一文详解机器学习中最好用的提升方法:Boosting 与 AdaBoost
Posted Python学习与数据挖掘
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了一文详解机器学习中最好用的提升方法:Boosting 与 AdaBoost相关的知识,希望对你有一定的参考价值。
在 Kaggle 及其它机器学习任务中,集成方法非常流行,不论是 还是随机森林,它们都强大无比。而本文作者从最基础的 Boosting 概念到 AdaBoost 算法进行了详细的介绍,并展示了如何实现 AdaBoost,这些都是走进集成方法大家族的敲门砖。
最近, Boosting 技术在 Kaggle 竞赛以及其它预测分析任务中大行其道。本文将尽可能详细地介绍有关 Boosting 和 AdaBoost 的相关概念。 喜欢本文记得收藏、点赞、关注。
本文将涉及:
-
对 bagging(装袋法)的快速回顾
-
bagging 的局限性
-
Boosting 的概念细节
-
boosting 的计算效率
-
代码示例
Bagging 的局限性
接下来,我们不妨考虑一个二元分类问题。我们把一个观测结果分类为 0 或 1。尽管这并不是本文的目的,但是为了清晰起见,让我们回顾一下 Bagging 的概念。
Bagging 指的是一种叫做「Bootstrap Aggregating」(自助聚合)的技术。其实质是选取 T 个 bootstrap 样本,在每个样本安装一个分类器,然后并行训练模型。通常,在随机森林中,决策树是并行训练的。然后,将所有分类器的结果平均化,得到一个 bagging 分类器:

Bagging 分类器的公式
该过程可以通过以下方式来说明。让我们考虑 3 个分类器,它们生成一个分类结果,该结果可能是对的也可能是错的。如果我们绘制 3 个分类器的结果,会有一些区域代表分类器的结果是错误的。在下图中,这样的区域用红色表示:
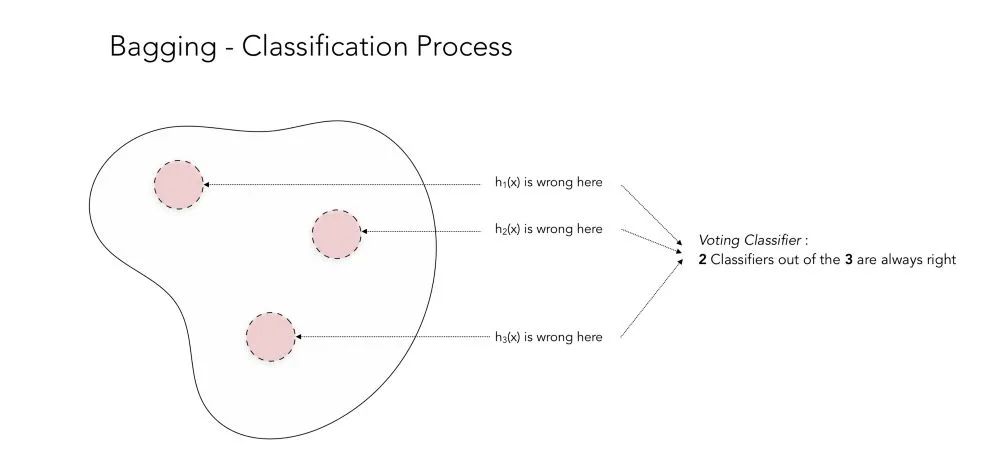
_Bagging 适用场景的示例
_
这个示例可以很好地起到说明作用,其中有一个分类器的结果是错误的,而另外两个分类器的结果是正确的。通过对分类器进行投票,你可以获得很高的分类准确率。但正如你可能会猜到的那样,bagging 机制有时并不能很好地起作用,这时所有的分类器都会在同一个区域内获得错误的分类结果。
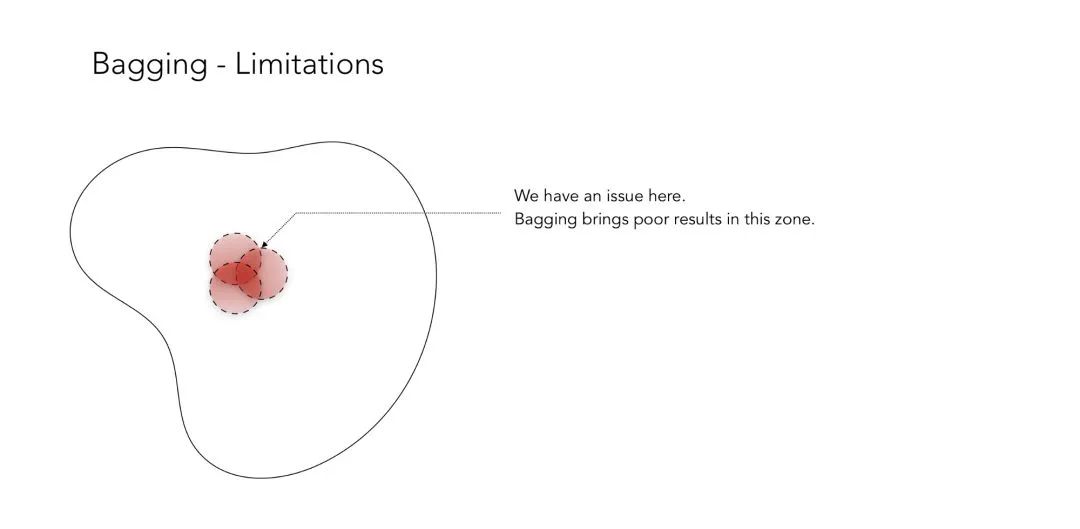
出于这个原因,对 boosting 方法背后的直观想法是:
-
