样本标注置信度进行惩罚:
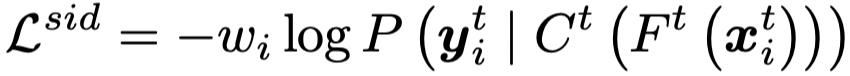
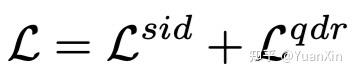
是针对噪声关联的损失函数,其实一个新的自适应四元组损失:
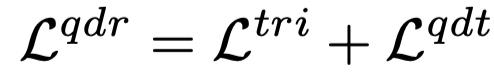
其中
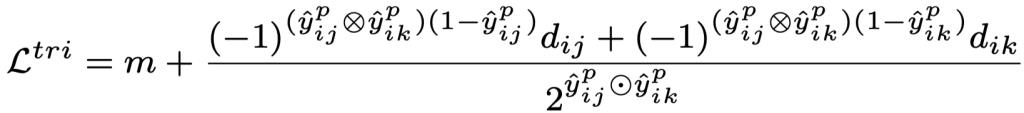

针对可能存在的样本对组合,真阳性-真阴性(TP-TN),真阳性-假阴性(TP-FN),假阳性-真阴性(FP-TN),假阳性-假阴性(FP-FN),
将会分别自适应地(如图2所示)变成以下形式:
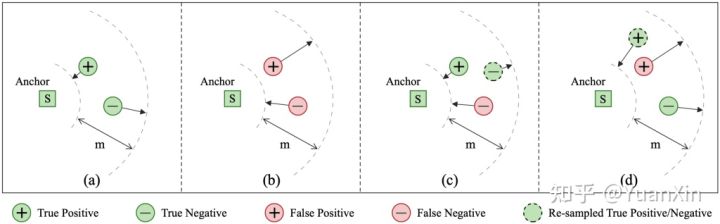
TP-TN:

FP-FN:
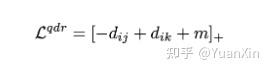
TP-FN:
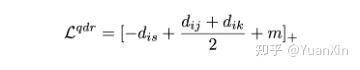
FP-TN:
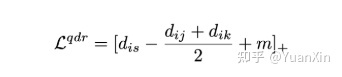
重复步骤2-4直至网络收敛,即可得到鲁棒的跨模态行人重识别模型。
实验:本文在VI-ReID的两个数据集上进行了实验,包括:SYSU-MM01和RegDB。为验证DART的鲁棒性和有效性,论文分别在噪声率为0%,20%和50%下和包括ADP在内的目前SOTA方法进行对比。由于目前跨模态行人重识别方法无法标签含噪数据,为保证公平性,对比方法中包含了ADP-C,其抛弃了含噪数据,只在干净数据上训练。以下展示部分实验结果,更多结果和分析详见原文。
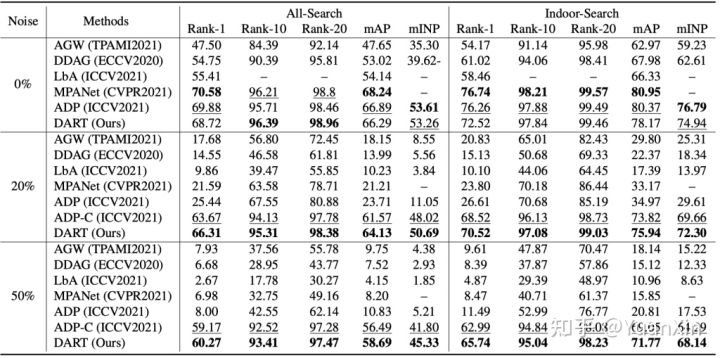
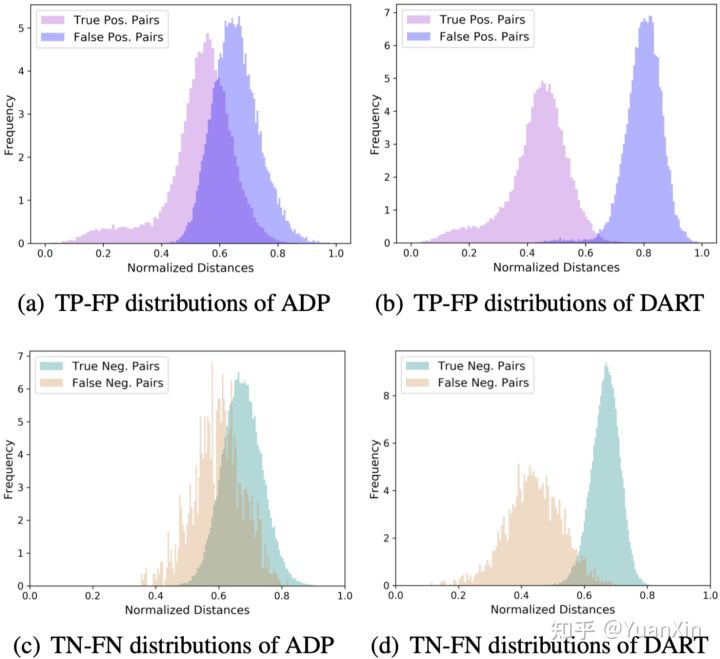
总结:本文是彭玺教授CVPR2021工作[1]和NeurIPS2021 Oral工作[2]的深入延续。[1]通过探索了对比学习中的假阴性(False Negative)样本对问题,在国际上以对比学习为背景,初步揭示了数据错配和样本对错误关联现象,并构造了一个鲁棒的损失函数,赋予对比学习对假阴性样本的鲁棒性。[2]以跨模态匹配任务为背景,基于对真实数据集(Conceptual Captions)的观察,揭示了假阳性(False Positive)的错误配对现象,首次正式提出了噪声关联学习的概念和方向,并给出了解决方案。而本文则以跨模态行人重识别任务为应用,揭露了噪声标注和其带来的噪声关联,即孪生噪声标签问题(Twin Noisy Labels)对跨模态行人重标识任务中的影响。
Reference:https://cs.scu.edu.cn/info/1246/16829.htm
2. Part-based Pseudo Label Refinement for Unsupervised Person Re-identification
作者:Yoonki Cho, Woo Jae Kim, Seunghoon Hong, Sung-Eui Yoon
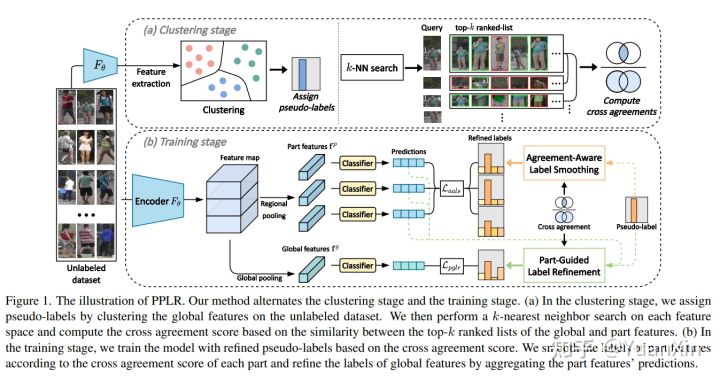
