密码学维吉尼亚密码加解密原理及其破解算法Java实现
Posted remo0x
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了密码学维吉尼亚密码加解密原理及其破解算法Java实现相关的知识,希望对你有一定的参考价值。
代码已上传到 GitHub —— Vigenere.java
1 维吉尼亚密码方阵
人们在恺撒移位密码的基础上扩展出多表密码,称为维吉尼亚密码。该方法最早记录在吉奥万·巴蒂斯塔·贝拉索( Giovan Battista Bellaso)于1553年所著的书《吉奥万·巴蒂斯塔·贝拉索先生的密码》

第一行代表明文字母,第一列代表密钥字母,它的明码表后有26个密码表,每个表相对前一个发生一次移位。
如果只用其中某一个进行加密,那么只是简单的恺撒移位密码。但用方阵中不同的行加密不同的字母,它就是一种强大的密码了。
加密者可用第7行来加密第一个字母,再用第25行来加密第二个字母,然后根据第8行来加密第三个字母等。
2 使用维吉尼亚密码
维吉尼亚密码引入了“密钥”的概念,即根据密钥来决定用哪一行的密表来进行替换,以此来对抗字频统计
2.1 加密
1.确定密钥
首先,和消息接收方需要在密钥上达成一致,加密解密都是同一个密钥,比如选用BIG。
2.排列明文
把明文转换为大写字母排列出来,对应着重复排列密钥,直到明文结尾:
明文:THE BUTCHER THE BAKER AND THE CANDLESTICK MAKER
密钥:BIG BIGBIGB IGB IGBIG BIG BIG BIGBIGBIGBI GBIGB
3.加密明文
然后,每一组的两个字母就成了我们的坐标。在维吉尼亚坐标图中分别横向纵向找出它们。横坐标和纵坐标的交点就是加密后的字母。
比如例子中的第一个字母是T,它下面是B,在维吉尼亚密码表中第一行找到T,第一列中找到B,所以得到的它们的交点就是U:
明文:THE BUTCHER THE BAKER AND THE CANDLESTICK MAKER
密钥:BIG BIGBIGB IGB IGBIG BIG BIG BIGBIGBIGBI GBIGB
密文:UPK CCZDPKS BNF JGLMX BVJ UPK DITETKTBODS SBSKS
2.2 解密
1.排列密文
和加密一样,把密文排列出来,在下面对应着重复排列密钥:
密文:UPK CCZDPKS BNF JGLMX BVJ UPK DITETKTBODS SBSKS
密钥:BIG BIGBIGB IGB IGBIG BIG BIG BIGBIGBIGBI GBIGB
2.解密密文
解密就是加密的逆过程,比如第一个字母是U,下面是B,找到B开头的那一行,在该行中找到U,得到的明文字母就是那一列的开头字母T:
密文:UPK CCZDPKS BNF JGLMX BVJ UPK DITETKTBODS SBSKS
密钥:BIG BIGBIGB IGB IGBIG BIG BIG BIGBIGBIGBI GBIGB
明文:THE BUTCHER THE BAKER AND THE CANDLESTICK MAKER
3. 破解维吉尼亚密码
3.1 确定密钥长度m
3.1.1 Kasiski测试法
Kasiski测试法是由Friedrich Kasiski于1863年给出了其描述,然而早在约1854年这一方法就由Charles Babbage首先发现。它主要基于这样一个事实:两个相同的明文段将加密成相同的密文段,它们的位置间距假设为δ,则δ≡0(mod m)。反过来,如果在密文中观察到两个相同的长度至少为3的密文段,那么将给破译者带来很大方便,因为它们实际上对应了相同的明文串。
使用流程
搜索长度至少为3的相同的密文段,记下其离起始点的那个密文段的距离。假如得到如下几个距离δ₁,δ₂,...,那么,可以猜测m为这些δi的最大公因子的因子。
使用实例
密钥:FORESTFORESTFORESTFORESTFOR
明文:better to do well than to say well
密文: GSKXWKYCUSOXQZKLSGYCJEQPJZC
第一个YC出现后到第二个YC的结尾一共有12个字母,那么密钥的长度应是12的约数1,2,3,4,6,12之中的一个。
当密文很长的时候,可以找出几组重复的密文段,找出它们间距的相同约数,就是密钥长度。
3.1.2 重合指数法
重合指数(Index of Coincidence)
设x=x1x2...xn是一条n个字母的串,x的重合指数记为CI,定义为x中两个随机元素相同的概率。
定义公式:
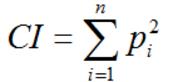