我们需要串行训练模型,而不是并行训练。
-
每个模型需要重点关注之前的分类器表现不佳的地方。
**Boosting 简介
**
概念
上述想法可以诠释为:
-
在整个数据集上训练模型 h1
-
对 h1 表现较差的区域的数据加权,并在这些数据上训练模型 h2
-
对 h1 ≠ h2 的区域的数据加权重,并在这些数据上训练模型 h3
-
…
我们可以串行地训练这些模型,而不是并行训练。这是 Boosting 的本质!
Boosting 方法会随着时间的推移,通过调整误差度量来训练一系列低性能算法,称之为弱学习器。弱学习器指的是那些误差率略低于 50% 的算法,如下图所示:
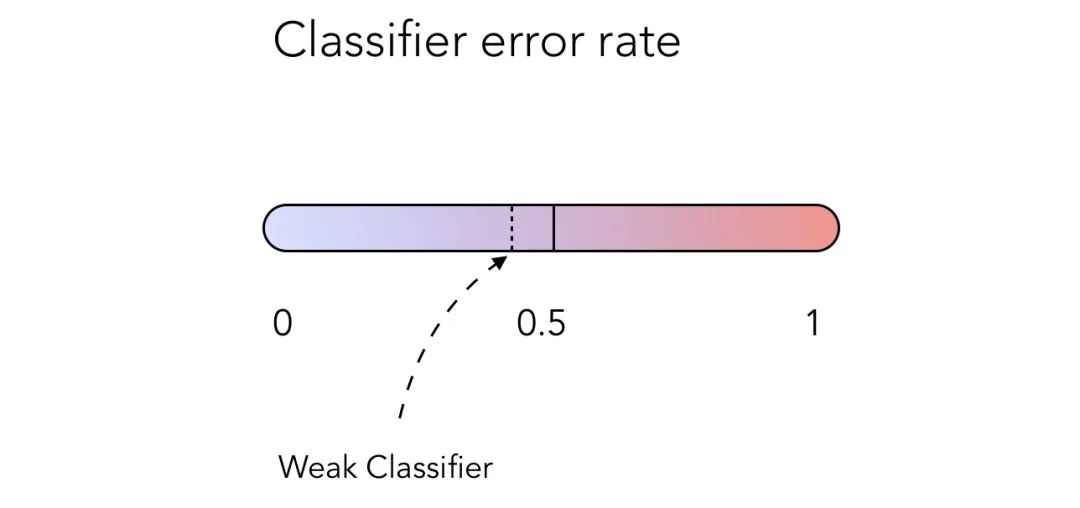
_误差率略低于 50% 的弱分类器
_
加权误差
我们如何才能实现这样的分类器呢?实际上,我们是通过在整个迭代过程中加权误差做到的。这样,我们将为之前分类器表现较差的区域赋予更大的权重。
不妨想想二维图像上的数据点。有些点会被很好地分类,有些则不会。通常,在计算误差率时,每个误差的权重为 1/n,其中 n 是待分类的数据点个数。
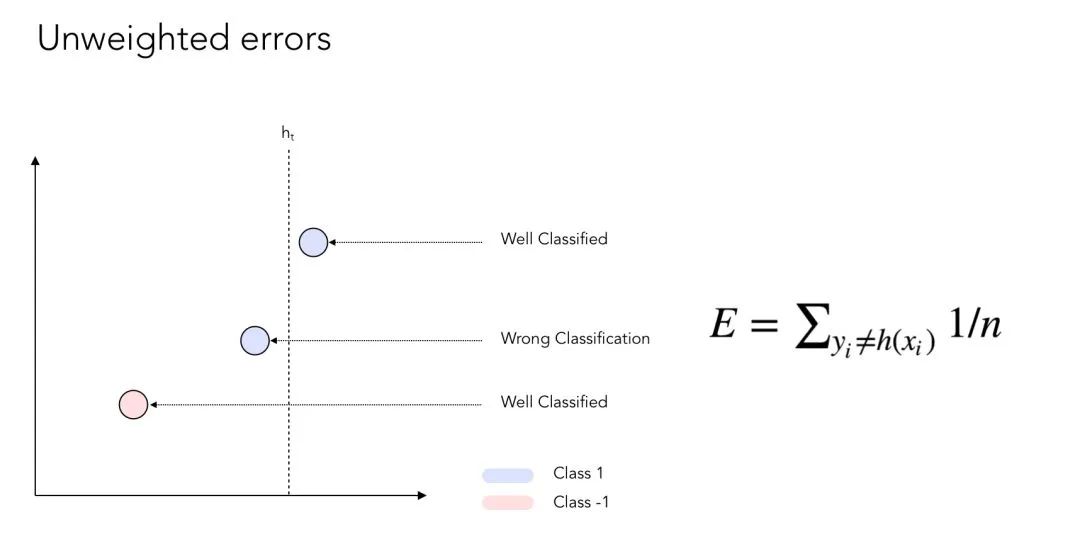
_未加权的误差
_
现在让我们对误差进行加权!
