kafka专栏如何做以消息队列为核心的应用程序开发(含视频)
Posted 字母哥哥
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了kafka专栏如何做以消息队列为核心的应用程序开发(含视频)相关的知识,希望对你有一定的参考价值。
文章目录
怎么做以消息队列为核心的应用开发
有的时候我们会遇到这样一种情况,某个数据记录存储到数据库之后,需要反复的查询统计。会造成一种局面:某个数据库既要承担高并发的实时数据处理,又要承担耗费资源较多的离线数据分析。下面我们就来回顾一下,在传统基于数据库为核心应用开发中我们经常会遇到的一种场景,以及我们该如何解决相关问题。
1.以数据库核心的应用开发
在绝大多数的小型企业中,仍然较多的使用以数据库为核心的应用开发模式。这种开发模式比较适合短小精悍的项目。如果用来支撑一个大型的以数据驱动的项目,就会出现下面的一些问题:
- 假设用户提出的第一个需求是:n台linux内存服务器内存使用率采集。我们马上开发需求,常规的做法是开发一个采集器负责指标采集,一个接收器负责指标数据接收,之后将度量指标数据保存到数据库。没问题,需求实现并满足用户要求。
- 过了几天用户给你提出另外一个需求,这个指标数据需要提供给第三方系统,你们对接一下吧。对接的结果大概率是你方提供接口服务给第三方应用系统。没问题,需求也能实现。
- 又过一段时间,用户说你不能总是让我登录系统去看指标,能不能针对指标设置阈值,超过阈值发短信告警?所以你开发程序读取数据库,然后遍历数据,发现超过某个阈值的数据,然后发出告警短信。
- 用户又提出新需求,要针对这个指标进行计算,求5、15、30、60分钟的最大值、最小值、平均值。所以你又开发程序去读取数据库,写了四个定时任务,每隔5、15、30、60分钟去查询数据库计算最大值、最小值、平均值。
一套需求开发下来,你会发现你的数据交互过程是下面的这张图:

问题:
- 你会发现你所有的交互过程是以数据库为中心的,数据库的压力非常大。
- 正因为你是以数据库为中心,你会发现你的数据延时非常大,因为数据库查询统计需要时间
- 你从数据库查询指标数据,提供给第三方很慢,不仅查询还要更新数据标识,哪些发过了哪些没发过
- 你从数据库查询超过某个阈值的数据,等你的查询结果出来,可能那边的应用服务已经因为内存问题宕机了,没得到及时的处理
