Redis源码之跳表数据结构
Posted 特立独行的猫a
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Redis源码之跳表数据结构相关的知识,希望对你有一定的参考价值。
跳表
跳跃表(skiplist)是一种随机化的数据, 由 William Pugh 在论文《Skip lists: a probabilistic alternative to balanced trees》中提出, 跳跃表以有序的方式在层次化的链表中保存元素, 效率和平衡树媲美 —— 查找、删除、添加等操作都可以在对数期望时间下完成, 并且比起平衡树来说, 跳跃表的实现要简单直观得多。
跳表是一个随机化的数据结构,在原有的有序链表上面增加了多级索引,通过索引来实现快速查找。跳表不仅能提高搜索性能,同时也可以提高插入和删除操作的性能。
它或可以被看做二叉树的一个变种,它在性能上和红黑树,AVL树不相上下,但是跳表的原理非常简单,在Redis和LeveIDB中都有用到。
提到Redis的“数据结构”,可能是在两个不同的层面来理解。
第一个层面,是从使用者的角度。比如:string、list、hash、set、sorted set。
这一层面也是Redis暴露给外部的调用接口。
第二个层面,是从内部实现的角度,属于更底层的实现。如:dict、sds、ziplist、quicklist、skiplist。

跳表原理
它采用随机技术决定链表中哪些节点应增加向前指针以及在该节点中应增加多少个指针。跳表结构的头节点需有足够的指针域,以满足可能构造最大级数的需要,而尾节点不需要指针域。
采用这种随机技术,跳表中的搜索、插入、删除操作的时间均为O(logn),然而,最坏情况下时间复杂性却变成O(n)。相比之下,在一个有序数组或链表中进行插入/删除操作的时间为O(n),最坏情况下为O(n)。
跳表的数据结构模型:

每个带有箭头的框表示一个指针, 而每行是一个稀疏子序列的链表。底部的编号框(黄色)表示有序的数据序列。查找从顶部最稀疏的子序列向下进行, 直至需要查找的元素在该层两个相邻的元素中间。
跳表在原有的有序链表上面增加了多级索引,通过索引来实现快速查找。首先在最高级索引上查找最后一个小于当前查找元素的位置,然后再跳到次高级索引继续查找,直到跳到最底层为止,这时候以及十分接近要查找的元素的位置了(如果查找元素存在的话)。由于根据索引可以一次跳过多个元素,所以跳查找的查找速度也就变快了。
最理想的情况下,跳表就像一颗满二叉树,查找的时间复杂度是O(logn)。怎么决定一个结点有多少级索引?
针对这个问题跳表的创始人提出了一种抛硬币的方法,用随机函数产生一个0或者1,如果是1的话则leve++,直到产生0位置,当数据量足够大的时候,leve的取值会趋向于正态分布。
跳表的演化过程
对于单链表来说,即使数据是已经排好序的,想要查询其中的一个数据,只能从头开始遍历链表,这样效率很低,时间复杂度很高,是 O(n)。 那我们有没有什么办法来提高查询的效率呢?我们可以为链表建立一个“索引”,这样查找起来就会更快,如下图所示,我们在原始链表的基础上,每两个结点提取一个结点建立索引,我们把抽取出来的结点叫作索引层或者索引,down 表示指向原始链表节点的指针。
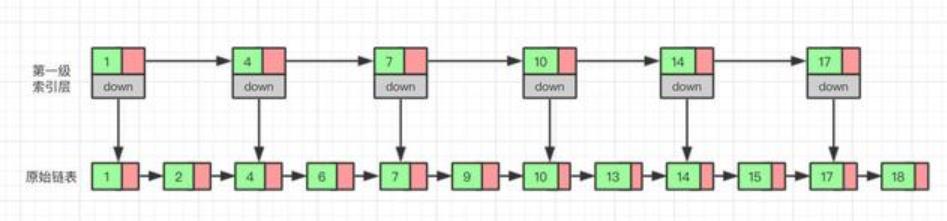