摘要:无监督行人重识别(re-ID)旨在学习识别表征,从无标签数据中检索行人。最近的技术通过使用伪标签来完成这个任务,但是这些标签本身就有噪声,并且降低了准确性。为了克服这一问题,提出了几种伪标签细化方法,但它们忽略了对行人重识别至关重要的细粒度局部上下文。本文提出了一种基于局部特征的伪标签细化(PPLR)框架,该框架利用局部特征与局部特征之间的互补关系来降低标签噪声。具体来说,我们设计了一个交叉协议得分作为特征空间之间k近邻的相似度,以利用可靠的互补关系。在交叉协议的基础上,通过对局部特征的预测进行集成,提炼出全局特征的伪标签,共同缓解了全局特征聚类的噪声。根据给定标签对每个零件的适用性,应用标签平滑进一步细化零件特征的伪标签。由于交叉协议得分提供了可靠的互补信息,我们的PPLR有效地减少了噪声标签的影响,并学习了具有丰富局部上下文的区别表示。在Market-1501和MSMT17上的大量实验结果证明了该方法的有效性。
代码:https://github.com/yoonkicho/PPLR
arXiv:https://arxiv.org/abs/2203.14675
3. Camera-Conditioned Stable Feature Generation for Isolated Camera Supervised Person Re-IDentification
作者:Chao Wu, Wenhang Ge, Ancong Wu, Xiaobin Chang
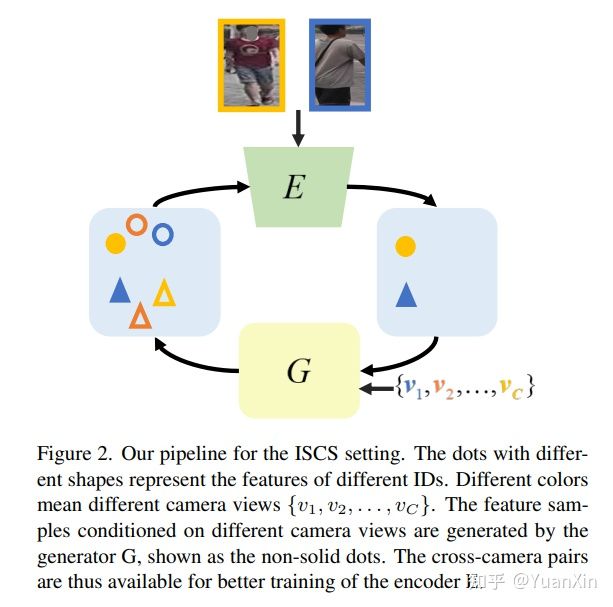
摘要:为了学习行人重识别(Re-ID)的相机视角不变的特征,每个人的跨相机图像对发挥了重要作用。然而,在孤立相机监督(ISCS)环境下,例如在遥远的场景中部署的监控系统,这种跨视角的训练样本可能是不可用的。为了处理这个具有挑战性的问题,我们引入了一个新的管道,在特征空间中合成跨摄像头的样本用于模型训练。具体来说,特征编码器和生成器在一种新的方法下进行端到端的优化,即CameraConditioned Stable Feature Generation(CCSFG)。它的联合学习程序引起了对生成模型训练稳定性的关注。因此,我们提出了一种新的特征生成器--σ-Regularized Conditional Variational Autoencoder(σReg.CVAE),并对其稳健性进行了理论和实验分析。在两个ISCS行人Re-ID数据集上进行的广泛实验证明了我们的CCSFG比竞争对手的优势。

arXiv:Camera-Conditioned Stable Feature Generation for Isolated Camera Supervised Person Re-IDentification
代码:https://github.com/ftd-Wuchao/CCSFG
4. Large-Scale Pre-training for Person Re-identification with Noisy Labels
