《云原生入门级开发者认证》学习笔记之云原生基础设施之Kubernetes
Posted 山河已无恙
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了《云原生入门级开发者认证》学习笔记之云原生基础设施之Kubernetes相关的知识,希望对你有一定的参考价值。
写在前面
- 嗯,报了考试,整理课堂笔记记忆
- 学习的原因:
- 虽然考了
CKA,了解了一些K8s相关的知识 - 但是对
云原生整个体系一直都很模糊 - 希望对云原生有一个基本的认识
- 通过学习实现云原生相关入门
- 虽然考了
- 博文主要内容涉及:
- 关于云原生基础设施的简述,主要为K8s,适合温习,初学
- 都是理论,很浅,对K8s做一个整体的简介
傍晚时分,你坐在屋檐下,看着天慢慢地黑下去,心里寂寞而凄凉,感到自己的生命被剥夺了。当时我是个年轻人,但我害怕这样生活下去,衰老下去。在我看来,这是比死亡更可怕的事。--------王小波
云原生基础设施
容器集群管理概述
容器编排技术
容器(如Docker)以及周边生态系统提供了很多工具来实现容器生命周期管理,能够满足在单台宿主机管理容器的需求。但越来越多企业开始使用容器,对容器技术的进一步发展提出了以下新的诉求:·
- 高效的容器管理及
编排。 - 容器的
跨主机部署及调度。 - 容器的
存储、网络、运维、安全等能力的拓展。
容器编排技术可实现跨主机集群的容器调度,并管理各种不同的底层容器。k8s通过管理底层的容器节点,自动化应用容器的部署、扩展和操作,提供以容器为中心的基础架构。
容器编排的价值
容器编排是指自动化容器的部署、管理、扩展和联网
-
容器编排管理平台用于管理云平台中多个主机上的容器化应用,其目标是让部署容器化的应用简单并且高效。 -
容器编排平台提供了应用
部署、规划、更新、维护的一种机制。 -
对应用开发者而言,容器编排平台是一个集群操作系统,提供
服务发现、伸缩、负载均衡、自愈甚至选举等功能,让开发者从基础设施相关配置等解脱出来。
大规模容器集群管理工具,从Borg到Kubernetes
Kubernetes起源于Google内部的Borg项目,它对计算资源进行了更高层次的抽象,通过将容器进行细致的组合,将最终的应用服务交给用户。它的目标是管理大规模的容器,提供基本的部署、维护以及应用伸缩等功能,其主要实现语言为Go语言。
Kubernetes作为容器集群管理工具,于2015年7月22日迭代到v1.0并正式对外公布。与此同时,谷歌联合Linux基金会及其他合作伙伴共同成立了CNCF基金会(Cloud Native Computing Foundation),并将Kuberentes作为首个编入CNCF管理体系的开源项目,助力容器技术生态的发展进步。
容器集群管理竞争史
在整个容器编排生态中,过去多国混战,包括:mesos+Marathon、docker swarm、kubernetes等等。
Kubernetes架构与核心概念
Kubernetes架构
一个基础的Kubernetes集群(Cluster)通常包含一个Master节点和多个Node节点。每个节点可以是一台物理机,也可以是一台虚拟机。
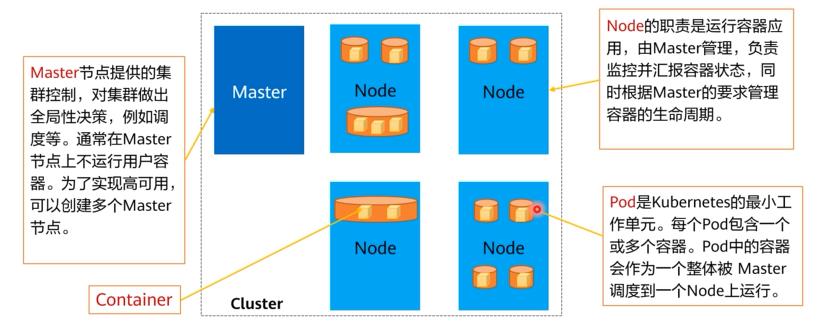
Master节点
Master节点是集群的控制节点,由API Server、Scheduler、Controller Manager和ETCD四个组件构成。
Kube-apiserver:kube-apiserver对外暴露了KubernetesAPl。它是的Kubernetes前端控制层。被设计为水平扩展架构,即通过部署更多实例来承载业务。各组件互相通讯的中转站,接受外部请求,并将信息写到ETCD中。etcd:etcd用于Kubernetes的后端存储,存储集群数据,提供数据备份。一个分布式数据存储组件,负责存储集群的配置信息。Kube-controller-manager:控制器,负责策略控制,针对不同的工作负载执行不同的策略,如无状态应用,有状态应用等。执行集群级功能,例如复制组件,跟踪Node节点,处理节点故障等等。Kube-scheduler:负责任务调度工作,监控没有分配节点的新创建的Pod,选择一个节点供Pods运行。负责应用调度的组件,根据各种条件(如可用的资源、节点的亲和性等)将容器调度到Node上运行。
