[深度学习][原创]使用labelImg+yolov5完成所有slowfast时空动作检测项目-开山篇
Posted FL1623863129
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了[深度学习][原创]使用labelImg+yolov5完成所有slowfast时空动作检测项目-开山篇相关的知识,希望对你有一定的参考价值。
网上其实就只有一个仁兄(计算机视觉-杨帆)搞slowfast自定义数据集训练的,出了很多教程,专门照顾小白学者和学生,但是里面有很多细节没有说清楚,不过像我这样子老司机看过之后直呼简单。虽然说起来容易但是做起来却是很难。其实如果你想自定义ava action数据集训练,你必须要搞清楚ava数据集每个文件具体含义才行。在计算机视觉-杨帆这个博主的csdn中,写的其实还算详细,其中有2个地方不得不提:
(1)ava2.1和ava2.2中所有基本csv文件是差不多的,只不过ava_train_2.2.csv中多了一个追踪ID,这个追踪ID其实要在自定义数据集中去标注难度就很大了。既然我们做时空动作检测,其实没必要标注这个追踪ID,即使有必要也是很简单的,只要在labelImg中加上ID就可以了。我训练自己的数据集其实没有用追踪ID。
(2)在person_box_67091280_iou90/ava_detection_train_boxes_and_labels_include_negative_v2.2.csv这个文件中,仔细看下图
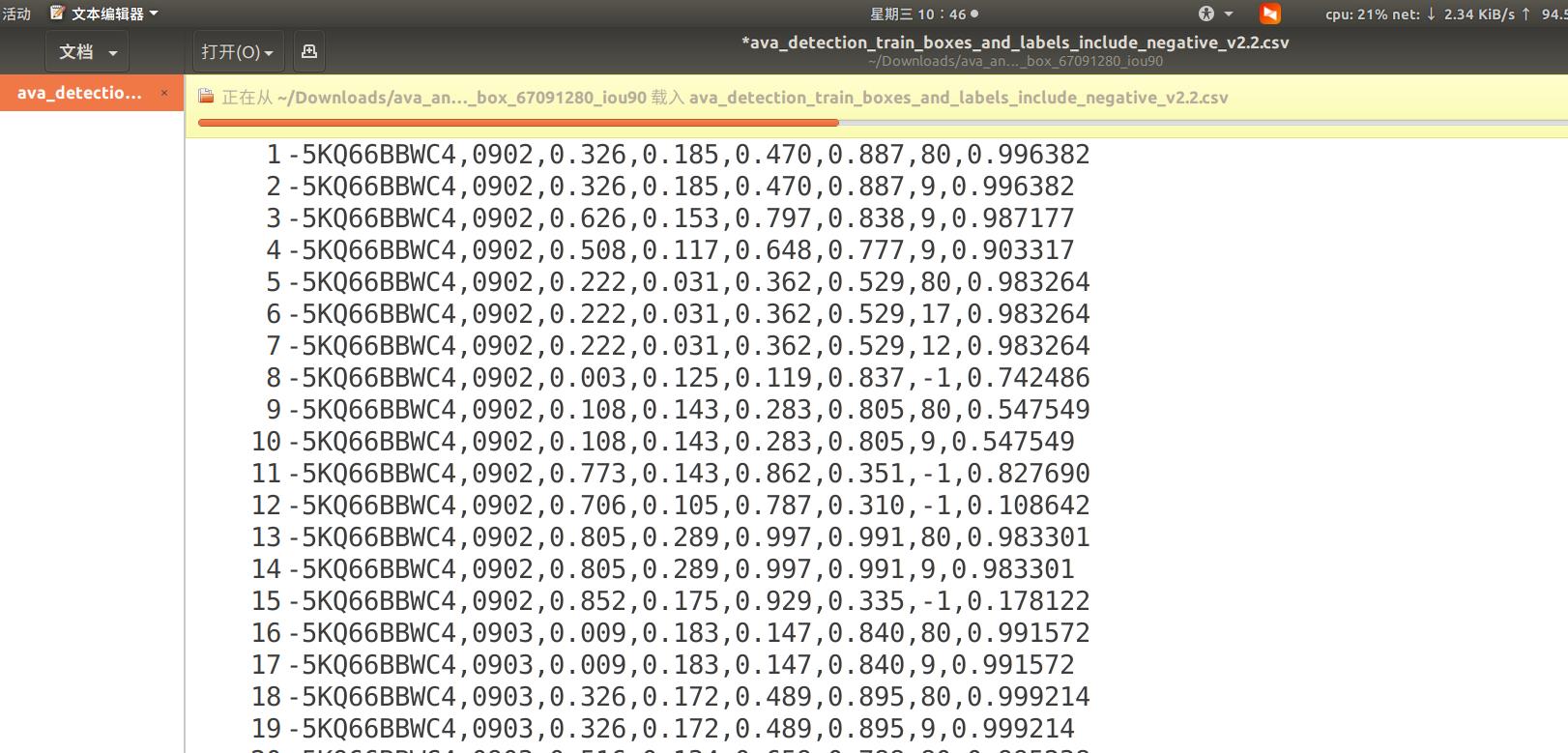
最后一列有个概率值,我看很多同学不清楚怎么来的这些值,这些值其他博客都没有怎么解释,其实这就是bbox概率值,如果你用目标检测会有一个置信度值你完全可以写在这列,但是如果标注有错误,比如删除错误框,这些值可能就对不上你那个框了,因此完全可以设置一个固定值。我设定0.99是没问题的。
网上统一的自定义ava数据集训练自己的模型步骤如下:
(1)采集自己的视频文件
(2)对视频文件进行抽帧,按30fps抽取
(3)将抽取的图片采用mmdetection中的模型或者faster-rcnn模型进行预标注,并转化为via或者via3(一个网页版本的标注工具)
(4)手工矫正标注的框,个人感觉via3虽然好用,但是感觉比较复杂,至少比labelImg复杂一点,而且保存的标注一大坨。只有通过json.load才能看的清楚
(5)对标注进行代码分析转化为需要ava格式的文件
(6)送入slowfast训练,然后测试结果
这回我的自定义训练数据集ava的流程为
(1)采集自己的视频文件
(2)对视频文件进行抽帧,按30fps抽取
(3)将抽取的图片采用yolov5模型进行预标注,并转化pascal VOC格式数据集
(4)手工矫正标注的框,使用labelImg矫正
(5)对标注进行代码分析转化为需要ava格式的文件
(6)送入slowfast训练,然后测试结果
其中labelImg需要解决的关键技术有:
1、同一个人多种行为怎么标注,采用逗号分隔,比如一个人有talk还有stand则可以标注为talk,stand,如果需要追踪,则可以每个标注后面加个追踪ID号
2、负样本怎么标注,采用逗号分隔,标注动作名称只要不在自己动作名称就可以,比如talk,stand,neg这样转化解析时候将neg设置-1这样就解决了负样本标注问题
3、转化ava_predicted_box.csv数据集时候,最后一列的score可以设置为统一值
4、ava默认是从902帧开始,我们可以从第1帧开始,不过需要修改代码,位置在slowfast/slowfast/datasets/ava_helper.py,这里我门要求视频1-40秒,即视频文件时长需要>40s
#!/usr/bin/env python3
# Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved.
import logging
import os
from collections import defaultdict
from slowfast.utils.env import pathmgr
logger = logging.getLogger(__name__)
FPS = 30
SECONDS=40
AVA_VALID_FRAMES = range(1, FPS*SECONDS)
def load_image_lists(cfg, is_train):
"""
Loading image paths from corresponding files.
Args:
cfg (CfgNode): config.
is_train (bool): if it is training dataset or not.
Returns:
image_paths (list[list]): a list of items. Each item (also a list)
corresponds to one video and contains the paths of images for
this video.
video_idx_to_name (list): a list which stores video names.
"""
list_filenames = [
os.path.join(cfg.AVA.FRAME_LIST_DIR, filename)
