Elasticsearch入门 简介及部署
Posted 虎鲸不是鱼
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Elasticsearch入门 简介及部署相关的知识,希望对你有一定的参考价值。
Elasticsearch入门(一) 简介及部署
简介
传统的索引是根据id查取内容(例如:mysql的索引),RDBMS负载量很小。专业的搜索引擎是按照内容查id(倒排索引)。ElasticSearch吸收了前2代工具(Lucene、Solr)的优点,自己实现集群管理(不需要依赖Zookeeper),实现了类似Zookeeper的分布式管理机制Zen-discovery机制。接口友好,主要功能是搜索引擎,其余功能通过插件实现。
官网:
对新手很友好,是中文页面。可以在上方的学习找到文档,会自动跳转到官方指导手册,往下翻:

还有中文版官方指导,还有中文版官方指导手册。
Elastic Stack包含了4大组件:
ElasticSearch:搜索引擎工具(分布式存储、分布式分析计算)
Logstash:用于实现数据采集(重量级数据采集,功能比Flume多:文件、数据流、数据库)
Kibana:可视化工具(专门为ES设计的可视化工具,搭配ES使用)
Beats:轻量级数据采集(功能相对来说单一化,简单并且性能很好)
所有搜索引擎的场景都可以使用Elastic Stack来实现,但是主要还是用于日志搜索引擎。
ES是分布式的(高可用、可扩展、高性能),NTR(近实时的分布式存储系统。。。和嵌入式的各种RTOS真实时不同),全文索引(任何东西写入ES以后,都会自动创建索引)。
| 对比项目 | Redis | HBASE | Kafka | ES |
|---|---|---|---|---|
| 实时性 | 实时 | 实时 | 实时 | 近实时 |
| 存储 | 内存 | 内存+硬盘 | 内存+硬盘 | 内存+硬盘 |
| 功能 | NoSQL数据库 | NoSQL数据库 | 消息队列 | 全文索引 |
| 适用场景 | 大数据量缓存 | 大数据量持久存储 | 大数据量缓存 | 大数据量持久化存储 |
ES存储结构
| 对比项 | HDFS | HBASE | Kafka | ES |
|---|---|---|---|---|
| 第一层划分 | 目录 | NameSpace | X | Index |
| 第二层划分 | 文件 | Table | Topic | Type(7.0后的新版没有) |
| 存储分区 | 分块Block | 范围Region | 分区:Partition | Shard |
| 分区安全 | 副本机制 | WAL+副本机制(就近原则) | 副本机制:Leader+Follower | 副本机制:Replicas(Leader+Follower) |
| 存储单元 | 行 | Rowkey+Store列 | Segment(行根据Offset计算偏移量) | docId + data(fields) |
| 架构 | 主从架构:NameNode+DataNode | 主从架构:Master+RegionServer | 主从架构:Crontroler+Broker | 主从架构:Master + Worker |
| HA | 2个NameNode+Zookeeper | 两个Master+Zookeeper | Zookeeper | Zen-discovery |
才学浅疏。。。
部署
准备工作
新建用户
Elasticsearch严禁使用root用户操作。。。只好先创建专门的普通用户:
useradd esuser
