Kibana:在 Lens 中运用多个索引在同一个可视化中创建多个可视化层
Posted Elastic 中国社区官方博客
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Kibana:在 Lens 中运用多个索引在同一个可视化中创建多个可视化层相关的知识,希望对你有一定的参考价值。
我们知道在早期的 Lens 中它只可以使用一个索引。如果我们想使用多个索引来在同一个可视化中创建多层展示,我们必须借助于 TSVB 来实现相应的功能。随着 Lens 的功能不断完善,我们可以在 Lens 中轻松使用多个索引来做可视化。如果你想了解更多 Lens 的使用,请阅读我之前的文章:
在今天的我将用两个例子来展示如何通过多个索引来建立多层可视化图以更好地展示可观测性。
在今天的展示中,我将使用 Elastic 8.1 来进行展示。我将使用 Kibana 自带的 web logs 索引来进行展示。在这个展示中,我将首先使用机器学习来创建一个异常分析。
在 Lens 中运用多个索引在同一个可视化中创建多个可视化层
在 Lens 中运用多个索引在同一个可视化中创建多个可视化层_哔哩哔哩_bilibili
准备数据
我将使用 Kibana 自带的数据来进行展示:
这样我们就在 Elasticsearch 中创建了一个叫做 kibana_sample_data_logs 的索引。
创建机器学习任务
我们接下来创建一个机器学习的任务:
由于机器学习是收费功能,我们必须启动试用功能。
这样就启动了白金版试用功能。
我们再次回到之前的界面:
我们来创建一个 Single metric 任务:
我们定义 Job ID 为 bytes_job:
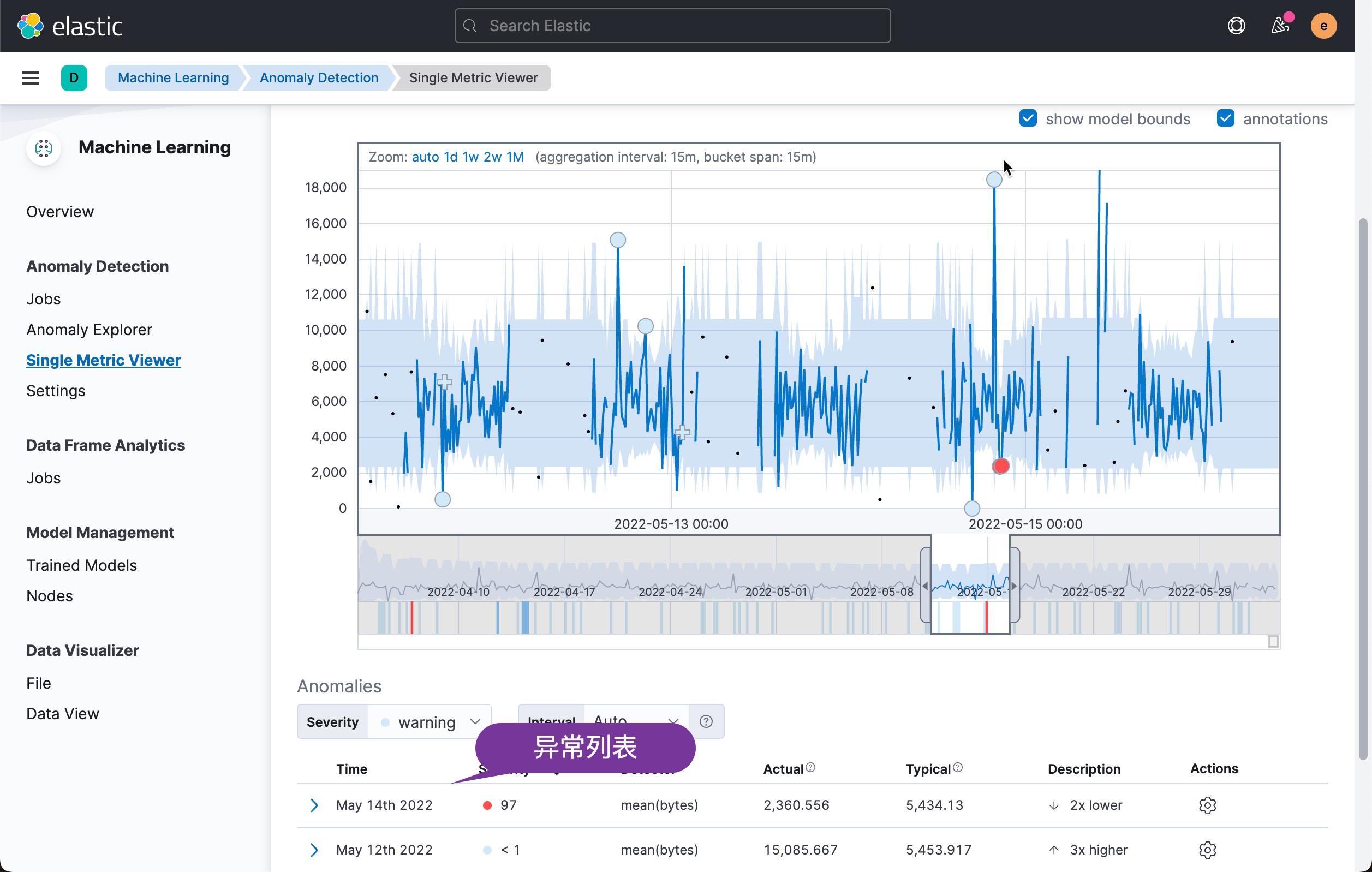
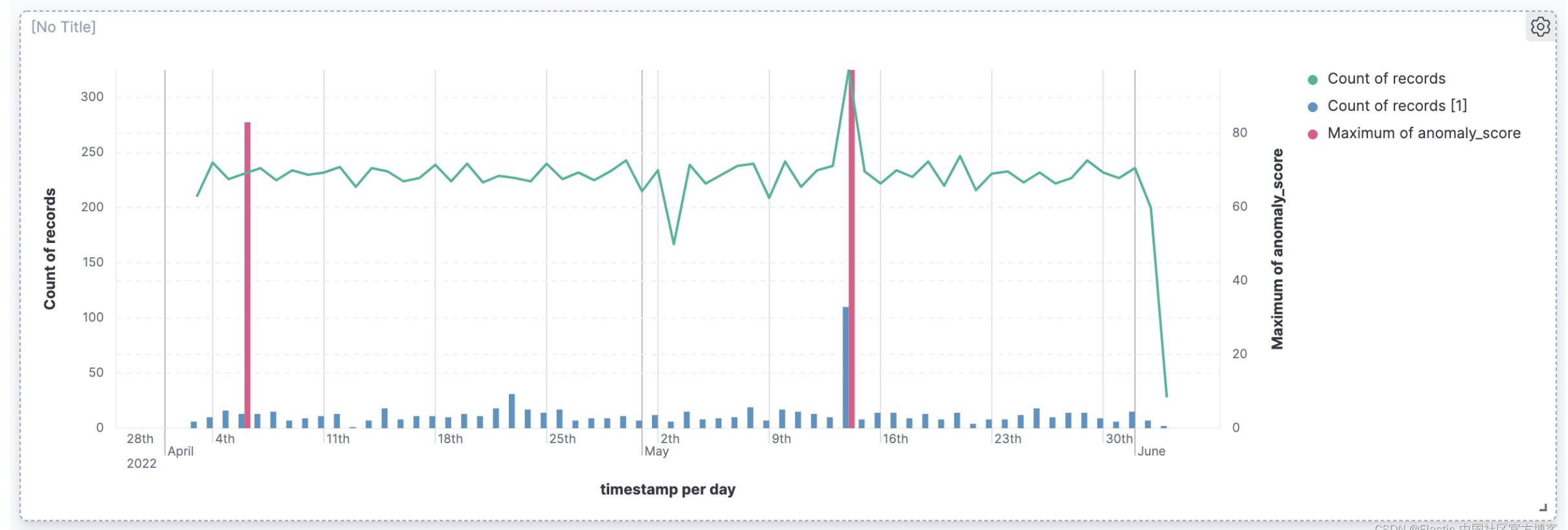
