费解的备份corrupt终于搞明白了
Posted PostgreSQLChina
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了费解的备份corrupt终于搞明白了相关的知识,希望对你有一定的参考价值。


前言
前几天分享了一篇关于pg_probackup的生产案例《生产案例 | 费解的备份corrupt》,通过这几天的定位,终于将问题分析清楚了。
回顾
回顾一下,在之前的分析中,pg_probackup备份的大致流程是
• 先创建一个空的backup_content.control文件
• 然后备份文件,挨个transfer各个文件,同时会在parse_backup_filelist_filenames()逻辑里过滤掉临时表、unlogged表不进行备份
• 传输成功后,将transfer成功的文件写入到backup_content.control文件里面
• 接着进行校验,按照记录在backup_content.control里面的文件挨个执行validate,比如文件是否存在、CRC是否一致等
之前备份corrupt提示文件not found是怀疑文件传输到NAS上丢失了,或者backup_content.control刷盘丢IO了等。
但前天我打开了pg_probackup的全日志之后,发现一个奇怪的现象,如下:
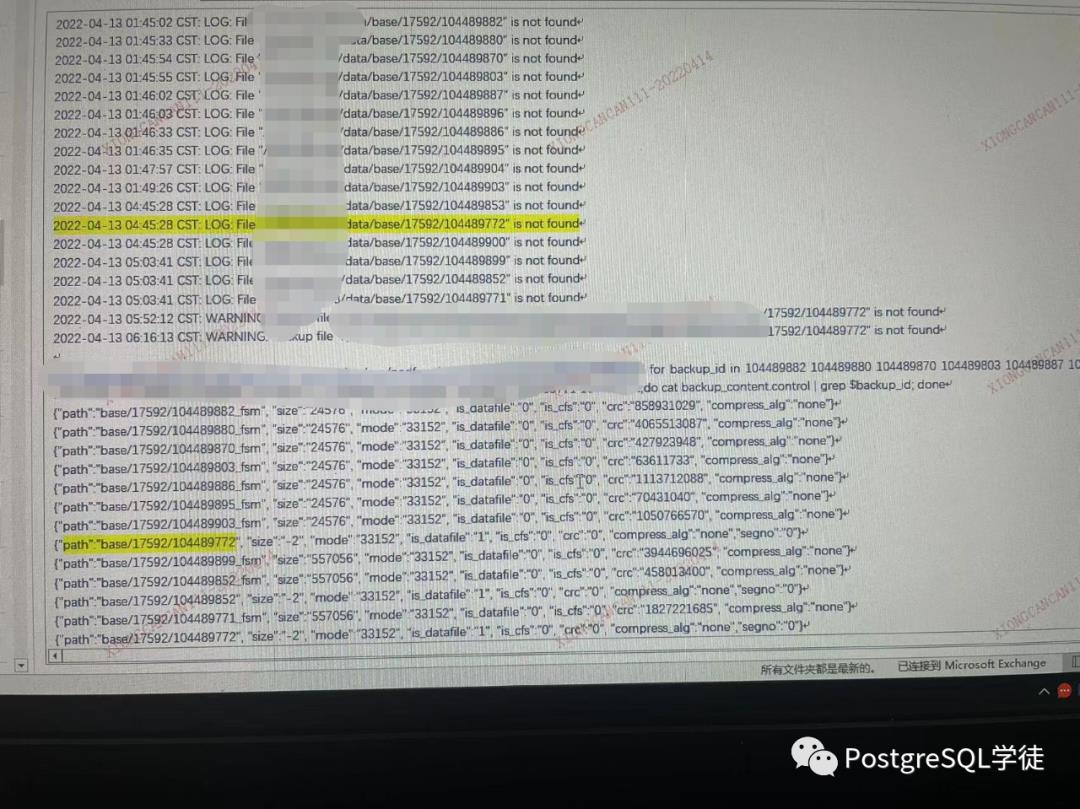
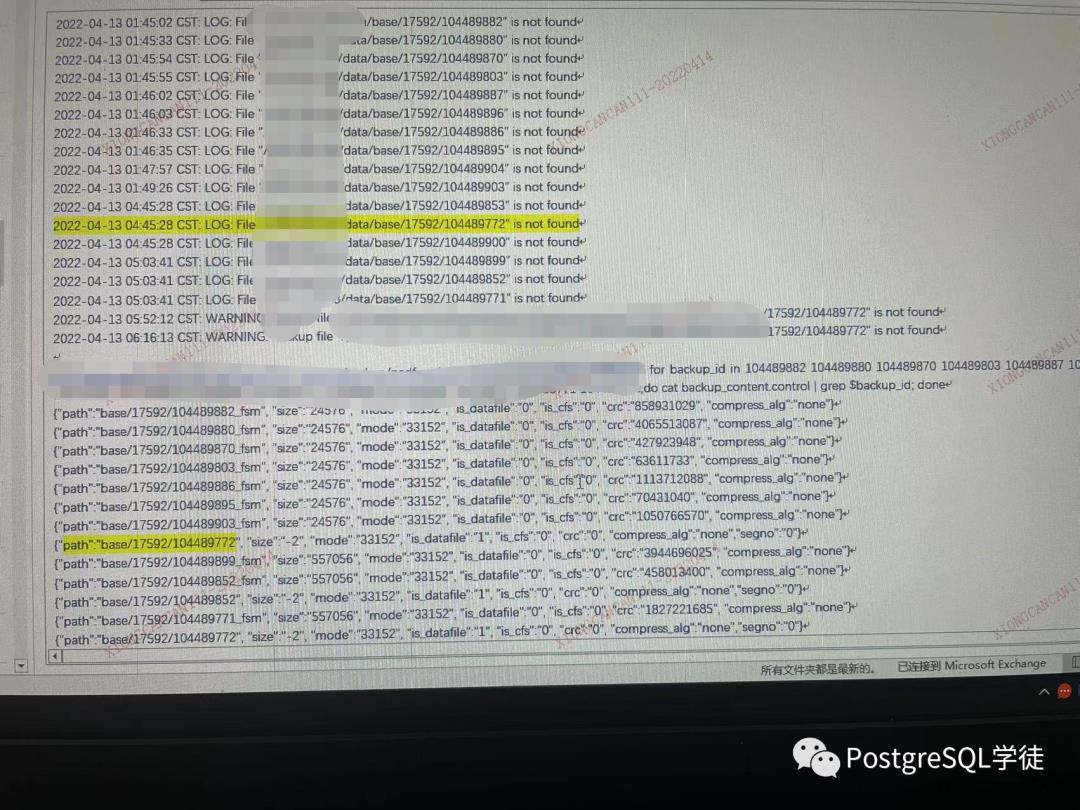
发现日志里面在transfer传输阶段就记录了大量的 xxx is not found的日志,并且更加奇怪的是,backup_content.control里面出现了两种情况:
• 记录了fsm文件,然后找对应的数据文件main的时候没有找到,提示not found
• 没有记录fsm文件,直接记录了main文件
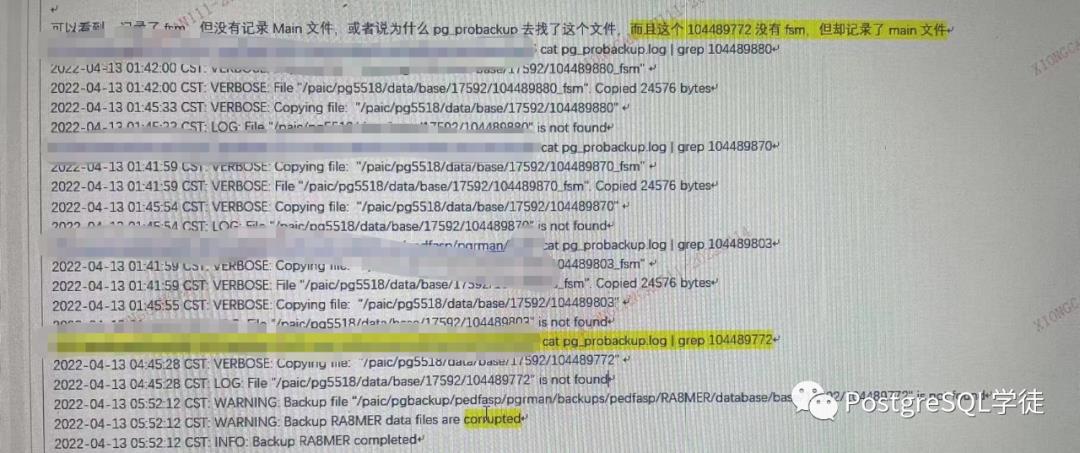
比如
• backup_content.control里面记录了104489880_fsm,但是提示104489880 is not found(第一条记录)
• backup_content.control里面记录了104489772,同时却提示了104489880 is not found(最后一条记录)