常用公式:xi为字母的频数,L为密文的长度
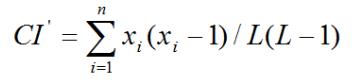
字母在英语文本中出现的概率:
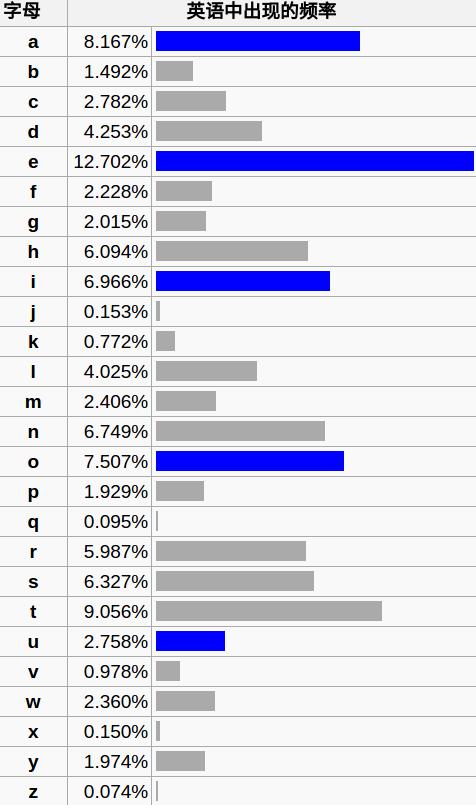
对英语而言,根据上述的频率表,我们可以计算出英语文本的重合指数为P(A)^2 + P(B)^2+……+P(Z)^2 = 0.065。
利用重合指数推测密钥长度的原理在于,对于一个由凯撒密码加密的序列,由于所有字母的位移程度相同,所以密文的重合指数应等于原文语言的重合指数
使用重合指数法
假设使用维吉尼亚密码加密的密文串为y=y1y2...yn。将串y分割成m个长度相等的子串,分别为y1,y2,...,ym,这样就可以以列的形式写出密文,组成一个m×(n/m)矩阵。矩阵的每一行对应于子串yi,1≤i≤m。
举例来说:
密文ABCDEABCDEABCDEABC
按m=2分组,则每组为:
组1:A C E B D A C E B
组2:B D A C E B D A C
如果y1,y2,...,ym按如上方式构造,则m实际上就是密钥字的长度,每一组的CI值大约为0.065。另外,如果m不是密钥字的长度,那么子串yi看起来更为随机,因为它们是通过不同密钥以移位加密方式获得的。对于一个随机串,其重合指数为0.038。
代码实现
重合指数法实现代码如下:
// Friedman测试法确定密钥长度
public int Friedman(String ciphertext)
int keyLength = 1; // 猜测密钥长度
double[] Ic; // 重合指数
double avgIc; // 平均重合指数
ArrayList<String> cipherGroup; // 密文分组
while (true)
Ic = new double[keyLength];
cipherGroup = new ArrayList<>();
avgIc = 0;
// 1 先根据密钥长度分组
for (int i = 0; i < keyLength; ++i)
StringBuilder tempGroup = new StringBuilder();
for (int j = 0; i + j * keyLength < ciphertext.length(); ++j)
tempGroup.append(ciphertext.charAt(i + j * keyLength));
cipherGroup.add(tempGroup.toString());
// 2 再计算每一组的重合指数
for (int i = 0; i < keyLength; ++i)
String subCipher = cipherGroup.get(i); // 子串
HashMap<Character, Integer> occurrenceNumber = new HashMap<>(); // 字母及其出现的次数
// 2.1 初始化字母及其次数键值对
for (int h = 0; h < 26; ++h)
occurrenceNumber.put((char) (h + 65), 0);
// 2.2 统计每个字母出现的次数
for (int j = 0; j < subCipher.length(); ++j)
occurrenceNumber.put(subCipher.charAt(j), occurrenceNumber.get(subCipher.charAt(j)) + 1);
// 2.3 计算重合指数
double denominator = Math.pow((double) subCipher.length(), 2);
for (int k = 0; k < 26; ++k)
double o = (double) occurrenceNumber.get((char) (k + 65));
Ic[i] += o * (o - 1);
Ic[i] /= denominator;
// 3 判断退出条件,重合指数的平均值是否大于0.065
for (int i = 0; i < keyLength; ++i)
avgIc += Ic[i];
avgIc /= (double) keyLength;
if (avgIc >= 0.06)
break;
else
keyLength++;
// while--end
// 打印密钥长度,分组,重合指数,平均重合指数
System.out.println("密钥长度为:" + String.valueOf(keyLength));