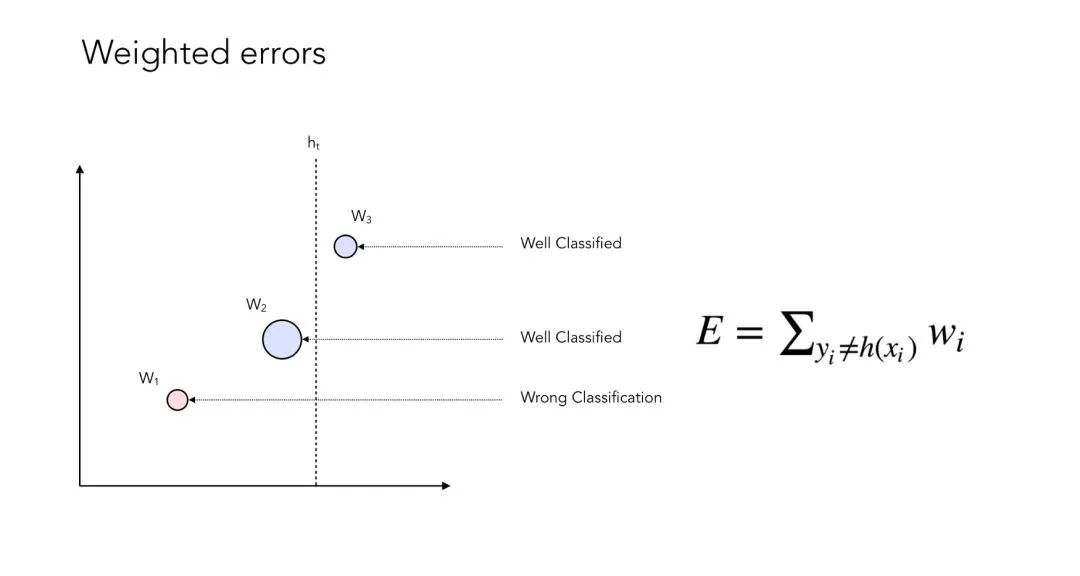
_加权后的误差
_
现在,你可能注意到了,我们对没有被很好地分类的数据点赋予了更高的权重。加权的过程如下图所示:
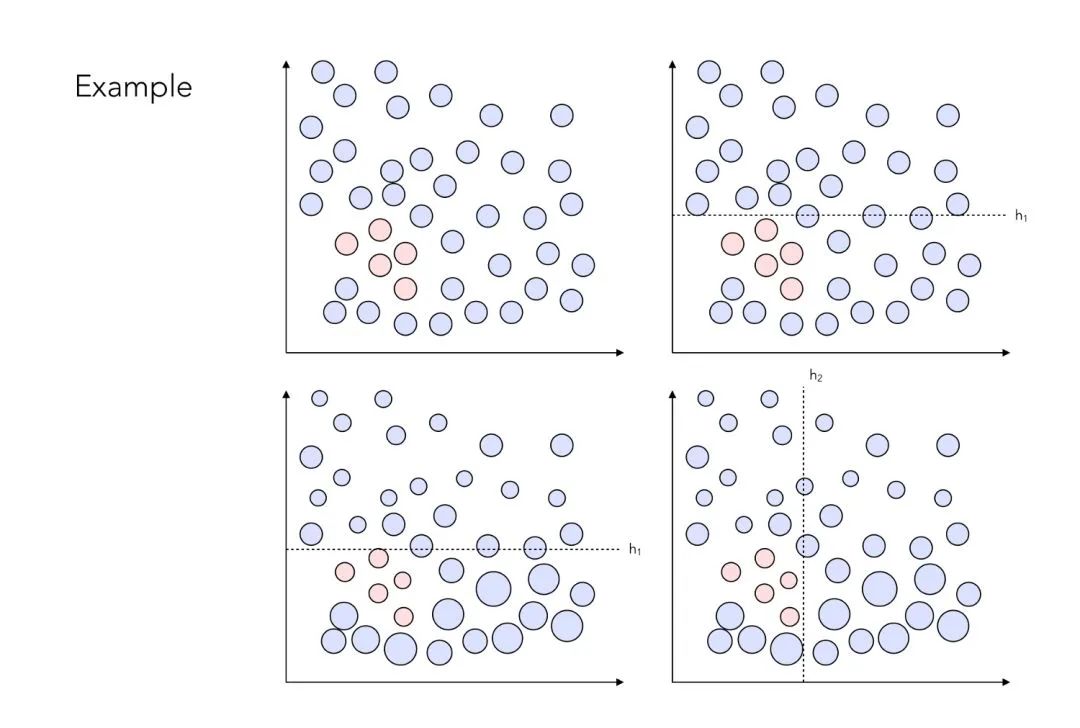
_加权过程示例
_
最终,我们希望构建如下图所示的强分类器:
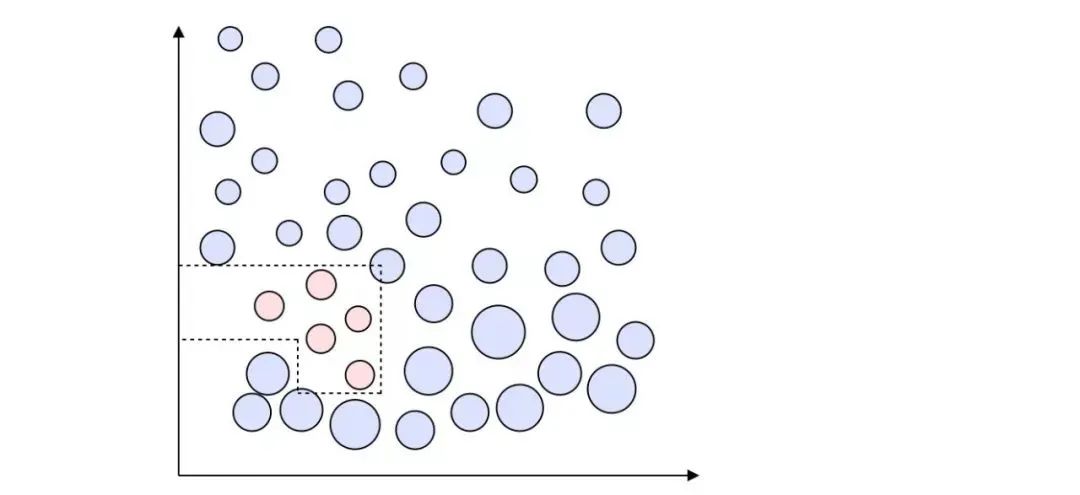
_强分类器
_
决策树桩
你可能会问,我们需要实现多少个分类器才能让整个 Boosting 系统很好地工作呢?在每一步中如何选择分类器?
答案是所谓的「决策树桩」!决策树桩是指一个单层决策树。主要思想是,我们在每一步都要找到最好的树桩(即得到最佳的数据划分),它能够使整体的误差最小化。