Dubbo -- dubbo高级特性(序列化 地址缓存 超时与重试机制 多版本:灰度发布 负载均衡 集群容错策略 服务降级)
Posted CodeJiao
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Dubbo -- dubbo高级特性(序列化 地址缓存 超时与重试机制 多版本:灰度发布 负载均衡 集群容错策略 服务降级)相关的知识,希望对你有一定的参考价值。
文章目录
1. Dubbo – 分布式系统的相关概念(大型互联网项目架构目标 集群和分布式 架构演进)、Dubbo概述(Dubbo的概念和架构)、Dubbo快速入门(Zookepper的安装:注册中心中心)
3.Dubbo – dubbo-admin 的安装 介绍 使用
4. Dubbo – dubbo高级特性(序列化 地址缓存 超时与重试机制 多版本:灰度发布 负载均衡 集群容错策略 服务降级)
1. dubbo高级特性
1.1 序列化
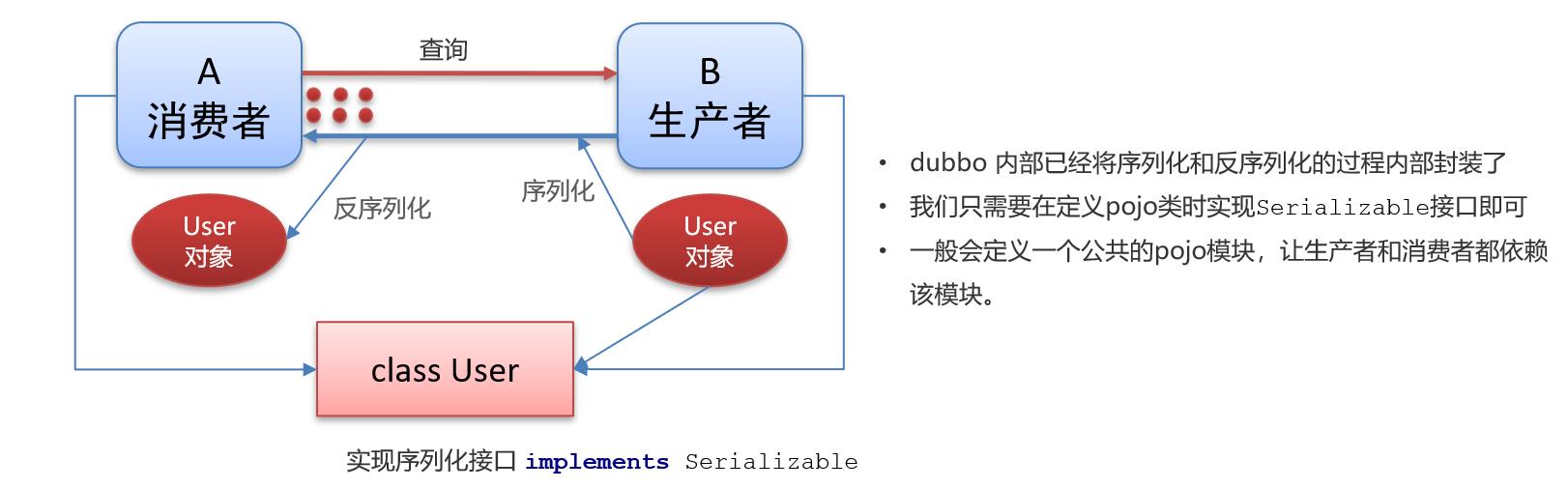
tips:因为生产者和消费者都会用到pojo,建议把新一个一个模块,用来存放pojo,然后在生产者和消费者中引入pojo模块即可。
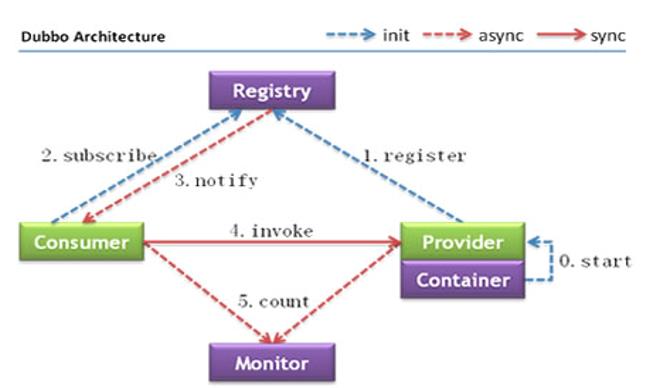
1.2 地址缓存
注册中心挂了,服务是否可以正常访问?
- 可以,因为dubbo服务消费者在第一次调用时,会将服务提供方地址缓存到本地,以后在调用则不会访问注册中心。
- 当服务提供者地址发生变化时,注册中心会通知服务消费者。
1.3 超时与重试机制
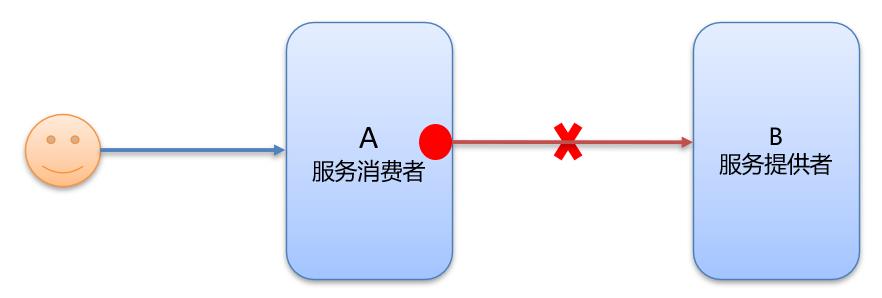
- 服务消费者在调用服务提供者的时候发生了阻塞、等待的情形,这个时候,服务消费者会一直等待下去。