因此,和我之前分析的结论不符,即在transfer的阶段就提示not found了,理应不会记录(因为只有传输成功的文件才会记录),但却记录在了backup_content.control里面。
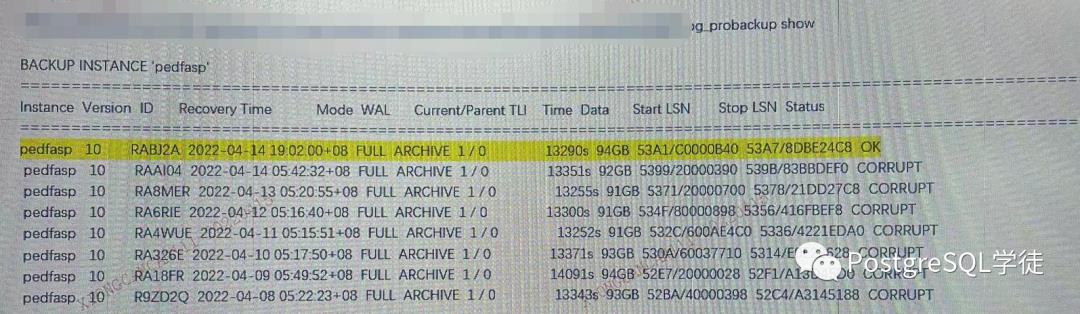
后面通过分析代码,发现提示not found的都是size为-2的文件,参照图1
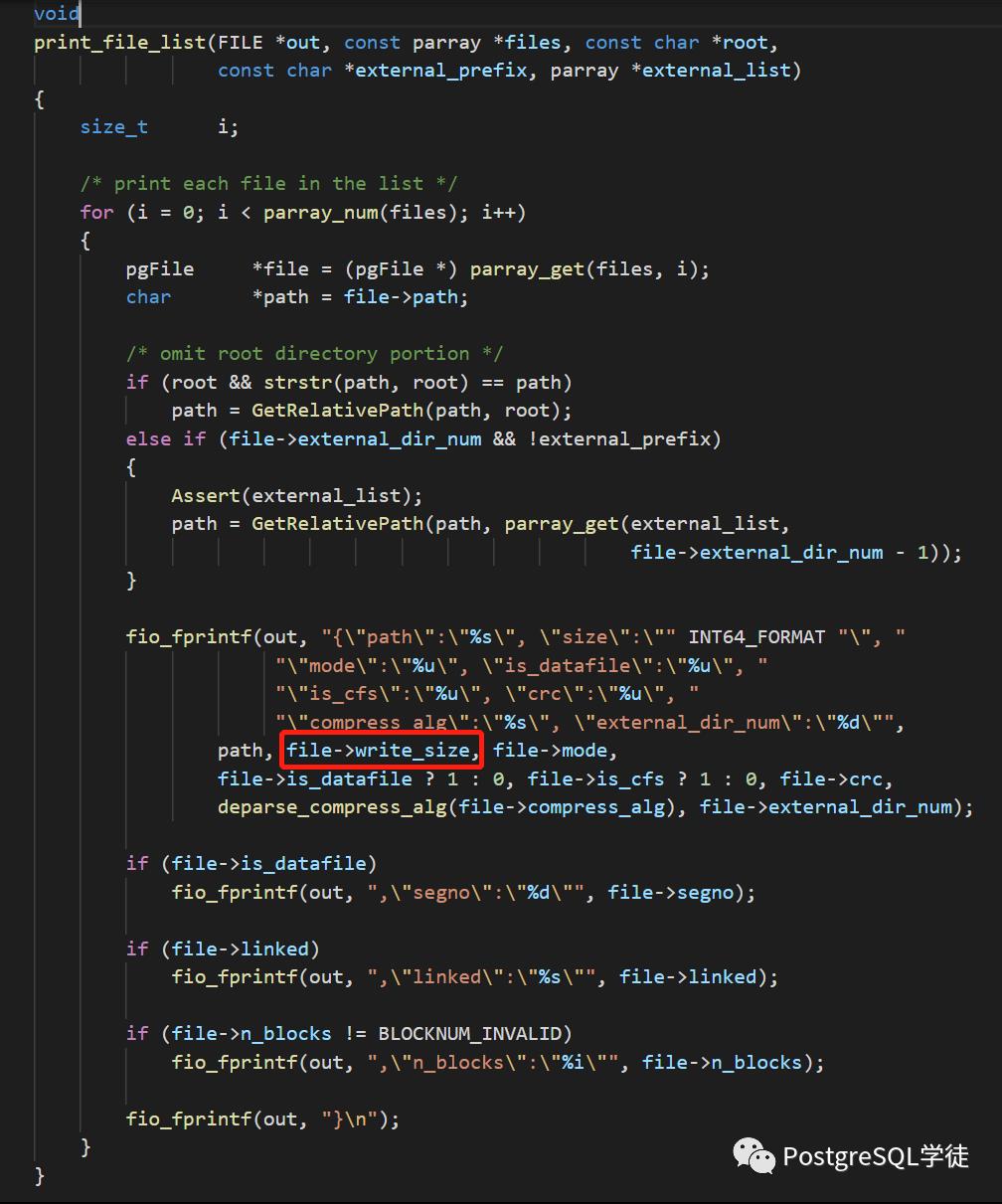
即此处的file -> write_size,而 (-2)表是FILE_NOT_FOUND,file disappeared during backup,表示备份期间文件丢失了。

同时,在代码逻辑里面,还有这么一段代码,这个代码是在write_backup_filelist() -> print_file_list()之前的,也就是说会在记录到backup_content.control之前就删除那些FILE_NOT_FOUND的文件,更加确信了我之前的分析,即只有传输成功的文件才会记录