在生产环境中,为了保障集群的高可用,通常会部署多个master,如CCE的集群高可用模式就是3个master节点
Node节点
Node节点是集群的计算节点,即运行容器化应用的节点。
Kubelet:在集群内每个节点中运行的一个代理,用于保证Pod的运行,接收Master的指令,负责管理节点容器(Pod)。kubelet主要负责同Container Runtime打交道Kube-proxy:负责做负载均衡工作,在多个Pod/Service之间做负载均衡。用于管理Service的访问入口,包括集群内Pod到Service的访问和集群外访问Service。应用组件间的访问代理Add-ons:插件,用于扩展Kubernetes的功能。Container runtime:通常使用Docker来运行容器,也可使用rkt或者podman等做为替代方案。
开放接口CRI、CNI、CSI
-
Kubernetes作为云原生应用的的基础调度平台,相当于云原生的操作系统,为了便于系统的扩展,Kubernetes中开放的以下接口,可以分别对接不同的后端,来实现自己的业务逻辑: -
CRI(Container Runtime Interface):容器运行时接口,提供计算能力,是定义了容器和镜像的服务的接口,常见的CRI后端有Docker、rkt、kata-containers等。 -
CNI(Container Network Interface):容器网络接口,提供网络能力,由一组用于配置Linux容器的网络接口的规范和库组成,同时还包含了一些插件,它仅关心容器创建时的网络分配,和当容器被删除时释放网络资源。 -
CSI(Container Storage Interface):容器存储接口,提供存储能力,通过它,Kubernetes可以将任意存储系统暴露给自己的容器工作负载。
Kubernetes工作流程

- 用户可以通过
UI或者kubectl提交一个Pod创建的请求给Kubernetes集群的控制面, - 这个请求首先会由
Kube API Server接收,API Server会把这个信息写入到集群的存储系统etcd。 - 之后
Scheduler会通过API Server的watch,或者叫做notification的机制得到这个信息。接收到Pod创建请求后,Scheduler会根据集群各节点的内存状态进行一次调度决策,在完成这次调度之后,它会向API Server返回可调度的节点的信息。API Server接收到这次操作之后,会把调度决策的结果再次写到etcd,然后通知相应的节点去真正的执行Pod的启动。 - 相应节点的
kubelet接收到创建Pod的请求后就会去调用Container runtime来真正的去动配置容器和这个容器的运行环境,并调度Storage Plugin进行容器存储的配置,调度network Plugin进行容器网络的配置。
Kubernetes核心概念-Pod
Pod是Kubernetes中最重要最基本的概念,Pod是Kubernetes最小工作单元。每一个Pod包含一个或多个相关容器,Kubernetes将Pod看做一个整体进行调度。
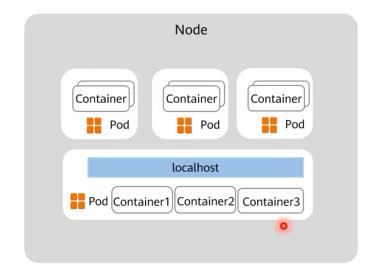
引入Pod的目的:
- 将
联系紧密的容器封装在一个Pod单元内,以Pod整体进行调度、扩展和实现生命周期管理。 - Pod内所有容器使用相同的
网络Namespace和共享存储。即Pod内容器拥有相同IP地址和Port空间,容器间直接使用localhost通信。当挂载volume到Pod,即可实现将volume挂载到Pod中的每个容器。
Pod使用主要分为两种方式:
- Pod中运行一个容器。这是Kubernetes最常见的用法,您可以将Pod视为单个封装的容器,但是Kubernetes是直接管理Pod而不是容器。
- Pod中运行多个需要耦合在一起工作、需要
共享资源的容器(比如初始化容器)。通常这种场景下应用包含一个主容器和几个辅助容器(SideCar Container),例如主容器为一个web服务器,从一个固定目录下对外提供文件服务,而辅助容器周期性的从外部下载文件存到这个固定目录下。
Kubernetes核心概念-Label
当资源变得非常多的时候,如何分类管理就非常重要了,Kubernetes提供了一种机制来为资源分类,那就是Label(标签)。类似html中的标签属性,Label非常简单,但是却很强大,Kubernetes中几乎所有资源都可以用Label来组织。Label的具体形式是key-value的标记对,可以在创建资源的时候设置,也可以在后期添加和修改。
