快速解决“多分类不平衡”问题
Posted 56kb
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了快速解决“多分类不平衡”问题相关的知识,希望对你有一定的参考价值。
在机器学习中,经常会遇到分类不平衡问题。
简单来说,就是多分类时有的类别数量少,会影响整体模型的准确率。
目录
前言
我做的是一个多分类问题,特征有55列,标签1列,共有15000条数据。(由于某些原因,不方便展示数据集)
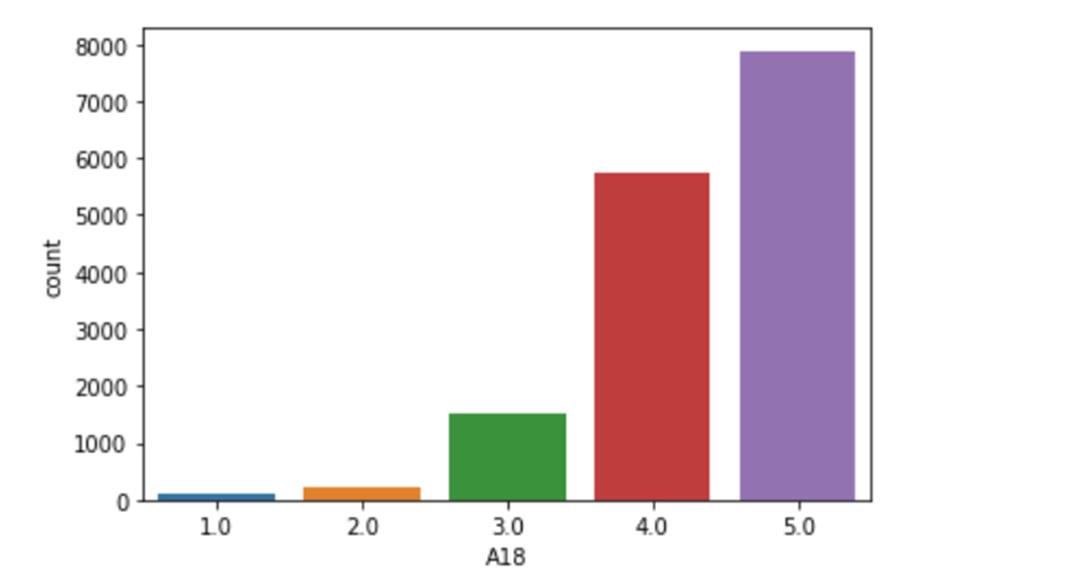
- 从上图可以明显看出,label列有五个种类:[1,2,3,4,5]
- 明显发现:1,2,3,类别相对于4,5很少,即是 典型的多分类不平衡
- 我用随机森林(RF),XGBoost,lightGBM进行训练,发现三种模型准确率最高为70%。这明显低于我的要求,为此,我以RF为例,通过调参,尝试将模型准确率提高——发现模型提高到72%左右就提升不上去了。为此,我对这个问题进一步分析······
一、问题详细描述
1.项目介绍
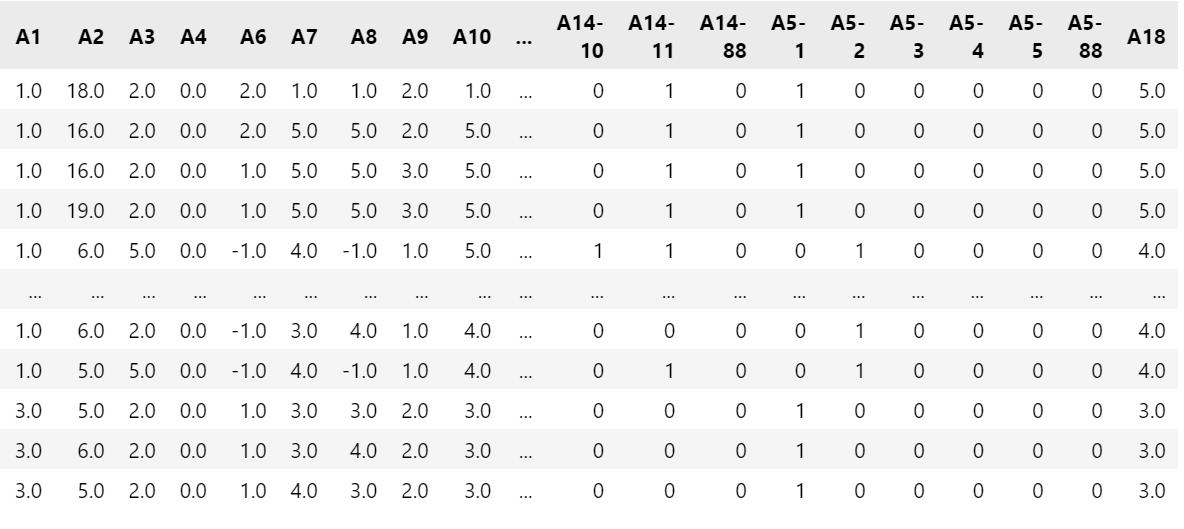
如上图,A18列是标签列,前面的都是属性列。且已经经过数据处理(无空缺值和异常值)。
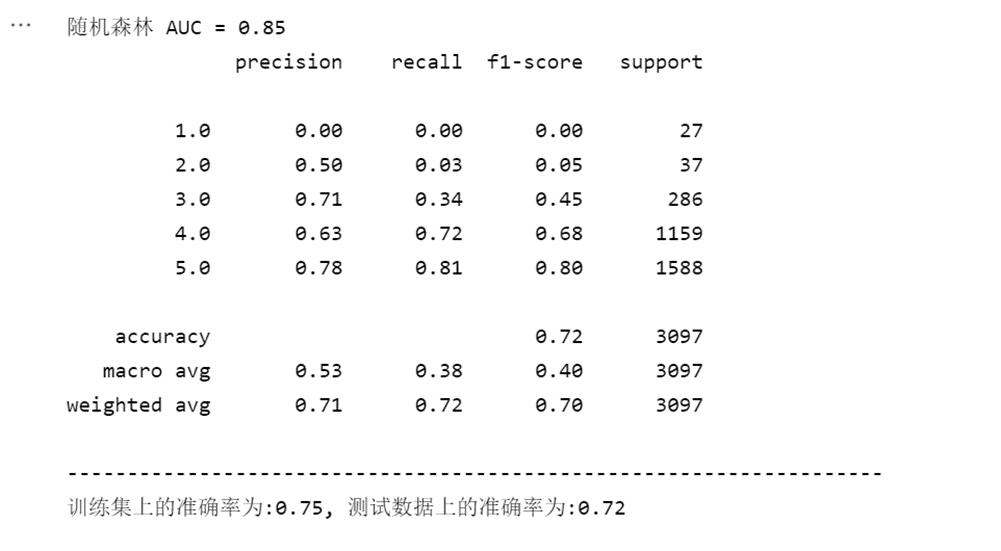 训练集、测试集比为8:2。这是我建立RF后,多次调参,所表现出的最佳性能。RF模型表明在测试集上的准确率为72%,AUC为0.85。
训练集、测试集比为8:2。这是我建立RF后,多次调参,所表现出的最佳性能。RF模型表明在测试集上的准确率为72%,AUC为0.85。
需要注意的是:对1类的accurancy、recall、f1-score的值全为0,2类和3类的数值与4、5类相差很大。