- 通过SQL每5、15、30、60分钟查库,求最大值、最小值、平均值,你再想想你的数据库压力大不大?如果用户再提一个需求,将5、15、30、60分钟的最大值、最小值、平均值以实时的动态折线图展示出来,你就疯了,因为数据库统计查询根本做不到获取实时统计数据。
2.以消息队列为核心的应用开发
如果上面的需求,以消息队列为核心进行开发,其交互过程是下面这样的
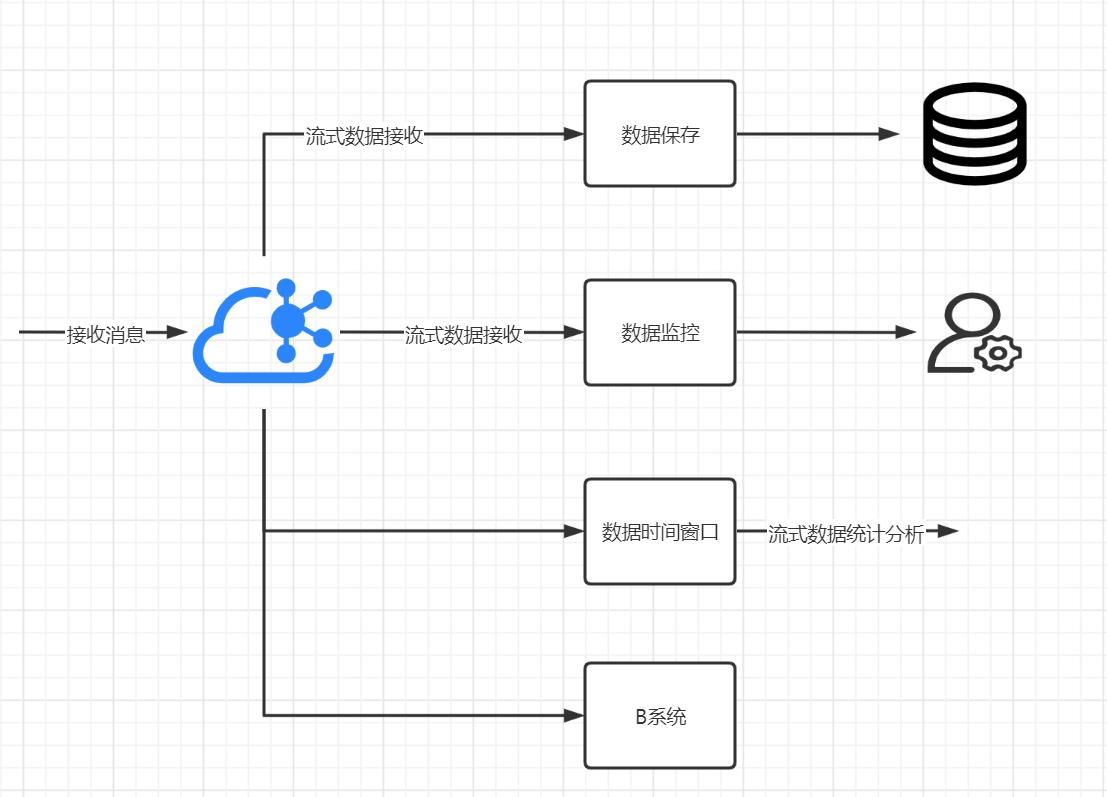
采集器采集到指标之后,发送给消息队列
- 系统管理应用作为一个消费者X,监听该数据主题,接收到数据之后将数据保存到数据库
- 数据监控应用作为一个消费者Y,同样监听该应用,接收到数据之后直接判断该数据是否超过阈值,超过之后直接发出告警短信
- 用户要求你提供数据给第三方系统B,你也不用再给他开发接口了,就告诉他消息队列的监听地址和主题。提供给系统B的数据还是准实时的,比查数据库快得多。
- 统计每5、15、30、60分钟指标的最大值、最小值、平均值,以kafka为例提供了时间窗口的能力,能有效地进行统计。如果你不会用kafka、flink之类的进行流式数据统计,自己写代码实现其实也很简单:以5分钟指标最大值为例,保存一个变量maxValue初始值为0,每次接收到一个指标数据值为currentValue,判断赋值
maxValue = currentValue>maxValue?currentValue:maxValue,每5分钟输出一次统计值,重新设置maxValue=0就可以了。
这样做的好处就是:
- 因为kafka作为消息队列,消息的延时非常低,可以做到准实时。只要你的程序有足够的处理能力,消息本身传递的延时是非常低的,远远快于数据库SQL查询。
- 你的数据库压力降低了,数据库响应数据提升,可以有效提升用户体验。
缺点还是那一个: 你需要多维护一个消息队列,但通常情况下,对于一个成熟的团队这不是问题,这远比数据库运维、调优要简单的多。要想成为一个kafka消息队列专家,深入学习与应用一年就足够了;要想成为oracle专家,可能需要整个职业生涯。
 创作打卡挑战赛
创作打卡挑战赛
 赢取流量/现金/CSDN周边激励大奖
赢取流量/现金/CSDN周边激励大奖
以上是关于kafka专栏如何做以消息队列为核心的应用程序开发(含视频)的主要内容,如果未能解决你的问题,请参考以下文章