作者:Dengpan Fu, Dongdong Chen, Hao Yang, Jianmin Bao, Lu Yuan, Lei Zhang, Houqiang Li, Fang Wen, Dong Chen
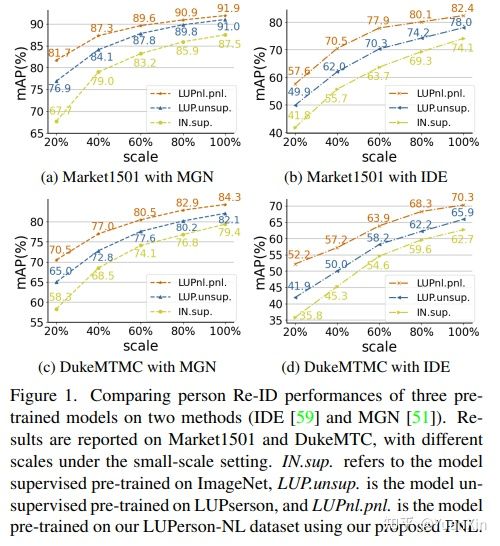
摘要:本文旨在解决有噪声标签的行人重识别(Re-ID)的预训练问题。为了设置预训练任务,我们将一个简单的在线多目标跟踪系统应用于现有的无标签Re-ID数据集 "LUPerson "的原始视频,并建立称为 "LUPerson-NL "的噪声标签变量。由于这些从追踪器中自动得出的ID标签不可避免地包含噪声,我们开发了一个利用噪声标签的大规模预训练框架(PNL),它由三个学习模块组成:有监督的Re-ID学习、基于原型的对比学习和标签引导的对比学习。原则上,这三个模块的联合学习不仅可以将相似的例子聚集到一个原型上,还可以根据原型的分配来纠正噪声标签。我们证明,直接从原始视频中学习是一种有希望的预训练的替代方法,它利用空间和时间的相关性作为弱监督。这个简单的预训练任务为在 "LUPerson-NL "上从头开始学习SOTA的Re-ID表征提供了一种可扩展的方法,而不需要花哨的东西。例如,通过在相同的监督Re-ID方法MGN上的应用,我们的预训练模型在CUHK03、DukeMTMC和MSMT17上的mAP比无监督的预训练对应物分别提高了5.7%、2.2%、2.3%。在小规模或少量拍摄的情况下,性能的提高甚至更加明显,这表明所学到的表征有更好的可迁移性。
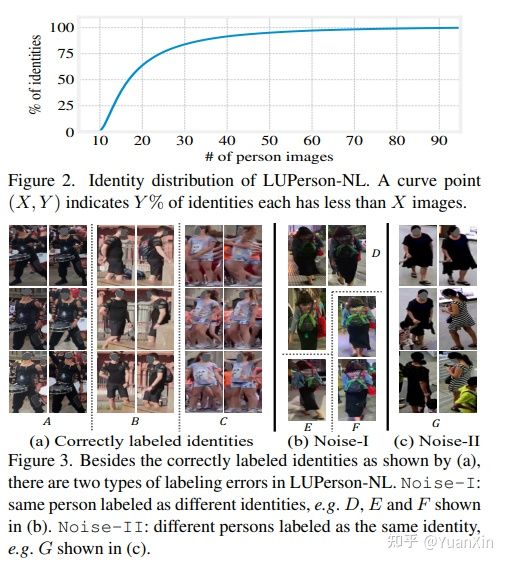
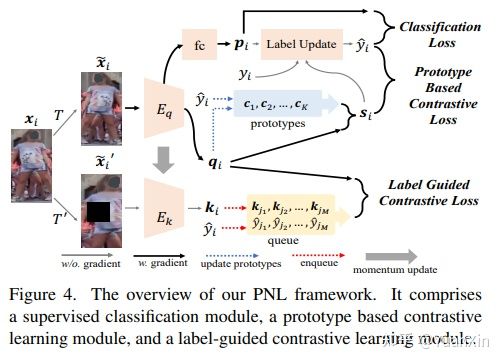
arXiv:Large-Scale Pre-training for Person Re-identification with Noisy Labels
代码:https://github.com/DengpanFu/LUPerson-NL
5. Cloning Outfits from Real-World Images to 3D Characters for Generalizable Person Re-Identification
作者:Yanan Wang, Xuezhi Liang, Shengcai Liao
摘要:最近,大规模的合成数据集被证明对泛化行人重识别非常有用。然而,现有数据集中的合成人物大多是卡通式的,并且是随机的服装搭配,这限制了它们的性能。为了解决这个问题,在这项工作中,我们提出了一种自动方法,直接将真实世界的人物图像中的整个服装克隆到虚拟的三维人物中,这样,任何由此产生的虚拟人物都会显得与真实世界的对应物非常相似。具体来说,基于UV纹理映射,我们设计了两种克隆方法,即注册衣服映射和同质布扩展。考虑到在人物图像上检测到的衣服关键点,并在具有清晰衣服结构的常规UV图上进行标注,注册制图应用透视同源法将真实世界的衣服扭曲成UV图上的对应物。对于不可见的衣服部分和不规则的UV图,同质扩展将衣服上的同质区域分割成一个现实的布纹或单元,并扩展单元以填充UV图。此外,还提出了一种相似性-多样性扩展策略,通过对人物图像进行聚类,对每个聚类的图像进行采样,并克隆服装以生成三维角色。这样一来,虚拟人物可以在视觉相似度上进行密集扩展以挑战模型学习,在人群中进行多样性扩展以丰富样本分布。最后,通过在Unity3D场景中渲染克隆人物,创建了一个更真实的虚拟数据集,称为ClonedPerson,有5,621个身份和887,766张图像。实验结果表明,在ClonedPerson上训练的模型具有更好的泛化性能,优于在其他流行的真实世界和合成行人重识别数据集上训练的模型。