- 对已存在的Pod,可以直接使用
kubectl label命令直接添加Label。 - Pod有了Label后,在查询Pod的时候带上
--show-labels就可以看到Pod的Label。
Kubernetes核心概念-Namespace
命名空间(Namespace)是对一组资源和对象的抽象整合。在同一个集群内可创建不同的命名空间,不同命名空间中的数据彼此隔离。使得它们既可以共享同一个集群的服务,也能够互不干扰。一般用于租户隔离。或者生产开发隔离
Namespace主要有以下功能及特点:
- 将包含很多组件的系统分成不同的组,每个资源仅属于一个Namespace。
- 实现多租户划分,这样多个团队可以共用一个集群,使用的资源用Namespace进行划分
- 不同的Namespace下面的资源可以拥有相同的名字
- Namespace可使用的资源量可通过ResourceQuota进行限制
在默认情况下,新建的集群存在以下四个Namespace:
default:所有未指定Namespace的对象都会被分配在default命名空间。kube-public:此命名空间下的资源可以被所有人访问(包括未认证用户),用来部署公共插件、容器模板等。kube-system:所有由Kubernetes系统创建的资源都处于这个命名空间(通过kubeadm的方式部署)。kube-node-lease:每个节点在该命名空间中都有一个关联的“Lease”对象,该对象由节点定期更新,被用来记录节点的心跳信号。(这个第一次听说)
Kubernetes中大部分资源可以用Namespace划分,不过有些资源不行,它们属于全局资源,不属于某一个Namespace,如Node、PV等。
Namespace只能做到组织上划分,对运行的对象来说,它不能做到真正的隔离。举例来说,如果两个Namespace下的Pod知道对方的IP,而Kubernetes依赖的底层网络没有提供Namespace之间的网络隔离的话,那这两个Pod就可以互相访问。
Kubernetes核心概念-Controller
工作负载是在Pod之上的一层抽象,我们可以通过控制器(controller)实现一系列基于Pod的高级特性,比如节点故障时Pod的自动迁移,Pod多副本横向扩展,应用滚动升级等。我们通常使用controller来做应用的真正的管理,而Pod是组成工作负载最小的单元。
工作负载按不同业务类型,在Kubernetes中分为以下四类:
Deployment和ReplicaSetStatefulSetDaemonSetJob、CronJob
Controller负责整个Kubernetes的管理工作,保证集群中各种资源的状态处于期望状态,当监控到集群中某个资源状态不正常时,管理控制器会触发对应的调度操作。一个Controller至少追踪一种类型的Kubernetes资源。这些对象有一个代表期望状态的spec字段。该资源的Controller负责确保其当前状态接近期望状态。
Kubernetes核心概念-Service
在Kubernetes中,Pod副本发生迁移或者伸缩的时候会发生变化,IP也是变化的。
Kubernetes中的Service是一种抽象概念,它定义了一个Pod逻辑集合以及访问它们的策略。Service定义了外界访问一组特定Pod的方式。Service有自己的IP和端口,Service为Pod提供了负载均衡(kube-proxy)。
Service有一个固定lP地址(在创建集群时有一个服务网段的设置,这个网段专门用于给Service分配IP地址),Service将访问它的流量转发给Pod,具体转发给哪些Pod通过Label来选择,而且Service可以给这些Pod做负载均衡。
Kubernetes核心概念-Volume
Volume用来管理Kubernetes存储,是用来声明在Pod中的容器可以访问的文件目录,含义如下:
- 声明在Pod中的容器可以访问的文件目录。
- 可以被挂载在Pod中一个或多个容器的指定路径下。
- 支持多种后端存储(本地存储、分布式存储、云存储等)。
Pod中的所有容器都可以访问Volume,但必须要挂载,且可以挂载到容器中任何目录。
Kubernetes应用编排与管理