现在如果我们想查找一个数据,比如说 15,我们首先在索引层遍历,当我们遍历到索引层中值为 14 的结点时,我们发现下一个结点的值为 17,所以我们要找的 15 肯定在这两个结点之间。这时我们就通过 14 结点的 down 指针,回到原始链表,然后继续遍历,这个时候我们只需要再遍历两个结点,就能找到我们想要的数据。好我们从头看一下,整个过程我们一共遍历了 7 个结点就找到我们想要的值,如果没有建立索引层,而是用原始链表的话,我们需要遍历 10 个节点。
跳表与红黑树,AVL树等平衡数据结构的比较
跳表与红黑树和AVL树相比,效率不相上下,但是它胜在实现起来比较简单,我们可以很快的实现出来。跳表在更新的时候需要改动的地方很少,而红黑树和AVL树需要改动的地方很多。如果在多线程的情况下,红黑树和AVL树在维持平衡的时候,需要的锁资源很多,越是在靠近根节点的地方越容易产生竞争。但是跳表的操作更加局部性一点,需要锁住的资源很少。
跳表性质
1、由很多层组成
2、每一层都是一个有序链表
3、最底层的链表包含所有元素
4、如果一个元素出现在第i层的链表中,则它在i-1层中也会出现。
5、上层节点可以跳转到下层。
跳表在Redis中的应用
ZSet结构同时包含一个字典和一个跳跃表,跳跃表按score从小到大保存所有集合元素。字典保存着从member到score的映射。这两种结构通过指针共享相同元素的member和score,不会浪费额外内存。
redis中的zset在元素少的时候用ziplist来实现,元素多的时候用skiplist和dict来实现。
一个skiplist的生成过程: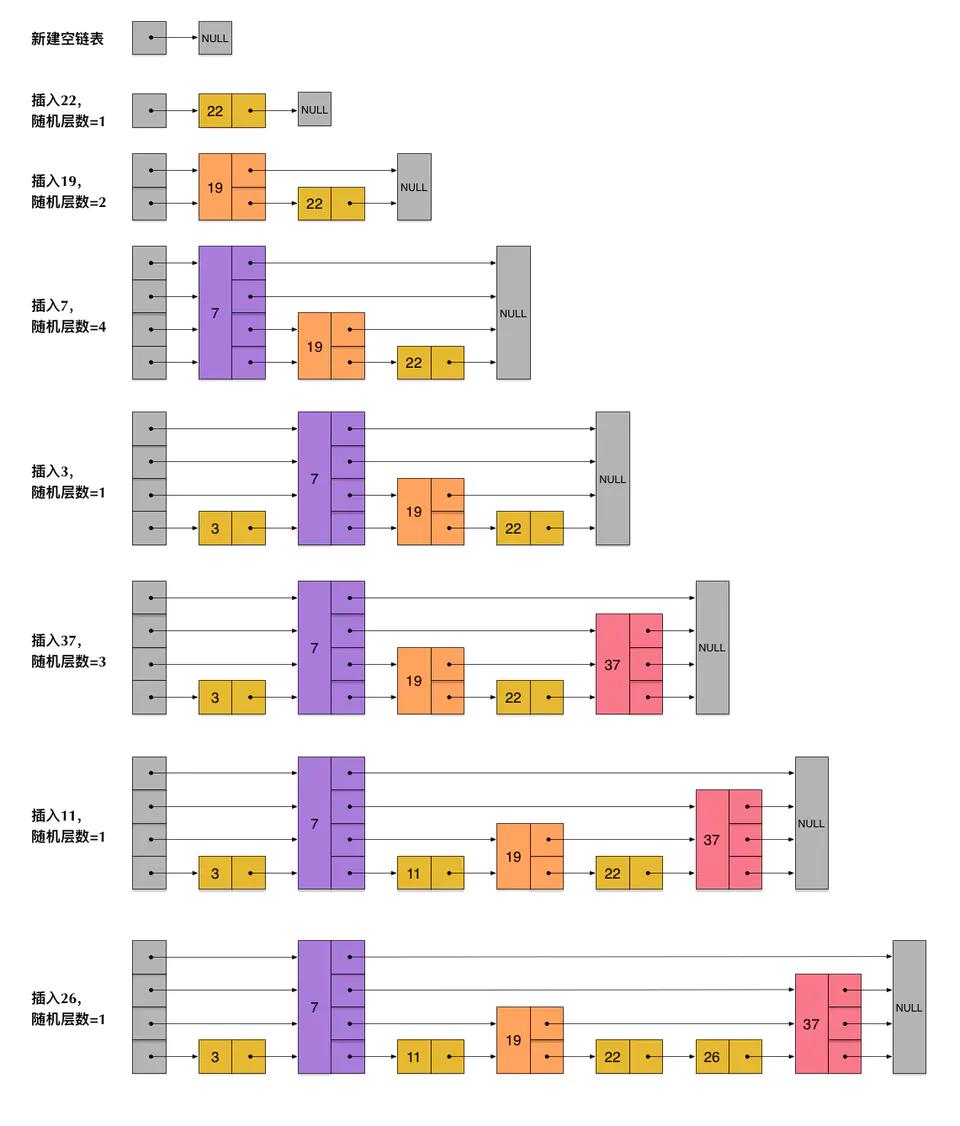
由于层数是每次随机出来的,所以新插入一个节点并不会影响其他节点的层数。插入一个节点只需要修改节点前后的指针即可,降低了插入的复杂度。
刚刚创建的skiplist包含4层链表,假设我们依然查找23,查找路径如下。插入的过程也需要经历一个类似查找的过程,确定位置后,再进行插入操作。
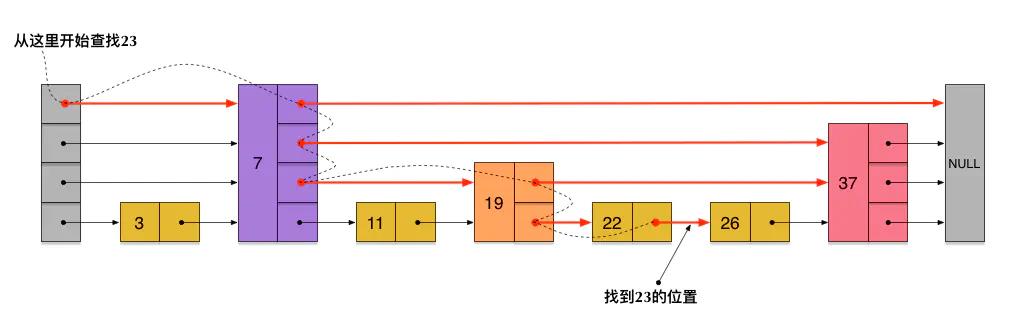
一个完整的跳表实现如下(代码地址:https://github.com/wangzheng0822/algo/tree/master/java/17_skiplist)
public class SkipList
// 大概每隔多少个节点向上提取一层的比例
// 1/2为大概每隔2个节点向上提取一层,1/4为每隔4个节点向上提取一层
private static final float SKIPLIST_P = 0.5f;
// 最高层数为16
private static final int MAX_LEVEL = 16;
// 目前的层数
private int levelCount = 1;
private Node head = new Node(); // 带头链表
public Node find(int value)
Node p = head;
// p.forwards[i]表示节点p到第i层的下一个节点
for (int i = levelCount - 1; i >= 0; --i)
while (p.forwards[i] != null && p.forwards[i].data < value)
p = p.forwards[i];
// 遍历到最底层了
if (p.forwards[0] != null && p.forwards[0].data == value)
return p.forwards[0];