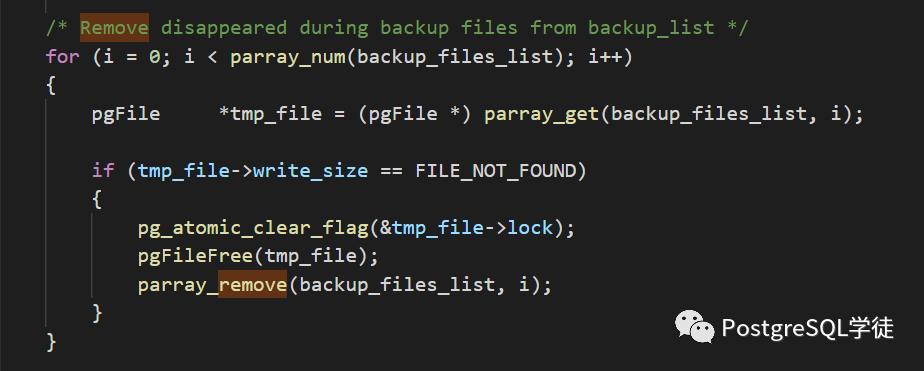
因此,分析到这里,似乎出现了矛盾,我明明会在记录到backup_content.control之前就删除这些丢失的文件,但是现象却又是真的记录到了文件里面,然后校验的时候就提示不存在报错了。而且记录进去又像是偶发性的,比如图1总共17条not found,但是backup_content.control就只有13条。
因此,我昨天下午在parray_remove处打了一个断点,然后在稳定复现的主机上使用gdb触发了pg_probackup,可是令人尴尬的是,备份居然成功了。
这十分不可思议,同时backup_content.control确实没有size为-2的文件,也没有xxx is not found的日志,正常备份成功了。
没法,我只能去看release,寄希望于是BUG。可喜的是,在2.1.3的版本说明里面,的确提到了这么一个bugfix:validate was giving a false-positive alarm for files disappeared during backup,validate可能会提示文件丢失的误报!