Pod:最小调度单位。Workload:Kuberntes中承载工作负载的对象,实现Pod的编排与调度。Routing:Kubernetes网络,解决Pod的访问问题。Nucleus:Kubernetes存储及配置管理。Policy Enforcement:各类实现Kubernetes高级特性的插件。
Kubernetes管理-Kubectl
Kubectl是Kubernetes的命令行工具。通过kubectl,用户能对集群进行管理,并在集群上进行容器化应用的安装部署。
Kubectl支持以下对象管理方式:
指令式:通过kubectl内置的驱动命令,如:kubectl'+create/scale/delete/..+参数的形式,直接快速创建、更新和删除Kubernetes对象。声明式:使用kubectl apply创建指定目录中配置文件所定义的所有对象。通常,此配置文件采用yaml进行描述。
K8s中所有的配置都是通过API对象的spec去设置的,也就是用户通过配置系统的理想状态来改变系统,这是k8s重要设计理念之一,即所有的操作都是声明式(Declarative)的而不是命令式(Imperative)的。
声明式操作在分布式系统中的好处是稳定,不怕丢操作或运行多次。例如,设置副本数为3的操作运行多次也还是一个结果,而给副本数加1的操作就不是声明式的,运行多次结果就错了。
因此,在容器编排体系中,我们可以执行一个应用实例副本数保持在3个,而不用明确的去扩容Pod或是删除已有的Pod来保证副本数。
Kubernetes管理-命令行语法
在Kubernetes中的很多操作都是用kubectl来完成,通过其命令可以管理Deployment、Replicaset、ReplicationController、Pod等,进行操作、扩容、删除等全生命周期操作,同时可以对管理对象进行查看或者监控资源使用情况。
kubectl的语法:kubectl[command][TYPE][NAME][flags]
Command:指定你希望进行的操作,如create,get,describe,delete等。TYPE:指定操作对象的类型,如deployment,pod,service等。NAME:指定对象的名字。flags:可选的标志位。
Kubernetes管理-yaml示例
创建Kubernetes对象时,必须提供对象的规约,用来描述该对象的期望状态,以及关于对象的一些基本信息(例如名称)。在同一个yaml配置文件内可以同时定义多个资源
在编辑Kubernetes对象对应的yaml文件时,至少需要配置如下的字段:
apiVersion:建该对象所使用的KubernetesAPl的版本。kind:创建的对象的类别,如Pod/Deploymen/Service等。Metadata:描述对象的唯一性标识,可以是一个name字符串,可选的namespace,label项指定标签等。Spec:该对象的期望状态,其中replicas指定Pod副本数量。
apiVersion: v1
kind: Pod
metadata:
creationTimestamp: null
labels:
run: pod-svc
name: pod-svc
spec:
containers:
- image: nginx
imagePullPolicy: IfNotPresent
name: pod-svc
resources:
dnsPolicy: ClusterFirst
restartPolicy: Always
status:
Kubernetes应用编排-工作负载类型
无状态工作负载:管理的Pod集合是相互等价的,需要的时候可以被替换。
DeploymentReplicaSet
有状态工作负载:为每个Pod维护了一个唯一的ID,能够保证Pod的顺序性和唯一性,每个Pod是不可替代的。可使用持久存储来保存服务产生的状态。
StatefulSet
守护进程工作负载:保证每个节点上运行着这样一个守护进程。
DaemonSet
批处理工作负载:一次性的任务。
JobCronjob
无状态工作负载的“无状态”指的是请求无论经由哪一个实例进行处理,其返回的处理结果应是一致的,也就是说任何一个请求都可以被任意一个Pod处理;Pod不存储状态数据,相互等价,可以水平拓展,可被替换。web应用就是一类典型的无状态应用,对于这类应用,可采用Deployment或ReplicaSet进行部署。
Deployment概述