- 在某个峰值时刻,大量的请求都在同时请求服务消费者,会造成线程的大量堆积,势必会造成雪崩。
- dubbo 利用超时机制来解决这个问题,设置一个超时时间,在这个时间段内,无法完成服务访问,则自动断开连接。
- 使用timeout属性配置超时时间,默认值1000,单位毫秒。
- 设置了超时时间,在这个时间段内,无法完成服务访问,则自动断开连接。
- 如果出现网络抖动,则这一次请求就会失败。Dubbo 提供重试机制来避免类似问题的发生。 通过 retries 属性来设置重试次数。默认为 2 次。
超时连接失败后的截图

说明:
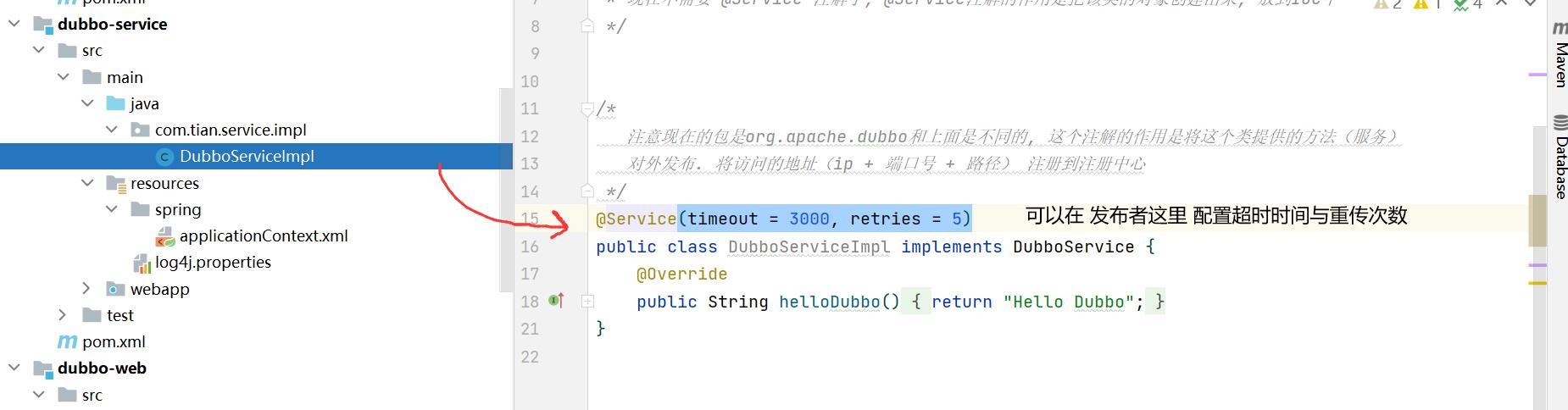
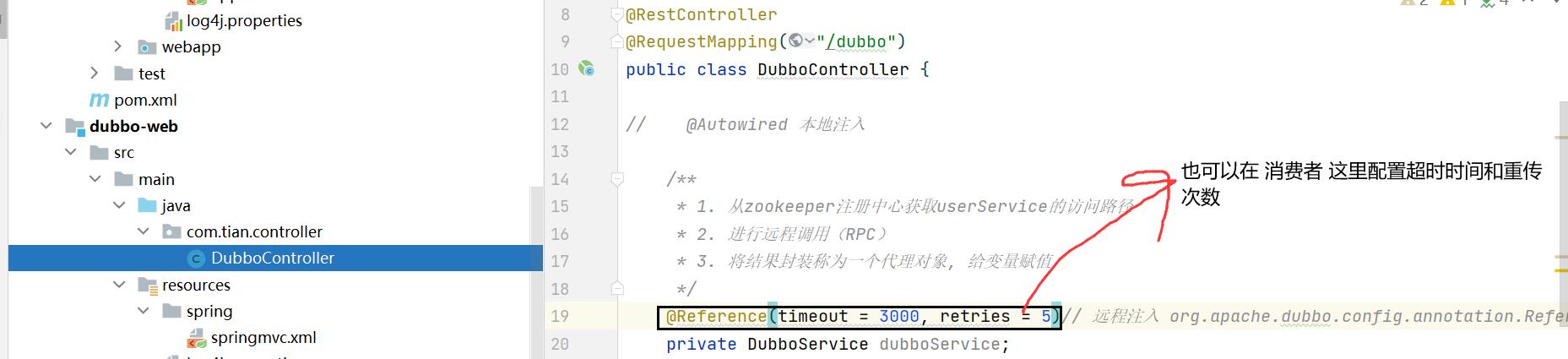
/**
* timeout = 3000 当前服务在连接3s后就会超时
* retries = 5 如果上一次没有连接成功,则会重试,加上第一次连接,一共尝试6次。
