6-机器学习场景下Volcano集成调度能力实践
Posted 琦彦
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了6-机器学习场景下Volcano集成调度能力实践相关的知识,希望对你有一定的参考价值。
6-机器学习场景下Volcano集成调度能力实践
今天主要给大家分享如何使用Volcano调度器运行一个TF Job。
今天的分享主要包括3个部分的内容:
- Kubeflow简介
- Kubeflow on Volcano
- 演示(运行一个简单的机器学习作业)
01 Kubeflow简介
• Kubeflow是Kubernetes的机器学习工具包,是运行在K8s之上的一套技术栈,包括很多个组件,这些组件可以单独使用,也可以互相配合使用。
• 在Kubernetes机器中上对机器学习流程中的各个阶段提供技术支持。
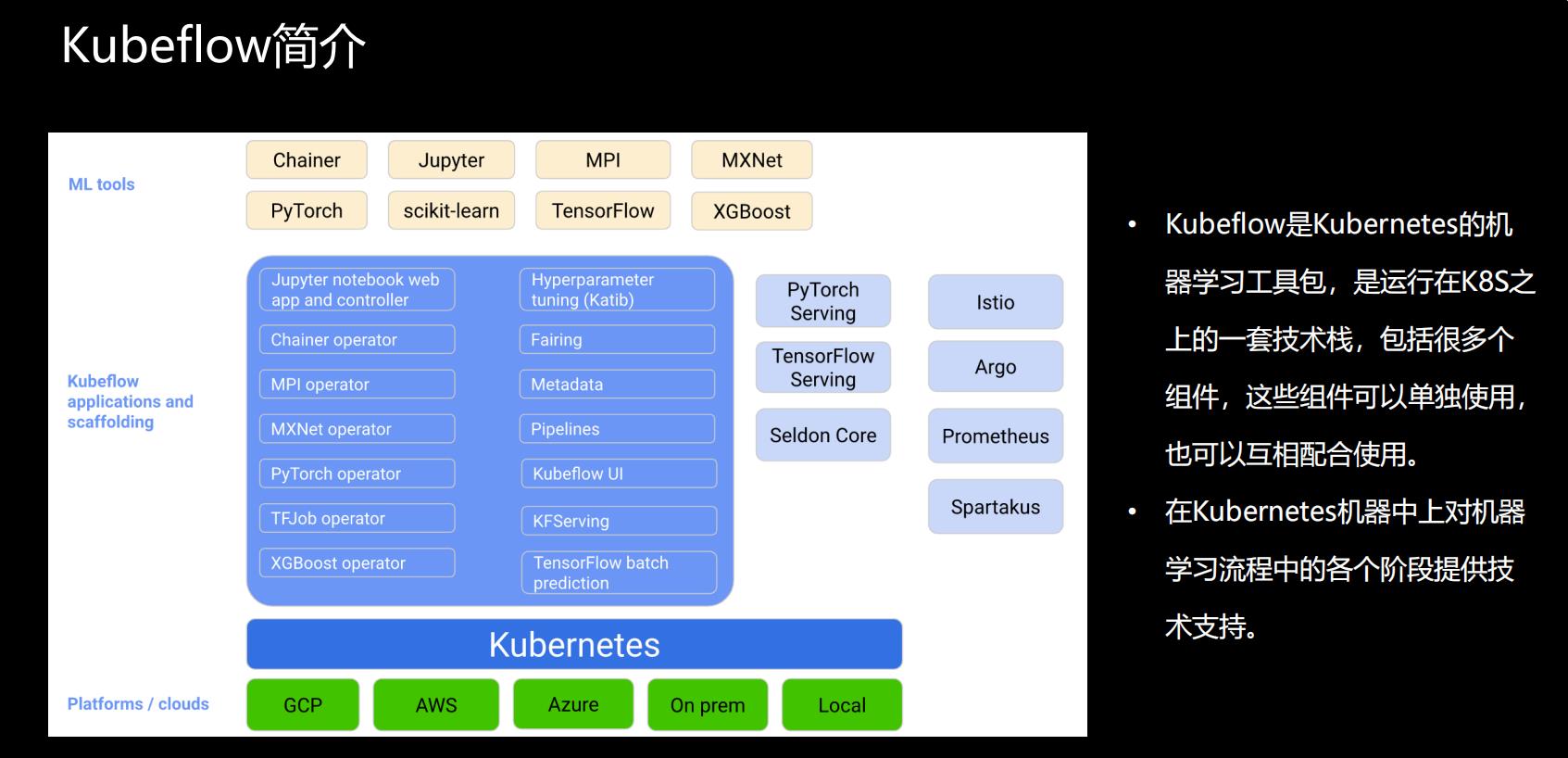
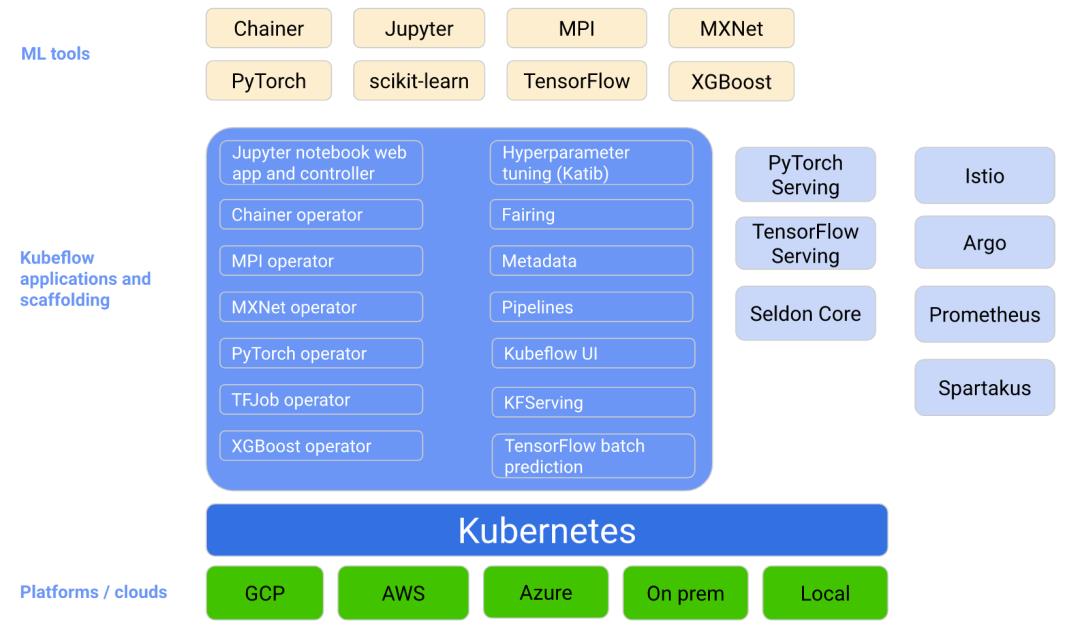
图片来自Kubeflow官网
上图内容分为3个部分:
机器学习框架
Chainer是一个专门为高校研究和开发深度学习算法而设立的一个的开源框架,基于python语言开发的,也是一个独立的深度学习框架;