其根本原因是:测试集中1、2类数据只有几十条,反观4、5类数据 上千了。最后训练出的模型,数据的真实标签为1/2,但模型更倾向于选4/5(手动doge:我宁愿什么也不做,也不愿犯错),举个详细的例子来说,模型如果选4/5,犯错的概率是1%,但选1/2的话,犯错可能达30%。
2.调参尝试
我刚遇到这个问题的时候,以为是模型参数导致没有很好的训练,因此我根据一系列步骤 合理地调参,想法设法地提高其准确率。其调参过程如下:
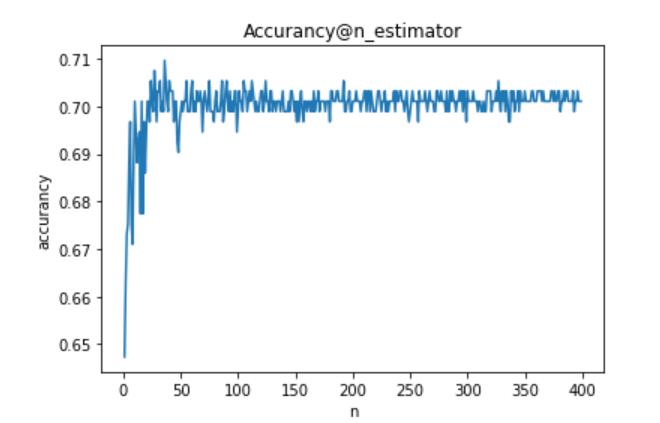
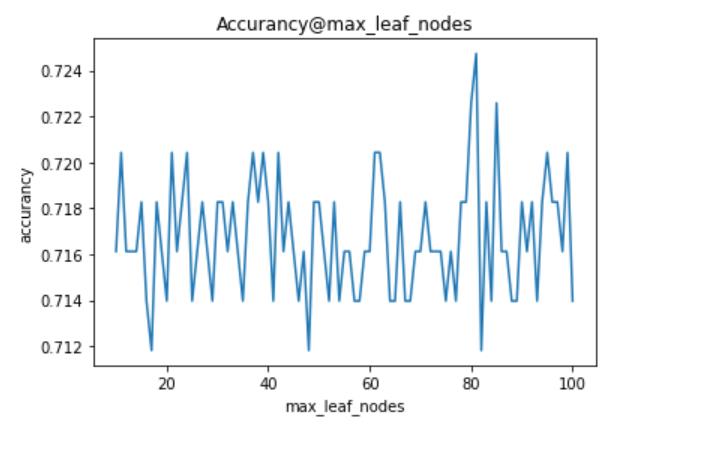
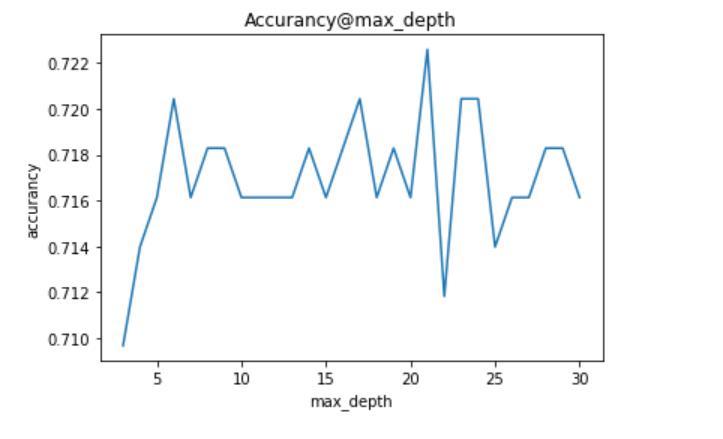
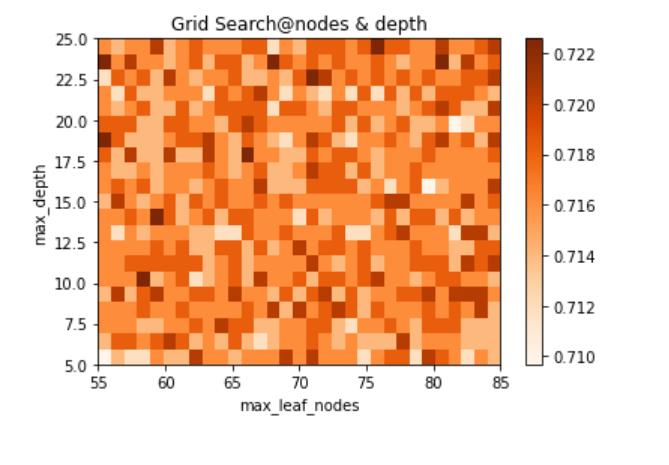
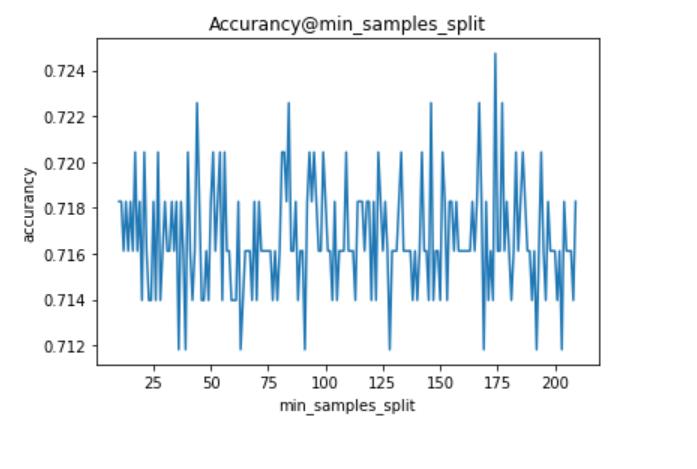
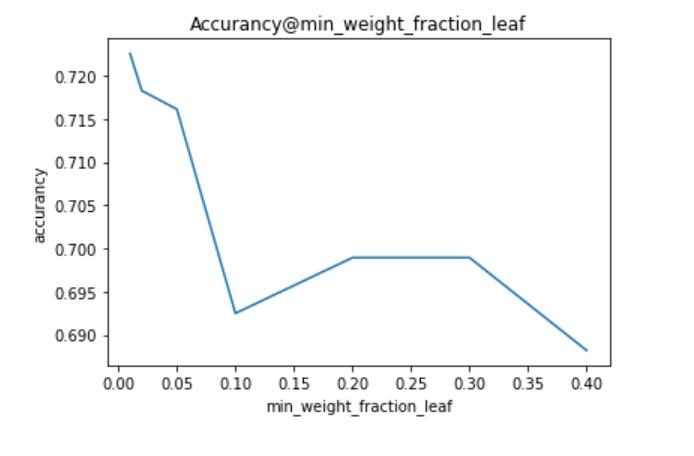
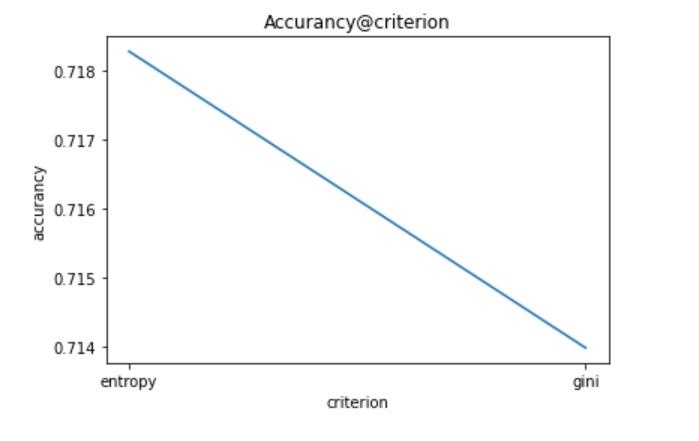
从上面可以看出,n_estimators、miin_weight_fraction_leaf、criterion具有明显规律,可以根据实际情况赋值。但其他参数不具有规律(即剧烈震荡、周期变化),表明这些参数不适合细调,应该粗调。
下面是我调试一个参数n_estimators的代码,仅供参考。
accurancyList =
'params':[],
'precision':[]
def tune_rf(Xtrain,Ytrain,parameters):
rf = RandomForestClassifier(
n_estimators = parameters['n_estimators'],
max_leaf_nodes = parameters['max_leaf_nodes'],
max_depth = parameters['max_depth'],