* 所以最多 3 * (5 + 1) = 18 秒后就会发生TimeOut(超时)错误。
*/
@Reference(timeout = 3000, retries = 5)
注意:如果发布者和消费者都配置了 超时与重试,则消费者的配置会覆盖发布者的配置。但是根据业务的逻辑性来说,超时与重试 配置在发布者这里会更加合理一些。
1.4 多版本
- 灰度发布:当出现新功能时,会让一部分用户先使用新功能,用户反馈没问题时,再将所有用户迁移到新功能。
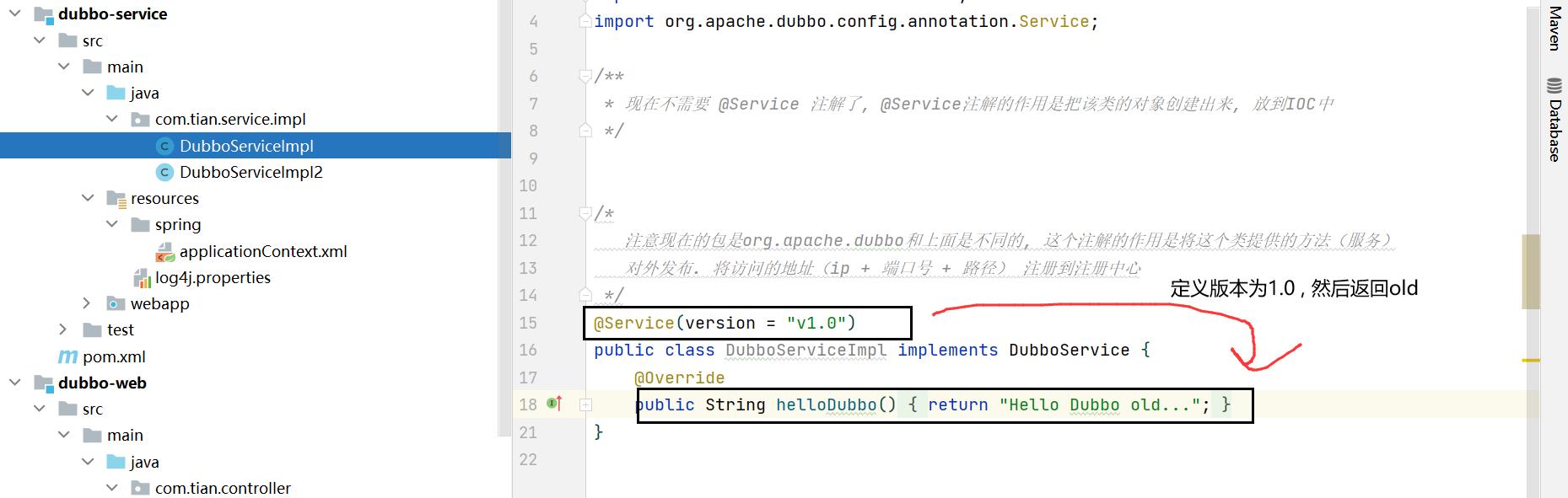
- dubbo 中使用version 属性来设置和调用同一个接口的不同版本。
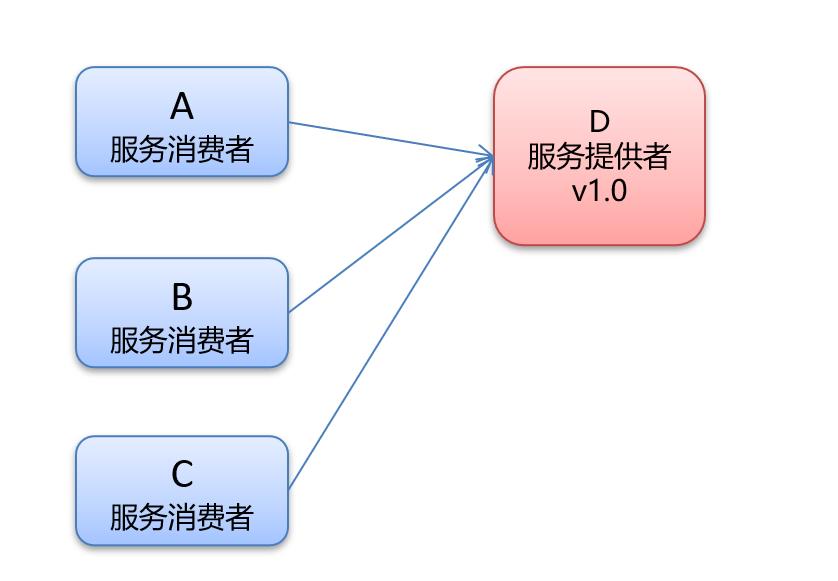
1.4.1 灰度发布图示
刚开始服务提供者的版本是1.0。