passwd esuser
3台机都用root用户执行,都创建ES的用户。。。自己玩,为了方便,设置密码和用户名相同。。。密码输入两次esuser就可以成功,不用管警告。
为了方便管理文件,创建ES的目录并设置关联组:
mkdir -p /export/server/es
chown -R esuser:esuser /export/server/es
3台节点都需要设置,并检查是否成功:
[root@node1 ~]# ll /export/server/
总用量 8
drwxr-xr-x 2 esuser esuser 6 6月 2 16:49 es
虽然ES不能用root用户操作,但是专用用户需要sudo权限才能运行,就很神奇:
visudo
和VIM编辑器用法差不多,100gg跳转,在100行附近可以看到:
root ALL=(ALL) ALL
就在下一行按o插入:
esuser ALL=(ALL) NOPASSWD:ALL
这句的意思是:
用户名 所有登录的机器=(所有用户) 免密:所有命令
记得wq保存。有权限后就可以按照这种格式执行命令:
sudo vim /etc/profile
免密钥
为了方便使用,在Secure CRT中单独配置esuser的连接:
偷懒的做法是直接复制一份,右键→属性→SSH2→用户名修改为esuser。密码和之前root用户密码不一致,肯定是连不上的,连接失败就会提示输入密码,就可以实现在Secure CRT中使用esuser用户远程连接Linux虚拟机。
ES集群是不需要依赖Zookeeper的,有自己的方式。root用户的免密钥配置对esuser用户不生效。。。先配置esuser用户的免密钥,让3台虚拟机实现互通:
ssh-keygen -t rsa
点3下回车键即可生成密钥。。。接下来分发密钥,偷懒的做法是使用Send commands to all sessions:
ssh-copy-id node1
ssh-copy-id node2
ssh-copy-id node3
由于此时笔者还开着root的会话,不得已用“勤奋”的方式在3台机手动执行。。。还需要输入密码。。。9次输入yes和9次输入esuser密码,吐了。。。完成后需要测试:
[esuser@node3 ~]$ ssh 'node2'
Last login: Wed Jun 2 17:05:51 2021 from 192.168.88.1
[esuser@node2 ~]$ exit
登出
Connection to node2 closed.
正常情况1个成功说明9个都成功。。。
修改资源配置
Linux默认的连接资源限制的很少,文件句柄数很容易不够用,设置大一点防止报错:
sudo vi /etc/security/limits.conf
3台机都需要末尾添加(*不能少):
* soft nofile 65536
* hard nofile 131072
* soft nproc 4096
* hard nproc 4096
记得保存。。。之前配置过就不用重新配置了。。。
3台机都需要修改系统配置:
sudo sed -i '/^#DefaultLimitNOFILE=/aDefaultLimitNOFILE=4096' /etc/systemd/system.conf
sudo sed -i '/^#DefaultLimitNPROC=/aDefaultLimitNPROC=4096' /etc/systemd/system.conf
这2条命令是在这个系统配置文件夹添加了这2个配置:
#DefaultLimitNOFILE=
DefaultLimitNOFILE=4096
#DefaultLimitAS=