min_samples_split = parameters['min_samples_split'],
min_samples_leaf = parameters['min_samples_leaf'],
min_weight_fraction_leaf = parameters['min_weight_fraction_leaf'],
max_features = parameters['max_features'],
criterion = parameters['criterion']
)
# 模型训练
rf.fit(Xtrain, Ytrain)
return accuracy_score(Ytest,rf.predict(Xtest))
parameters =
'n_estimators':20,
'max_leaf_nodes':20,
'max_depth':20,
'min_samples_split':20,
'min_samples_leaf':20,
'min_weight_fraction_leaf':0.03,
'max_features':30,
'criterion':'entropy'
for n in range(1,201):
parameters['n_estimators'] = n
accurancyList['params'].append(parameters)
# 将更新后的paramseters投入训练
accurancyList['precision'].append(tune_rf(Xtrain,Ytrain,parameters))
# 绘制图像
plt.plot(range(1,201),accurancyList['precision'])
plt.xlabel('n')
plt.ylabel('accurancy')
plt.title('Accurancy@n_estimator')
plt.show()调参的大体思路:
一.确定主要参数,并通过绘制曲线(参数与Accurancy二维曲线)选定合适的区间。
二.通过网格搜索(Grid Search),找到合适的参数。
三.分析模型效果——是否过拟合,接下来调不重要的参数,来弥补模型的缺陷。
二、分析原因
1.观察稀疏矩阵
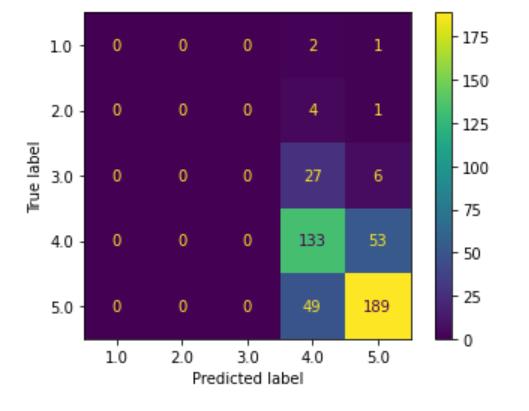
稀疏矩阵可以很好地反映多分类预测情况:明明有好几个1类别和2类别了,模型却非得预测是4或者5,可谓不让人省心。同时我们需要在这里多停留一会~~~~我们是否可以换个角度,对这类小样本数据作为异常点检测。这极大地启发了我们如何去发现这类占比极小的点(在我这个项目中,1和2表示不满意的人群),这类人群对我们有很重要的人群,我们需要找到这类人,分析不满意的原因,进而调整做法,以尽可能地减少这类人群。
2.解决方案
方案一 处理数据
1.欠采样(under-sampling):对大类的数据样本进行采样来减少该类数据样本的个数,使其与其他类数目接近,然后再进行学习。欠采样若随机丢弃大类样本,可能会丢失一些重要信息。欠采样的代表算法是EasyEnsemble,利用集成学习机制,将大类划分为若干个集合供不同的学习器使用。这样对每个学习器来看都进行了欠采样,但在全局来看却不会丢失重要信息。
2.过采样(over-sampling):过采样的代表算法是SMOTE和ADASYN。
SMOTE:通过对训练集中的小类数据进行插值来产生额外的小类样本数据。产生新的少数类样本,产生的策略是对每个少数类样本a,从它的最近邻中随机选一个样本b,然后在a、b之间的连线上随机选一点作为新合成的少数类样本。
ADASYN:基本思想是根据学习难度的不同,对不同的少数类别的样本使用加权分布,比较容易学习的少数类样本,对于难以学习的少数类的样本,产生更多的综合数据。
3.重采样特定类,通过对数据量少的种类多次采样(某种意义上将少量数据复制许多份,平衡各种类数据)。详细信息可参考下面 “求则得之,舍则失之” 博主写的文章:(104条消息) 4种改善类别不平衡的方法_求则得之,舍则失之的博客-CSDN博客_解决类别不平衡的方法