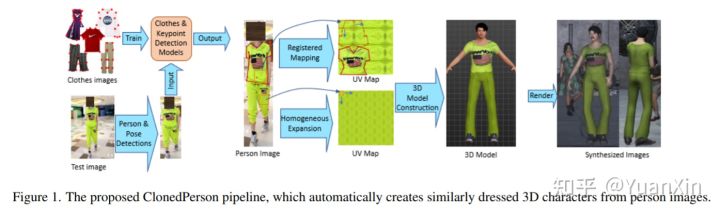
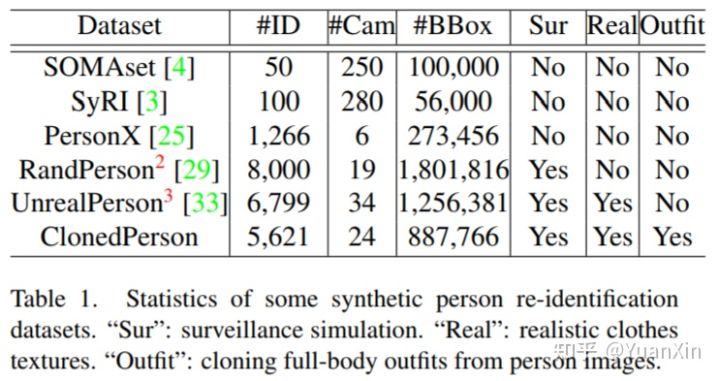

arXiv:Cloning Outfits from Real-World Images to 3D Characters for Generalizable Person Re-Identification
代码:https://github.com/Yanan-Wang-cs/ClonedPerson
6. Clothes-Changing Person Re-identification with RGB Modality Only
作者: Xinqian Gu, Hong Chang, Bingpeng Ma, Shutao Bai, Shiguang Shan, Xilin Chen
摘要:解决换衣行人重识别(re-id)的关键是提取与衣服无关的特征,如脸部、发型、体形和步态。目前大多数工作主要集中在从多模态信息(如剪影和草图)中建模身体形状,但没有充分利用原始RGB图像中与衣服无关的信息。在本文中,我们提出了一种基于衣服的对抗性损失(CAL),通过惩罚re-id模型对衣服的预测能力,从原始RGB图像中挖掘与衣服无关的特征。大量的实验表明,仅使用RGB图像,CAL在广泛使用的换衣人重新识别基准上优于所有先进的方法。此外,与图像相比,视频包含更丰富的外观和额外的时间信息,这些信息可以用来建立适当的时空模式,以帮助换衣服的重新识别。由于没有公开可用的换衣视频重新识别数据集,我们贡献了一个名为CCVID的新数据集,并表明在时空信息建模方面存在很大的改进空间。


arXiv:Clothes-Changing Person Re-identification with RGB Modality Only
代码和数据集:https://github.com/guxinqian/Simple-CCReID
7. Implicit Sample Extension for Unsupervised Person Re-Identification
作者: Xinyu Zhang, Dongdong Li, Zhigang Wang, Jian Wang, Errui Ding, Javen Qinfeng Shi, Zhaoxiang Zhang, Jingdong Wang