你可以将一个树桩看做一个测试,其中,我们假设位于树桩某一侧的所有数据点都属于 1 类,另一侧的所有数据点都属于 0 类。
决策树桩的组合可能有很多种。接下来,让我们看看在这个简单的示例中有多少种树桩组合?
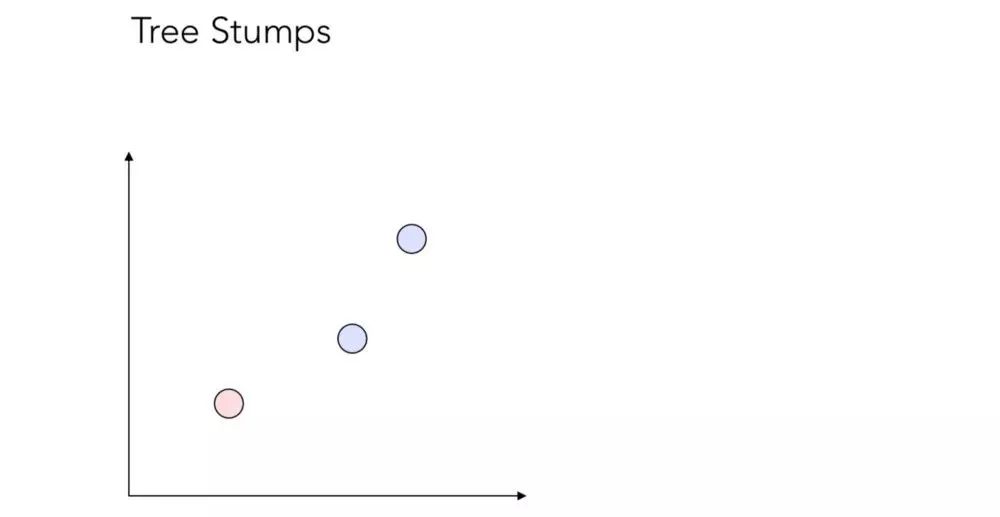
_待划分的 3 个数据点
_
实际上,本例中有 12 种树桩组合!这看起来可能有些令人惊讶,但其实很容易理解。
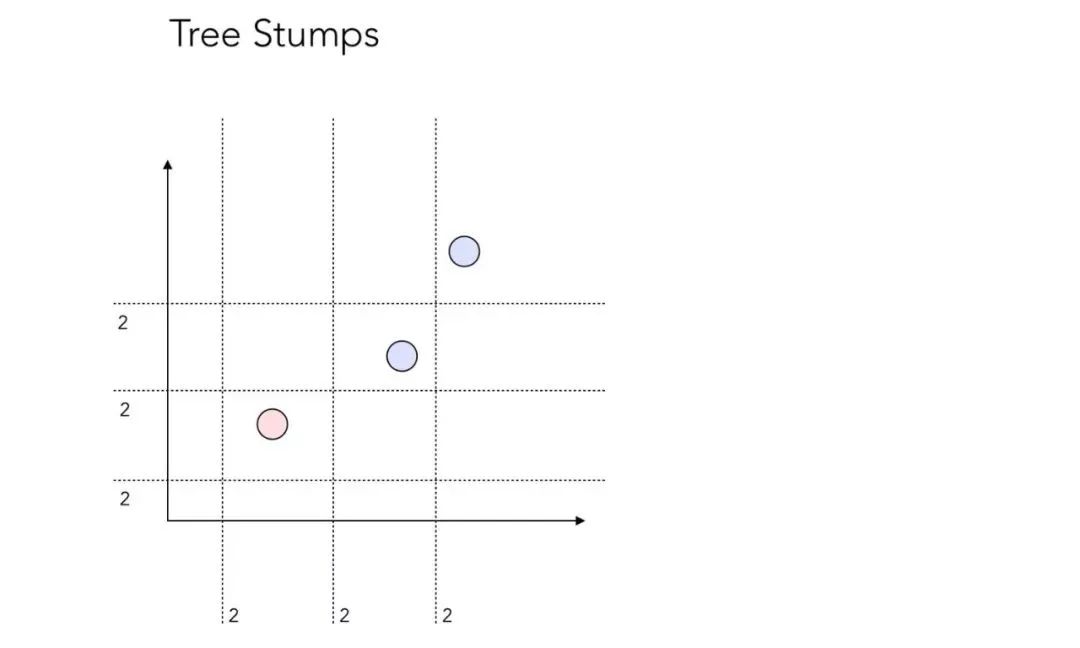
_12 个决策树桩
_
我们可以对上面的情况做 12 种可能的「测试」。每条分割线边上的数字「2」简单地表示了这样一个事实:位于分割线某一侧的所有点都可能属于 0 类或 1 类。因此,每条分割线嵌入了 2 个「测试」。