for filename in (
cfg.AVA.TRAIN_LISTS if is_train else cfg.AVA.TEST_LISTS
)
]
image_paths = defaultdict(list)
video_name_to_idx =
video_idx_to_name = []
for list_filename in list_filenames:
with pathmgr.open(list_filename, "r") as f:
f.readline()
for line in f:
row = line.split()
# The format of each row should follow:
# original_vido_id video_id frame_id path labels.
assert len(row) == 5
video_name = row[0]
if video_name not in video_name_to_idx:
idx = len(video_name_to_idx)
video_name_to_idx[video_name] = idx
video_idx_to_name.append(video_name)
data_key = video_name_to_idx[video_name]
image_paths[data_key].append(
os.path.join(cfg.AVA.FRAME_DIR, row[3])
)
image_paths = [image_paths[i] for i in range(len(image_paths))]
logger.info(
"Finished loading image paths from: %s" % ", ".join(list_filenames)
)
return image_paths, video_idx_to_name
def load_boxes_and_labels(cfg, mode):
"""
Loading boxes and labels from csv files.
Args:
cfg (CfgNode): config.
mode (str): 'train', 'val', or 'test' mode.
Returns:
all_boxes (dict): a dict which maps from `video_name` and
`frame_sec` to a list of `box`. Each `box` is a
[`box_coord`, `box_labels`] where `box_coord` is the
coordinates of box and 'box_labels` are the corresponding
labels for the box.
"""
gt_lists = cfg.AVA.TRAIN_GT_BOX_LISTS if mode == "train" else []
pred_lists = (
cfg.AVA.TRAIN_PREDICT_BOX_LISTS
if mode == "train"
else cfg.AVA.TEST_PREDICT_BOX_LISTS
)
ann_filenames = [
os.path.join(cfg.AVA.ANNOTATION_DIR, filename)
for filename in gt_lists + pred_lists
]
ann_is_gt_box = [True] * len(gt_lists) + [False] * len(pred_lists)
detect_thresh = cfg.AVA.DETECTION_SCORE_THRESH
# Only select frame_sec % 4 = 0 samples for validation if not
# set FULL_TEST_ON_VAL.
boxes_sample_rate = (
4 if mode == "val" and not cfg.AVA.FULL_TEST_ON_VAL else 1
)
all_boxes, count, unique_box_count = parse_bboxes_file(
ann_filenames=ann_filenames,
ann_is_gt_box=ann_is_gt_box,
detect_thresh=detect_thresh,
boxes_sample_rate=boxes_sample_rate,
)
logger.info(
"Finished loading annotations from: %s" % ", ".join(ann_filenames)
)
logger.info("Detection threshold: ".format(detect_thresh))
logger.info("Number of unique boxes: %d" % unique_box_count)
logger.info("Number of annotations: %d" % count)
return all_boxes
def get_keyframe_data(boxes_and_labels):
"""
Getting keyframe indices, boxes and labels in the dataset.
