[机器学习与scikit-learn-46]:特征工程-特征选择(降维)-3-初级过滤:方差过滤法
Posted 文火冰糖的硅基工坊
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了[机器学习与scikit-learn-46]:特征工程-特征选择(降维)-3-初级过滤:方差过滤法相关的知识,希望对你有一定的参考价值。
作者主页(文火冰糖的硅基工坊):文火冰糖(王文兵)的博客_文火冰糖的硅基工坊_CSDN博客
本文网址:https://blog.csdn.net/HiWangWenBing/article/details/123970142
目录
2.2 scikit-learn的方差过滤:feature_selection.VarianceThreshold
前言:
当样本的特征的数量太多(比如成百上千,或上千上万)时,就需要一种方法,过滤掉对结果影响小的特征,来降低特征的维度。
哪些特征可以优先过滤掉呢?
第1章 特性选择常见方法
1.1 scikit-learn中特征工程

(1)特征提取(特征编码)
把非数值数据转换成适合模型训练的数值数据。
(2)特征创作(特征升维)
对现有的少量特征进行组合,得到新的特征。
(3)特征选择(特征降维)
在众多的特征中,选择部分特征,用来表征特定业务应用的样本。
- 人工过滤:通过人工分析的方法过滤的明显无关的特征。
- 方差过滤:根据特征值的波动范围的大小过滤,过滤到不同样本中,特征值相差不大的特征。
- 相关性过滤:合并相关性一致的特征。
- 嵌入法
- 包装法
- 降维算法
备注:本文重点探讨方差过滤。
1.2 人工过滤
算法工程师与业务工程师一起探讨特征对应的业务含义,过滤掉明显与业务不相关的特征。
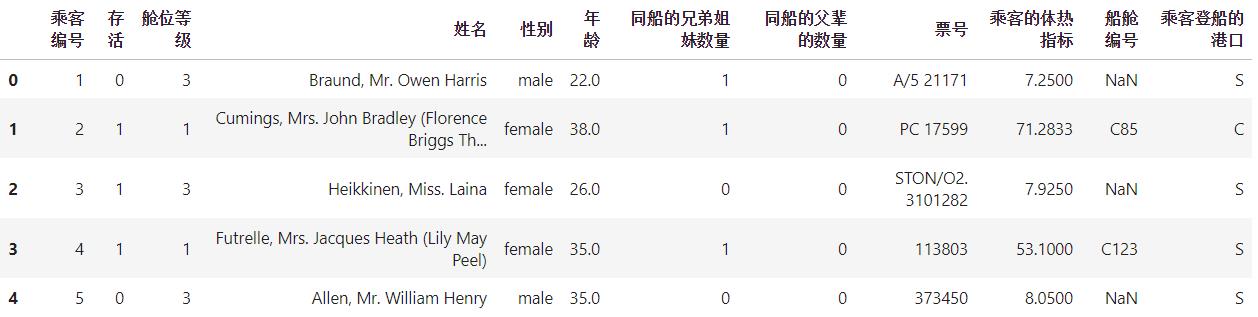
上述泰坦尼克号存活的特征信息。很显然,票号、乘客的登录框与是否能够存活下来的关系不大。可以直接进过滤掉。
比如考试成绩的高低,与学号无关也可以过滤掉。
人工过滤,必须要理解每个特征的业务含义!!!!
第2章 方差过滤
2.1 什么是方差

方差是在概率论和统计方差衡量随机变量或一组数据时离散程度的度量。
概率论中方差用来度量随机变量和其数学期望(即平均值)之间的偏离程度。
统计中的方差(样本方差)是每个样本值与全体样本值的平均数之差的平方值的平均数。
在许多实际问题中,研究方差即偏离程度有着重要意义。
方差越小,反应的是不同样本之间该特征值的差别越小,越说明该特征值用于区分不同样本的能力越小。这样的特征数据,对于模型区分不同目标的用处就越小。
一个特征本身的方差很小,就表示样本在这个特征上基本没有差异,可能特征中的大多数值都一样,甚至整个特征的取值都相同,那这个特征对于样本区分没有什么作用。所以无论接下来的特征工程要做什么,都要优先消除方差为0的特征, 然后优先过滤掉方差小的某个门限的特征。
2.2 scikit-learn的方差过滤:feature_selection.VarianceThreshold
(1)VarianceThreshold类概述
VarianceThreshold是通过特征本身的方差来筛选特征的类。
VarianceThreshold有重要参数threshold,表示方差的阈值,表示舍弃所有方差小于threshold的特征,不填默认为0,即删除所有的记录都相同的特征。
(2)代码展示
from sklearn.feature_selection import VarianceThreshold
import numpy as np
variance = X.var().values
threshold_min = np.min(variance)
threshold_mid = np.median(variance)
threshold_max = np.max(variance)
print("variance.shape", variance.shape)
print("threshold_min", threshold_min)
print("threshold_mid", threshold_mid)
selector_zero = VarianceThreshold() #=》默认过滤掉方差位0的特征
selector_min = VarianceThreshold(threshold_min)#=》默认过滤掉方差小于最小值的特征
selector_mid = VarianceThreshold(threshold_mid)#=》默认过滤掉方差小于中值的特征
X_fsvar_zero = selector_zero.fit_transform(X)
X_fsvar_min = selector_min.fit_transform(X)
X_fsvar_mid = selector_mid.fit_transform(X)
print("\\n过滤前的特征维度:", X.shape) # 874 =>
print("X_fsvar_zero.shape", X_fsvar_zero.shape) # 708 =>
print("X_fsvar_min.shape", X_fsvar_min.shape) # 708 =>
print("X_fsvar_mid.shape", X_fsvar_mid.shape) # 392第3章 方差过滤对算法的影响
3.1 方差过滤对KNN的影响
(1)对算法时间复杂度的影响:非常大
KNN算法是通过求样本点的距离来进行分类的,而样本向量的距离与样本的维度密切相关。
KNK算法,维度越高,求解样本距离的复杂度越高,
因此,降维对KNN算法的计算时间影响非常大!!!
(2)对算法空间复杂度的影响:非常大
由于每个特征都会占用内存变量,因此对空间复杂度影响较大。
(3)对算法准确率的影响:较小
由于方差过滤是过滤掉那些对区分结果影响不大的样本,
因此,降维对KNN算法的准确率的影响不大!!!
3.2 方差过滤随机深林的影响
(1)对算法时间复杂度的影响:较小
随机深林的每次决策,都是随机的选择特征进行决策分类,每次决策无需计算所有的特征。
因此,降维对随机深林的时间复杂度影响较小。
(2)对算法空间复杂度的影响:非常大
由于每个特征都会占用内存变量,因此对空间复杂度影响较大。
(3)对算法准确率的影响:较小
由于方差过滤是过滤掉那些对区分结果影响不大的样本,
因此,降维对随机算法的准确率的影响不大!!!
作者主页(文火冰糖的硅基工坊):文火冰糖(王文兵)的博客_文火冰糖的硅基工坊_CSDN博客
本文网址:https://blog.csdn.net/HiWangWenBing/article/details/123970142
以上是关于[机器学习与scikit-learn-46]:特征工程-特征选择(降维)-3-初级过滤:方差过滤法的主要内容,如果未能解决你的问题,请参考以下文章