#DefaultLimitNPROC=
DefaultLimitNPROC=4096
自己VIM手动添加也可以。。。
最后还需要配置虚拟内存:
sudo sysctl -w vm.max_map_count=262144
这是临时方案。。。最好配成永久的:
sudo vim /etc/sysctl.conf
添加:
vm.max_map_count=262144
保存后检查是否成功:
sudo sysctl -a | grep "vm.max_map_count"
[esuser@node1 ~]$ sudo sysctl -a | grep "vm.max_map_count"
sysctl: reading key "net.ipv6.conf.all.stable_secret"
sysctl: reading key "net.ipv6.conf.default.stable_secret"
sysctl: reading key "net.ipv6.conf.ens33.stable_secret"
sysctl: reading key "net.ipv6.conf.lo.stable_secret"
vm.max_map_count = 65530
[esuser@node1 ~]$ sysctl -p
sysctl: permission denied on key 'vm.max_map_count'
[esuser@node1 ~]$ sudo sysctl -a | grep "vm.max_map_count"
sysctl: reading key "net.ipv6.conf.all.stable_secret"
sysctl: reading key "net.ipv6.conf.default.stable_secret"
sysctl: reading key "net.ipv6.conf.ens33.stable_secret"
sysctl: reading key "net.ipv6.conf.lo.stable_secret"
vm.max_map_count = 65530
遇到这种问题,reboot是永远的神:
[esuser@node3 ~]$ sudo sysctl -a | grep "vm.max_map_count"
sysctl: reading key "net.ipv6.conf.all.stable_secret"
sysctl: reading key "net.ipv6.conf.default.stable_secret"
sysctl: reading key "net.ipv6.conf.ens33.stable_secret"
sysctl: reading key "net.ipv6.conf.lo.stable_secret"
vm.max_map_count = 262144
准备工作终于做完了。。。
ES部署
安装单机
cd ~
rz
tar -zxvf elasticsearch-7.6.1-linux-x86_64.tar.gz -C /export/server/es/
cd /export/server/es/
ll
修改配置
cd /export/server/es/elasticsearch-7.6.1/
vim config/elasticsearch.yml
里边的内容全部#注释掉了,可以:
ggVG #全选vim编辑器内的内容
dG #删除全选的全部内容
留着可能有用,故笔者直接在末尾插入:
cluster.name: test-es
node.name: node1