摘要:大多数现有的无监督行人重识别(Re-ID)方法使用聚类来生成模型训练的伪标签。不幸的是,聚类有时会把不同的真实身份混在一起,或者把同一身份分成两个或多个子聚类。在这些有噪音的聚类上进行训练会大大影响Re-ID的准确性。由于每个身份的样本有限,我们认为可能缺乏一些潜在的信息来很好地揭示准确的聚类。为了发现这些信息,我们提出了一个隐性样本扩展( \\OurWholeMethod)的方法,在集群边界周围生成我们所说的支持样本。具体来说,我们通过渐进式线性插值(PLI)策略,从实际样本和它们在嵌入空间的相邻集群中生成支持样本。PLI通过两个关键因素来控制生成,即:1)从实际样本到其K-nearest集群的方向;2)混合K-nearest集群的背景信息的程度。同时,给定支持样本,ISE进一步使用标签保全损失将它们拉向其对应的实际样本,从而压缩每个集群。因此,ISE减少了 "子和混合 "聚类误差,从而提高了Re-ID的性能。大量的实验表明,所提出的方法是有效的,并且在无监督的行人重识别方面达到了最先进的性能。
arXiv:Implicit Sample Extension for Unsupervised Person Re-Identification
代码:GitHub - PaddlePaddle/PaddleClas: A treasure chest for visual recognition powered by PaddlePaddle
8. NFormer: Robust Person Re-identification with Neighbor Transformer
作者: Haochen Wang, Jiayi Shen, Yongtuo Liu, Yan Gao, Efstratios Gavves
摘要:行人重识别的目的是在不同的相机和场景中检索高度不同的人,在这种情况下,强大的和有鉴别力的表征学习是至关重要的。大多数研究考虑从单个图像中学习表征,忽略它们之间的任何潜在的相互作用。然而,由于身份内的高度变化,忽略这种互动通常会导致离群的特征。为了解决这个问题,我们提出了一个邻域转换网络,即NFormer,它明确地模拟了所有输入图像之间的相互作用,从而抑制了离群的特征,并导致了整体上更加稳健的表征。由于模拟大量图像之间的相互作用是一项具有大量干扰因素的艰巨任务,NFormer引入了两个新的模块,即地标代理注意力和互为邻里的Softmax。具体来说,地标代理注意力通过对特征空间中少数地标的低秩因子化来有效地模拟图像之间的关系图。此外,互为邻里的Softmax实现了对相关邻里--而不是所有邻里--的稀疏关注,这减轻了不相关表征的干扰并进一步减轻了计算负担。在四个大规模数据集的实验中,NFormer取得了新的先进水平。

arXiv:NFormer: Robust Person Re-identification with Neighbor Transformer
代码:https://github.com/haochenheheda/NFormer
9. Dual Cross-Attention Learning for Fine-Grained Visual Categorization and Object Re-Identification
作者: Haowei Zhu, Wenjing Ke, Dong Li, Ji Liu, Lu Tian, Yi Shan
