爬虫效率怎么提高,怎么完成企业需求,真正体验到企业级数据下载!
Posted 普通网友
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了爬虫效率怎么提高,怎么完成企业需求,真正体验到企业级数据下载!相关的知识,希望对你有一定的参考价值。
python爬虫进阶:Q队列多任务批量下载斗图吧
前言
本文纯技术角度出发,教你如何用Python爬虫获取企业级数据下载。
主要内容:
1.Q队列储存数据信息
2.py多任务批量下载
3.低耦合类方式下载
目标站点
百度搜索斗图啦,斗图道路从此不会再迷茫。
https://www.doutula.com/
开发环境
开发环境:Python3.7 + win10
开发工具:pycharm + chrome
第三方库:requests,lxml , re,Queue,threading
效果预览
网页效果图:
代码爬取效果:
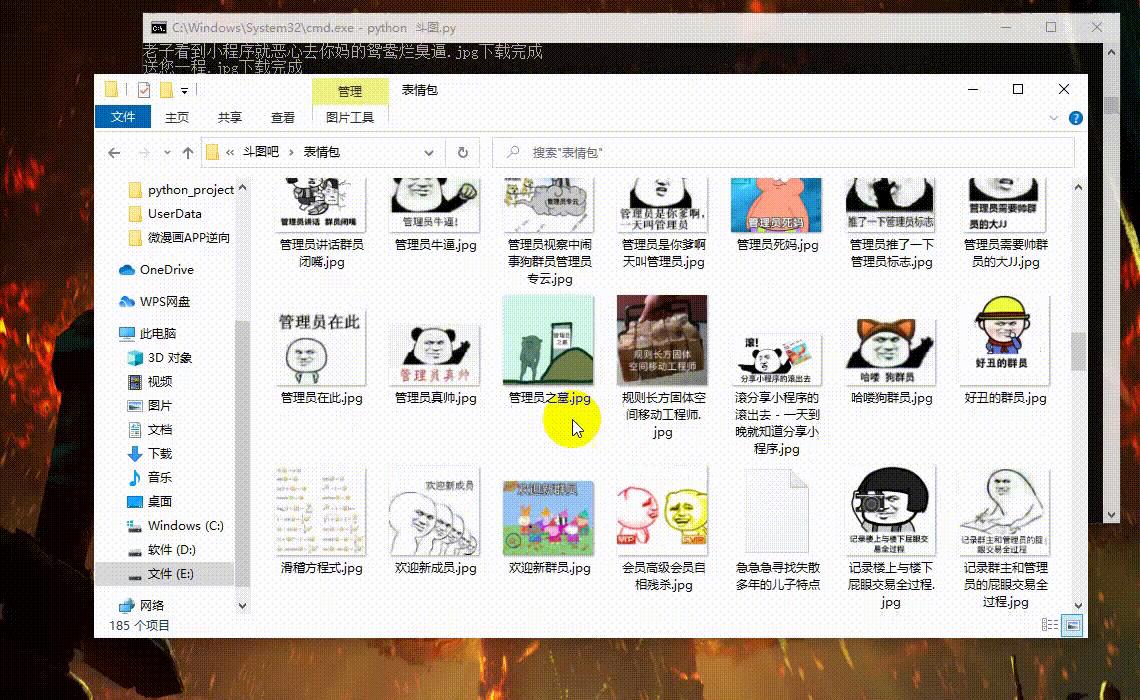
正式教程
创建队列
创建两个队列:
page_queue用来保存翻页的url
img_queue 用来保存图片的链接
page_queue = Queue()
img_queue = Queue()
提交页数url到page队列
将翻页的数据保存到page队列里 :
for x in range(1, 11):
url = 'https://www.doutula.com/search?type=photo&more=1&keyword=%E7%A8%8B%E5%BA%8F%E5%91%98&page='.format(x)
page_queue.put(url)
创建解析网页类
基于类的方式封装线程:
通过获取的页数的url 解析当前网页的图片链接,保存到img队列
class ImageParse(threading.Thread):
def __init__(self, page_queue, img_queue):
super(ImageParse, self).__init__() # 子类继承了父类的所有属性和方法,父类方法进行初始化。
self.page_queue = page_queue
self.img_queue = img_queue
self.headers =
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (Khtml, like Gecko) Chrome/87.0.4280.88 Safari/537.36'
def run(self):
while True:
if self.page_queue.empty():
break
url = self.page_queue.get()
self.parse_page(url)
def parse_page(self, url):
response = requests.get(url, headers=self.headers).text
# print(response)
html = etree.HTML(response)
images = html.xpath('//div[@class="random_picture"]')
for img in images:
img_url = img.xpath('.//img/@data-original')
# 获取图片名字
print(img_url)
alt = img.xpath('.//p/text()')
for name, new_url in zip(alt, img_url):
filename = re.sub(r'[??.,。!!*\\\\/|]', '', name) + ".jpg"
# 获取图片的后缀名
# suffix = os.path.splitext(img_url)[1]
# print(alt)
self.img_queue.put((new_url, filename))
创建保存图片类
获取img队列里的数据
保存到当前文件:
class Download(threading.Thread):
def __init__(self, page_queue, img_queue):
super(Download, self).__init__()
self.page_queue = page_queue
self.img_queue = img_queue
def run(self):
while True:
if self.img_queue.empty() and self.page_queue.empty():
break
img_url, filename = self.img_queue.get()
with open("表情包/" + filename, "wb")as f:
response = requests.get(img_url).content
f.write(response)
print(filename + '下载完成')
启动线程
开启多线程:
for x in range(1, 11):
url = 'https://www.doutula.com/search?type=photo&more=1&keyword=%E7%A8%8B%E5%BA%8F%E5%91%98&page='.format(x)
page_queue.put(url)
for x in range(5):
t = ImageParse(page_queue, img_queue)
t.start()
t = Download(page_queue, img_queue)
t.start()
完整代码
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2020/12/17 13:20
# @Author : BaiChuan
# @File : 斗图.py
import requests
from lxml import etree
import re
from queue import Queue
import threading
class ImageParse(threading.Thread):
def __init__(self, page_queue, img_queue):
super(ImageParse, self).__init__() # 子类继承了父类的所有属性和方法,父类方法进行初始化。
self.page_queue = page_queue
self.img_queue = img_queue
self.headers =
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36'
def run(self):
while True:
if self.page_queue.empty():
break
url = self.page_queue.get()
self.parse_page(url)
def parse_page(self, url):
response = requests.get(url, headers=self.headers).text
# print(response)
html = etree.HTML(response)
images = html.xpath('//div[@class="random_picture"]')
for img in images:
img_url = img.xpath('.//img/@data-original')
# 获取图片名字
print(img_url)
alt = img.xpath('.//p/text()')
for name, new_url in zip(alt, img_url):
filename = re.sub(r'[??.,。!!*\\\\/|]', '', name) + ".jpg"
# 获取图片的后缀名
# suffix = os.path.splitext(img_url)[1]
# print(alt)
self.img_queue.put((new_url, filename))
class Download(threading.Thread):
def __init__(self, page_queue, img_queue):
super(Download, self).__init__()
self.page_queue = page_queue
self.img_queue = img_queue
def run(self):
while True:
if self.img_queue.empty() and self.page_queue.empty():
break
img_url, filename = self.img_queue.get()
with open("表情包/" + filename, "wb")as f:
response = requests.get(img_url).content
f.write(response)
print(filename + '下载完成')
def main():
# 建立队列
page_queue = Queue()
img_queue = Queue()
for x in range(1, 11):
url = 'https://www.doutula.com/search?type=photo&more=1&keyword=%E7%A8%8B%E5%BA%8F%E5%91%98&page='.format(x)
page_queue.put(url)
for x in range(5):
t = ImageParse(page_queue, img_queue)
t.start()
t = Download(page_queue, img_queue)
t.start()
if __name__ == '__main__':
main()

以上是关于爬虫效率怎么提高,怎么完成企业需求,真正体验到企业级数据下载!的主要内容,如果未能解决你的问题,请参考以下文章