path.data: /export/server/es/elasticsearch-7.6.1/data
path.logs: /export/server/es/elasticsearch-7.6.1/log
network.host: node1
http.port: 9200
discovery.seed_hosts: ["node1", "node2", "node3"]
cluster.initial_master_nodes: ["node1", "node2"]
bootstrap.system_call_filter: false
bootstrap.memory_lock: false
http.cors.enabled: true
http.cors.allow-origin: "*"
保存后,修改JVM配置文件:
vim config/jvm.options
在22和23行修改:
-Xms3g
-Xmx3g
配置为虚拟机一半的内存(笔者虚拟机配置了6G内存)并保存。
分发
cd /export/server/es/
scp -r elasticsearch-7.6.1/ node2:$PWD
scp -r elasticsearch-7.6.1/ node3:$PWD
在node2和node3中:
cd /export/server/es/elasticsearch-7.6.1/
vim config/elasticsearch.yml
末尾这2条修改为node2和node3:
node.name: node3 #node2修改为node2
network.host: node3 #node2修改为node2
有可能出现:
[esuser@node3 bin]$ elasticsearch
future versions of Elasticsearch will require Java 11; your Java version from [/export/server/jdk1.8.0_241/jre] does not meet this requirement
这种情况把进程直接kill -9 进程号杀掉,重启进程即可,问题不大。。。
启动
由于ES是前台运行的程序,会“霸占”命令行,所以:
cd /export/server/es/elasticsearch-7.6.1/
/export/server/es/elasticsearch-7.6.1/bin/elasticsearch >>/dev/null 2>&1 &
将输出重定向到黑洞,>覆盖或者>>追加都可以,没什么区别。
三台机都需要手动启动,得等一会儿。。。jps看到进程Elasticsearch后可以尝试浏览器打开node1:9200:
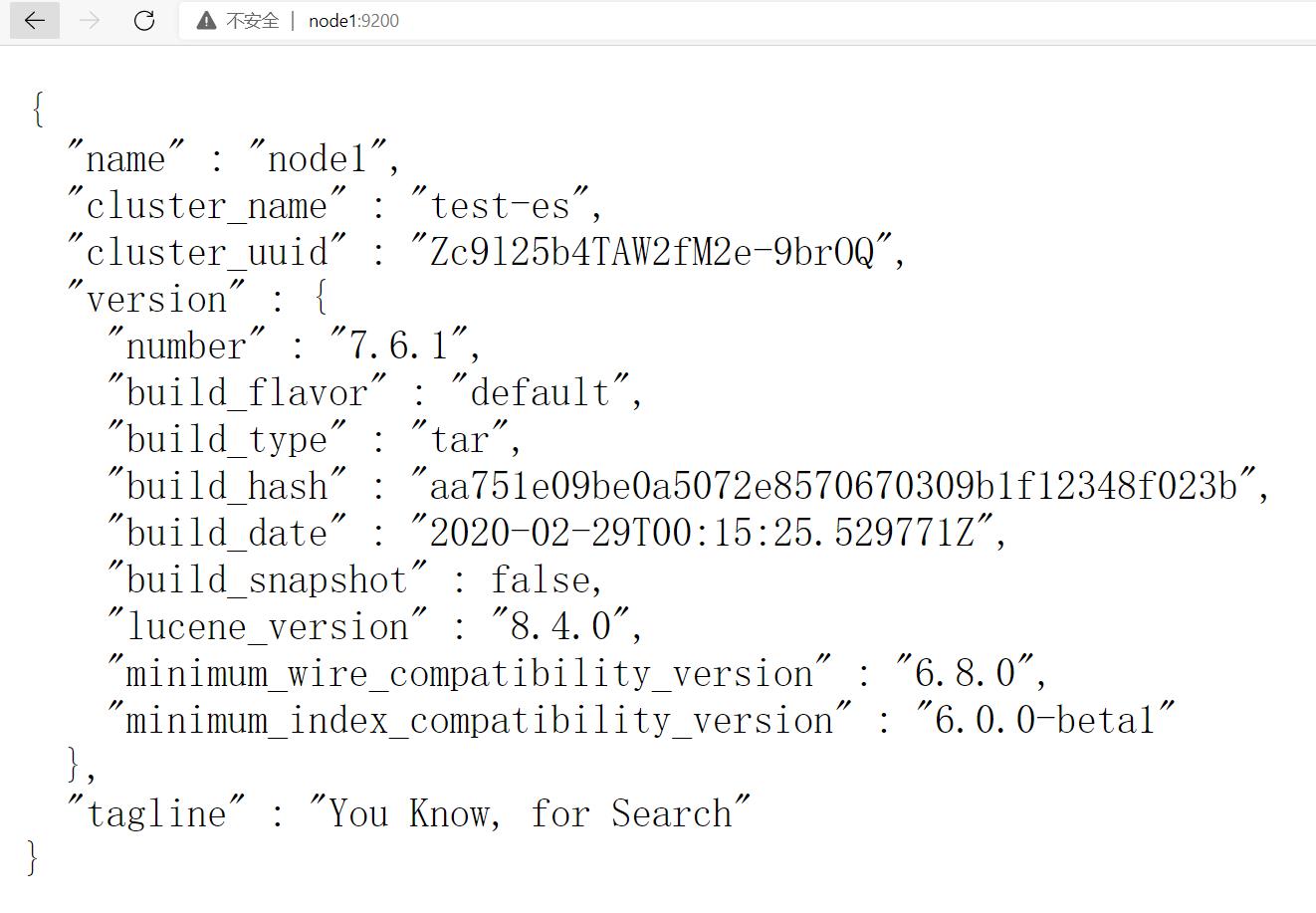
也可以查看node2和node3。。。但是并没有神马卵用。。。
不需要可以kill -9。
es-head部署
es-head是Web GUI,可以方便用户进行操作。
配置依赖
先下载node.js:
cd ~
wget https://npm.taobao.org/mirrors/node/v8.1.0/node-v8.1.0-linux-x64.tar.gz
tar -zxvf node-v8.1.0-linux-x64.tar.gz -C /export/server/es/
创建软连接:
sudo ln -s /export/server/es/node-v8.1.0-linux-x64/lib/node_modules/npm/bin/npm-cli.js /usr/local/bin/npm