摘要:最近,自注意机制在各种NLP和CV任务中表现出令人印象深刻的性能,它可以帮助捕捉序列特征并得出全局信息。在这项工作中,我们探讨了如何扩展自我注意力模块,以更好地学习微妙的特征嵌入,从而识别细粒度的对象,例如不同的鸟类物种或人的身份。为此,我们提出了一种双交叉注意力学习(DCAL)算法,与自我注意力学习相协调。首先,我们提出全局-局部交叉注意(GLCA),以加强全局图像和局部高反应区域之间的相互作用,这可以帮助加强识别的空间上的判别线索。其次,我们提出成对交叉注意(PWCA)来建立图像对之间的相互作用。PWCA可以通过将另一个图像作为分心物并在推理过程中被移除来规范一个图像的注意力学习。我们观察到,DCAL可以减少误导性的注意力,并分散注意力反应以发现更多的互补部分用于识别。我们对细粒度的视觉分类和目标重新识别进行了广泛的评估。实验表明,DCAL的表现与最先进的方法相当,并持续改善了多个自我注意基线,例如,在MSMT17上分别超过DeiT-Tiny和ViT-Base 2.8%和2.4% mAP。
arXiv:Dual Cross-Attention Learning for Fine-Grained Visual Categorization and Object Re-Identification
10. Graph Sampling Based Deep Metric Learning for Generalizable Person Re-Identification
作者: Shengcai Liao, Ling Shao
摘要:最近的研究表明,明确的深度特征匹配以及大规模和多样化的训练数据都可以显著提高行人重识别的泛化程度。然而,在大规模数据上学习深度匹配器的效率还没有得到充分的研究。虽然用分类参数或类记忆学习是一种流行的方式,但它会产生大量的内存和计算成本。相比之下,在小批量内进行成对的深度匹配器学习将是一个更好的选择。然而,最流行的随机抽样方法,即著名的PK采样器,对于深度度量学习来说并不具有信息量和效率。尽管在线硬例挖掘在一定程度上提高了学习效率,但随机抽样后在mini-batch中的挖掘仍然是有限的。这激发了我们探索在数据采样阶段更早地使用硬例挖掘。为此,在本文中,我们提出了一种高效的小批量抽样方法,称为图抽样(GS),用于大规模深度度量学习。其基本思想是在每个时代的开始为所有的类建立一个最近的邻居关系图。然后,每个小批量由一个随机选择的类和其最近的相邻类组成,以便为学习提供信息量大且具有挑战性的例子。与一个适应性的竞争基线一起,我们大大改善了可推广的人的再识别技术,当在RandPerson上训练时,在MSMT17上的Rank-1上提高了25.1%。此外,所提出的方法也优于竞争基线,在MSMT17上训练时,在CUHK03-NP上排名第一,提高了6.8%。同时,在RandPerson上训练8,000个身份时,训练时间明显减少,从25.4小时减少到2小时。
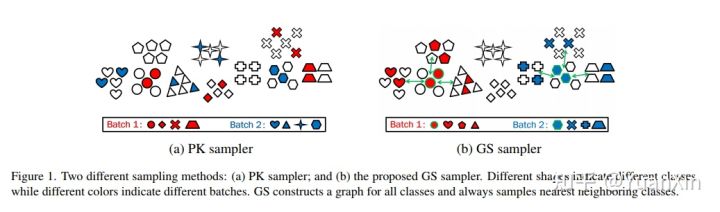
arXiv:Graph Sampling Based Deep Metric Learning for Generalizable Person Re-Identification