从上面的图中,我们可以看出来来所有异常发生的地方。从上面的图中,我们可以定位出来发生异常的时间,但是这些异常和请求之间有什么直接的联系吗?比如请求多了,或者 404 出现的时候多了,会造成这些异常?从上面的这些图中,我们没法看出来这些关系。我们在下面的可视化图中,我们来直观地把这些放在一个图中来进行查看。
首先,当我们完成一个机器学习的任务后,我们会发现有一个系统生成的索引 .ml-anomalies-shared :
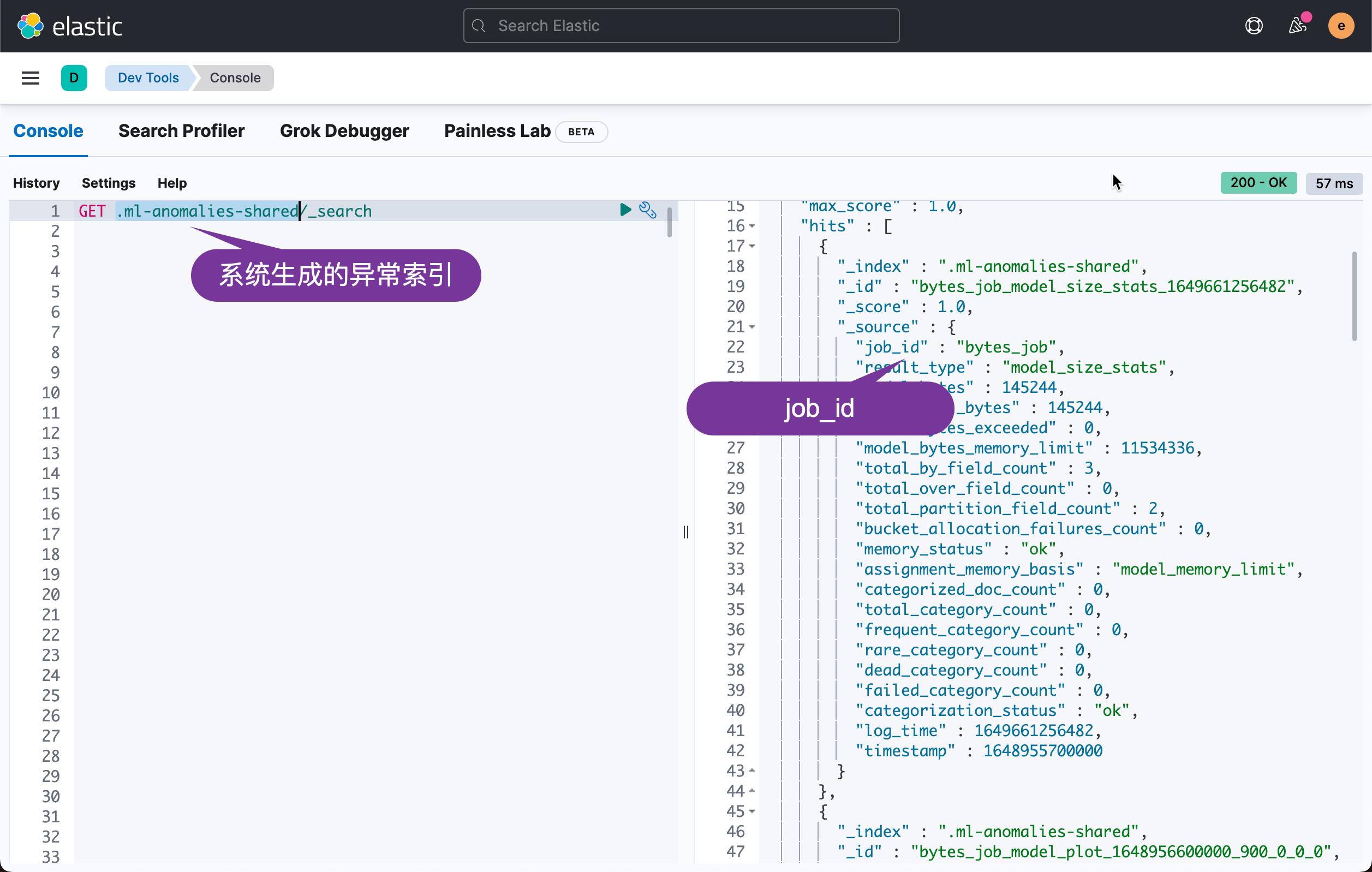
在这个索引中,它包含了所有的异常。 我们甚至可以针对这个索引做一些查询,比如:
GET .ml-anomalies-shared/_search
"query":
"bool":
"must": [
"match":
"job_id": "bytes_job"
,