在每一轮迭代 t 中,我们将选择能够最好地划分数据的弱分类器 ht,该分类器能够最大限度地降低整体误差率。回想一下,这里的误差率是一个经过加权修正之后的误差率版本,它考虑到了前面介绍的内容。
寻找最佳划分
如上所述,通过在每轮迭代 t 中识别最佳弱分类器 ht(通常为具有 1 个节点和 2 片叶子的决策树(决策树桩))来找到最佳划分。假设我们试图预测一个想借钱的人是否会是一个好的还款人:
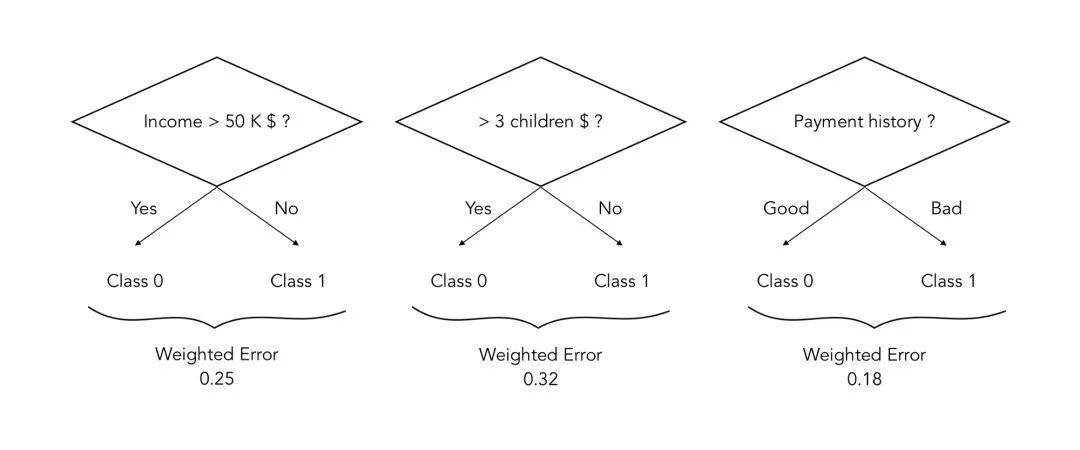
_找出最佳划分
_
在这种情况下,t 时刻的最佳划分是将「支付历史」作为树桩,因为这种划分的加权误差是最小的。
只需注意,实际上,像这样的决策树分类器可能具备比简单的树桩更深的结构。这将会是一个超参数。