System.out.println("\\n密文分组及其重合指数为:");
for (int i = 0; i < keyLength; ++i)
System.out.println(cipherGroup.get(i) + " 重合指数: " + Ic[i]);
System.out.println("\\n平均重合指数为: " + String.valueOf(avgIc));
return keyLength;
// Friedman--end
3.2 确定密钥
3.2.1 拟重合指数测试法
在知道了密钥长度n以后,就可将密文分解为n组,每一组都是一个凯撒密码,然后对每一组用字母频度分析进行解密,和在一起就能成功解密凯撒密码。
首先对子密文段重各个字母的频率进行统计(记为fi, i∈a – z),查看字母频率分布统计概率表(记pi),计算子密文段长度为n,使用公式:
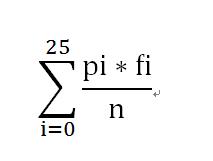
计算出M0,然后对子密文段移位25次,同样按照上述方法求出M1 — M25的值。
根据重合指数的定义知:一个有意义的英文文本,M ≈0.065,所以找出M值接近0.065的移位数,就是秘钥中的对应字母。
拟重合指数测试法的实现代码如下:
// 再次使用重合指数法确定密钥
public void decryptCipher(int keyLength, String ciphertext)
int[] key = new int[keyLength];
ArrayList<String> cipherGroup = new ArrayList<>();
double[] probability = new double[]0.082, 0.015, 0.028, 0.043, 0.127, 0.022, 0.02, 0.061, 0.07, 0.002, 0.008,
0.04, 0.024, 0.067, 0.075, 0.019, 0.001, 0.06, 0.063, 0.091, 0.028, 0.01, 0.023, 0.001, 0.02, 0.001;
// 1 先根据密钥长度分组
for (int i = 0; i < keyLength; ++i)
StringBuilder temporaryGroup = new StringBuilder();
for (int j = 0; i + j * keyLength < ciphertext.length(); ++j)
temporaryGroup.append(ciphertext.charAt(i + j * keyLength));
cipherGroup.add(temporaryGroup.toString());
// 2 确定密钥
for (int i = 0; i < keyLength; ++i)
double MG; // 重合指数
int flag; // 移动位置
int g = 0; // 密文移动g个位置
HashMap<Character, Integer> occurrenceNumber; // 字母出现次数
String subCipher; // 子串
while (true)
MG = 0;
flag = 65 + g;
subCipher = cipherGroup.get(i);
occurrenceNumber = new HashMap<>();
// 2.1 初始化字母及其次数
for (int h = 0; h < 26; ++h)
occurrenceNumber.put((char) (h + 65), 0);
// 2.2 统计字母出现次数
for (int j = 0; j < subCipher.length(); ++j)
occurrenceNumber.put(subCipher.charAt(j), occurrenceNumber.get(subCipher.charAt(j)) + 1);
// 2.3 计算重合指数
for (int k = 0; k < 26; ++k, ++flag)
double p = probability[k];
flag = (flag == 91) ? 65 : flag;
double f = (double) occurrenceNumber.get((char) flag) / subCipher.length();
MG += p * f;
// 2.4 判断退出条件
if (MG >= 0.055)
key[i] = g;
break;
else
++g;