else
return null;
public void insert(int value)
int level = randomLevel();
Node newNode = new Node();
newNode.data = value;
newNode.maxLevel = level;
Node update[] = new Node[level];
for (int i = 0; i < level; ++i)
update[i] = head;
// record every level largest value which smaller than insert value in update[]
Node p = head;
for (int i = level - 1; i >= 0; --i)
while (p.forwards[i] != null && p.forwards[i].data < value)
p = p.forwards[i];
update[i] = p;// use update save node in search path
// in search path node next node become new node forwords(next)
for (int i = 0; i < level; ++i)
newNode.forwards[i] = update[i].forwards[i];
update[i].forwards[i] = newNode;
// update node hight
// 更新目前的层数
if (levelCount < level) levelCount = level;
public void delete(int value)
Node[] update = new Node[levelCount];
Node p = head;
for (int i = levelCount - 1; i >= 0; --i)
while (p.forwards[i] != null && p.forwards[i].data < value)
p = p.forwards[i];
update[i] = p;
if (p.forwards[0] != null && p.forwards[0].data == value)
for (int i = levelCount - 1; i >= 0; --i)
if (update[i].forwards[i] != null && update[i].forwards[i].data == value)
update[i].forwards[i] = update[i].forwards[i].forwards[i];
while (levelCount > 1 && head.forwards[levelCount] == null)
levelCount--;
// 理论来讲,一级索引中元素个数应该占原始数据的 50%,二级索引中元素个数占 25%,三级索引12.5% ,一直到最顶层。
// 因为这里每一层的晋升概率是 50%。对于每一个新插入的节点,都需要调用 randomLevel 生成一个合理的层数。
// 该 randomLevel 方法会随机生成 1~MAX_LEVEL 之间的数,且 :
// 50%的概率返回 1
// 25%的概率返回 2
// 12.5%的概率返回 3 ...