融合分类器
自然而然地,下一步就应该是将这些分类器融合成一个符号分类器。根据某个数据点处于分割线的哪一侧,将其分类为 0 或 1。该过程可以通过如下方式实现:
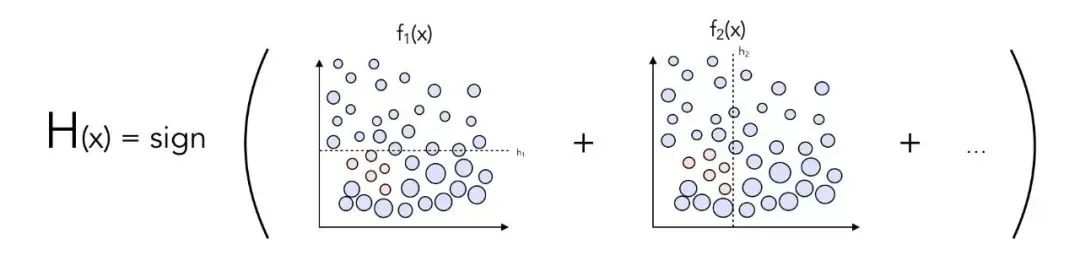
_融合分类器
_
你发现了可能提升分类器性能的方法吗?
通过为每个分类器加权,可以避免赋予不同的分类器相同的重要性。
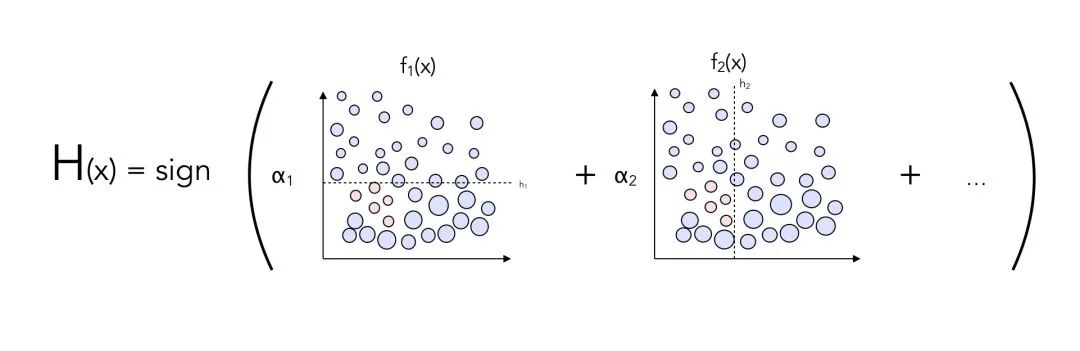
_AdaBoost
_
小结一下
让我们把到目前为止本文已经介绍过的内容总结在一段小小的伪代码中。

_伪代码
_
其中需要记住的关键点是:
-
Z 是一个常数,其作用是对权重进行归一化,使得它们加起来等于 1!