sudo ln -s /export/server/es/node-v8.1.0-linux-x64/bin/node /usr/local/bin/node
配置环境变量:
sudo vim /etc/profile
export NODE_HOME=/export/server/es/node-v8.1.0-linux-x64
export PATH=:$PATH:$NODE_HOME/bin
source /etc/profile #刷新环境变量
检查是否成功:
[esuser@node1 ~]$ node -v
v8.1.0
[esuser@node1 ~]$ npm -v
5.0.3
安装单机
node1中:
cd ~
rz
tar -zxvf elasticsearch-head-compile-after.tar.gz -C /export/server/es/
修改配置
vim /export/server/es/elasticsearch-head/Gruntfile.js
使用93gg跳转到93行附近,修改:
hostname: 'node1',
port: 9100,
保存后:
vim /export/server/es/elasticsearch-head/_site/app.js
使用4354gg跳转,修改:
this.base_uri = this.config.base_uri || this.prefs.get("app-base_uri") || "http://node1:9200";
启动
由于这货也是前台运行,为了防止霸占shell,需要输出重定向:
/export/server/es/elasticsearch-head/node_modules/grunt/bin/grunt server >/dev/null 2>&1 &
、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、
2021.6.3更新:
这玩意儿比较特殊。。。绝对路径启动不一定都能成功。。。
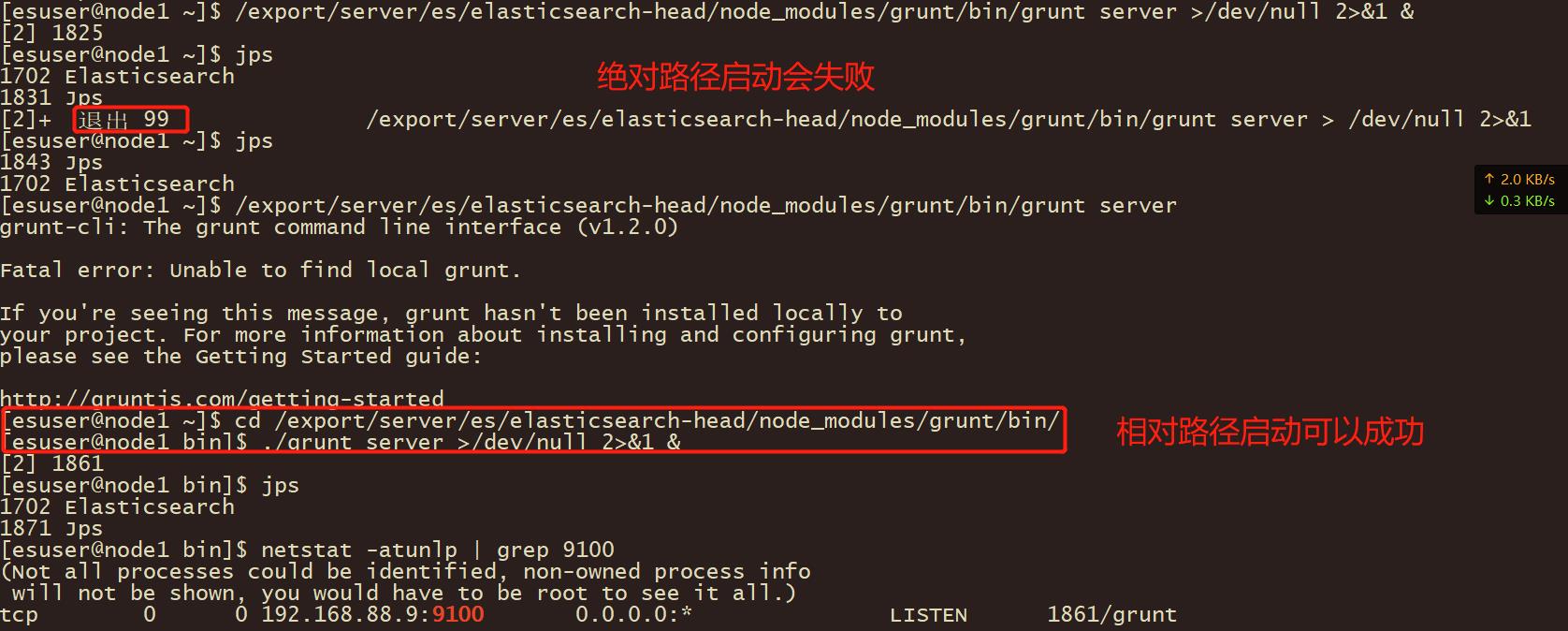
发现启动失败:
1943 Jps
1741 Elasticsearch
[2]+ 退出 99 /export/server/es/elasticsearch-head/node_modules/grunt/bin/grunt server > /dev/null 2>&1
[esuser@node1 ~]$ /export/server/es/elasticsearch-head/node_modules/grunt/bin/grunt server >/dev/null 2>&1 &
[2] 1955
[esuser@node1 ~]$ /export/server/es/elasticsearch-head/node_modules/grunt/bin/grunt server >/dev/null 2>&1 &
[3] 1961
[2] 退出 99 /export/server/es/elasticsearch-head/node_modules/grunt/bin/grunt server > /dev/null 2>&1
[esuser@node1 ~]$ /export/server/es/elasticsearch-head/node_modules/grunt/bin/grunt server
grunt-cli: The grunt command line interface (v1.2.0)
Fatal error: Unable to find local grunt.