// while--end
// for--end
// 3 打印密钥
StringBuilder keyString = new StringBuilder();
for (int i = 0; i < keyLength; ++i)
keyString.append((char) (key[i] + 65));
System.out.println("\\n密钥为: " + keyString.toString());
// 4 解密
StringBuilder plainBuffer = new StringBuilder();
for (int i = 0; i < ciphertext.length(); ++i)
int keyFlag = i % keyLength;
int change = (int) ciphertext.charAt(i) - 65 - key[keyFlag];
char plainLetter = (char) ((change < 0 ? (change + 26) : change) + 65);
plainBuffer.append(plainLetter);
System.out.println("\\n明文为:\\n" + plainBuffer.toString().toLowerCase());
4 算法运行实例
密文如下:
KCCPKBGUFDPHQTYAVINRRTMVGRKDNBVFDETDGILT
XRGUDDKOTFMBPVGEGLTGCKQRACQCWDNAWCRXI
ZAKFTLEWRPTYCQKYVXCHKFTPONCQQRHJVAJUWE
TMCMSPKQDYHJVDAHCTRLSVSKCGCZQQDZXGSFRL
SWCWSJTBHAFSIASPRJAHKJRJUMVGKMITZHFPDISP
ZLVLGWTFPLKKEBDPGCEBSHCTJRWXBAFSPEZQNR
WXCVYCGAONWDDKACKAWBBIKFTIOVKCGGHJVLNHI
FFSQESVYCLACNVRWBBIREPBBVFEXOSCDYGZWPFD
TKFQIYCWHJVLNHIQIBTKHJVNPIST
运行结果如下:
密钥长度为:6
密文分组及其重合指数为:
KGQNGVGGTGCQWAWQHNJEPJTKQFWAPJGHPWKCTAQVNCIVJFVNIVCPQJQJT 重合指数: 0.061557402277623886
CUTRRFIUFEKCCKRKKCVTKVRCDRSFRRKFZTEEJFNYWKKKVFYVRFDFIVIV 重合指数: 0.08227040816326531
CFYRKDLDMGQWRFPYFQAMQDLGZLJSJJMPLFBBRSRCDAFCLSCREEYDYLBN 重合指数: 0.04846938775510204
PDATDETDBLRDXTTVTQJCDASCXSTIAUIDVPDSWPWGDWTGNQLWPXGTCNTP 重合指数: 0.06377551020408163
KPVMNTXKPTANILYXPRUMYHVZGWBAHMTILLPHXEXAKBIGHEABBOZKWHKI 重合指数: 0.042091836734693876
BHIVBDROVGCAZECCOHWSHCSQSCHSKVZSGKGCBZCOABOHISCBBSWFHIHS 重合指数: 0.07206632653061225
平均重合指数为: 0.061705145277563156
密钥为: CRYPTO
明文为(手动分词):
i learned how to calculate the amount of paper needed for a
room when i was at school you multiply the square foot age
of the walls by the cubic contents of the floor and ceiling
combined and double it you then allow half the total for
openings such as windows and doors then you allow the
other half for matching the pattern then you double the
whole thing again to give a margin of error and then you
order the paper
以上是关于密码学维吉尼亚密码加解密原理及其破解算法Java实现的主要内容,如果未能解决你的问题,请参考以下文章