Args:
boxes_and_labels (list[dict]): a list which maps from video_idx to a dict.
Each dict `frame_sec` to a list of boxes and corresponding labels.
Returns:
keyframe_indices (list): a list of indices of the keyframes.
keyframe_boxes_and_labels (list[list[list]]): a list of list which maps from
video_idx and sec_idx to a list of boxes and corresponding labels.
"""
def sec_to_frame(sec):
"""
Convert time index (in second) to frame index.
0: 900
30: 901
"""
return (sec - 900) * FPS
keyframe_indices = []
keyframe_boxes_and_labels = []
count = 0
for video_idx in range(len(boxes_and_labels)):
sec_idx = 0
keyframe_boxes_and_labels.append([])
for sec in boxes_and_labels[video_idx].keys():
if sec not in AVA_VALID_FRAMES:
continue
if len(boxes_and_labels[video_idx][sec]) > 0:
keyframe_indices.append(
(video_idx, sec_idx, sec, sec_to_frame(sec))
)
keyframe_boxes_and_labels[video_idx].append(
boxes_and_labels[video_idx][sec]
)
sec_idx += 1
count += 1
logger.info("%d keyframes used." % count)
return keyframe_indices, keyframe_boxes_and_labels
def get_num_boxes_used(keyframe_indices, keyframe_boxes_and_labels):
"""
Get total number of used boxes.
Args:
keyframe_indices (list): a list of indices of the keyframes.
keyframe_boxes_and_labels (list[list[list]]): a list of list which maps from
video_idx and sec_idx to a list of boxes and corresponding labels.
Returns:
count (int): total number of used boxes.
"""
count = 0
for video_idx, sec_idx, _, _ in keyframe_indices:
count += len(keyframe_boxes_and_labels[video_idx][sec_idx])
return count
def parse_bboxes_file(
ann_filenames, ann_is_gt_box, detect_thresh, boxes_sample_rate=1
):
"""
Parse AVA bounding boxes files.
Args:
ann_filenames (list of str(s)): a list of AVA bounding boxes annotation files.
ann_is_gt_box (list of bools): a list of boolean to indicate whether the corresponding
ann_file is ground-truth. `ann_is_gt_box[i]` correspond to `ann_filenames[i]`.
detect_thresh (float): threshold for accepting predicted boxes, range [0, 1].
boxes_sample_rate (int): sample rate for test bounding boxes. Get 1 every `boxes_sample_rate`.
"""
all_boxes =
count = 0
unique_box_count = 0
for filename, is_gt_box in zip(ann_filenames, ann_is_gt_box):
with pathmgr.open(filename, "r") as f:
for line in f:
row = line.strip().split(",")
# When we use predicted boxes to train/eval, we need to
# ignore the boxes whose scores are below the threshold.
#if not is_gt_box:
# score = float(row[7])
# if score < detect_thresh:
# continue
video_name, frame_sec = row[0], int(row[1])
if frame_sec>=FPS*SECONDS:
continue
if frame_sec % boxes_sample_rate != 0:
continue
# Box with format [x1, y1, x2, y2] with a range of [0, 1] as float.
box_key = ",".join(row[2:6])
box = list(map(float, row[2:6]))
label = -1 if row[6] == "" else int(row[6])
if video_name not in all_boxes:
all_boxes[video_name] =
for sec in AVA_VALID_FRAMES:
all_boxes[video_name][sec] =
if box_key not in all_boxes[video_name][frame_sec]:
all_boxes[video_name][frame_sec][box_key] = [box, []]
unique_box_count += 1
all_boxes[video_name][frame_sec][box_key][1].append(label)
if label != -1:
count += 1
for video_name in all_boxes.keys():
for frame_sec in all_boxes[video_name].keys():
# Save in format of a list of [box_i, box_i_labels].
all_boxes[video_name][frame_sec] = list(
all_boxes[video_name][frame_sec].values()
)
return all_boxes, count, unique_box_count下一篇将介绍如何训练自己数据集具体流程
参考文献:
1、https://blog.csdn.net/WhiffeYF/article/details/115581800
2、https://blog.csdn.net/qq_45672807/article/details/123294954
3、https://github.com/futureflsl/self-made_ava_dataset_tool
4、https://blog.csdn.net/Bluemoon17/article/details/123238573
以上是关于[深度学习][原创]使用labelImg+yolov5完成所有slowfast时空动作检测项目-开山篇的主要内容,如果未能解决你的问题,请参考以下文章