代码:https://github.com/ShengcaiLiao/QAConv
11. Lifelong Unsupervised Domain Adaptive Person Re-identification with Coordinated Anti-forgetting and Adaptation
作者: Zhipeng Huang, Zhizheng Zhang, Cuiling Lan, Wenjun Zeng, Peng Chu, Quanzeng You, Jiang Wang, Zicheng Liu, Zheng-jun Zha
摘要:无监督领域适应性行人重识别(ReID)已被广泛研究,以减轻领域差距的不利影响。这些工作假设目标领域的数据可以一次性获取。然而,对于现实世界的流媒体数据,这阻碍了对不断变化的数据统计的及时适应和对不断增加的样本的充分利用。在本文中,为了解决更多的实际情况,我们提出了一个新的任务,即终身无监督领域自适应(LUDA)行人重识别。这是一个具有挑战性的任务,因为它要求模型不断适应目标环境中的无标签数据,同时为这样一个细粒度的人物检索任务减轻灾难性的遗忘。我们为这个任务设计了一个有效的方案,称为CLUDA-ReID,其中反遗忘与适应性和谐地协调。具体来说,我们提出了一个基于元的协调数据重放策略,以重放旧数据并以协调的优化方向来更新网络,以适应和记忆。此外,我们提出了关系一致性学习,用于旧知识的提炼/继承,以符合基于检索的任务的目标。我们设置了两个评估环境来模拟实际应用场景。广泛的实验证明了我们的CLUDA-ReID在静止的目标流和动态的目标流场景中的有效性。
arXiv:https://arxiv.org/abs/2112.06632
代码:
12. Feature Erasing and Diffusion Network for Occluded Person Re-Identification
作者:Zhikang Wang, Feng Zhu, Shixiang Tang, Rui Zhao, Lihuo He, Jiangning Song
摘要:遮挡行人重识别(ReID)旨在将被遮挡的人的图像与不同摄像机视角下的整体图像相匹配。目标行人(TP)通常会受到非行人遮挡(NPO)和非目标行人(NTP)的干扰。以前的方法主要集中在提高模型对NPO的鲁棒性,而忽略了NTP的特征污染。在本文中,我们提出了一种新的特征消除和扩散网络(FED)来同时处理NPO和NTP。具体来说,NPO特征被我们提出的遮挡消除模块(OEM)所消除,该模块在NPO增强策略的帮助下,在整体行人图像上模拟NPO并生成精确的遮挡掩码。随后,我们将行人表征与其他记忆中的特征进行扩散,在特征空间中合成NTP特征,这是通过一个新颖的特征扩散模块(FDM)通过可学习的交叉注意机制实现的。在原始设备制造商提供的闭塞评分的指导下,特征扩散过程主要在可见的身体部分进行,这保证了合成的NTP特征的质量。通过在我们提出的FED网络中共同优化OEM和FDM,我们可以极大地提高模型对TP的感知能力,减轻NPO和NTP的影响。此外,提议的FDM只作为训练的辅助模块,在推理阶段将被丢弃,因此引入的推理计算开销很小。在遮挡和整体人脸识别基准上的实验证明了FED比最先进的技术更有优势,FED在闭塞人脸识别上达到了86.3%的Rank-1准确率,比其他方法至少高出了4.7%。