// Math.random()返回的值为[0, 1)
private int randomLevel()
int level = 1;
while (Math.random() < SKIPLIST_P && level < MAX_LEVEL)
level += 1;
return level;
public void printAll()
Node p = head;
while (p.forwards[0] != null)
System.out.print(p.forwards[0] + " ");
p = p.forwards[0];
System.out.println();
public class Node
private int data = -1;
private Node forwards[] = new Node[MAX_LEVEL];
private int maxLevel = 0;
@Override
public String toString()
StringBuilder builder = new StringBuilder();
builder.append(" data: ");
builder.append(data);
builder.append("; levels: ");
builder.append(maxLevel);
builder.append(" ");
return builder.toString();
Redis为什么用skipList来实现有序集合,而不是红黑树?
redis中zset常用的操作有如下几种,插入数据,删除数据, 查找数据,按照区间输出数据,输出有序序列。
1.插入数据,删除数据,查找数据,输出有序序列这几种操作红黑树也能实现,时间复杂度和跳表一样。但是按照区间输出数据,红黑树的效率没有跳表高,跳表可以在O(logn)的时间复杂度定位区间的起点,然后向后遍历极客。
2.跳表和红黑树相比,比较容易理解,实现比较简单,不容易出错。
3.可以通过设置参数,改变索引构建策略,按需平衡执行效率和内存消耗。
zset在redis中的使用场景
先说下set在redis中的使用场景:
Set类型特点就是唯一,依靠唯一性,我们可以实现推荐好友,安全提示等功能。Redis中的set类型也是一种无序集合,集合中的元素没有先后顺序,而且具有确定性、唯一性的特点。相比于我们前面介绍的list类型,set支持更加丰富的操作,比如求交、并、差集等。
1.跟踪唯一性数据。
2.用于维护对象之间的关联关系。
例如redis跟踪数据唯一性,访问博客的唯一性。每次访问把访问者ip存储set中,保证了唯一性。充分用服务器端聚合高效,维护数据对象关联关系,如购买电子设备的id,存储到set中,另外购买的id存储到set中,可以比较交际查看到这个用户购买了哪些电器。
zset的应用场景
延时队列
score作为时间戳,自动按照时间最近的进行排序,启一个线程持续poll并设置park时间,完成延迟队列的设计。
排行榜
score作为浏览次数,自动进行排序,但要注意冷数据。
t_zset.c文件
/* ZSETs are ordered sets using two data structures to hold the same elements
* in order to get O(log(N)) INSERT and REMOVE operations into a sorted
* data structure.
*
* The elements are added to a hash table mapping Redis objects to scores.
* At the same time the elements are added to a skip list mapping scores
* to Redis objects (so objects are sorted by scores in this "view"). */
/* This skiplist implementation is almost a C translation of the original
* algorithm described by William Pugh in "Skip Lists: A Probabilistic
* Alternative to Balanced Trees", modified in three ways:
* a) this implementation allows for repeated scores.
* b) the comparison is not just by key (our 'score') but by satellite data.
* c) there is a back pointer, so it's a doubly linked list with the back
* pointers being only at "level 1". This allows to traverse the list
* from tail to head, useful for ZREVRANGE. *//* ZSETs use a specialized version of Skiplists */
typedef struct zskiplistNode
robj *obj;
double score;
struct zskiplistNode *backward;
struct zskiplistLevel
struct zskiplistNode *forward;
unsigned int span;
level[];
zskiplistNode;
typedef struct zskiplist
struct zskiplistNode *header, *tail;
PORT_ULONG length;
int level;
zskiplist;
typedef struct zset
dict *dict;
zskiplist *zsl;
zset;ZSet中的字典和跳表布局:

ZSet中跳表的实现细节
随机层数的实现原理
跳表是一个概率型的数据结构,元素的插入层数是随机指定的。Willam Pugh在论文中描述了它的计算过程如下:指定节点最大层数 MaxLevel,指定概率 p, 默认层数 lvl 为1
生成一个0~1的随机数r,若r<p,且lvl<MaxLevel ,则lvl ++
重复第 2 步,直至生成的r >p 为止,此时的 lvl 就是要插入的层数。
论文中生成随机层数的伪码:
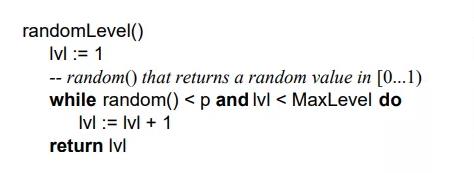
在Redis中对跳表的实现基本上也是遵循这个思想的,只不过有微小差异,看下Redis关于跳表层数的随机源码src/z_set.c:
/* Returns a random level for the new skiplist node we are going to create.