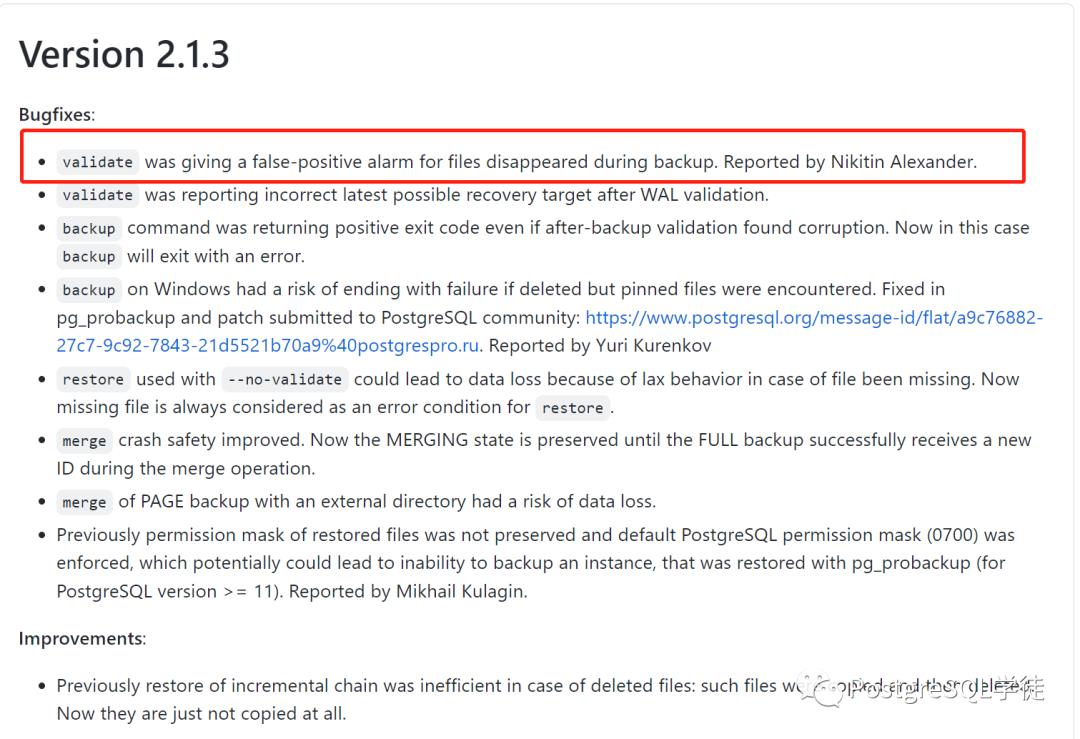
看到这里,我在昨天晚上给出一个结论:为什么凌晨备份(我们的定时任务是放在凌晨1点的)会稳定报错,而我下午手动触发的时候不会报错,我觉得是凌晨定时任务触发的时候是所有主机上的实例都在备份,同时争抢NAS资源、带宽、主机资源等,而我下午手动调试触发,没有报错因为就我一个实例在跑,回想之前的生产案例,主机夯死,都是大库同时备份争抢主机资源导致故障,进而加剧了这个BUG。
但是今天汪总回了一下邮件:"这个bugfix是在validate的阶段,和现象还是有点出入,我们是在backup阶段就发生了,虽然说明很类似"。
为了严谨,我今天又去看了一下这个逻辑,按照之前的分析,backup_file_list在记录到backup_content.control之前,会删除file_size为-2的文件,因此无论如何backup_content.control都不应该包含file_size为-2的文件。因此,这样说来,可能是parray_remove()这个处理函数有问题。
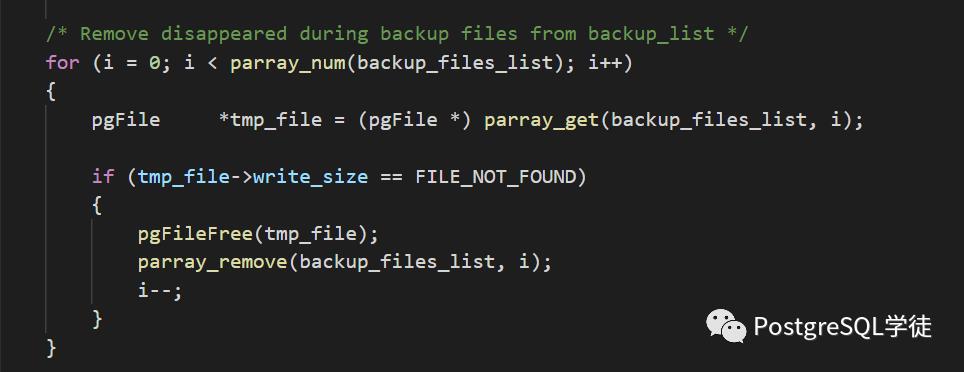
我去比较了一下2.1.3的和2.0.27的代码,发现有一个关键的不同点!这个是2.1.3的代码
这个是我们生产中的2.0.27的代码
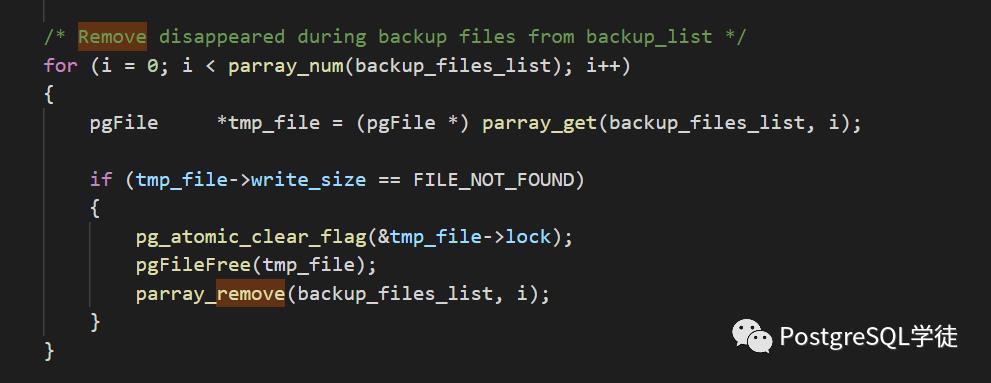
可以看到,关键点在于2.1.3多了一个i-- 的逻辑,而parray_remove()里面的逻辑完全一样。
复现
因此,我又尝试去复现了一次。总共打了4个断点
(gdb) info b
Num Type Disp Enb Address What
1 breakpoint keep y 0x00000000004107f5 in write_backup_filelist at src/catalog.c:594
breakpoint already hit 1 time
2 breakpoint keep y 0x0000000000418aee in print_file_list at src/dir.c:1236
breakpoint already hit 1 time