arXiv:https://arxiv.org/abs/2112.08740
代码:
Person Search
1. Cascade Transformers for End-to-End Person Search
摘要:行人搜索的目标是从一组场景图像中定位目标人物,由于大尺度变化、姿势/视点变化和遮挡,这具有极大的挑战性。在本文中,我们提出了用于端到端人物搜索的级联闭塞注意变换器(COAT)。我们的三阶段级联设计侧重于在第一阶段检测行人,而后面的阶段同时并逐步完善行人的检测和重新识别的表示。在每个阶段,闭塞的注意力转化器在联合阈值上应用更紧密的交叉,迫使网络学习从粗到细的姿势/比例不变的特征。同时,我们计算每个检测的闭塞注意力,以将一个人的标记与其他人或背景区分开来。通过这种方式,我们模拟了其他物体在标记水平上遮挡感兴趣的人的效果。通过全面的实验,我们在两个基准数据集上实现了最先进的性能,从而证明了我们方法的优势。
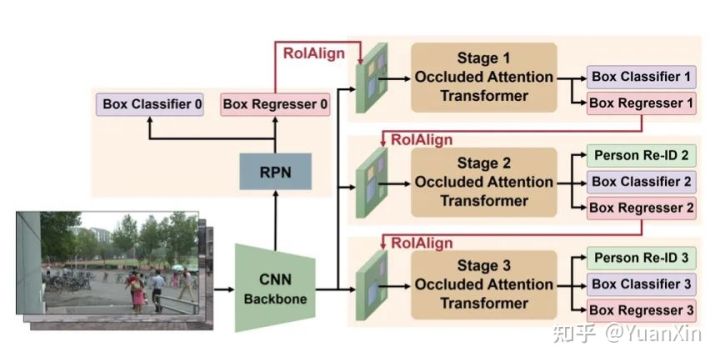
paper:https://arxiv.org/abs/2203.09642
code:https://github.com/Kitware/COAT
2. PSTR: End-to-End One-Step Person Search With Transformers
作者:Jiale Cao, Yanwei Pang, Rao Muhammad Anwer, Hisham Cholakkal, Jin Xie, Mubarak Shah, Fahad Shahbaz Khan
摘要:我们提出了一个新颖的基于Transformer的行人检索框架,PSTR,它在一个单一的架构中联合执行人检测和重识别(re-id)。PSTR包括一个人行人检索专用(PSS)模块,它包含一个用于行人检测的检测编码器-解码器和一个用于行人重识别的判别式解码器。鉴别性重识别解码器利用一个多级监督方案和一个共享解码器来进行鉴别性重识别特征学习,还包括一个部分关注块来编码一个人的不同部分之间的关系。我们进一步介绍了一个简单的多尺度方案,以支持不同尺度的人物实例的重识别。PSTR联合实现了对象级识别(检测)和实例级匹配(重识别)的不同目标。据我们所知,我们是第一个提出一个端到端的基于Transformer的行人检索框架。实验是在两个流行的基准上进行的。CUHK-SYSU和PRW。我们广泛的消融实验显示了所提出的贡献的优点。此外,提议的PSTR在两个基准上都达到了最先进的性能。在具有挑战性的PRW基准上,PSTR实现了56.5%的平均精度(mAP)得分。
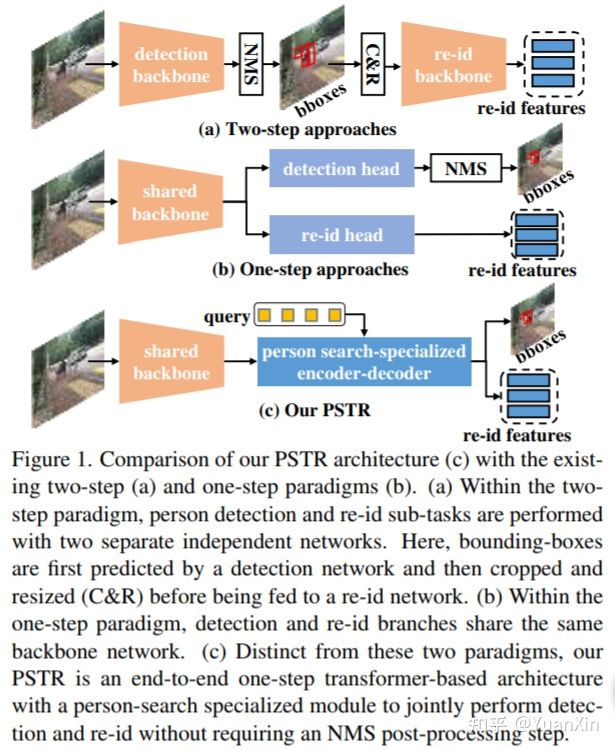
代码:https://github.com/JialeCao001/PSTR
arXiv:https://arxiv.org/abs/2204.03340
以上是关于CVPR 2022 部分行人重识别的主要内容,如果未能解决你的问题,请参考以下文章