Python连接SQL与hive
Posted 米米吉吉
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python连接SQL与hive相关的知识,希望对你有一定的参考价值。
--Zstarling
SQL连接
import pymysql
def sql(path):
conn = pymysql.Connect(host='36.104.34.123', user='用户名', passwd='密码', db='库名')
# 获取游标
cursor = conn.cursor()
# 1、从数据库中查询
sql = """
SELECT
x.province,
x.city,
count(DISTINCT x.pid_new)
FROM database.table AS x
WHERE x.province IN ("江苏")
group by x.city
"""
try:
result = cursor.execute(sql) # cursor执行sql语句
print(result) # 会输出操作的行数
# 使用fetch方法进行遍历结果 总共有三条数据
rr = cursor.fetchall() # 会输出查询的所有结果
# print(cursor.fetchone()) # 会输出一条查询的结果
# print(cursor.fetchmany(2)) # 传入参数会输出对应条数的查询结果
conn.commit() # 提交操作,只要涉及增删改就必须有commit,否则写不进数据库
except Exception as e:
print(e)
conn.rollback()
for row in rr:
with open(path, 'a+') as f:
print(row)
f.writelines(str(row) + '\\n')
f.close()
cursor.close()
conn.close()
hive连接
from impala.dbapi import connect
class Hiveclient():
# Hive登录
def __init__(self, user, password):
self.user = user
self.conn = connect(host='master1', port=99999, auth_mechanism='GSSAPI', user=user, password=password,
kerberos_service_name='hive')
# 数据查询与返回
def query(self):
print("开始取数啦!!!")
with self.conn.cursor() as curs:
qu_sql = """SELECT
province,
city
FROM database.table
limit 10
"""
print(qu_sql)
try:
curs.execute(qu_sql)
rr = curs.fetchall()
print(type(rr), rr)
# 对结果进行处理
for i in rr:
with open(path, 'a+', encoding='GB2312') as f:
print(i, type(i))
f.writelines(str(i) + '\\n')
print('=============全部完成===============')
except Exception as e:
print(e)
return
# 关闭客户端
def close(self):
self.conn.close()
补充写入方法
write与writelines对比
write():只能写入字符串。会把
writelines():可以写入字符串,列表,元组等。
with open(path, 'a+') as f:
print(rr)
f.write(str(rr)+'\\n')
f.writelines(str(rr)+'\\n')
都是字符串形式时两者无区别。结果如下:

注意:如果此时需要换行的话需要转化成字符串的形式与\\n连接。否则则会在尾部直接追加。示例如下:

表格Dataframe形式的写入
另外,如果是Dataframe或者series的数据需要写入的话,需要采用to_csv或者to_excel的方式。
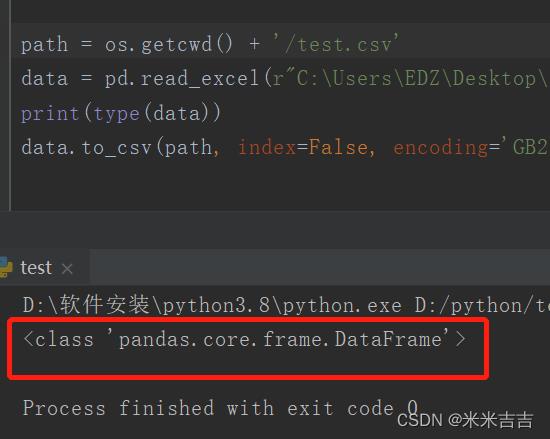
import os
import pandas as pd
path = os.getcwd() + '/test.csv'
data = pd.read_excel(r"C:\\Users\\EDZ\\Desktop\\test2.xlsx")
print(type(data))
data.to_csv(path, index=False, encoding='GB2312')
for、with 位置对比
with open(path, 'a+') as f:
for row in rr:
print(row)
f.writelines(str(row)+'\\n')
for row in rr:
with open(path, 'a+') as f:
print(row)
f.writelines(str(row)+'\\n')
for row in rr:
with open(path, 'a+') as f:
print(row)
f.write(str(row)+'\\n')
- 用了for循坏之后,write与writelines结果相同。
- with 和for 调换位置后并不影响循坏,即输出结果相同。
以上是关于Python连接SQL与hive的主要内容,如果未能解决你的问题,请参考以下文章