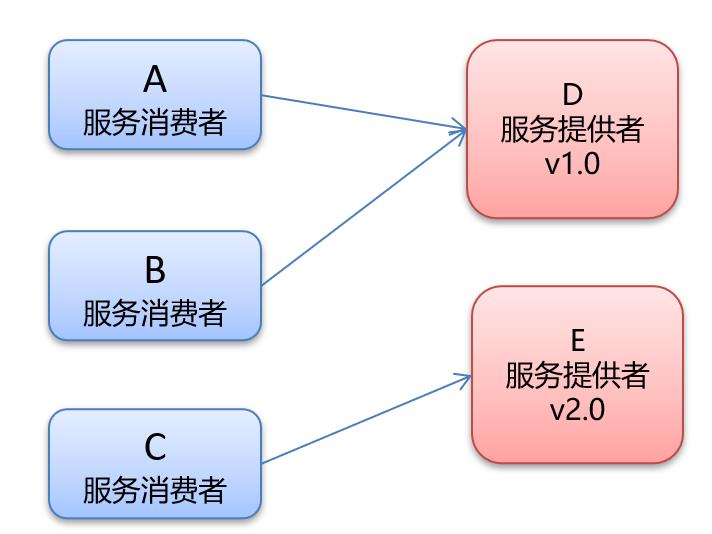
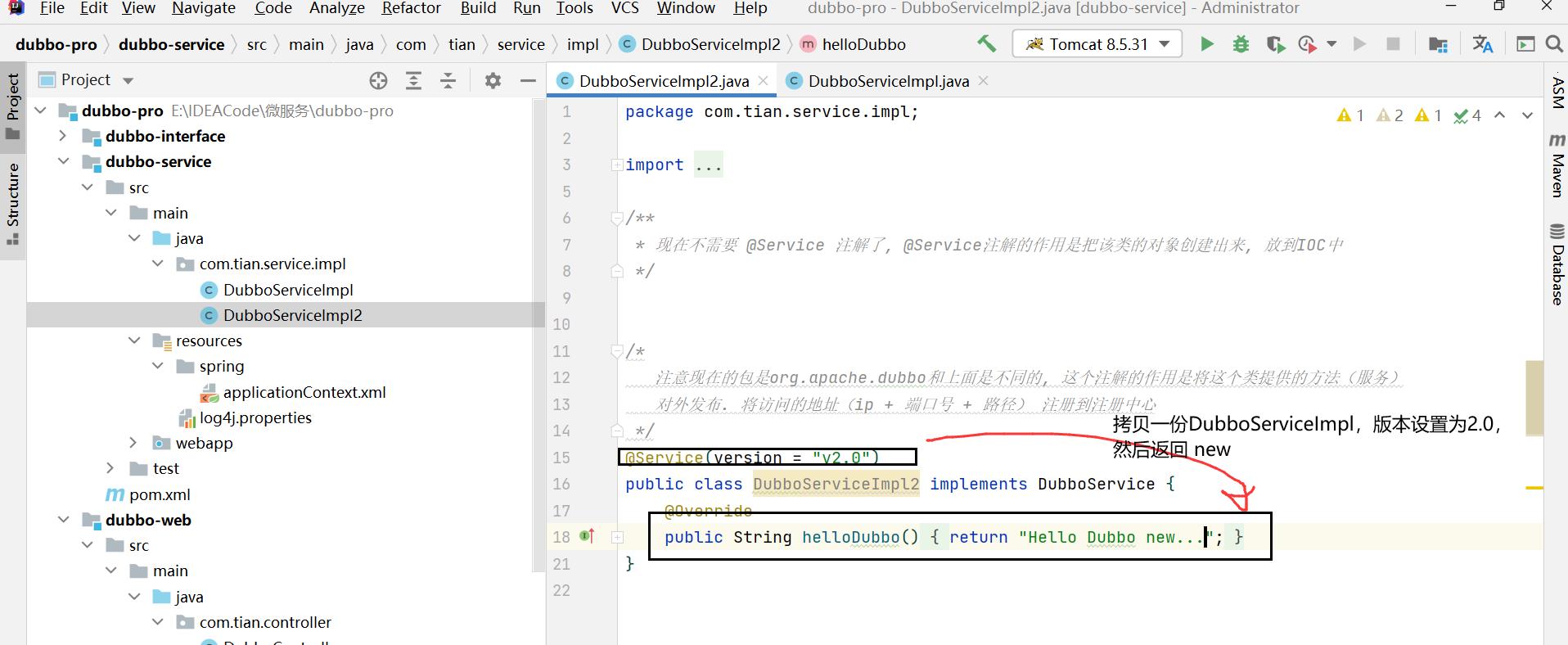
后面发布了一个新版本(2.0)的服务提供者,我们不着急将服务消费者全部迁移过去
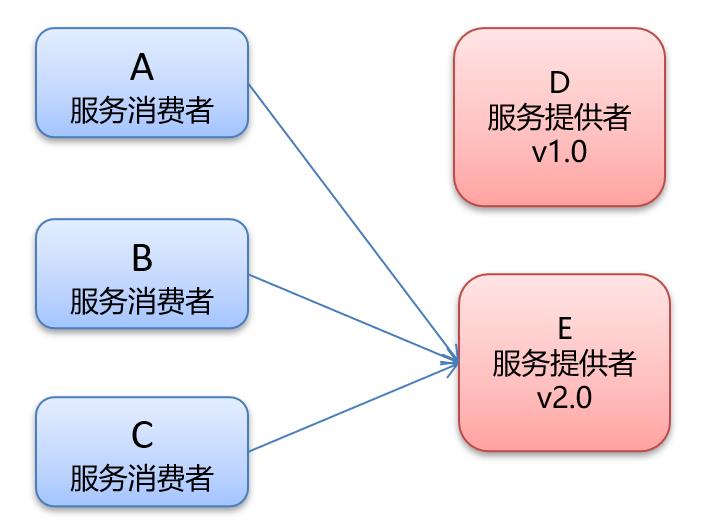
1.4.2 version 属性示例
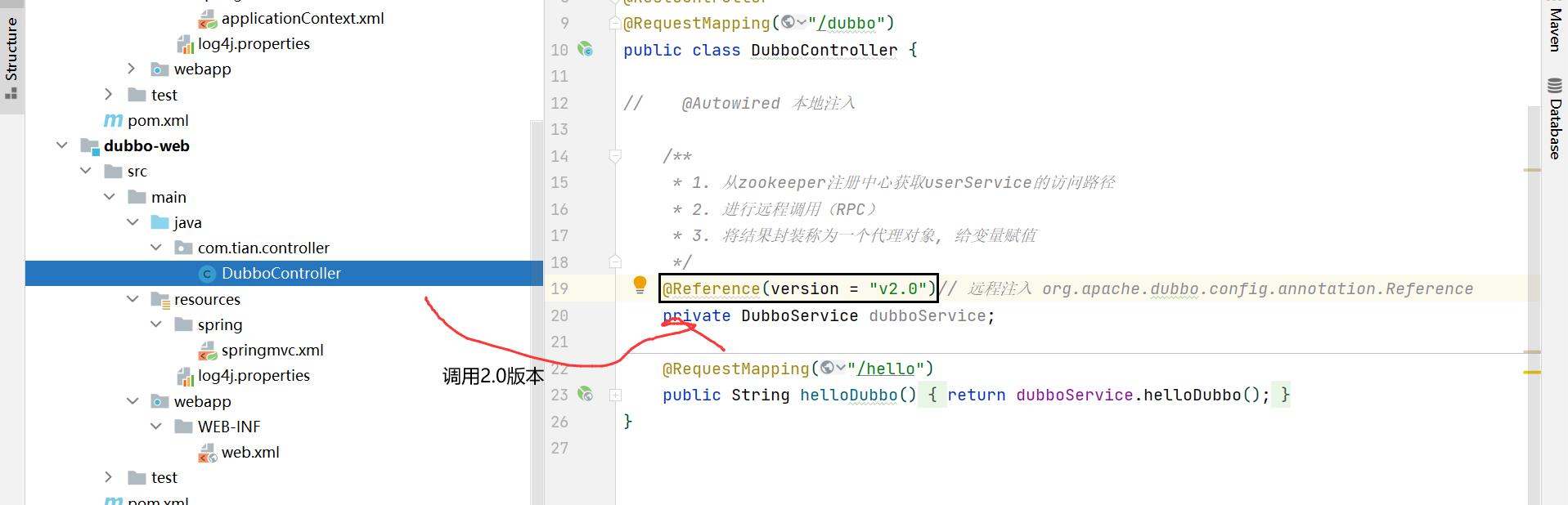
启动项目,访问测试 http://localhost:8080/dubbo/hello.do:

1.5 负载均衡
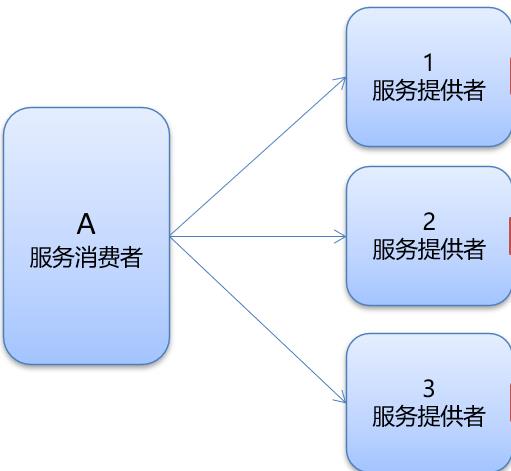
负载均衡策略(4种):
-
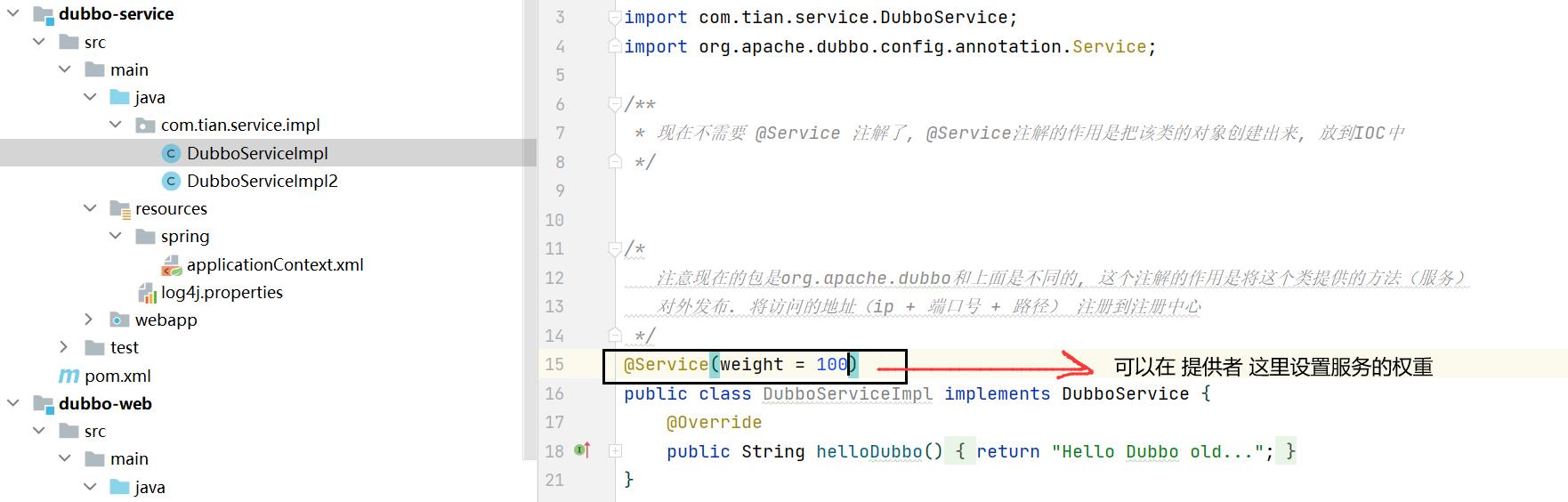
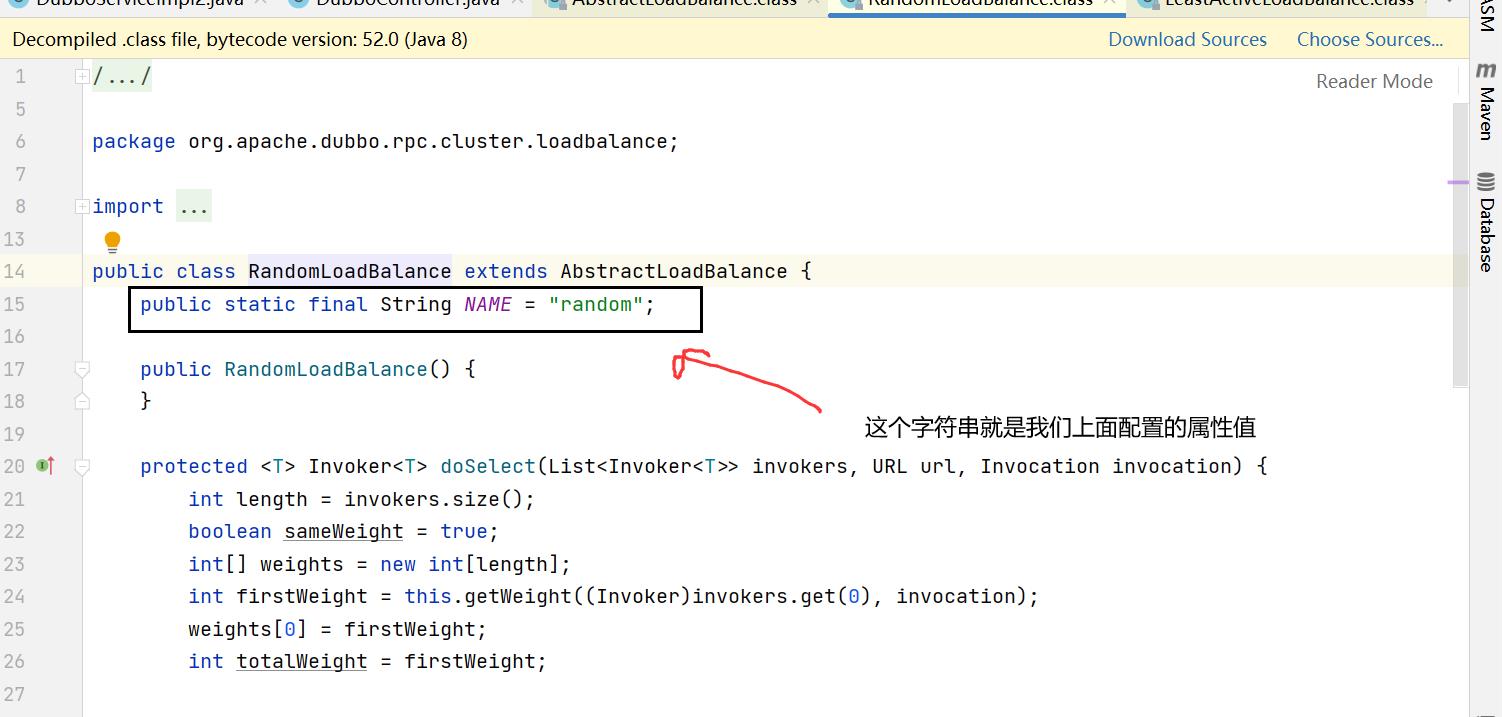