"range":
"anomaly_score":
"gte": 90
]
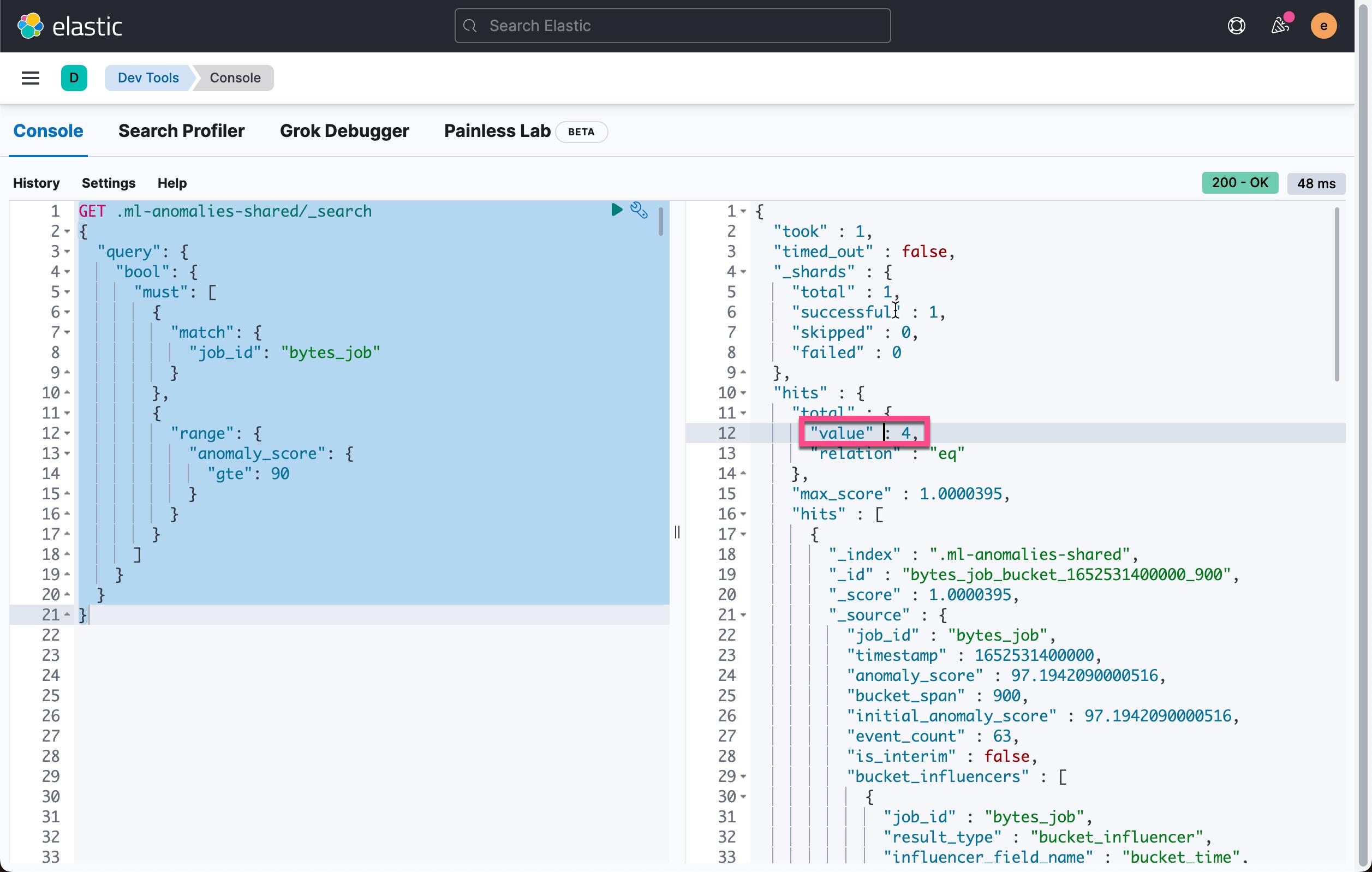
在上面,我们可以看到有 36 个异常的异常值是大于 90 的。
在接下来的步骤里,我们来展示这些异常出现在时序数据的哪些位置。
可视化异常出现的地方
在接下来的展示中,我们展示:
- 出现 404 响应值是在时序数据的哪些地方?
- 出现异常的地方是在时序的哪些地方?
添加 404 出现的地方
我们首先打开 Dashboad:
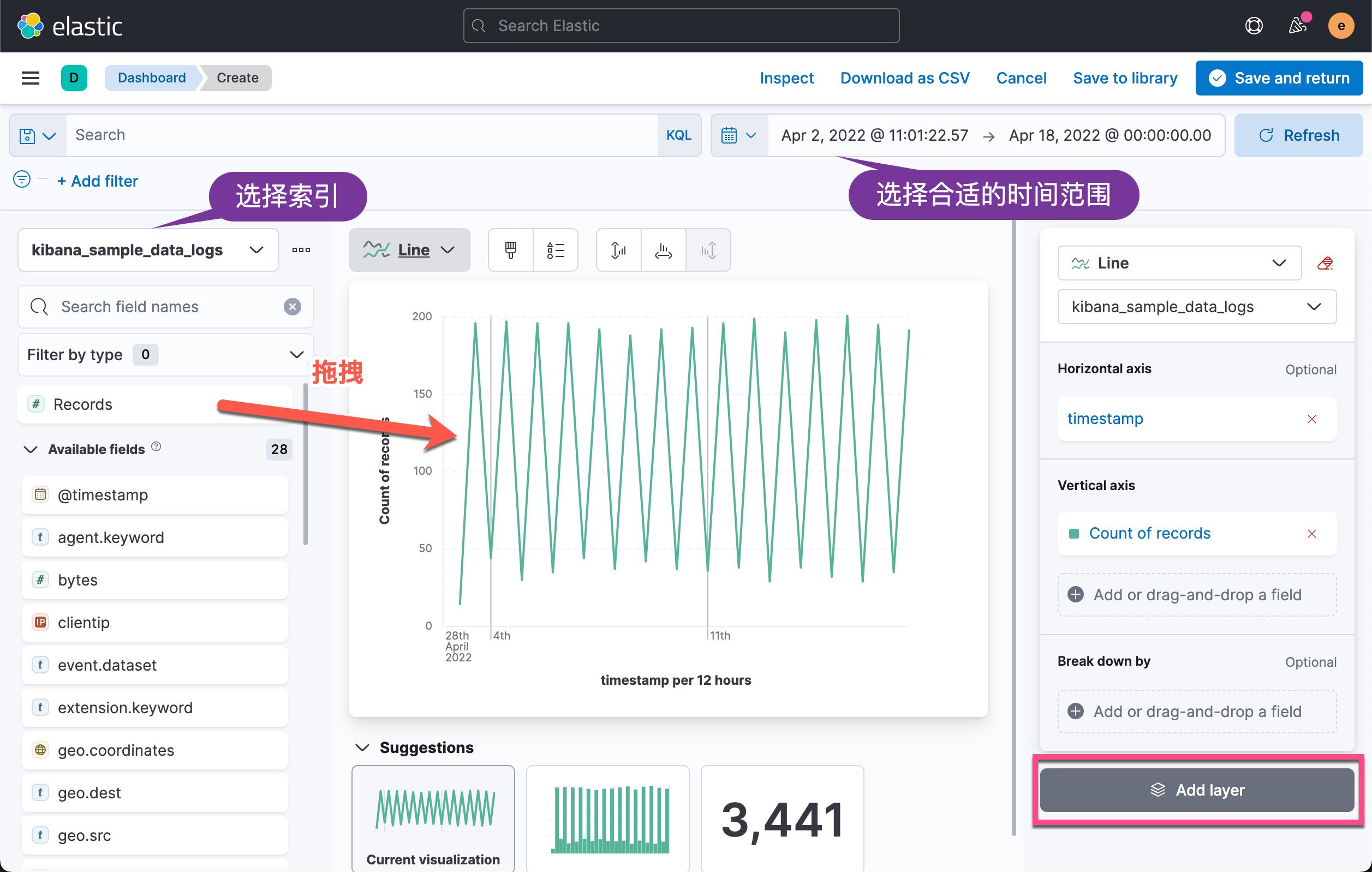
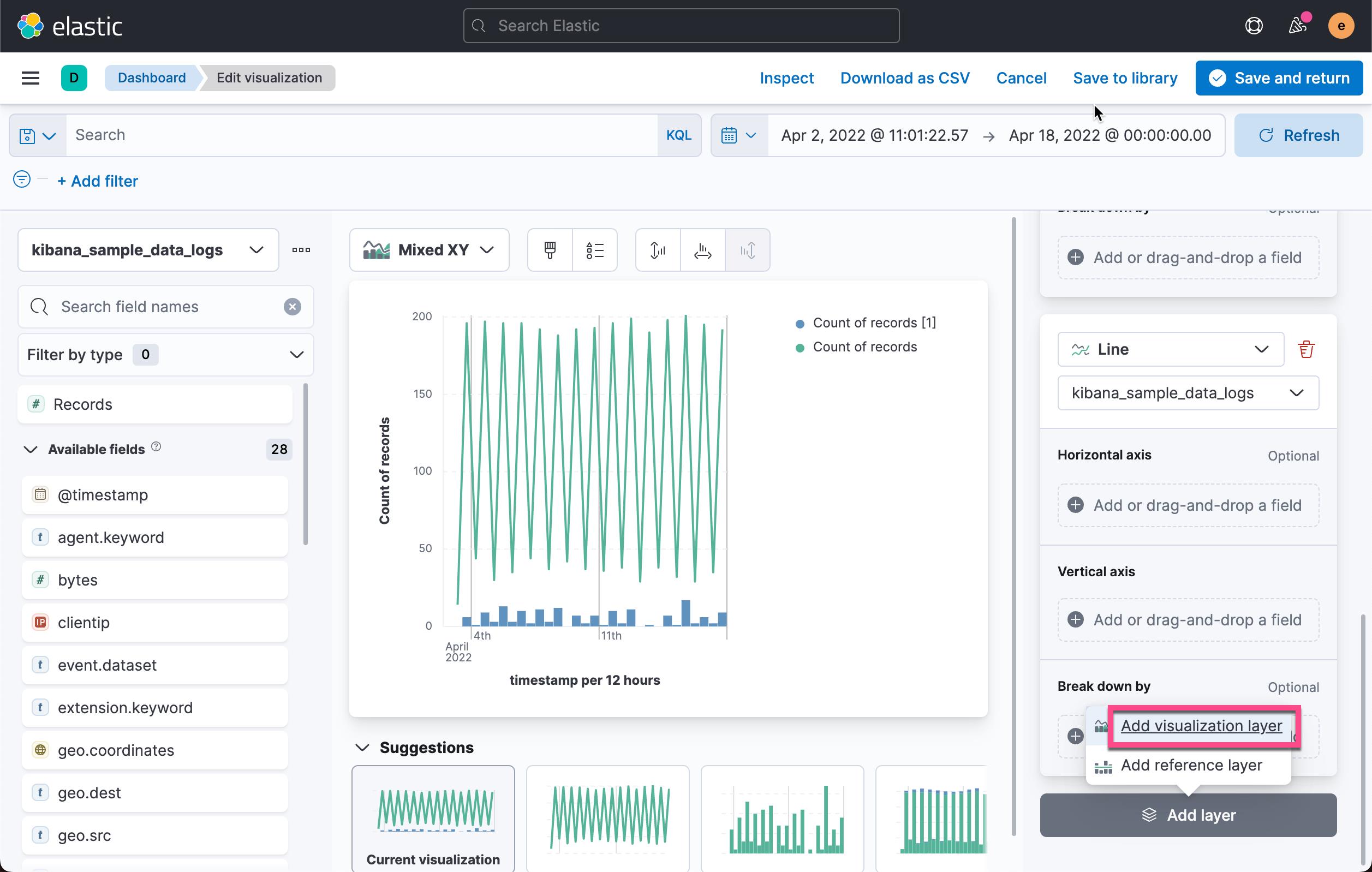
在上面,我们通过选择合适的时间范围及索引,拖拽 Records 到工作区里。我们就可以看到如上所示的可视化图。我们接下来点击 Add layer:
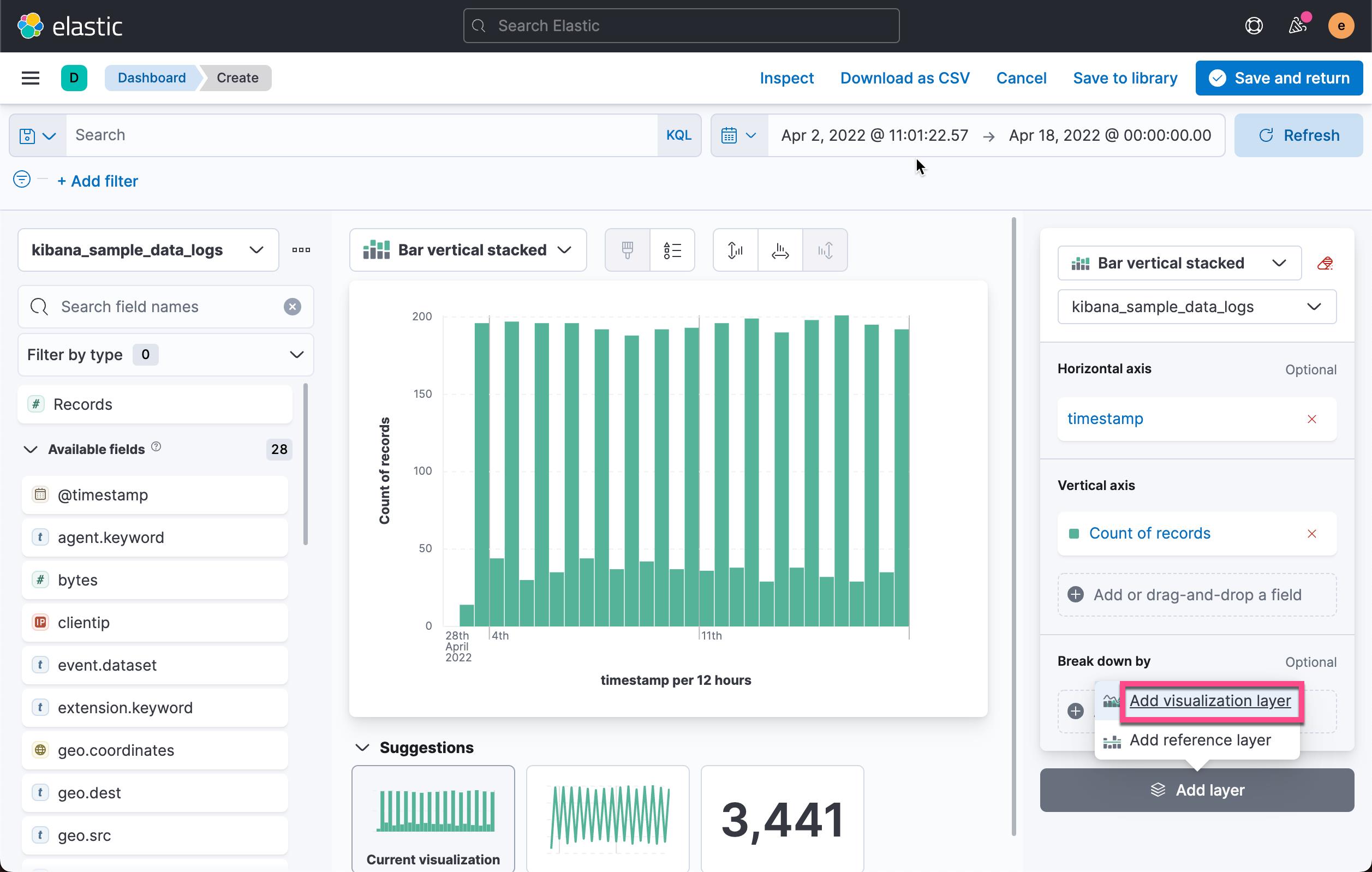
我们选择 Add visualization layer:
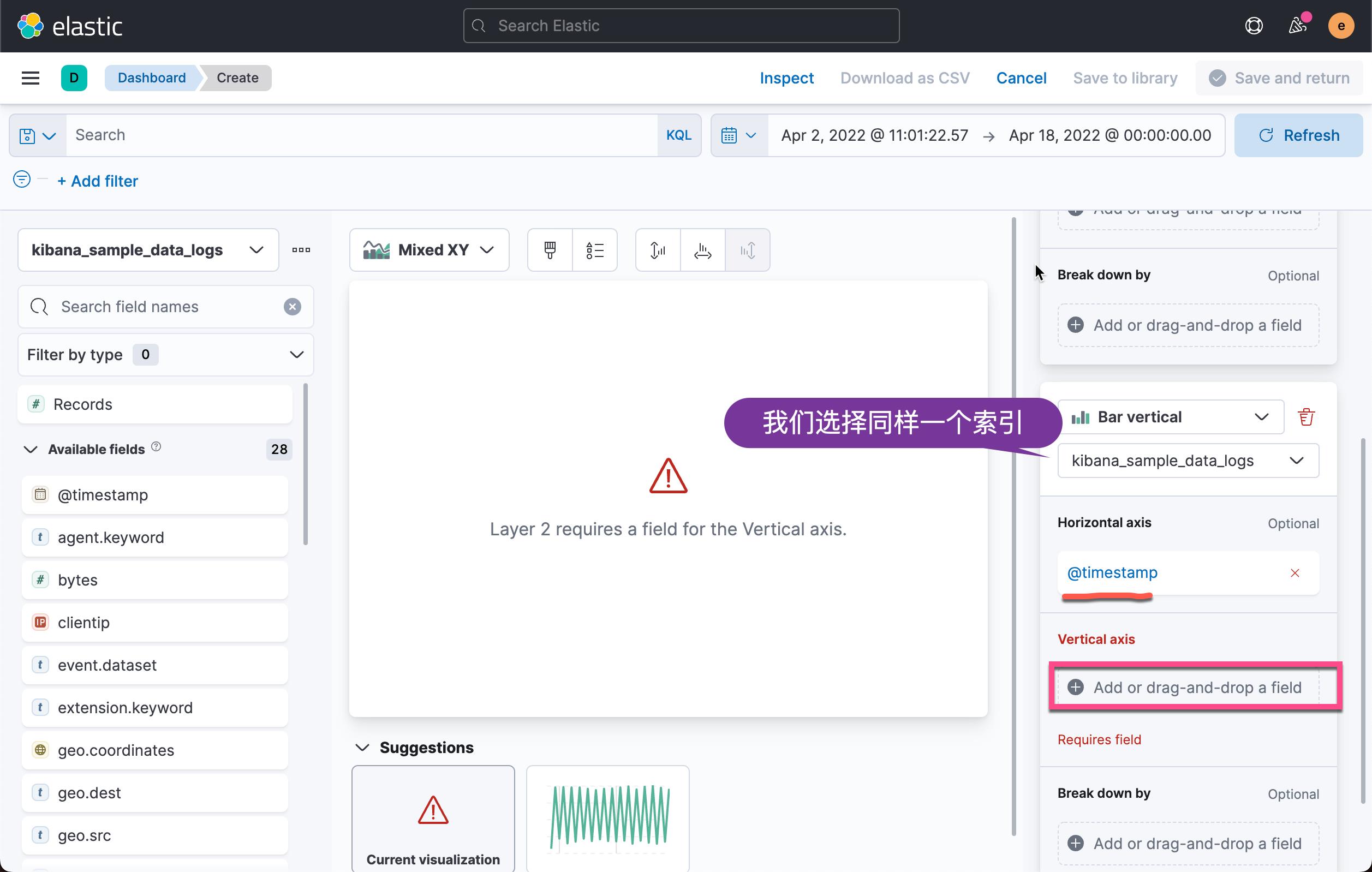
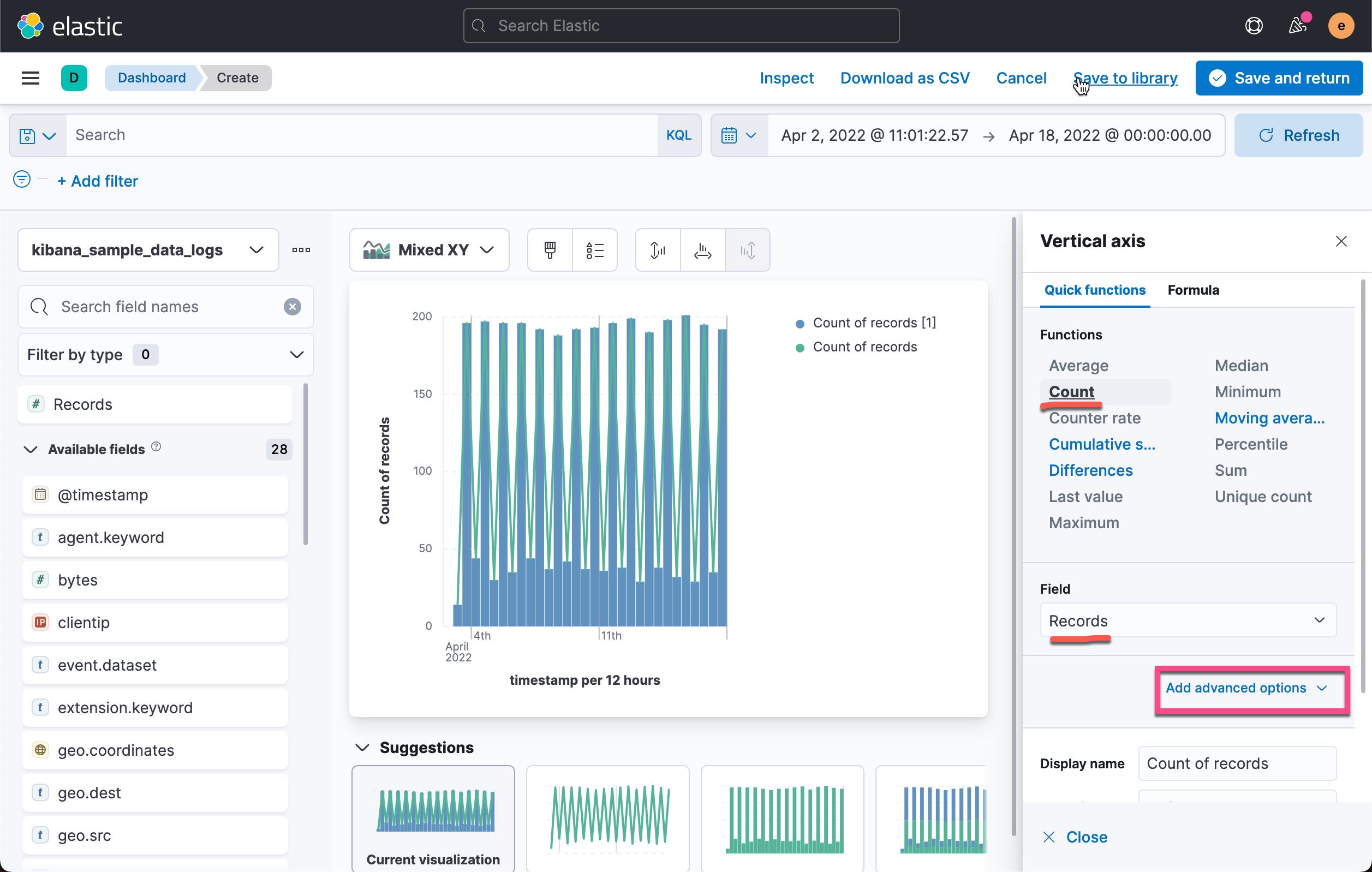
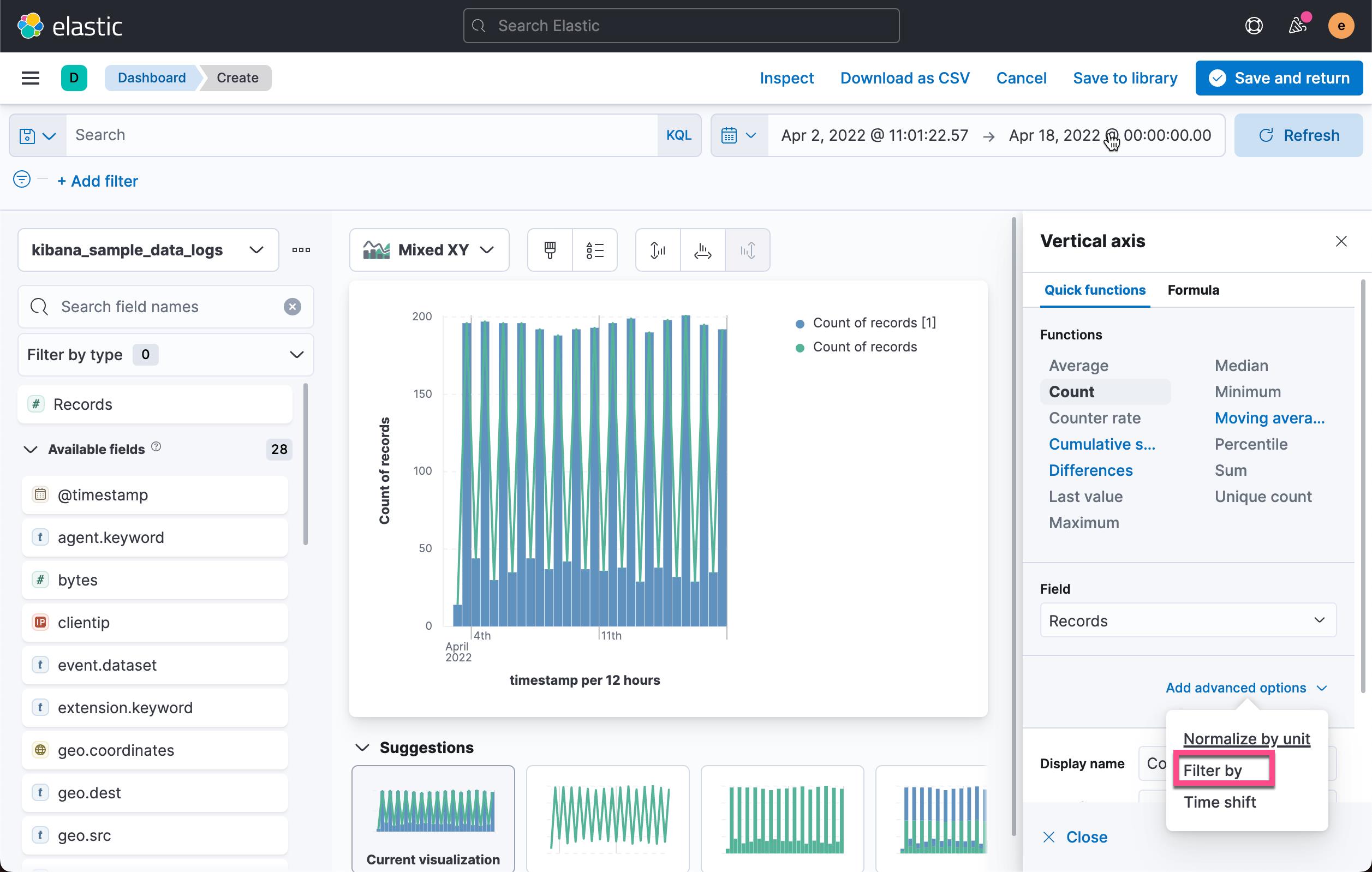
在上面,我们选择 Count,并且选择 Records。我们点击 Add advanced options:
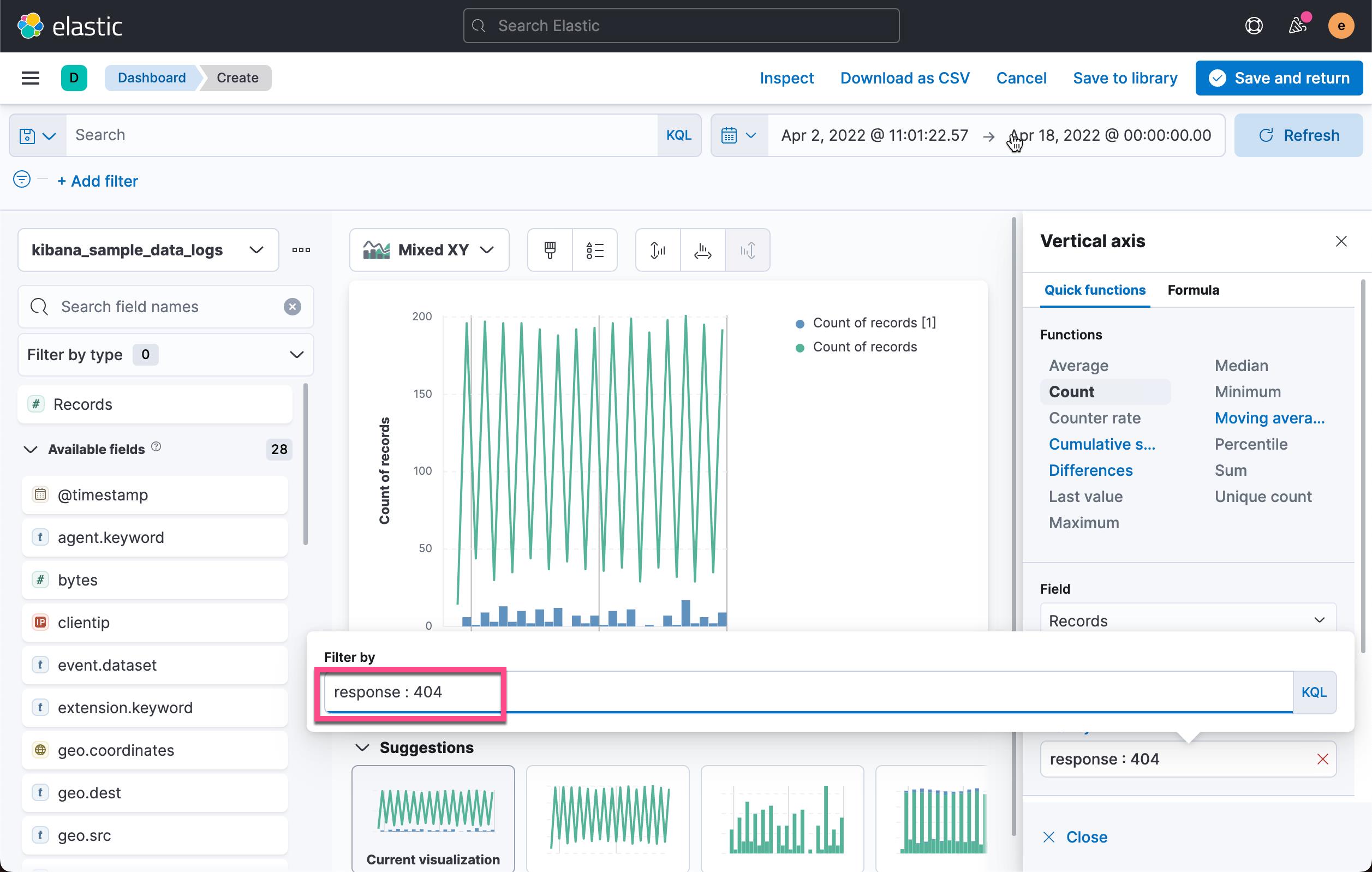
从上面的图中,我们可以看出来请求的多少和相应是否为 404 有啥关系。是不是请求阅读,404 就越多?
当然,我们甚至可以把这个显示的轴放在右边。我们目前不这么做,是因为我们想在下面的异常值展示中使用这个右边的轴,它的范围是 0-100 之间。