If you're seeing this message, grunt hasn't been installed locally to
your project. For more information about installing and configuring grunt,
please see the Getting Started guide:
http://gruntjs.com/getting-started
[3]+ 退出 99 /export/server/es/elasticsearch-head/node_modules/grunt/bin/grunt server > /dev/null 2>&1
报错:Unable to find local grunt.
使用相对路径启动更合适:
cd /export/server/es/elasticsearch-head/node_modules/grunt/bin/
#后台启动
./grunt server >/dev/null 2>&1 &
#查看进程
netstat -atunlp | grep 9100
、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、
查看进程:
[esuser@node1 elasticsearch-head]$ netstat -atunlp | grep 9100
(Not all processes could be identified, non-owned process info
will not be shown, you would have to be root to see it all.)
tcp 0 0 192.168.88.9:9100 0.0.0.0:* LISTEN 7693/grunt
启动后可以浏览器node1:9100:
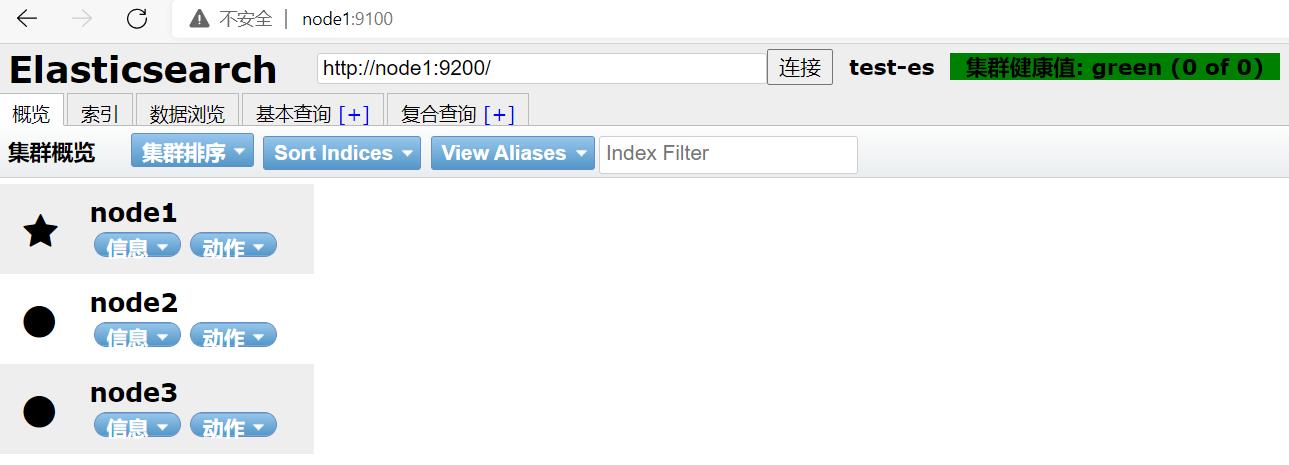
虽然也很丑,但是比什么按钮都没有还是好一些。。。
IK分词器部署
英文分割比较容易(一般情况单词会用空格隔开),中文博大精深。。。IK分词器可以把中文分割出多个词语。
安装单机
mkdir -p /export/server/es/elasticsearch-7.6.1/plugins/ik
cd /export/server/es/elasticsearch-7.6.1/plugins/ik/
rz
由于是zip格式的压缩包,需要:
unzip elasticsearch-analysis-ik-7.6.1.zip
rm -rf elasticsearch-analysis-ik-7.6.1.zip
分发
cd /export/server/es/elasticsearch-7.6.1/plugins
scp -r ik/ node2:$PWD
scp -r ik/ node3:$PWD
启动
IK是个插件,会随着ES一起启动。。。故需要重启ES以便加载IK分词器。。。直接jps查看进程号,使用 kill -9 进程号 杀进程,之后再次启动ES即可:
/export/server/es/elasticsearch-7.6.1/bin/elasticsearch >>/dev/null 2>&1 &
以上是关于Elasticsearch入门 简介及部署的主要内容,如果未能解决你的问题,请参考以下文章