Random :按权重随机(权重值默认值为0),默认值。按权重设置随机概率。
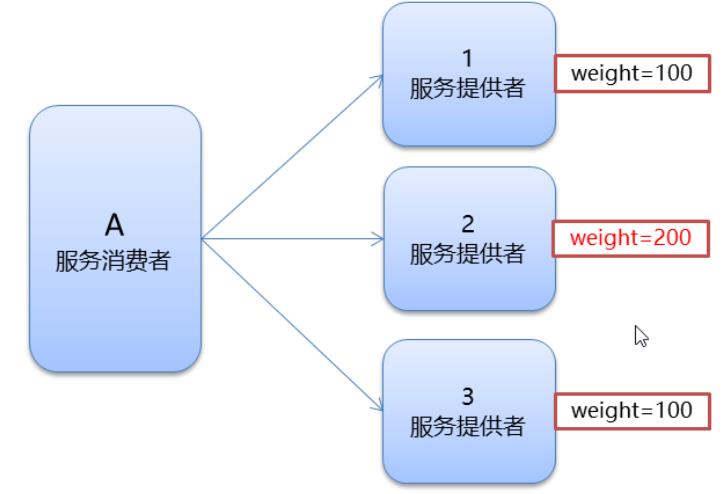
-
RoundRobin :按权重轮询。
-
LeastActive:优先调用活跃,相同活跃数的随机。 每次访问都去看一下调用服务提供者的服务所需要的时间,然后选择上一次花费时间最少的去调用。
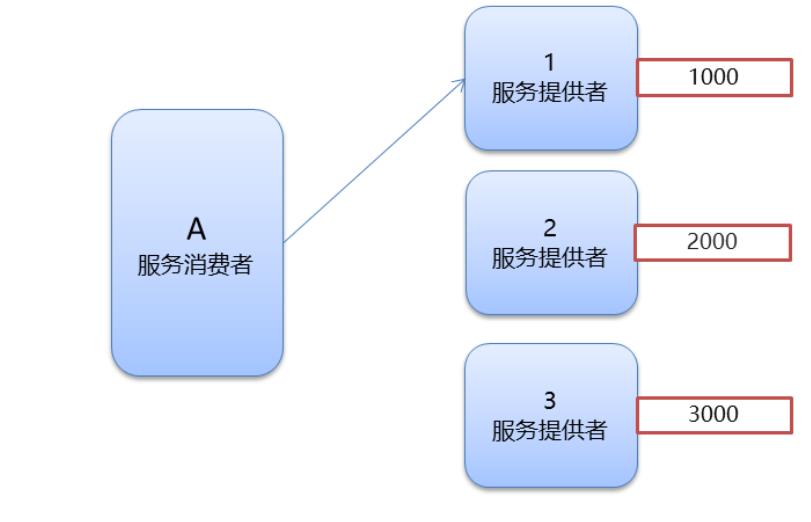
-
ConsistentHash:一致性 Hash,相同参数的请求总是发到同一提供者。比如这里可以根据id参数去选择服务提供者。
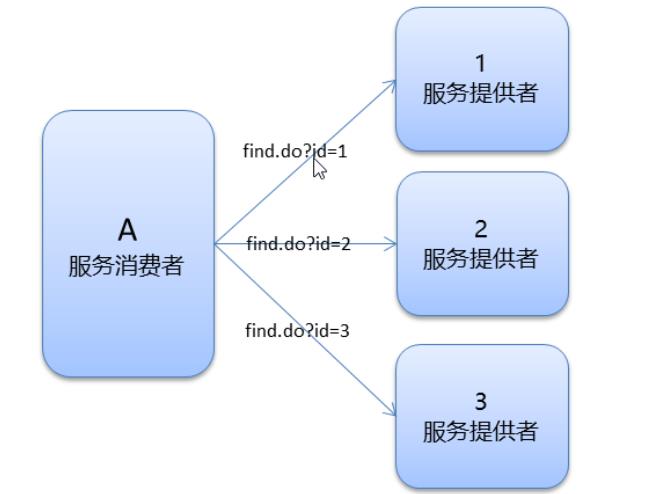
示例:
消费者这里选择负载均衡策略。
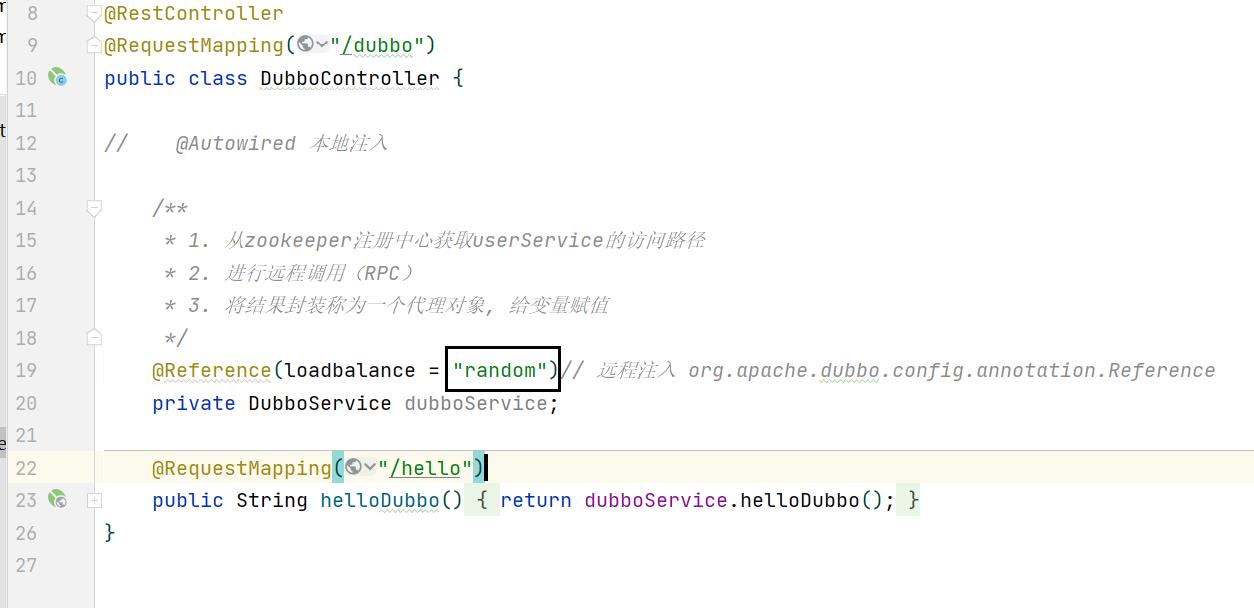
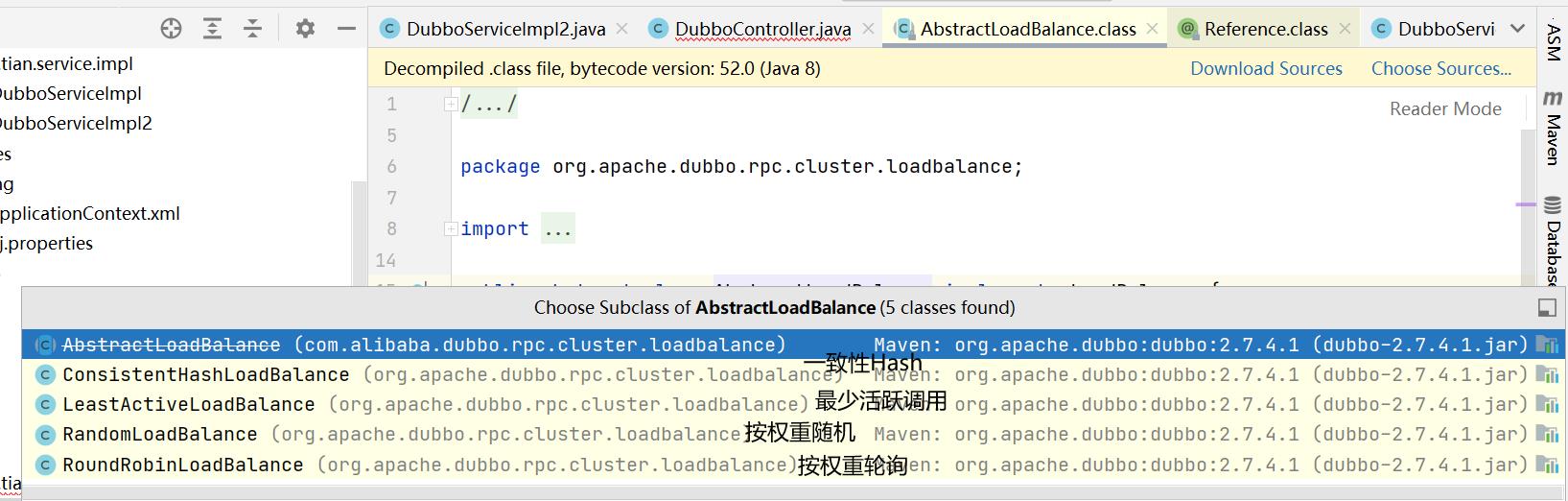