https://blog.csdn.net/weixin_43229348/article/details/119892260?spm=1001.2101.3001.6650.8&utm_medium=distribute.pc_relevant.none-task-blog-2%7Edefault%7EBlogCommendFromBaidu%7ERate-8.pc_relevant_default&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2%7Edefault%7EBlogCommendFromBaidu%7ERate-8.pc_relevant_default&utm_relevant_index=17
方案二 改进模型
1.由于项目要求,我只能使用RF,XGBoost,lightGBM三种算法进行预测。在不适用组合模型的情况下,只能原模型加入一些代码,如将一般的随机森林变成针对性的强随机森林(针对性:提高对1,2类的预测权重或者降低判定为positive的阈值),代码是辅助模型进行预测的。
2.模型搭配一些算法,即当模型给出1类概率为0.2,通过算法可以判断能否在特殊情况下支持预测为1类。或者说,通过算法限制:让模型预测至少有10个数据点选1类。这有点像在其他算法基础上改造算法。核心是:集成模型+算法 = 新模型
3.在同意使用组合模型的情况下,将RF用于去检测1,2类数据(可看作是“异常点检测”),而lightGBM和XGBoost共同去检测4和5的数据,而且可以考虑加权投票法。将集成模型用一种新的集成方法提高在数据集上的准确率。
方案三 调整评价指标
1.Accurancy直观反映模型在测试集上的表现效果。它虽然不准确,但如果题目要求是让你预测,你就必须去直面这个指标——根本方法是通过处理后的数据和好的参数训练出鲁棒性足够高的模型。这个评价指标必须保留!!!