Deployment是一组不具有唯一标识的多个Pod的集合,具备以下功能:
- 确保集群中有
期望数量的Pod运行 - 提供多种
升级策略以及一键回滚能力。 - 提供
暂停/恢复的能力。
典型使用场景:
Web Server等无状态应用。
从大到小的管理逻辑为:Deployment>ReplicaSet>Pod>容器,多个ReplicaSet场景:滚动更新
Deployment管理 - 使用命令行创建Deployment
kubectl create deployment web1 --image=nginx
Deployment管理 - 使用yaml创建Deployment
apiVersion: apps/v1
kind: Deployment
metadata:
creationTimestamp: null
labels:
app: web1
name: web1
spec:
replicas: 3
selector:
matchLabels:
app: web1
strategy:
template:
metadata:
creationTimestamp: null
labels:
app: web1
spec:
containers:
- image: nginx
name: nginx
ports:
- containerPort: 80
resources:
status:
Deployment管理-滚动更新
用户希望应用程序始终可用,而开发人员则需要每天多次部署它们的新版本。在Kubernetes中,这些是通过滚动更新(Rolling Updates)完成的。滚动更新允许通过使用新的实例逐步更新Pod实例,零停机进行工作负载的更新。新的Pod将在具有可用资源的节点上进行调度。
滚动更新允许以下操作:
- 将应用程序从一个环境提升到另一个环境(通过容器镜像更新)。
- 回滚到以前的版本。
- 持续集成和持续交付应用程序,无需停机。
StatefulSet概述
- 在某些分布式的场景,比如分布式数据库,要求每个Pod都有自己单独的状态时,这时Deployment就不能满足需求了。
此类应用依靠StatefulSet进行部署。StatefulSet具备的以下特征:
- Pod有稳定的网络标识符,Pod重新调度后
PodName和HostName不变。 - 每个
Pod有单独存储,保证Pod重新调度后还是能访问到相同的数据。
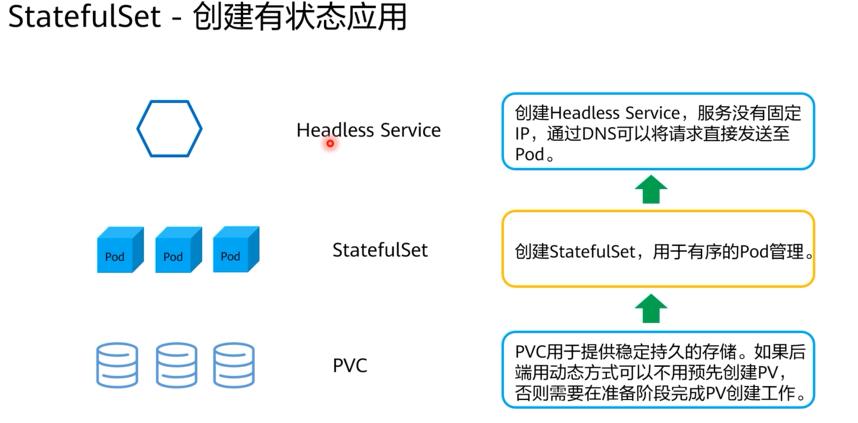
StatefulSet给每个Pod提供固定名称,Pod名称增加从0-N的固定后缀,Pod重新调度后Pod名称和HostName不变。StatefulSet通过Headless Service给每个Pod提供固定的访问域名,Service的概念会在后面章节中详细介绍。StatefulSet通过创建固定标识的PVC保证Pod重新调度后还是能访问到相同的持久化数据。
DaemonSet概述
DaemonSet(守护进程集)部署的副本Pod会分布在各个Node上。它具备以下特点:
- 确保
每一个节点或者期望的节点(通过nodeSelector实现)上运行一个Pod。DaemonSet跟节点相关,如果节点异常,也不会在其他节点重新创建。 - 新增节点时自动部署一个Pod。
- 移除节点时自动删除Pod。
DaemonSet典型场景:
- 在集群的每个节点上运行
存储Daemon,如glusterd,ceph。 - 在每个节点上运行
日志收集Daemon,如fluentd或logstash。 - 在每个节点上运行
监控Daemon,如Prometheus Node Exporter。
DaemonSet管理-创建DaemonSet
若需要在特定Node节点创建Pod,可在Pod模板中定义nodeSelector加以区分。
apiVersion: apps/v1
kind: DaemonSet
metadata:
creationTimestamp: null
labels:
app: myds1
name: myds1
spec:
#replicas: 1
selector:
matchLabels:
app: myds1
#strategy:
template:
metadata:
creationTimestamp: null
labels:
app: myds1
spec:
containers:
- image: nginx