如果记不住就去查看下面这个类
org.apache.dubbo.rpc.cluster.loadbalance.AbstractLoadBalance;

1.6 集群容错策略
集群容错模式:
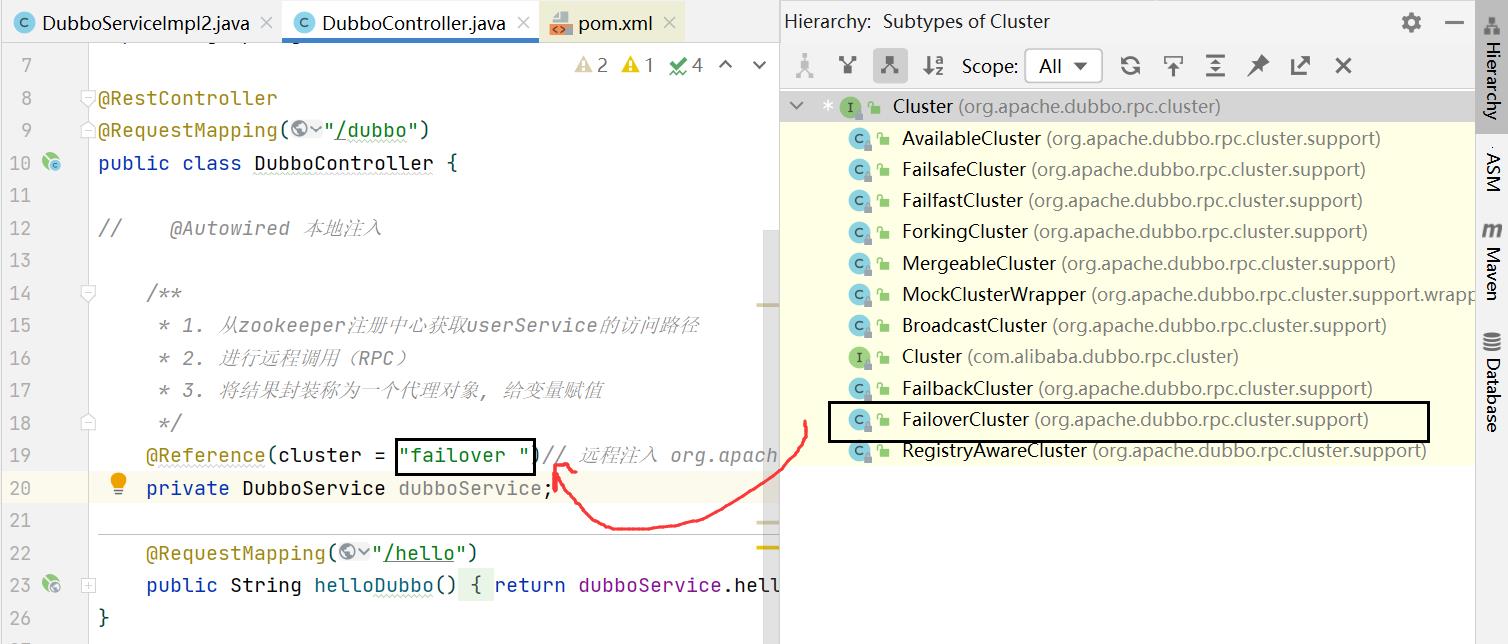
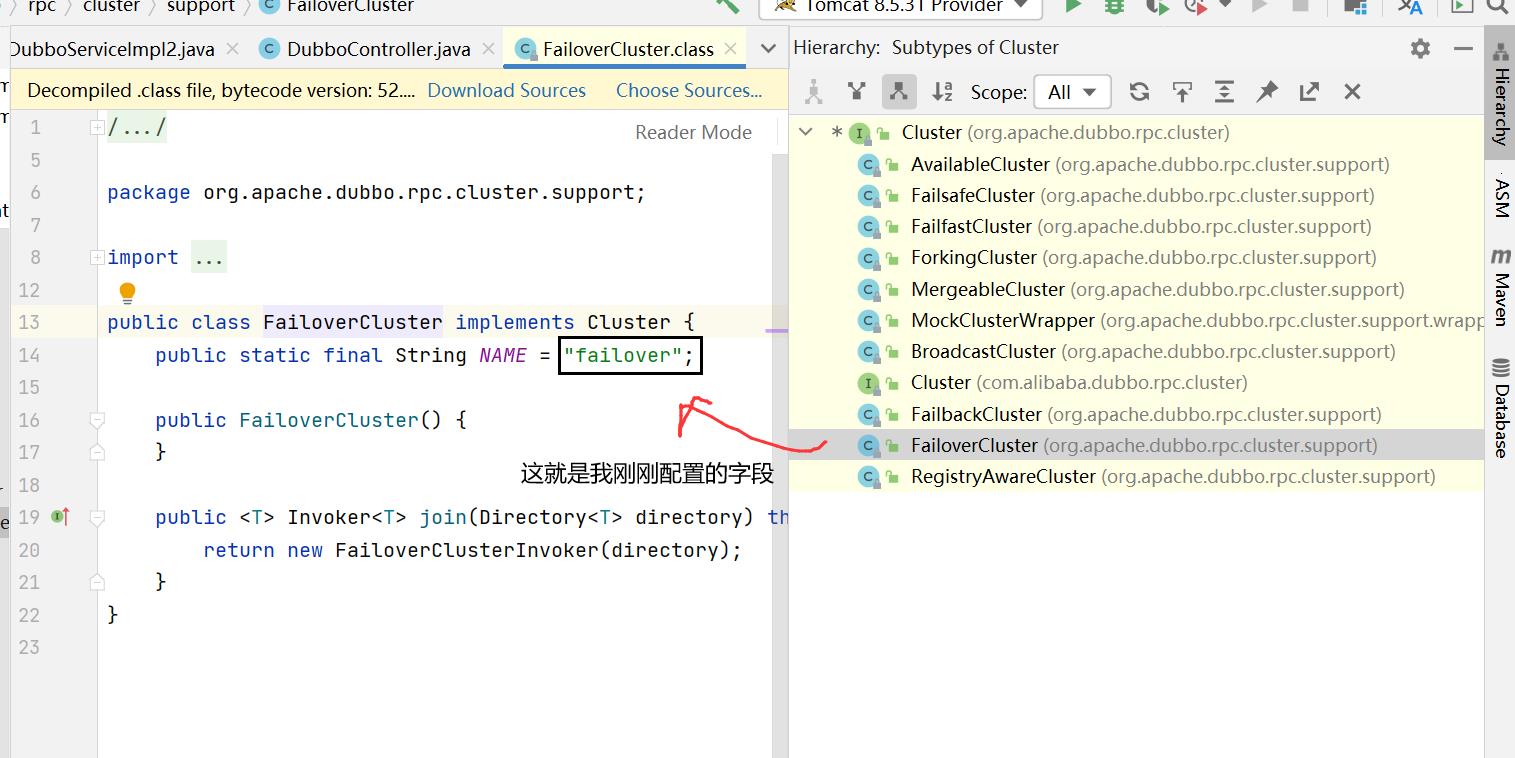
- Failover Cluster:失败重试。默认值。当出现失败,重试其它服务器 ,默认重试2次,使用 retries 配置。一般用于读操作 。
- Failfast Cluster :快速失败,只发起一次调用,失败立即报错。通常用于写操作。
- Failsafe Cluster :失败安全,出现异常时,直接忽略。返回一个空结果。
- Failback Cluster :失败自动恢复,后台记录失败请求,定时重发。通常用于消息通知操作。