-
α_t 是应用于每个分类器的权重
大功告成!这种算法就是「AdaBoost」。如果你想充分理解所有的 boosting 方法,那么这是你需要理解的最重要的算法。
计算
Boosting 算法训练起来非常快,这太棒了。但是我们考虑到了所有树桩的可能性并且采用了递归的方法计算指数,为什么它还会训练地这么快?
现在,神奇的地方来了!如果我们选择了恰当的 α_t 和 Z,本该在每一步变化的权重将简化成如下的简单形式:

_选择了恰当的α 和 Z 之后得到的权重
_
这是一个非常强的结论,这与权重应该随着迭代而变化的说法并不矛盾。因为错误分类的训练样本数量减少了,它们的总权重仍然是 0.5!
-
无需计算 Z
-
无需计算 α
-
无需计算指数
另外一个小诀窍是:任何试图将两个已经被很好地分类的数据点划分开的分类器都不会是最优的。我们甚至不需要对其进行计算。
动手编程试一下吧!
现在,本文将带领读者快速浏览一个代码示例,看看如何在 Python 环境下使用 Adaboost 进行手写数字识别。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.ensemble import AdaBoostClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import cross_val_predict
from sklearn.model_selection import train_test_split
from sklearn.model_selection import learning_curve
from sklearn.datasets import load_digits
首先,载入数据:
dataset = load_digits()
X = dataset['data']
y = dataset['target']
X 包含长度为 64 的数组,它们代表了简单的 8x8 的平面图像。使用该数据集的目的是为了完成手写数字识别任务。下图为一个给定的手写数字的示例:

如果我们坚持使用深度为 1 的决策树分类器(决策树桩),以下是如何在这种情况下实现 AdaBoost 分类器:
reg_ada = AdaBoostClassifier(DecisionTreeClassifier(max_depth=1))
scores_ada = cross_val_score(reg_ada, X, y, cv=6)
scores_ada.mean()
这样得到的分类准确率的结果应该约为 26%,还具有很大的提升空间。其中一个关键的参数是序列决策树分类器的深度。那么,决策树的深度如何变化才能提高分类准确率呢?
score = []
for depth in [1,2,10] :
reg_ada = AdaBoostClassifier(DecisionTreeClassifier(max_depth=depth))
scores_ada = cross_val_score(reg_ada, X, y, cv=6)
score.append(scores_ada.mean())
在这个简单的例子中,当决策树的深度为 10 时,分类器得到了最高的分类准确率 95.8%。
结语
研究人员已经针对 AdaBoost 是否会过拟合进行了深入的探讨。近来,AdaBoost 被证明在某些时候会发生过拟合现象,用户应该意识到这一点。同时,Adaboost 也可以作为回归算法使用。
参考链接:https://towardsdatascience.com/boosting-and-adaboost-clearly-explained-856e21152d3e_
推荐文章
技术交流
欢迎转载、收藏、有所收获点赞支持一下!

目前开通了技术交流群,群友已超过2000人,添加时最好的备注方式为:来源+兴趣方向,方便找到志同道合的朋友
- 方式①、发送如下图片至微信,长按识别,后台回复:加群;
- 方式②、添加微信号:dkl88191,备注:来自CSDN
- 方式③、微信搜索公众号:Python学习与数据挖掘,后台回复:加群

以上是关于一文详解机器学习中最好用的提升方法:Boosting 与 AdaBoost的主要内容,如果未能解决你的问题,请参考以下文章