Jupyter是基于网页用于交互计算的程序,可被应用于全过程的计算,包括开发、文档编写、运行代码以及展示结果,简单来说Jupyter是以网页形式打开,可以直接在网页中编写和运行你的代码,运行结果可直接在网页中看到,也可以直接在Jupyter中编写应用程序的文档;
MPI是并行计算的框架,也是应用于机器学习的;亚马逊MXNet支持C++、Python、R语言、GO语言等等,一般来说学习难度比较高;
PyTorch是从Torch来的,Torch是Facebook人工智能研究所所使用的一个框架,非常适用于卷积神经网络,灵活度比较高,因为是命令式的,所以也支持动态图的模型,后来facebook在Torch的基础上针对python语言又发布了一个新的机器学习的工具包PyTorch,我认为它是一个python版的Torch,它应该是在Torch的基础上增加了许多特性;
scikit-learn是一个开源的python机器学习库,提供了大量用于数据挖掘和分析的工具,还包括一些数据梳理、交叉验证、算法、可视化算法等一系列的接口;
TensorFlow是Google的一个机器学习框架;
XGBoost也是一个开源的机器学习项目,它比较高效的实现了梯度提升决策树算法,同时还对算法进行了改进,包括算法实现上的一些改进
Kubeflow提供的组件