name: nginx
resources:
#status:
Jobs概述
Job:是Kubernetes用来控制批处理型任务的资源对象。批处理业务与长期伺服业务(Deployment、Statefulset)的主要区别是批处理业务的运行有头有尾,而长期伺服业务在用户不停止的情况下永远运行。Job管理的Pod根据用户的设置把任务成功完成就自动退出(Pod自动删除)。
Jobs主要处理一些短暂的一次性任务,并具备以下特点保证指定数量Pod成功运行结束。
- 支持并发执行。
- 支持错误自动重试。
- 支持暂停/恢复
Jobs。
典型使用场景:
- 计算以及训练任务,如批量计算,Al训练任务等。
计算圆周率2000位
apiVersion: batch/v1
kind: Job
metadata:
creationTimestamp: null
name: job3
spec:
template:
metadata:
creationTimestamp: null
spec:
containers:
- command:
- perl
- -Mbignum=bpi
- -wle
- print bpi(500)
image: perl
name: job3
resources:
restartPolicy: Never
status:
CronJob概述
CronJob:是基于时间的Job,就类似于Linux系统的crontab文件中的一行,在指定的时间周期运行指定的Job。
CronJob主要处理周期性或者重复性的任务:
- 基于Crontab格式的时间调度。
- 可以暂停/恢复
CronJob。
·典型的使用场景: - 周期性的数据分析服务。
- 周期性的资源回收服务。
Jobs管理-创建Jobs
·相对于Deployment和DaemonSet通常提供持续的服务,Jobs执行一次性任务:
- Kind选择Job。
Completions当前的任务需要执行的Pod数量。Parallelism表示最多有多少个并发执行的任务。RestartPolicy只能选择Never或OnFailure。BackoffLimit参数指定job失败后进行重试的次数。
apiVersion: batch/v1
kind: Job
metadata:
creationTimestamp: null
name: my-job
spec:
backoffLimit: 6 #重试次数
completions: 6 # 运行几次
parallelism: 2 # 一次运行几个
template:
metadata:
creationTimestamp: null
spec:
containers:
- command:
- sh
- -c
- echo "hello jobs"
- sleep 15
image: busybox
name: my-job
resources:
restartPolicy: Never
status:
CronoJob管理-创建CronJob
CronJob是一种特殊的Job,它能够按照时间对任务进行调度,与我们熟悉的crontab非常相似。我们可以使用Cron格式快速指定任务的调度时间:
- 在给定时间点只运行一次。
- 在给定时间点周期性地运行。
```yaml
apiVersion: batch/v1
kind: CronJob
metadata:
creationTimestamp: null
name: test-job
spec:
jobTemplate:
metadata:
creationTimestamp: null
name: test-job
spec:
template:
metadata:
creationTimestamp: null
spec:
containers:
- command:
- /bin/sh
- -c
- date
image: busybox
name: test-job
resources:
restartPolicy: OnFailure
schedule: '*/1 * * * *'
status:
Kubernetes服务发布
Pod的特征·Pod特征
- Pod有自己独立的IP。
- Pod可以被创建,销毁。
- 当扩缩容时,Pod的数量会发生变更。
- 当Pod故障时,ReplicaSet会创建新的Pod。
如何保证在pod进行如此多变化时,业务都能被访问?