添加异常出现的地方
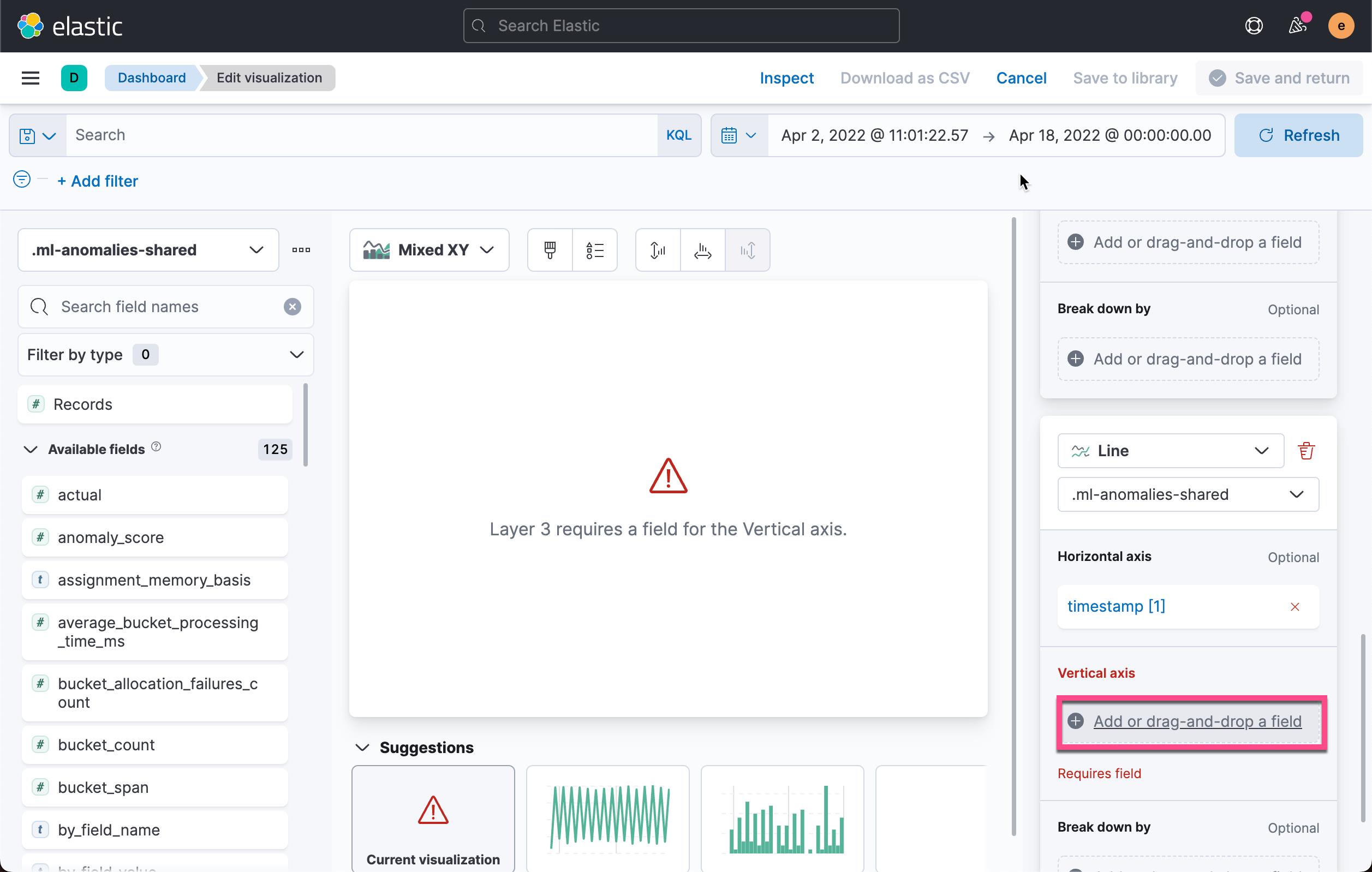
我们接下来添加另外一个图层:
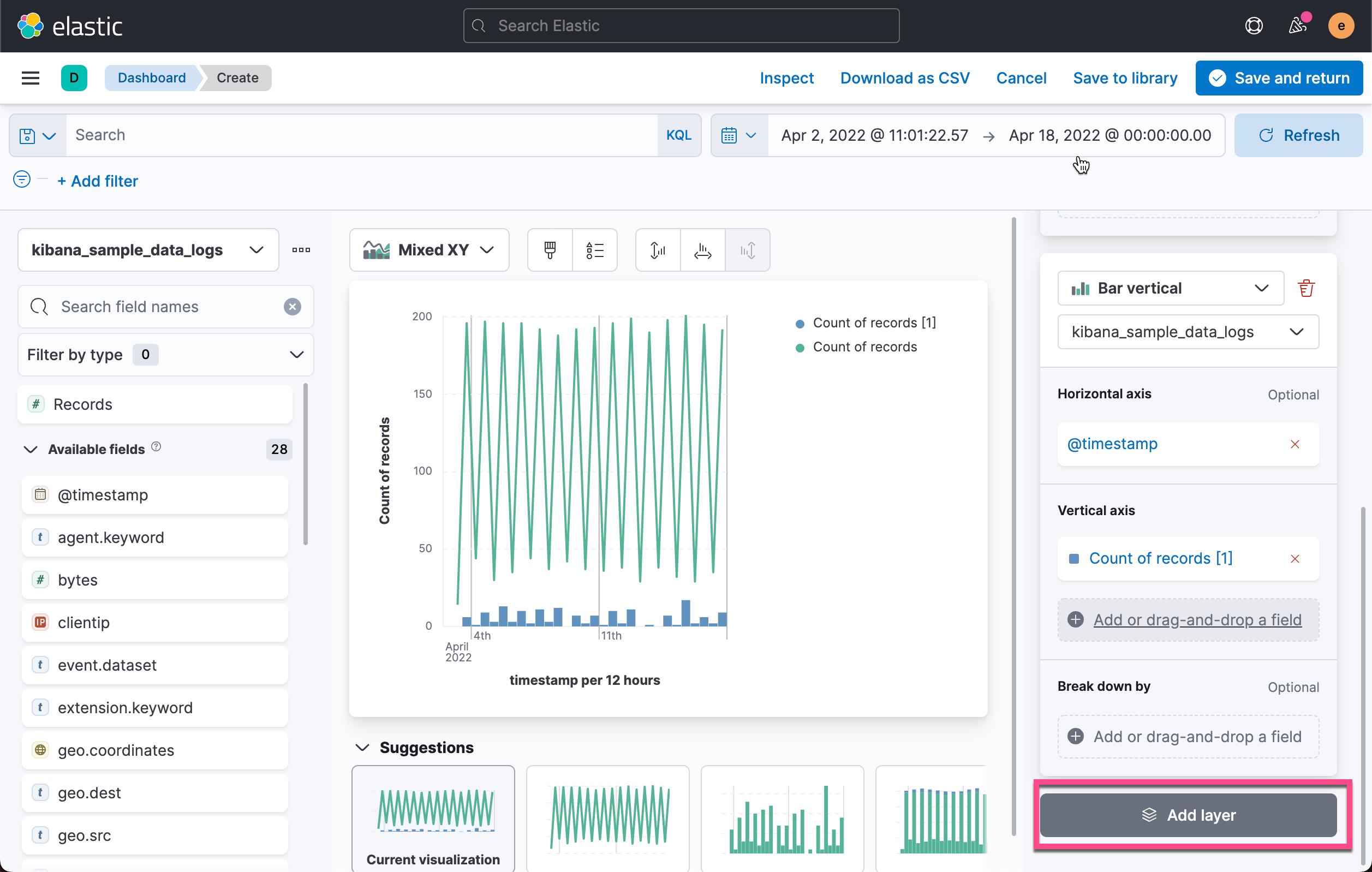
点击上面的 Add layer:
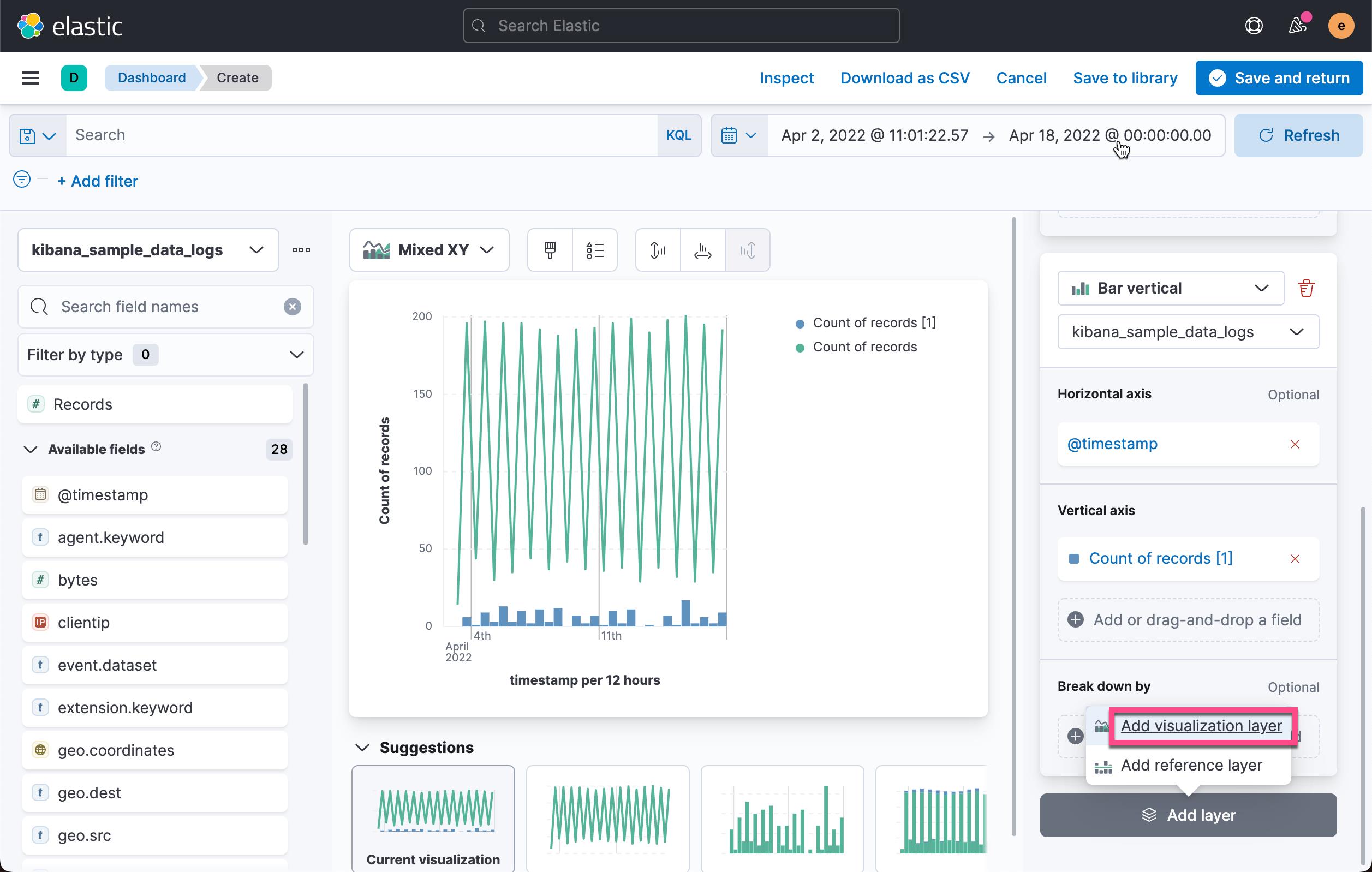
按照同样的套路,我们添加另外一个图层:
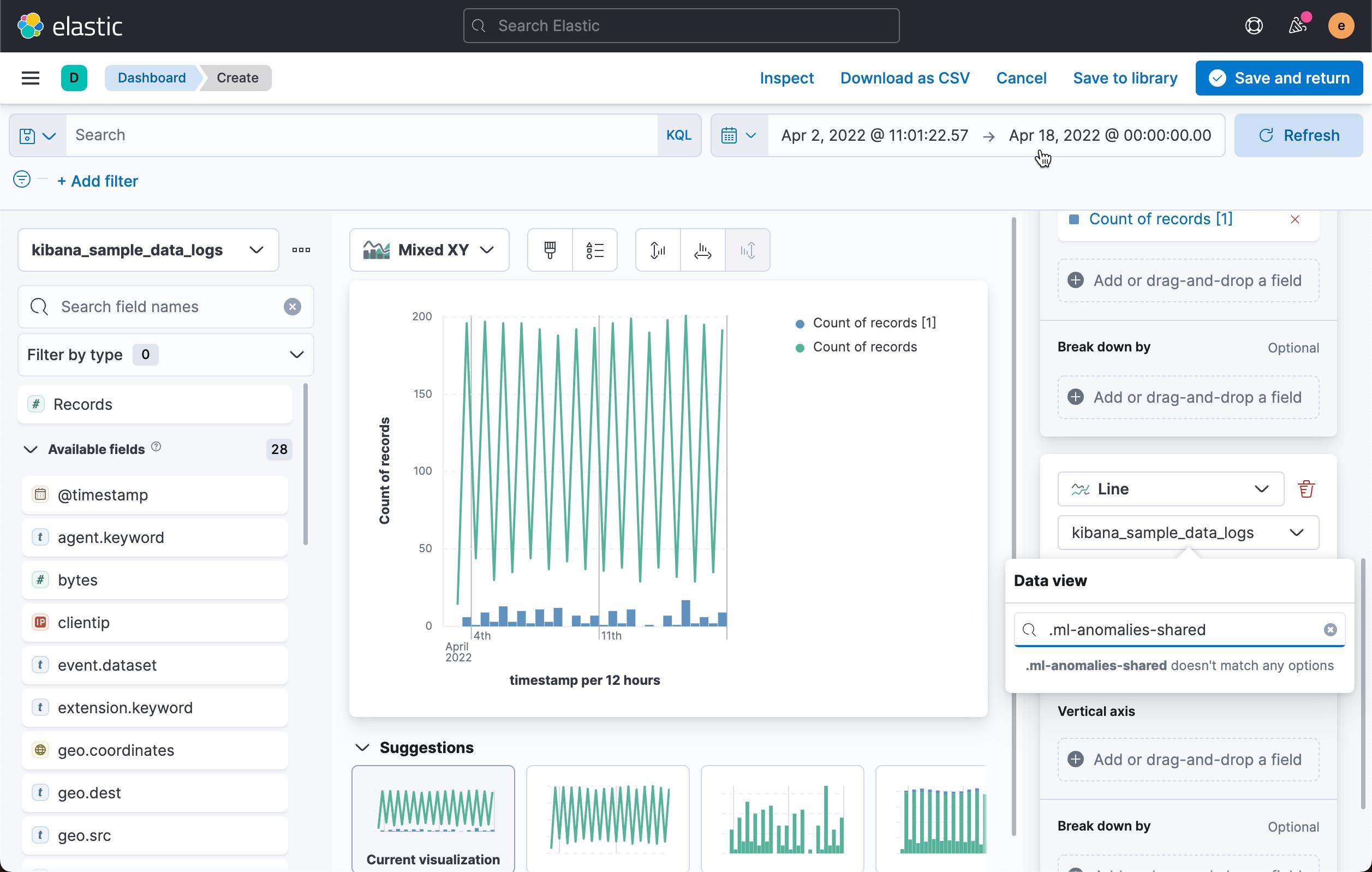
我们想添加 .ml-anomalies-shared 索引,但是我们目前还没有一个 data views 对应于这个索引。我们必须手动来创建这个 data view:
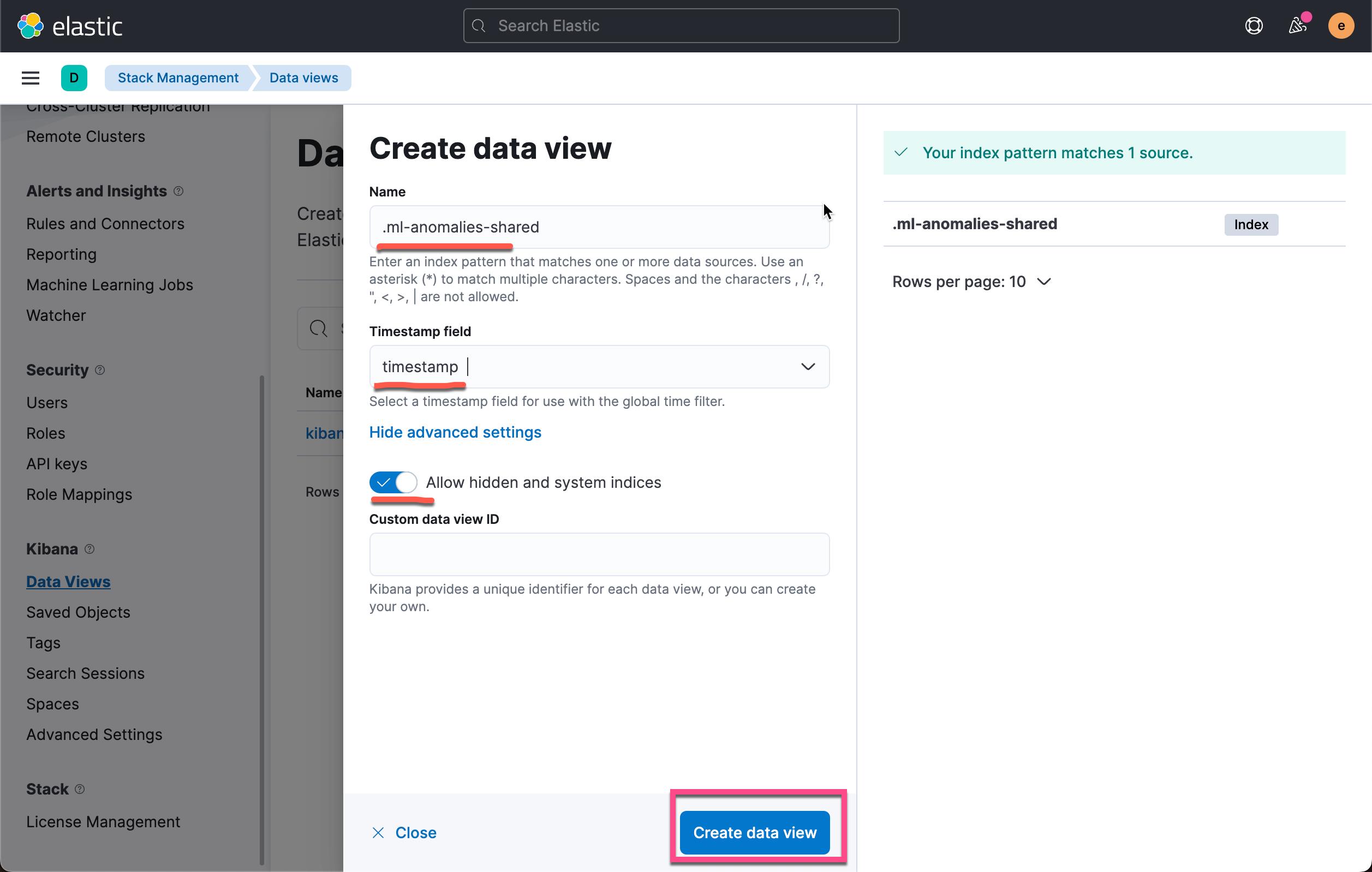
点击上面的 Create data view:
这样我们就创建了一个叫做 .ml-anomalies-shared 的 data view。