涵盖了机器学习流程中的各个部分,比如图中的kubeflow UI是TensorFlow的一个看板界面,大家可以在上面实时监控kubeflow的各种组件,以及提交的类似作业;
Metadata用于跟踪收集训练过程中的各种数据,提交的一些作业和模型等等,能帮助我们进行模型改进;
Jupyter notebook是一个交互式的ID的电脑环境,能比较方便的展示一些运行结果;
此外,这块还包括一大类的组件operator,主要是用来支持各种各样机器学习框架,它的组织形式都是以operator的形式进行的,目的是为了针对不同的机器学习框架,提供分布式训练和资源调度的能力,这里我们可以看到它有Chainer operator、MPI operator、MXNet operator、PyTorch operator、TFJob operator、XGBoost operator,基本上对应与我们主流的机器学习框架都有一个operator,这个Operator主要包括两部分,定义了一个K8s的CRD,比如用户想提交某种类型的机器学习的作业,它可以创建一个对应的CRD,后续的工作都是由operator来完成的,当然运行的镜像文件是由用户自己来提供的;
Hyperparameter tuning一个超参服务器,是基于operator实现的超参搜索和简单的模型结构搜索的一个系统,支持并行搜索和分布式训练等等,超参优化在实际工作中还未被大规模的应用,它目前还不能做到完全的自动化,所以在这个组件还需要进一步进行性能加强。
Pipelines是机器学习的一个工作流组件,可以定义比较复杂的机器学习流,是基于Argo实现的,实现了面向机器学习场景的流水线项目,比如提供了机器学习的流程创建、调度编排、管理等等,还提供了UI界面,可以让大家在上面看到自己工作流的流程;
此外还包括Serving的一些服务,主要是方便用户将训练好的模型部署到我们的K8s的环境里。
由于目前机器学习算法的框架比较多,且目前在真实的工业生产环境中,一直缺少一种能够真正统一部署的框架和解决方案,所以Kubeflow仅仅也是把我们常见的机器学习框架和模型集成起来,并没有提供统一的Serving服务;
Fairing组件能够帮助用户将写好的机器学习代码打包成镜像。
K8s集群 :如上图所示
机器学习工作的流程
当用户开发和部署一个机器学习系统时,一般来讲主要有几个阶段,这里列举了两个阶段:实验阶段和生产阶段,整个的过程其实是一个迭代的过程,并不是说只运行一次就结束了,在每个阶段执行过程中需要对流程中各个阶段的输出进行评估,通过评估后对整个流程进行一个改进,下图为按照顺序列举的工作流的各个阶段:
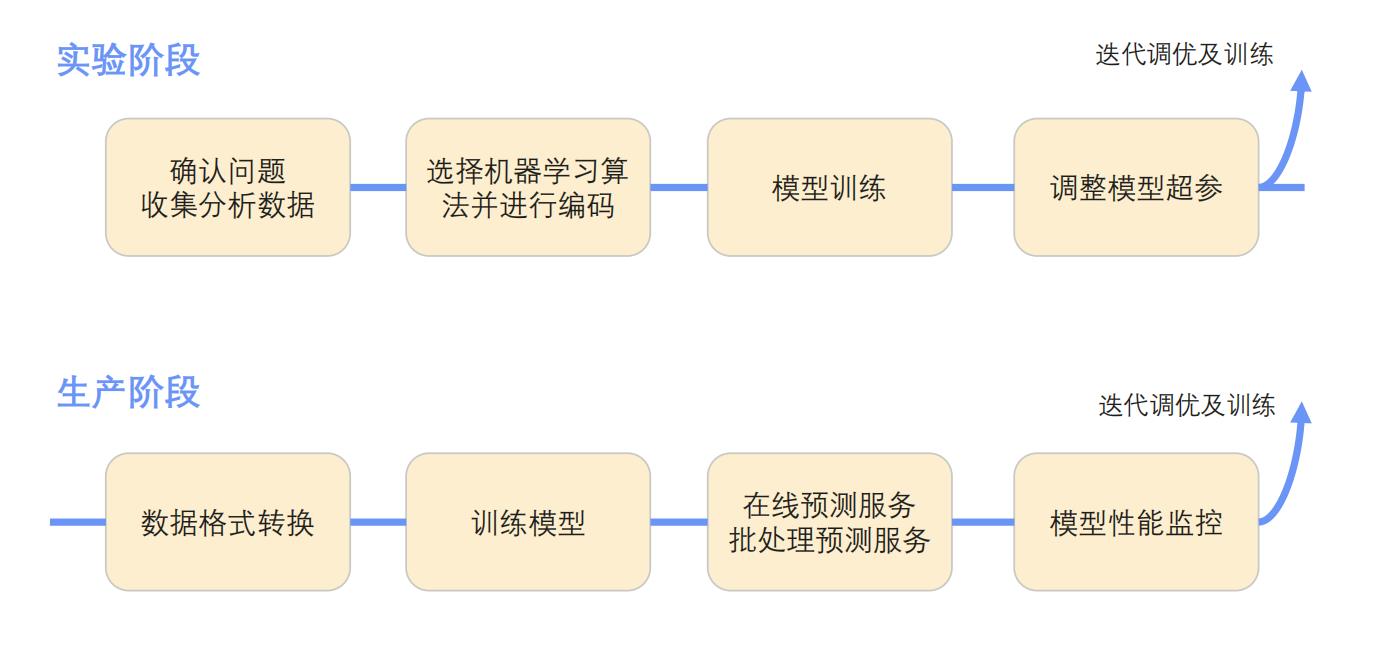
Kubeflow提供的组件与学习框架对应情况
实验阶段
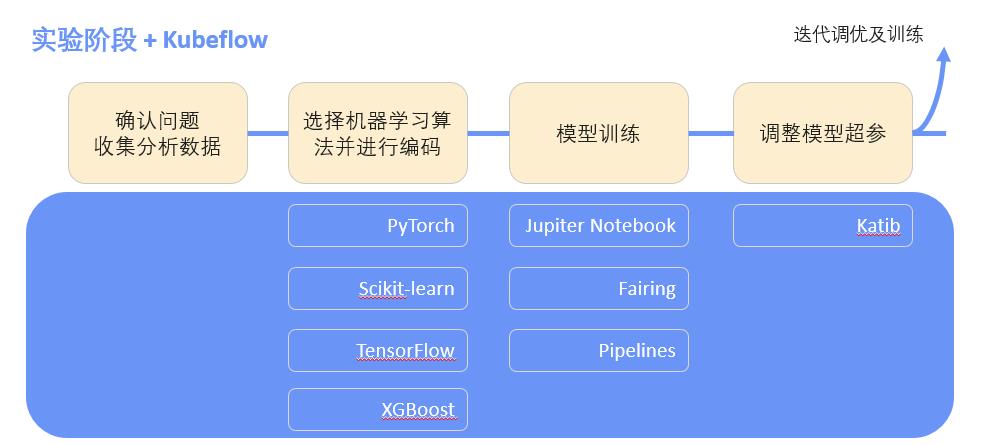
确认问题与收集分析阶段是由用户来完成的,选择机器学习算法并进行编码在选择机器学习框架时是独立的部分,kubeflow在这个部分没有提供任何功能;
但在模型训练过程中,提供了Jupiter Notebook支持,通过Fairing帮助用户把编译好 的代码打包成镜像,方便其运行,还有就是这种Pipelines工作流模式,整个过程类似于一个工作流的方式,它是分很多步骤的。
在这个模型训练中可以根据Pipelines定义在实验阶段工作流需要执行哪些步骤;调整模型参数阶段用到了Katib这个功能组件。
生产阶段
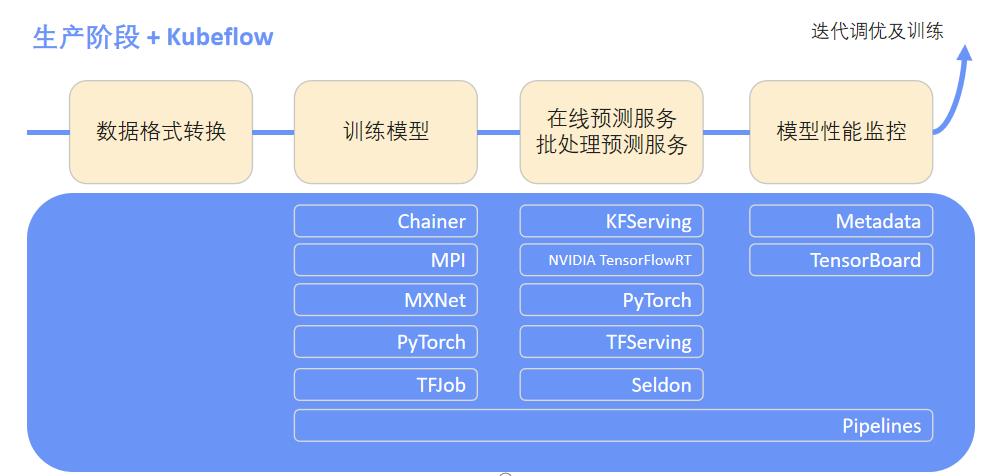
数据格式转换需要用户自己来处理,生产阶段的模型训练是和我们之前提到的operator关联起来的,用户在这个阶段可以根据自己选择的机器学习框架在kubeflow提交学习作业,kubeflow可以帮助他们把作业管理起来。
Kubeflow如何与Volcano集成在一起?
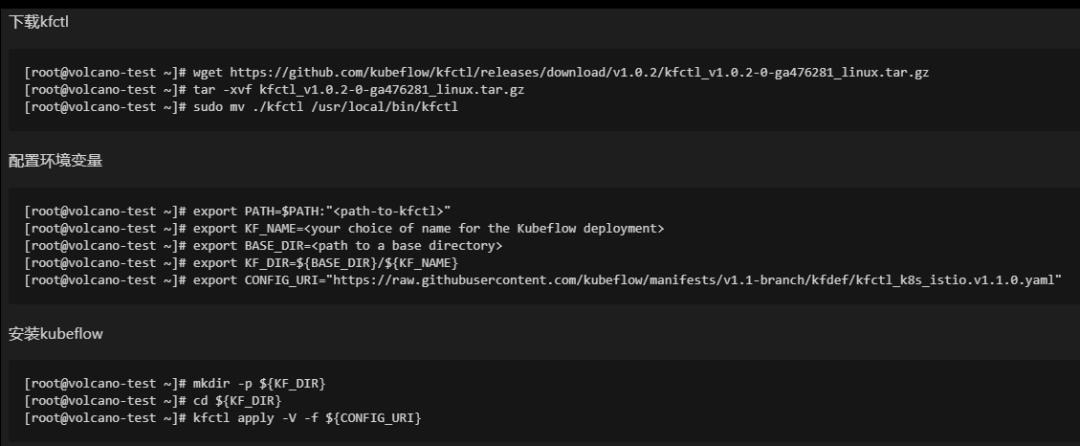