Pod创建完成后,如何访问Pod呢?直接访问Pod会有如下几个问题:
- Pod会随时被Deployment这样的控制器删除重建,那访问Pod的结果就会变得不可预知。
- Pod的IP地址是在Pod启动后才被分配,在启动前并不知道Pod的IP地址。
- 应用往往都是由多个运行相同镜像的一组Pod组成,逐个访问Pod也变得不现实。
Service概述
Kubernetes Service定义了这样一种抽象:逻辑上的一组Pod,一种可以访问它们的策略,通常称为微服务。这一组Pod能够被Service访问到,通常是通过Label Selector实现的。
Kubernetes支持以下Service类型:
- ClusterIP:提供一个集群内部的虚拟IP地址以供Pod访问(默认模式)。
- NodePort:在Node上打开一个端口以供外部访问。
- LoadBalancer:通过外部的负载均衡器来访问。
ClusterIP是Service的默认模式,LoadBalancer需要额外的模组来提供负载均衡。
Service管理-创建后端Deployment
创建一个deployment,特别注意其中的几个选项要和service匹配。
template选项必须配置labels,该配置和service匹配。
apiVersion: apps/v1
kind: Deployment
metadata:
creationTimestamp: null
labels:
app: web1
name: web1
spec:
replicas: 3
selector:
matchLabels:
app: web1
strategy:
template:
metadata:
creationTimestamp: null
labels:
app: web1
spec:
containers:
- image: nginx
name: nginx
resources:
status:
Pod的属性中ports选项指定pod对外提供服务的容器端口,该端口需要和Service匹配。
Service管理-创建集群内访问Service(ClusterIP)
apiVersion: v1
kind: Service
metadata:
creationTimestamp: "2021-12-21T15:31:19Z"
labels:
run: dbpod
name: dbsvc
namespace: liruilong-svc-create
resourceVersion: "310763"
uid: 05ccb22d-19c4-443a-ba86-f17d63159144
spec:
clusterIP: 10.102.137.59
clusterIPs:
- 10.102.137.59
internalTrafficPolicy: Cluster
ipFamilies:
- IPv4
ipFamilyPolicy: SingleStack
ports:
- port: 3306
protocol: TCP
targetPort: 3306
selector:
run: dbpod
sessionAffinity: None
type: ClusterIP
status:
loadBalancer:
- 集群内访问
(ClusterlP)表示工作负载暴露给同一集群内其他工作负载访问的方式,可以通过集群内部域名访问。 - 示例创建一个名为
httpd-svc的Service,通过selector选择到标签app:httpd的Pod,目标Pod的端口为80,Service对外暴露的端口为8080。 - 集群内Pod访问该服务只需要通过“
服务名称:对外暴露的端口”接口,对应本例即
httpd-svc:8080。
Service管理-创建可供外部访问的Service
如果需要Service可供外部进行访问,可以使用NodePort的方式。
- 编辑yaml文件时,添加type参数。
- 可以在使用nodePort字段指定对外服务端口,如果不进行指定,系统会自动分配空闲端口。
- 访问时通过访问“节点IP地址:端口”进行服务使用。
nodePort: 30000 为节点端口,取值范围为30000-32767。
LoadBalancer模型
负载均衡(LoadBalancer):可以通过弹性负载均衡从公网访问到工作负载,与NodePort加公网IP的方式相比提供了高可靠的保障。
LoadBalancer此功能由集群外部负载均衡器提供商提供。

负载均衡(LoadBalancer)一般用于系统中需要暴露到公网的服务。
负载均衡访问方式由公网弹性负载均衡服务地址以及设置的访问端口组成,例如
┌──[root@vms81.liruilongs.github.io]-[~/ansible/k8s-svc-create/metalld]
└─$kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
dbsvc ClusterIP 10.102.137.59 <none> 3306/TCP 101m
┌──[root@vms81.liruilongs.github.io]-[~/ansible/k8s-svc-create/metalld]
└─$kubectl expose --name=blogsvc pod blog --port=80 --type=LoadBalancer
service/blogsvc exposed
