python数据分析基础008 -利用pandas带你玩转excel表格(中下篇)
Posted 苏凉.py
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python数据分析基础008 -利用pandas带你玩转excel表格(中下篇)相关的知识,希望对你有一定的参考价值。
文章要点
🐚作者简介:苏凉(专注于网络爬虫,数据分析)
🐳博客主页:苏凉.py的博客
👑名言警句:海阔凭鱼跃,天高任鸟飞。
📰要是觉得博主文章写的不错的话,还望大家三连支持一下呀!!!
👉关注✨点赞👍收藏📂

🍺前言
上篇文章带着大家一起学习了在pandas中如何对excel表格进行创建和修改,还有一些基本的操作,接下来我们一起再深入的去了解pandas在excel中其他的一些有趣的操作吧!!
往期回顾:
1.python数据分析基础001 -matplotlib的基础绘图
2.python数据分析基础002 -使用matplotlib绘图(散点图,条形图,直方图)
3.python数据分析基础003 -numpy的使用(详解)
4.python数据分析基础004 -numpy读取数据以及切片,索引的使用
5.python数据分析基础005 -pandas详解_pandas入门这一篇就足够了
6.python数据分析基础006 -利用pandas带你玩转excel表格(上篇)
7.python数据分析基础007 -利用pandas带你玩转excel表格(中上篇)
🍁(一)利用pandas将excel中的数据绘制成可视化图形
实例:对这样的一组数据进行数据可视化,绘制成一张条形图
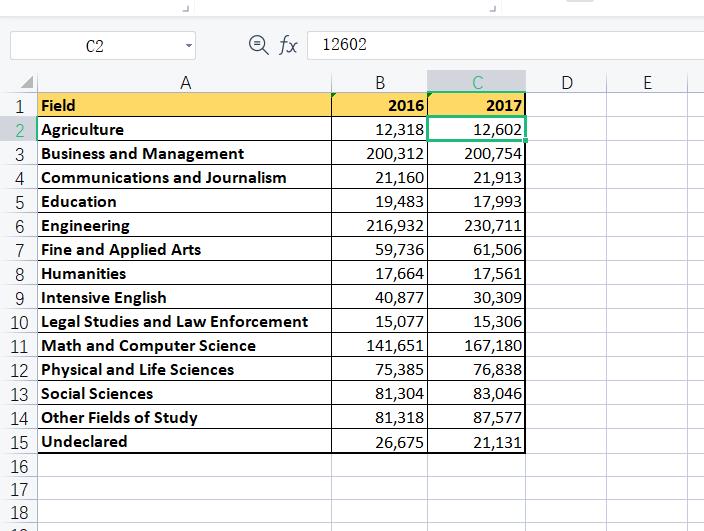
🔥1.在excel中实现
在excel中插入一个柱状图即可。

若需将他进行从大到小来进行比较则需要在原数据上先进行排序。
最后在进行标题以及坐标轴的美化
效果如下:

要在python中实现上述在excel中的操作,该如何做呢?下面就让我们在python下实现吧!利用pandas和matplotlib绘制出来的图形更直观。
🔥2.在pandas中实现
- 导入pandas以及matplotlib模块
import pandas as pd
from matplotlib import pyplot as plt
- 读取excel表格数据,并将其进行排序
student_data = pd.read_excel('./excel/testpicture.xlsx')
df = pd.DataFrame(student_data)
# 对数据进行排序
df.sort_values(by=['2016','2017'],inplace=True,ascending=False)
- 绘制图形,并对x轴的说明进行调整
# 绘制条形图
df.plot.bar(x = 'Field',y = ['2016','2017'] , color = ['red', 'blue'])
# plt.xticks(rotation = 45,ha= 'right')
# 获取x轴,对x轴的说明进行调整,rotation表示倾斜的度数,ha表示水平旋转
ax = plt.gca()
ax.set_xticklabels(df['Field'] ,rotation = 45, ha = 'right')
- 设置xy轴以及标题的说明
# 设置xy轴的说明
plt.xlabel('field')
plt.ylabel('data of number')
# 加标题
plt.title("Student of Number" ,fontsize =20,color = 'green')
- 使图片完整显示(两种方法)
# 对于标签名字太长显示不全,可以用tight_layout()将标签在图中完全显示出来
# plt.tight_layout()
# 获取图形,调整图形与边缘的距离
picture= plt.gcf()
picture.subplots_adjust(left =0.5 ,bottom = 0.1)
- 保存及展示
plt.savefig('./excel.png')
plt.show()
结果:
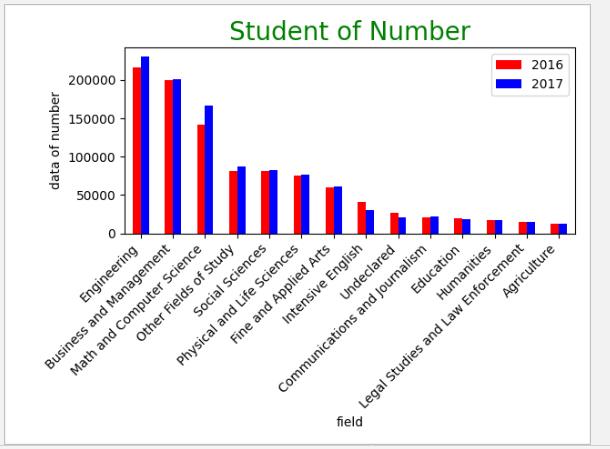
利用pandas和matplotlib结合绘制出的图形可以设置更多的参数,可以让图形变的更加美观也更直观。
✈补充:pandas的其他绘图方法
🍁(二)利用pandas实现多表联合
在一个ecxel中可以有很多张表,通常这些表合并在一起又会生成一个新的数据。
实例:将这两张表的学生成绩打印出来
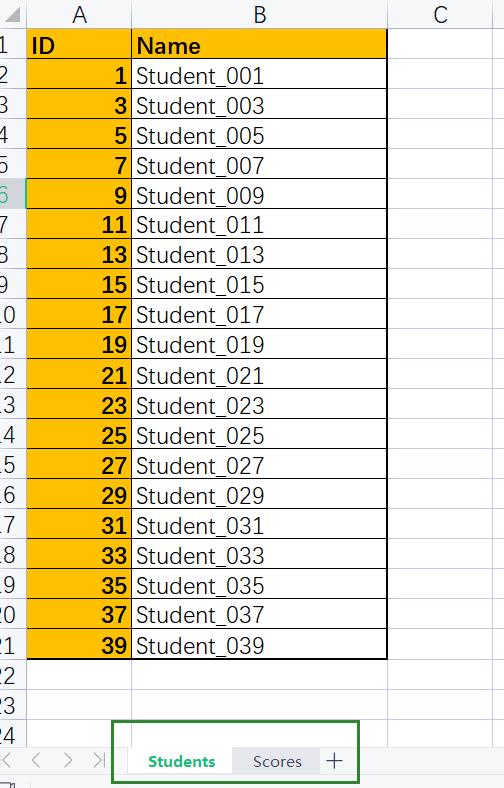

🔥1.在excel中实现
使用VLOOKUOP函数进行联合
📌注:在VLOOKUP中若是匹配不到数值,则会进行近似匹配,如上结果所示,21号学生成绩不存在,则近似匹配上一个的值。