Kubeflow的安装过程
下载kfctl: kfctl是一个安装工具,为二进制的文件,直接在网上下载即可
**配置环境变量:**这个过程中有两个比较重要的部分,一个是KF-NAME ,为我们此次安装所定义的名称;另一个是CONFIG-URI,为kubeflow要安装的具体信息,包括了版本、包含了哪些组件、组件的安装策略等
**安装:**按照下图步骤即可
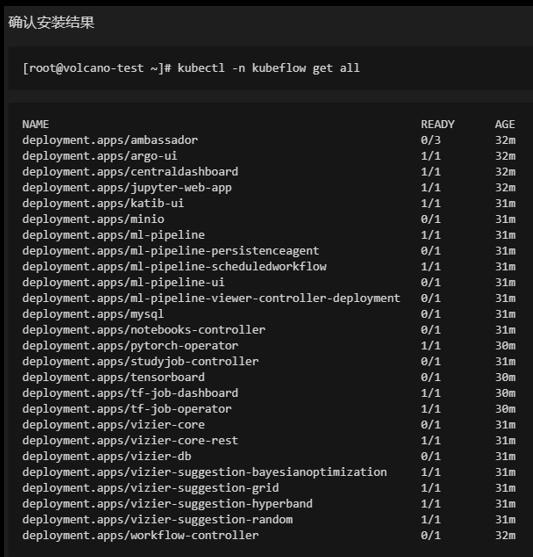
安装结果
安装问题及建议
• 镜像无法下载
• 系统资源不足
• 先构建,再安装
02 Kubeflow with Volcano:TFJob集成
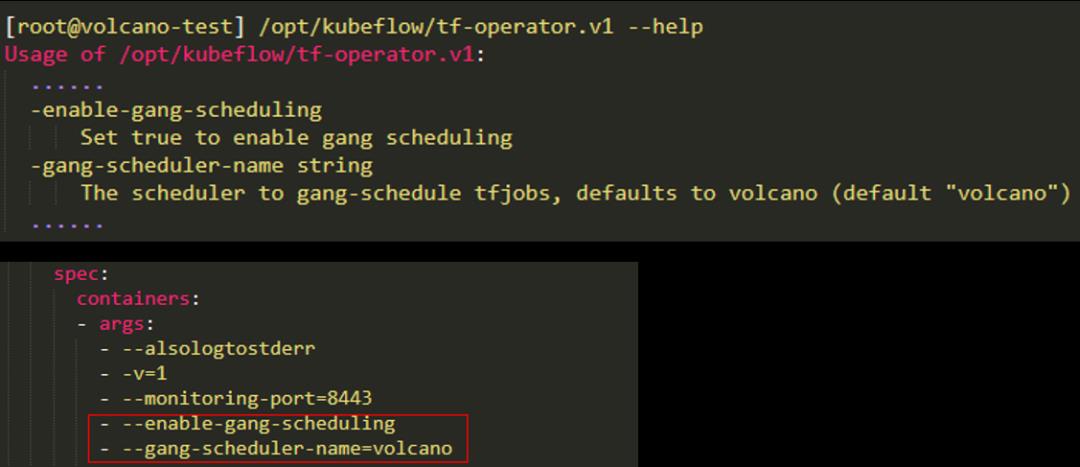
当用户想要运行TensorFlow作业时,其实可以创建一个TFJob CRD,创建完成后,TF Operator会去监控TFJob 这个CRD,能够获取到用户提交的作业信息,获取到之后会将TFJob 这个CRD转换成 PodGroup这个CRD,会添加一些调度信息,然后TF Operator这个任务就完成了。
后面是由Volcano来处理,Volcano会去监控PodGroup的信息,把它的信息拉到自己的组件里,根据策略对PodGroup里的Pod统一进行调度,调度好之后再将调度结果写回到这个ApiServer,写回之后Kubelet监控到Pod被调度出去了,会拿到对应本机的Pod,并将其启动起来。