- Forking Cluster :并行调用多个服务器,只要一个成功即返回。
- Broadcast Cluster :广播调用所有提供者,逐个调用,任意一台报错则报错。
示例:可以在消费者选择集群容错模式。
1.7 服务降级
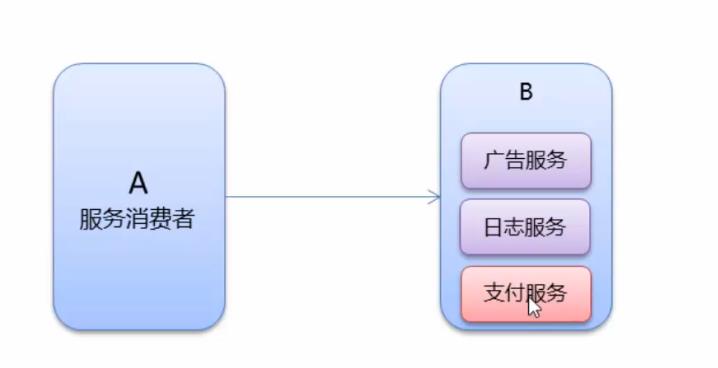
在服务器压力过大的时候,可以选择服务降级来减少某些服务占用的资源,从而使得更多的资源分配给核心业务(比如这里的 支付服务)

示例:可以在 服务消费者 来进行服务降级
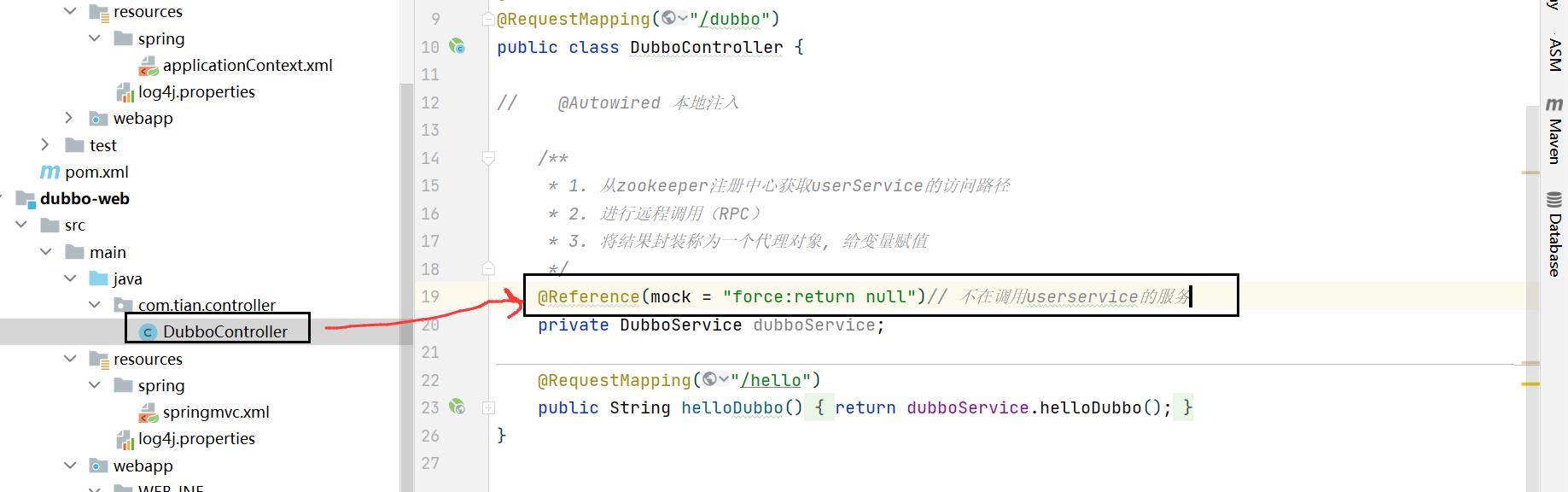
调用该服务后,不会报错,只会返会null。
以上是关于Dubbo -- dubbo高级特性(序列化 地址缓存 超时与重试机制 多版本:灰度发布 负载均衡 集群容错策略 服务降级)的主要内容,如果未能解决你的问题,请参考以下文章