3 breakpoint keep y 0x0000000000407be0 in parray_remove at src/utils/parray.c:139
breakpoint already hit 38 times
6 breakpoint keep y 0x00000000004145e0 in print_file_list at src/dir.c:1243
stop only if file->write_size<-1
分别是
• parray_remove,在记录到backup_content.control之前删除size为-2的文件
• write_backup_filelist() -> print_file_list()会将备份完成的文件记录到backup_content.control里面,在parray_remove()之后
• if file->write_size<-1,表示当发现size小于-1时,就中断
最终发现了断点卡在了第6个断点处,write_size = -2,跳过了parray_remove()这个断点
(gdb) p *file
$16 = name = 0x21b485d "11040981", mode=33152, size = 2138112, read_size = 0, write_size = -2,crc = 0, linked = 0x0, is_datafile = 1 '\\001', path = 0x21b4840 "/paic/pgxxx/data/base/17030/11040981", tblspcOid = 1663, dbOid = 17030, relOid = 11040981, forkNmae = 0x21b4430 "",segno = 0, n_blocks = -1, is_cfs = 0 '\\000', is_database = 0 '\\000', exists_in_prev = 0 '\\000', compress_alg = NOT_DEFINED_COMPRESS, lock = value = 1 '\\001',pagemap = ...