* The return value of this function is between 1 and ZSKIPLIST_MAXLEVEL
* (both inclusive), with a powerlaw-alike distribution where higher
* levels are less likely to be returned. */
int zslRandomLevel(void)
int level = 1;
while ((random()&0xFFFF) < (ZSKIPLIST_P * 0xFFFF))
level += 1;
return (level<ZSKIPLIST_MAXLEVEL) ? level : ZSKIPLIST_MAXLEVEL;
其中两个宏的定义在redis.h中:
#define ZSKIPLIST_MAXLEVEL 32 /* Should be enough for 2^32 elements */
#define ZSKIPLIST_P 0.25 /* Skiplist P = 1/4 */
while中的:
(random()&0xFFFF) < (ZSKIPLIST_P*0xFFFF)ZSKIPLIST_P*0xFFFF
由于ZSKIPLIST_P=0.25,所以相当于0xFFFF右移2位变为0x3FFF,假设random()比较均匀,在进行0xFFFF高16位清零之后,低16位取值就落在0x0000-0xFFFF之间,这样while为真的概率只有1/4,更一般地说为真的概率为1/ZSKIPLIST_P。
跳表结点的平均层数
产生越高的节点层数出现概率越低,无论如何层数总是满足幂次定律越大的数出现的概率越小。
如果某件事的发生频率和它的某个属性成幂关系,那么这个频率就可以称之为符合幂次定律。
幂次定律的表现是少数几个事件的发生频率占了整个发生频率的大部分, 而其余的大多数事件只占整个发生频率的一个小部分。

幂次定律应用到跳表的随机层数来说就是大部分的节点层数都是黄色部分,只有少数是绿色部分,并且概率很低。
对于Redis而言,当p=0.25时结点层数的期望是1.33。
level[]
每个跳跃表节点都包含一个level数组,这个数组包含1~32个元素,具体是多少呢,由幂次定律决定,假设为1的概率为,那么为2的概率就为,以此类推,为n的概率为,这个数组元素越多,说明层数越多,访问其他节点的速度就会越快。
level数组的每个元素都是一个zskiplistLevel结构体变量,这个变量包含2个元素forward和span,其中forward是一个指向下一个跳跃表节点的前进指针,span表示与下一个跳跃表节点的跨度,不理解的话可以看下面的例子说明。
2. backward
后退指针主要用于指向上一个跳跃表节点,形成逆向链表。
3. score
有序集合的分值,排序时用到,决定了跳跃表节点的位置。
4. obj
obj是一个指向实际成员对象的指针。
跳跃表的插入过程:
一开始跳跃表是空,先插入元素A,对应的score为5,随机生成的层数为2。
再插入元素B,对应的score为3,随机生成的层数为1。
最后再插入元素C,对应的score为7,随机生成的层数为1。
此时如果要查找分值为7的元素C,先从最高层的链表往右查,发现最上面的链表的第一个元素(不考虑header指向的节点)的分值为5<7,就往右前进,此时最上面的链表已经没有下一个节点了,所以就降一层再往右查,进而查到元素C的存在,整个过程其实直接跳过了对元素A对应节点的访问,从而提升了查询效率。
结果就像是由level条前进链表+1条后退链表构成的,后退链表的存在主要用于从后往前遍历所有跳跃表节点,而多条前进链表的存在则是为了提升查询效率。

引用
十分钟弄懂什么是跳表,不懂可以来打我_愤怒的可乐的博客-CSDN博客_跳表
https://epaperpress.com/sortsearch/download/skiplist.pdf
深入理解跳表及其在Redis中的应用 - ludongguoa - 博客园
redis 跳表_春天的早晨的博客-CSDN博客_redis跳表
Redis数据结构——skiplist(跳跃表)_fainionchen的博客-CSDN博客_redis数据结构跳跃表
Redis源码解析:数据结构详解-skiplist_Java识堂的博客-CSDN博客_redis skiplist
Redis内部数据结构详解(5)——quicklist - 铁蕾的个人博客
Redis内部数据结构详解(1)——dict - 铁蕾的个人博客
数据结构之跳表_xiaoxin_ysj的博客-CSDN博客_跳表数据结构
Leveldb skiplist 实现及解析_carbon06的博客-CSDN博客
以上是关于Redis源码之跳表数据结构的主要内容,如果未能解决你的问题,请参考以下文章