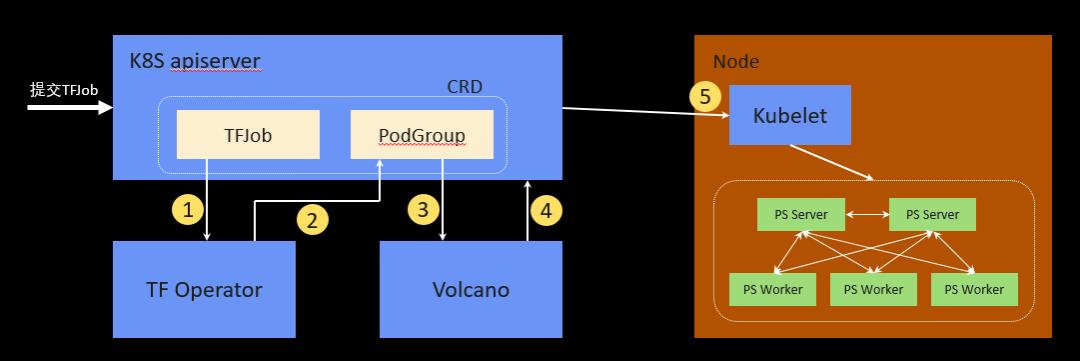
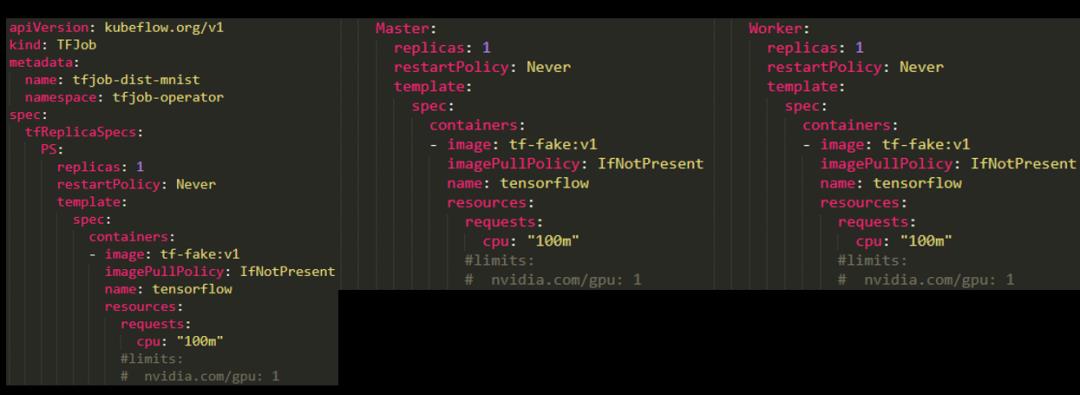
如何定义一个TFJob ?
如下图所示:
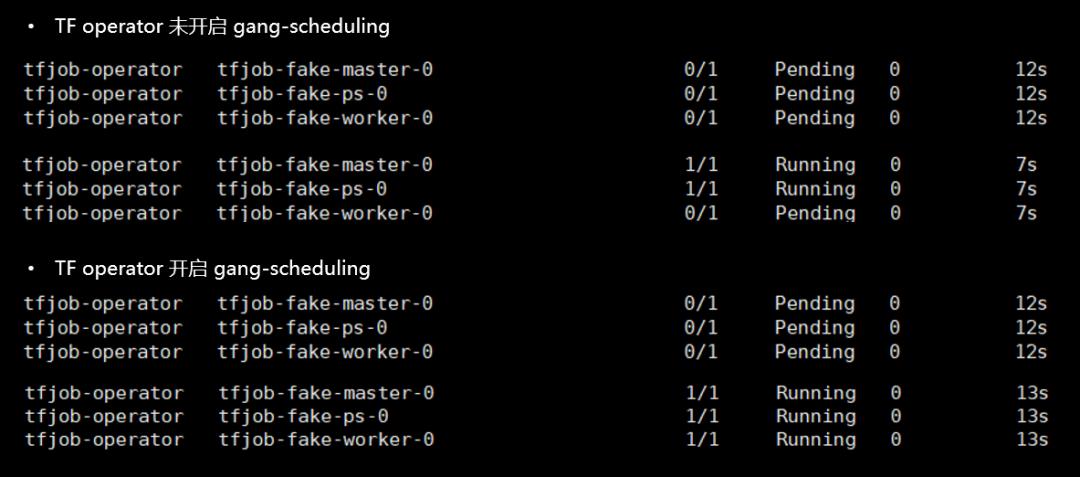
TF operator未开启与开启gang-scheduing对比
03 在K8s环境和在Volcano上运行一个简单TFJob
• 在集群中部署Volcano
• 在集群中部署Kubeflow TF Operator
• 运行一个Kubeflow TensorFlow作业
tor未开启与开启gang-scheduing对比
[外链图片转存中…(img-oWw0VRvK-1649325131452)]
03 在K8s环境和在Volcano上运行一个简单TFJob
• 在集群中部署Volcano
• 在集群中部署Kubeflow TF Operator
• 运行一个Kubeflow TensorFlow作业
以上是关于6-机器学习场景下Volcano集成调度能力实践的主要内容,如果未能解决你的问题,请参考以下文章