(gdb) c
Continuing.
因此,说明parray_remove这个函数有BUG!那得仔细去看一下逻辑了,刚刚说了,parray_remove()的逻辑在2.1.3和2.0.27中是完全一样的,唯一的区别就是2.1.3多了一个i--。
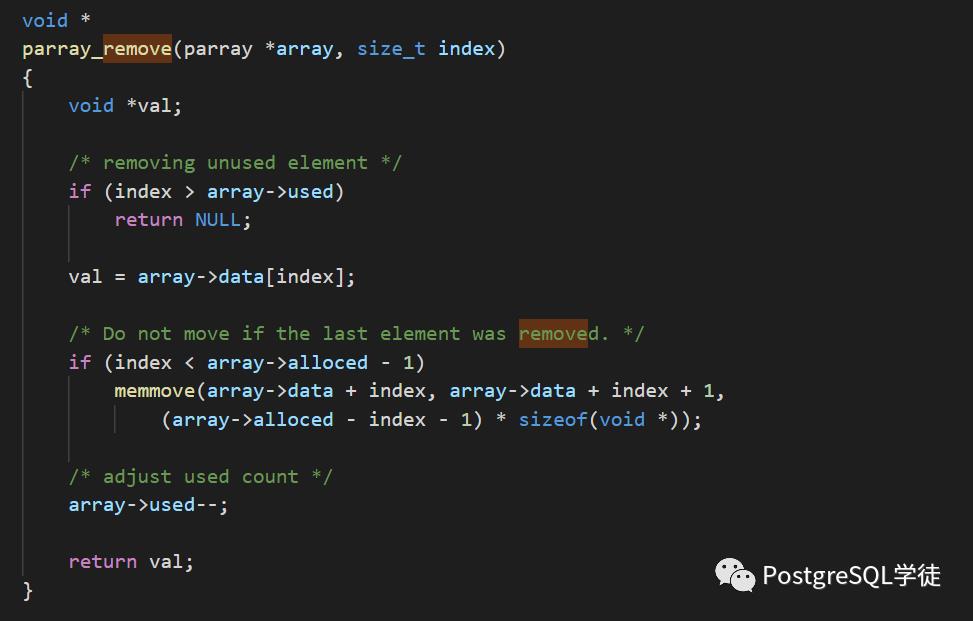
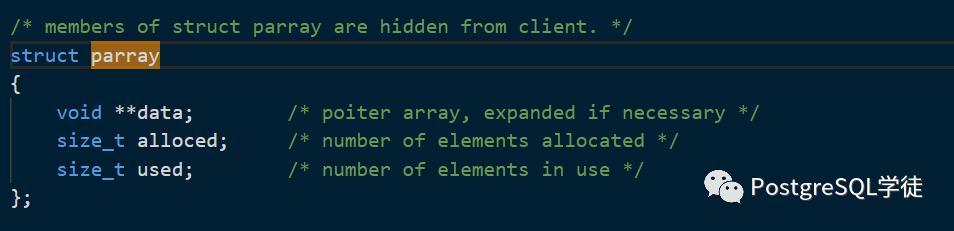
此处的index是传入的下标,而array-> used表示数组里面有多少个元素
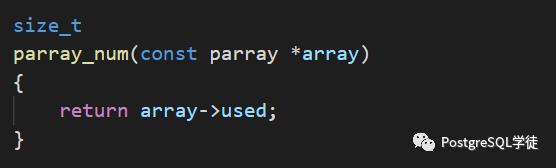
parray_num用于获取多少个元素
可以看到,每次调用memmove删除掉元素之后,数据元素array->used-- 同时减少1,而外层代码却同时又执行了i ++,相当于一次的步长是2,而在2.1.3里面,在外层又加了i--,相当于将步长又调回了1 !