我们再次回到上面的可视化作图的地方。如果这个最新创建的 data view 还不被认知,你需要保存当前的可视化,然后再对它进行编辑:
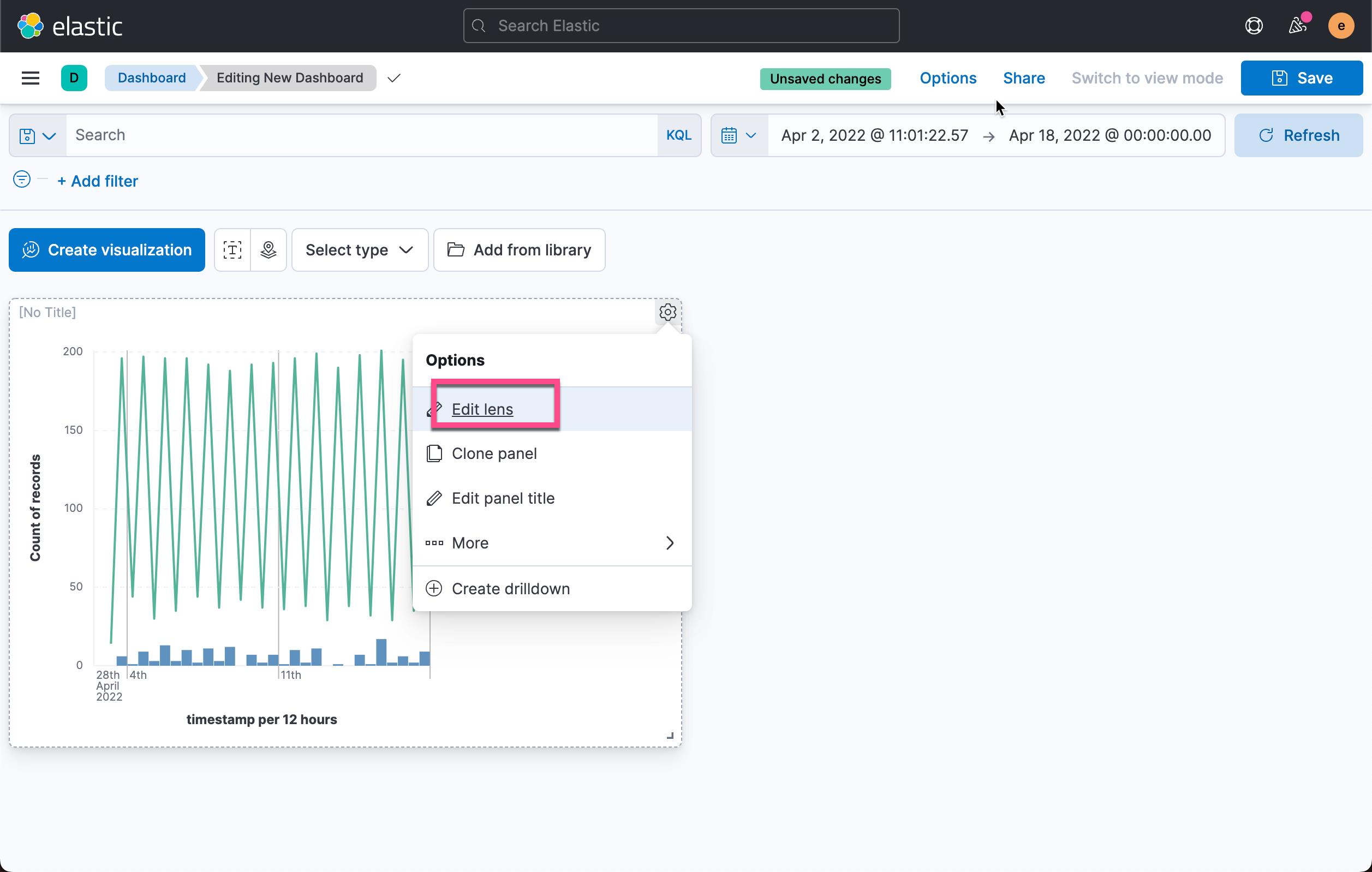
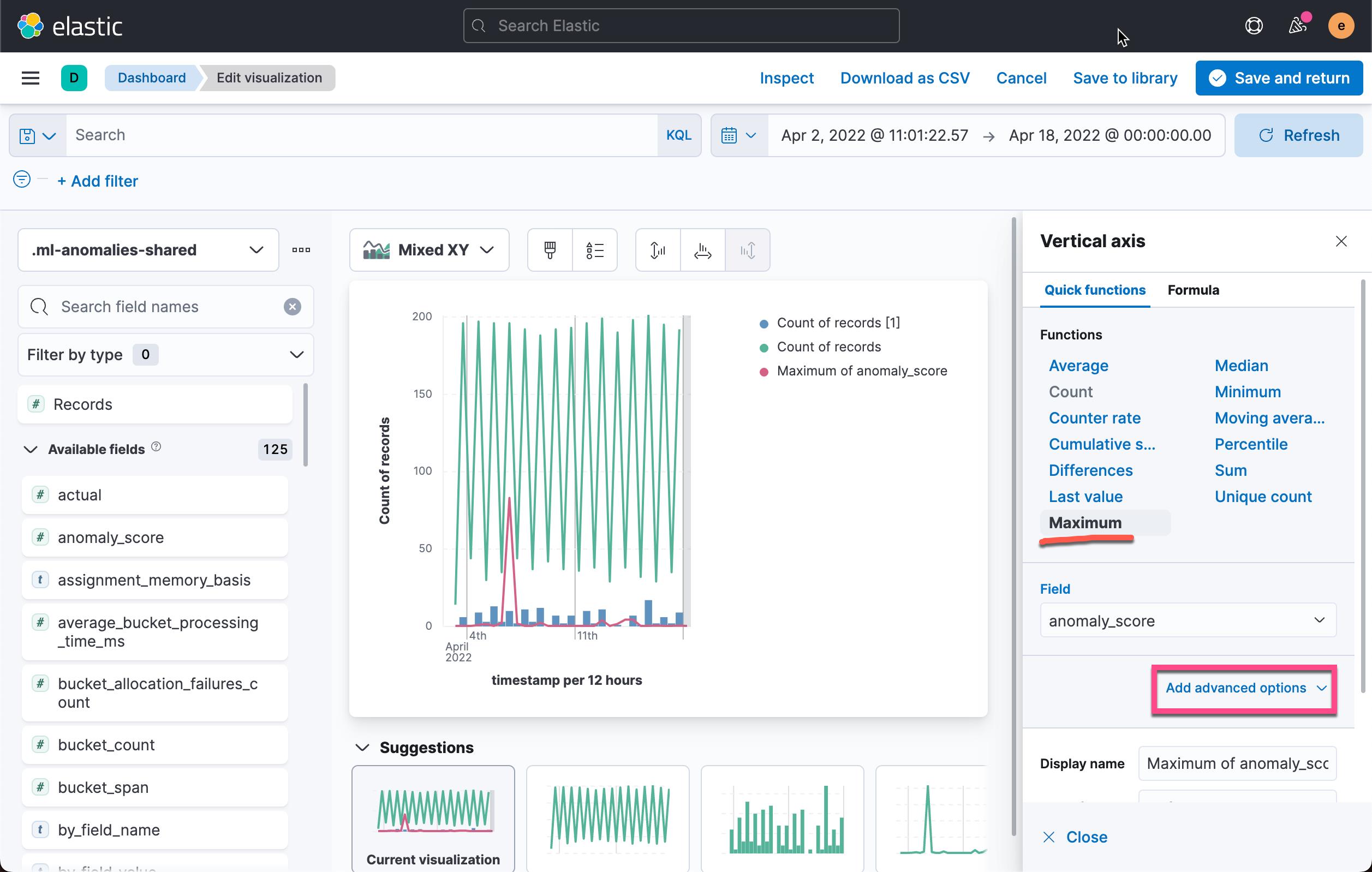
在上面,我们输入如下的条件:
job_id: "bytes_job" and anomaly_score > 80我们可以看到如下的可视化图:
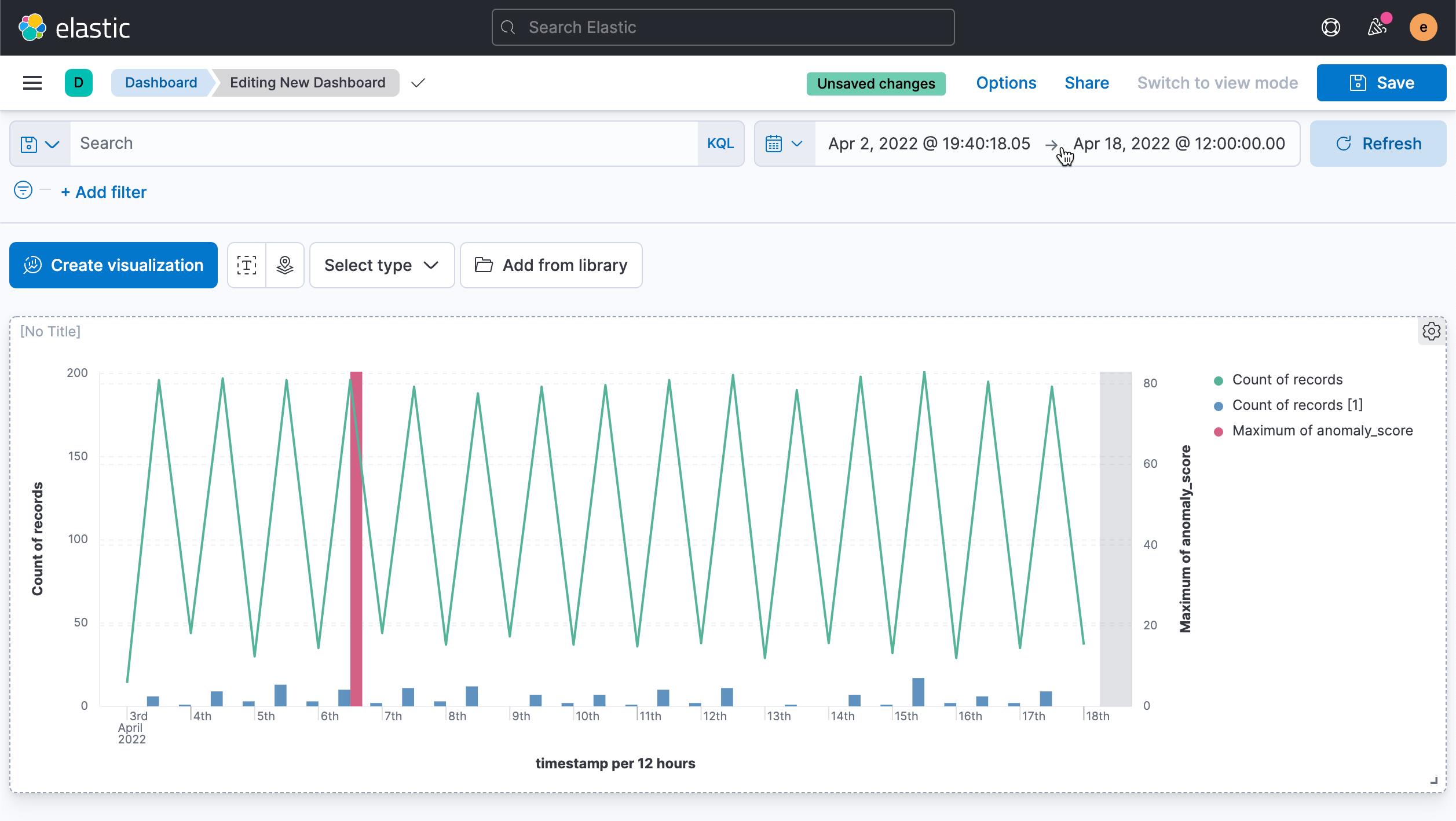
从上面,我们可以看出来请求的过数和异常有没有直接的关系。当然我们也可以查看请求的 bytes 的大小和异常的关系。我们可以使用另外一个可视化来描述。这里就不再累述了。在之前的查询中,我们知道有四个异常是大于 90 的,但是,我们上面的图中只看到一个是大于 80 的,这是咋回事呢?我们可以把时间调整到未来的一个截止时间:
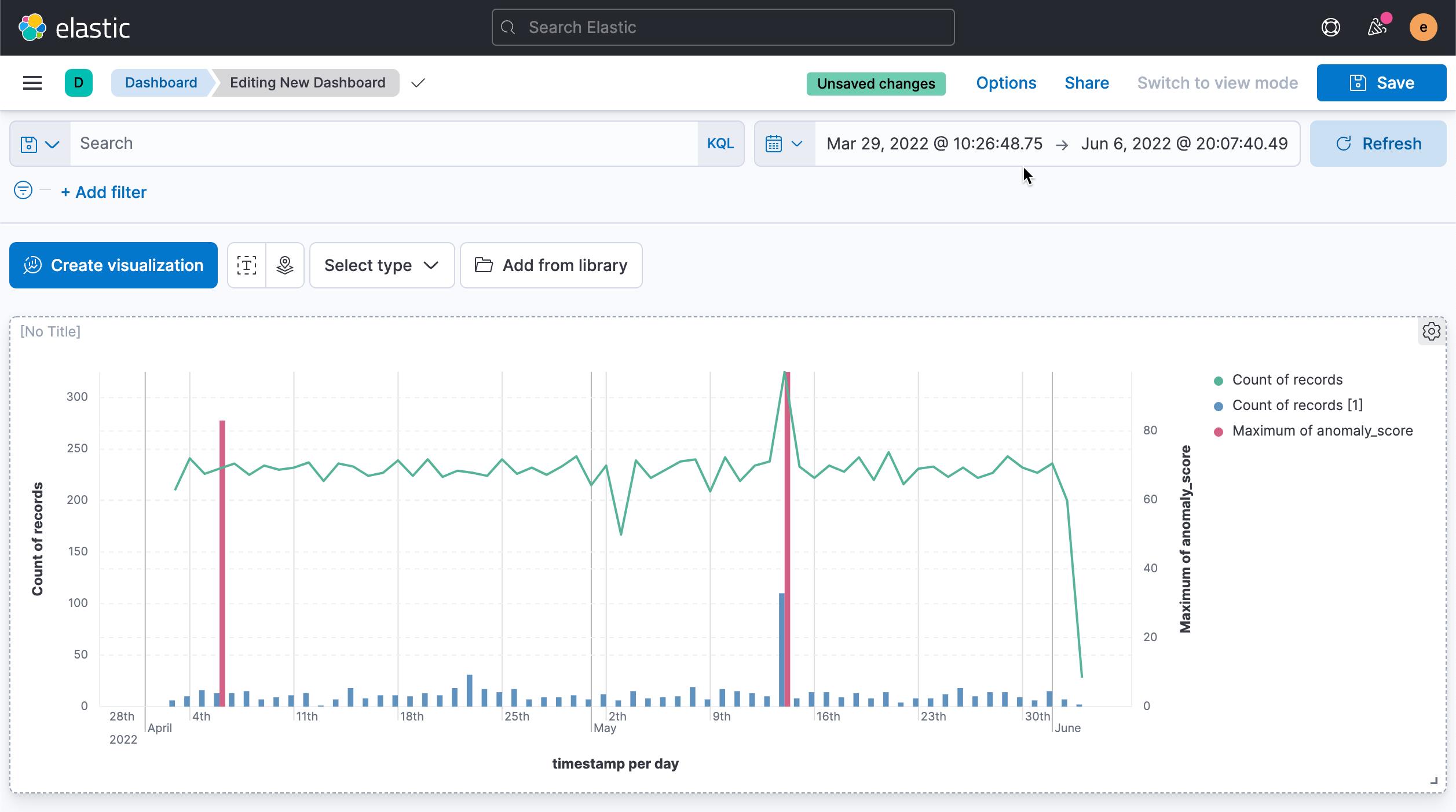
从上面的图中,我们可以看出来在第二异常值为 97 发生的时候,请求的响应值为 404 的也挺多。
以上是关于Kibana:在 Lens 中运用多个索引在同一个可视化中创建多个可视化层的主要内容,如果未能解决你的问题,请参考以下文章
网络研讨会报名2月26日,Kibana Lens 网络研讨会
Kibana:如何使用 Kibana 时间偏移高级公式和动态颜色 - 7.14
Kibana:如何使用 Kibana 时间偏移高级公式和动态颜色 - 7.14
Kibana:在 Lens 中轻松地创建运行时字段以分析数据 - 7.13 版本
Kibana:在 Lens 和 Discover 中轻松地创建 runtime fields 以分析数据 - 7.13 版本