2.混淆矩阵、ROC曲线、AUC是特别公平的指标,它刻画了模型的综合效果,最大的问题在于这些指标和Accurancy没有强关联性,即AUC高的模型准确率低,在模型训练的时候需要注意。而且,集成模型的AUC还是很Nice的!!
3.根据实际要求(例如特别关注1,2类人群),使用新的自制的评价指标。提高对这些人群的查找及权重,从而对整体数据预测的均衡和准确率。
我最近想到了以上的解决方案,具体代码还在测试中~~~~。先挖一个坑,下次补上。
总结
- 多分类问题尤其需要考虑类别是否平衡,这种不平衡会带来什么后果。
- 单纯的Accurancy指标是否能够正确反映模型在多分类上的表现情况。能否自制一个评估函数feval来有效地评估在模型的好坏。
- 是模型参数没有调好还是数据量少/不平衡导致模型效果一般?对应的问题该怎么解决(看上面解决方案)。
- 最后分析总结:从调参中、增强模型中学到了什么:调参经验,分析问题的能力等。
最后补充一些我的一些思考:
@模型调参的过程是构造一个函数F(theta1,theta2,theta3···)=Accurancy,输出值可以是准确率,参数是随机森林的参数(以随机森林举例)。调参的本质是通过修改参数值,降低函数值——>转化成了 最优化 问题。而且,不能使用最优化常用的梯度下降(难以求得梯度)法。
@集成方法是框架,模型融合是方式,我们可以把集成模型融合起来而不是再次集成。因为影响准确率的原因不是模型不好,而是在这种多分类不平衡的情况下,“集成”更倾向于犯错小的方向,因此,必须选用与集成对立的算法融合起来,才能将错误的分类给拉回来。
 创作挑战赛
创作挑战赛
 新人创作奖励来咯,坚持创作打卡瓜分现金大奖
新人创作奖励来咯,坚持创作打卡瓜分现金大奖
以上是关于快速解决“多分类不平衡”问题的主要内容,如果未能解决你的问题,请参考以下文章
大数据分析!广西快速锁定重点人群21万人,发现确诊病例138例