若不想近似匹配则将默认值改为True。
=VLOOKUP(A2,Scores!A1:B21,2,FALSE)
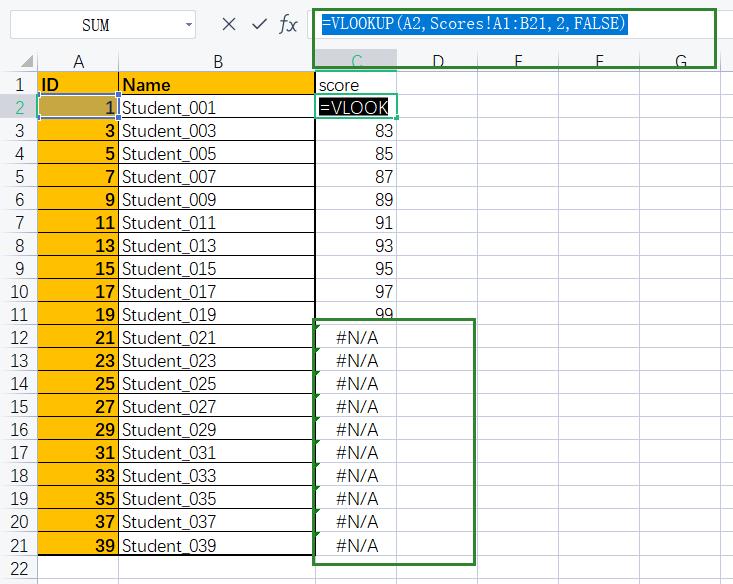
若要显示为0,则需要用到IFNA函数。
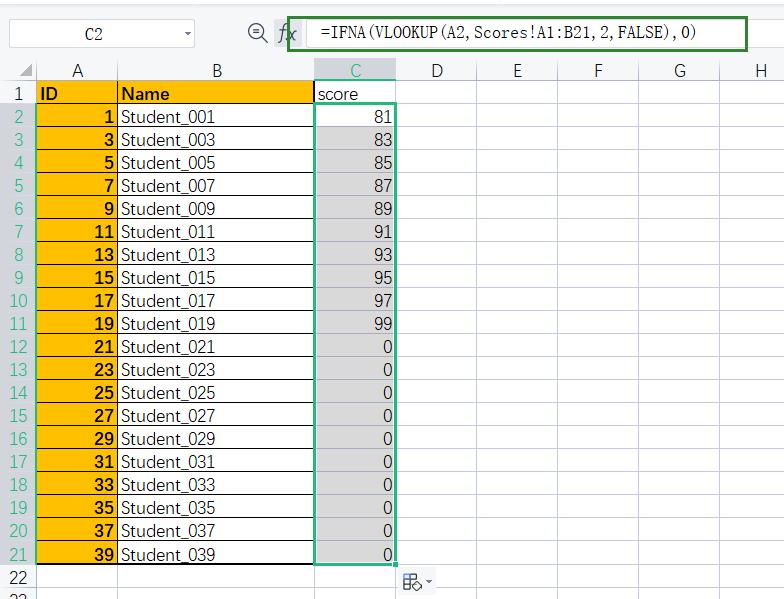
这样就完成了将两表联合查询到了学生的成绩。那么在pandas中该如何实现呢?
🔥2.在pandas中实现
在pandas中打开excel时加入参数sheet_name即可选定指定的表
student = pd.read_excel('./excel/testone.xlsx',sheet_name='Students')
score = pd.read_excel('./excel/testone.xlsx',sheet_name='Scores')
将两张表拼接起来使用,这样的操作对应到SQL中是join,而在pandas中则是用merge来实现。
注:在使用merge时默认为inner,即没有匹配到的值则丢弃。 这时需使用参数how来保留原表数据。fillna用来将Nan转换为0。
on 用来匹配数值通常为两表列名相同,若两表的列名不同则分别用left_on 和right_on指出,
import pandas as pd
student = pd.read_excel('./excel/testone.xlsx',sheet_name='Students')
score = pd.read_excel('./excel/testone.xlsx',sheet_name='Scores')
df_student = pd.DataFrame(student)
df_score = pd.DataFrame(score)
# how 表留左边表格数据,on按照id匹配,fillna将没有匹配到的值赋予0
# result = student.merge(score,how='left',on='ID').fillna(0)
result = student.merge(score,how='left',left_on='ID',right_on='ID').fillna(0)
# 修改Score的数据类型原本为float
result.Score = result.Score.astype(int)
print(result)
结果:

🍁(三)数据校验
在excel表格中,通常会有一些数据不符合我们的规范要求,从而导致我们的到的数据不准确,因此我们需要将他们筛选出来。那么我们该怎么做呢?
实例:将成绩不符合0-100的数据筛选出来
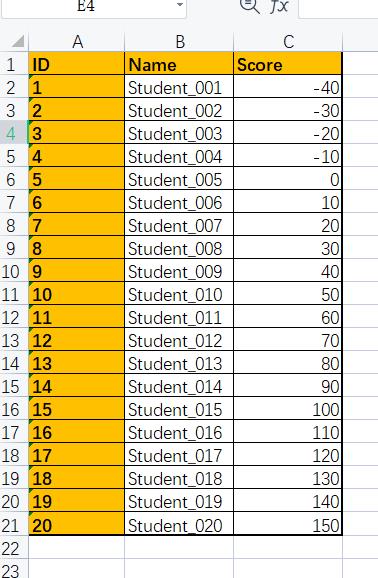
🔥1.在excel表格中实现
在数据栏找到有效性并设置数值范围,随后将不符合的值圈出即可。
结果:
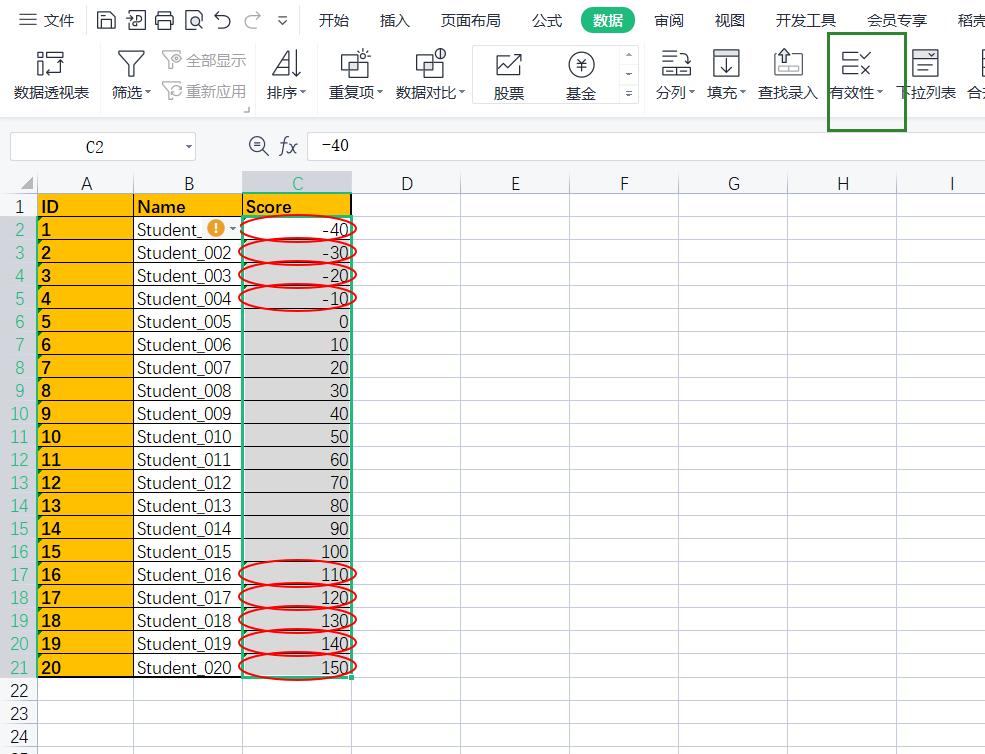
需要找出不符合的数据,在pandas中又如何操作呢?
🔥2.在pandas中实现
在实现上述结果前定义函数来作为条件判断
import pandas as pd
def Score_false(x):
if not 100>= x.Score >=0 :
print("ID为,姓名为:的学生成绩异常,成绩为:".format(x.ID,x.Name,x.Score))
score = pd.read_excel('./excel/testtwo.xlsx')
df = pd.DataFrame(score)
# axis=1则从行查询 axis=0则从列查询
df.apply(Score_false,axis=1)
结果:

🍁(四)拆分列
在excel中存在复合列,我们要将这些列拆分才方便数据的查询,那么该如何去操作呢?
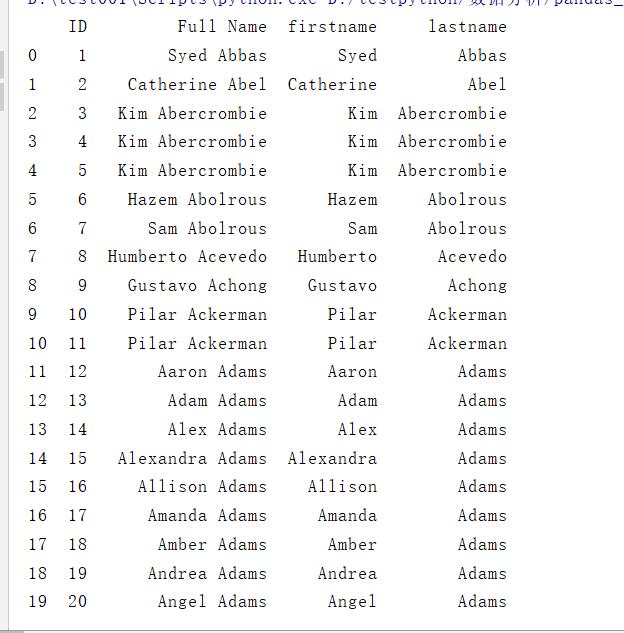
实例:将该表中的Full Name进行拆分。
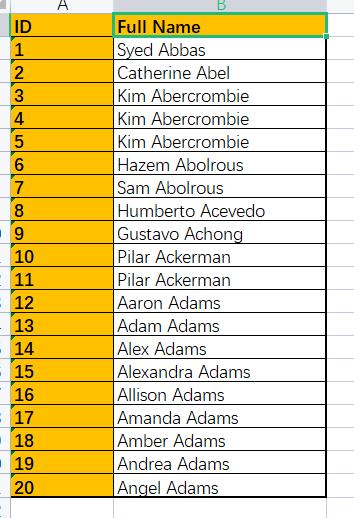
🔥1.在excel中实现
在数据栏中找到分列选项,在此分隔符为空格,按照实际情况来定。
结果:

那么在pandas中又如何实现呢?
🔥2.在pandas中实现
在pandas中需要用到字符串进行拆分
import pandas as pd
test = pd.read_excel('./excel/testthree.xlsx')
df = pd.DataFrame(test)
name = df['Full Name'].str.split(expand = True)
df['firstname'] = name[0]
df['lastname'] = name[1]
print(df)
结果:
🍻结语
今天的内容就到这里啦,希望看到此文的小伙伴能有所收获,另外pandas在excel中还有很多操作需要探索,关注我,咱们下期再见!!

以上是关于python数据分析基础008 -利用pandas带你玩转excel表格(中下篇)的主要内容,如果未能解决你的问题,请参考以下文章