这是一个致命缺陷,战斗名族也犯了如此低级的错误,因此不难想到,假如存在连续两个not found的文件,第一个被跳过了,第二个就会记录在文件中!参照今天的结果
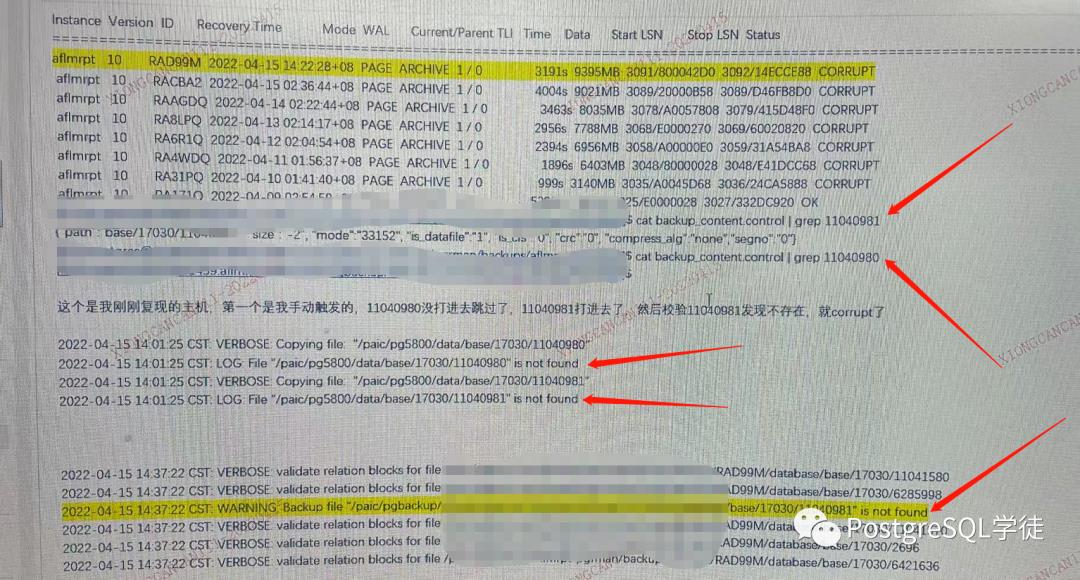
可以看到,在日志中,transfer阶段连续打印了两条日志
• "/paic/pg5800/data/base/17030/11040980" is not found
• "/paic/pg5800/data/base/17030/11040981" is not found
但是backup_content.control却只记录了11040981,相当于跳过了第一个!因为步长是2,最后在校验的时候当然只发现11040981 is not found。
因此,到这里可以解释了,为什么这个图片中,在transfer中,总共17条,backup_content.control里面只有13条,因为某些记录被跳过了!
不过既然知晓了这个报错原理,我们也可以直接hack的方式,去修改backup_content.control,将这一条记录删除即可,再次validate就会将corrupt的状态置为OK,当然你也可以直接修改backup.control中的status,不过不建议这么做。
小结
到这里,问题现象和根因彻底分析清楚了。确实之前的怀疑,即NAS丢失数据,很让人费解,丢IO这个事情谁能说得准。
通过这几天的分析,原来是2.0.27的代码BUG!因此,后续我们会选择merge较新的版本,当然也可以选择直接在我们的现有版本里添加i--的逻辑。整个过程收获颇多,一步步分析源码,在此也十分感谢 japin 和同事关于gdb的技巧指导。
以上是关于费解的备份corrupt终于搞明白了的主要内容,如果未能解决你的问题,请参考以下文章