┌──[root@vms81.liruilongs.github.io]-[~/ansible/k8s-svc-create/metalld]
└─$kubectl get svc -o wide
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR
blogsvc LoadBalancer 10.108.117.197 192.168.26.240 80:30230/TCP 9s run=blog
dbsvc ClusterIP 10.102.137.59 <none> 3306/TCP 101m run=dbpod
在访问时从ELB过来的流量会先访问到节点,然后通过Service转发到Pod。而如果创建一个LoadBalancer,系统则会创建一个NodePort,NodePort则会创建ClusterlP。
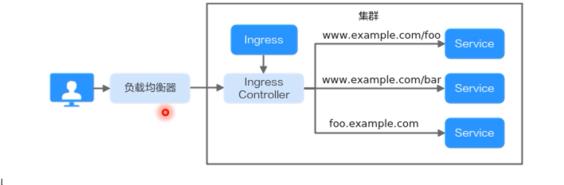
Ingress概述
Service是基于四层TCP和UDP协议转发的,而在实际使用场景中,四层Service无法满足应用层存在的大量HTTP/HTTPS访问需求,因此需要使用七层负载均衡(Ingress)来暴露服务。
Ingress可基于七层的HTTP和HTTPS协议进行转发,它是Kubernetes集群中一种独立的资源,制定了集群外部访问流量的转发规则。这些转发规则可根据域名和路径进行自定义,Ingress Controller根据这些规则将流量分配到一个或多个Service,完成对访问流量的细粒度划分。
┌──[root@vms81.liruilongs.github.io]-[~/ansible/k8s-svc-create]
└─$kubectl get svc -o wide
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR
pod-svc-1-svc ClusterIP 10.99.80.121 <none> 80/TCP 94s run=pod-svc-1
pod-svc-2-svc ClusterIP 10.110.40.30 <none> 80/TCP 107s run=pod-svc-2
pod-svc-svc ClusterIP 10.96.152.5 <none> 80/TCP 85s run=pod-svc
┌──[root@vms81.liruilongs.github.io]-[~/ansible/k8s-svc-create]
└─$
Ingress资源:一组基于域名或URL把请求转发到指定Service实例的访问规则,是Kubernetes的一种资源对象,通过接口服务实现增、删、改、查的操作。
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: my-ingress
annotations:
kubernetes.io/ingress.class: "nginx" #必须要加
spec:
rules:
- host: liruilongs.nginx1
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: pod-svc-svc
port:
number: 80
- host: liruilongs.nginx2
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: pod-svc-1-svc
port:
number: 80
- host: liruilongs.nginx3
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: pod-svc-2-svc
port:
number: 80
Ingress Controller:请求转发的执行器,用以实时监控资源对象Ingress、Service、End-point、Secret(主要是TLS证书和Key)、Node、ConfigMap的变化,解析Ingress定义的规则并负责捋请求转发到相应的后端Service。
Ingress Controller在不同厂商之间的实现方式不同,根据负载均衡器种类的不同,可以将其分成ELB型和Nginx型。
Kubernetes存储管理
Volume概述
Volume的核心是一个目录,其中可能存有数据,Pod中的容器可以访问该目录中的数据。
用户创建Volume时选择的卷类型将决定该目录如何形成,使用何种介质保存数据,以及规定目录中存放的内容。
Volume的生命周期与挂载它的Pod相同,但是Volume里面的文件可能在Volume消失后仍然存在,这取决于卷的类型。如当Pod不再存在时,Kubernetes也会销毁临时卷,但并不会销毁持久卷。
Volume类型
·Kubernetes支持多种卷类型,常用的类型有:
- emptyDir:一种简单的空目录,主要用于临时存储。
- hostPath:将主机(节点)某个目录挂载到容器中,适用于读取主机上的数据。
- ConfigMap:特殊类型,将Kubernetes特定的对象类型挂载到容器。
- Secret:特殊类型,
以上是关于《云原生入门级开发者认证》学习笔记之云原生基础设施之Kubernetes的主要内容,如果未能解决你的问题,请参考以下文章
《云原生入门级开发者认证》学习笔记之云原生基础设施之容器技术