Java岗大厂面试百日冲刺Day42— 实战那些事儿3 (日积月累,每日三题)
Posted _陈哈哈
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Java岗大厂面试百日冲刺Day42— 实战那些事儿3 (日积月累,每日三题)相关的知识,希望对你有一定的参考价值。
大家好,我是陈哈哈,北漂五年。相信大家和我一样,
都有一个大厂梦,作为一名资深Java选手,深知面试重要性,接下来我准备用100天时间,基于Java岗面试中的高频面试题,以每日3题的形式,带你过一遍热门面试题及恰如其分的解答。
一路走来,随着问题加深,发现不会的也愈来愈多。但底气着实足了不少,相信不少朋友和我一样,日积月累才是最有效的学习方式!想起高三时一个同学的座右铭:只有沉下去,才能浮上来。共勉(juan)。

作者:云野.
车票
- 面试题1:如果用mybatis批量插入数据时需要返回主键,你是怎么做的?
- 面试题2:在微服务中你是如何实现不同服务间session 共享的?
- 面试题3:你了解分库分表么?分库分表一般出现在哪些场景下?
- 每日小结
本栏目Java开发岗高频面试题主要出自以下各技术栈:Java基础知识、集合容器、并发编程、JVM、Spring全家桶、MyBatis等ORMapping框架、mysql数据库、Redis缓存、RabbitMQ消息队列、Linux操作技巧等。
面试题1:如果用mybatis批量插入数据时需要返回主键,你是怎么做的?
需要在Mapper.xml的中标签中配置useGeneratedKeys和keyProperty两个属性,就可以在批量插入时返回主键。
比如有个表t_user,里面有 user_id,user_name,sex 这三个字段,其中user_id是自增主键。
下面是批量插入的Dao层接口:
List<String> insertUsers(@Param("list") List<UserInfo> users);
xml形式:
<insert id="insertUsers" useGeneratedKeys="true" keyProperty="user_id" resultType="String">
insert into t_user (user_name,sex)
values
<foreach collection="list" item="c" separator=",">
(#c.user_name,#c.sex)
</foreach>
</insert>
注解形式:
@Insert("<script>insert into t_user (user_name,sex) values " +
"<foreach collection='list' item='c' separator=','>(#c.user_name,#c.sex)</foreach></script>")
@Options(useGeneratedKeys = true, keyProperty = "user_id", resultType="String")
List<String> insertUsers(@Param("list") List<UserInfo> users);
注意:
@Param里和foreach的collection里都需要写成list, 其实是源码中写死了key为list,否则批量插入后会报错说找不到"user_id"字段,而无法返回主键。
这种方式的前提是该表主键有序自增,它的原理其实就是拿到当前表中最大ID,然后结合影响行数来返回相应数据。但这就需要固定的insert场景,如果是insert ignore这种可能和实际影响行数不同的情况,就会出现不准确的情况。

课间休息,来秀一下来自咱们群里同学搬砖工地附近的夜市。
作者:山一程雪一更
面试题2:在微服务中你是如何实现不同服务间session 共享的?
在微服务中,一个完整的项目被拆分成多个不相同的独立的服务,各个服务独立部署在不同的服务器上,各自的 session 被从物理空间上隔离开了,但是经常,我们需要在不同微服务之间共享 session。
常见的方案就是 Spring Session + Redis 来实现 session 共享。将所有微服务的 session 统一保存在 Redis 上,当各个微服务对 session 有相关的读写操作时,都去操作 Redis 上的 session 。这样就实现了session 共享,Spring Session 基于 Spring 中的代理过滤器实现,使得 session 的同步操作对开发人员而言是透明的,非常简便。
同时,Spring Session已经集成了redis,可以很方便的将session存到redis中从而实现单点登陆/登出的效果,但是从微服务的角度来说,为了降低系统间的耦合度,一般会单独建一个Redis服务来搞session共享。
1、pom 文件中引入以下包
<!--spring boot 与redis应用基本环境配置 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
<!--spring session 与redis应用基本环境配置 -->
<dependency>
<groupId>org.springframework.session</groupId>
<artifactId>spring-session-data-redis</artifactId>
</dependency>
2、application.properties配置好 redis
spring.redis.database = 0
spring.redis.host = 192.168.xx.xx
spring.redis.port = 6379
spring.redis.password = test
spring.redis.pool.max-active = 200
spring.redis.pool.max-wait = -1
spring.redis.pool.max-idle = 10
spring.redis.pool.min-idle = 0
spring.redis.pool.timeout = 1000
在需要共享 session 的服务的启动类上,加上注解即可
@EnableRedisHttpSession
@SpringBootApplication(exclude= DataSourceAutoConfiguration.class)
public class PhoneApplication
public static void main(String[] args)
SpringApplication.run(PhoneApplication.class, args);

来了,CSDN的中秋礼品已到位
作者:陈哈哈
面试题3:你了解分库分表么?分库分表一般出现在哪些场景下?
分库:由单个数据库实例拆分成多个数据库实例,将数据分布到多个数据库实例中。分表:由单张表拆分成多张表,将数据划分到多张表内。
随着业务数据量和网站QPS日益增高,对数据库压力也越来越大,单机版数据库很快会到达存储和并发瓶颈,就需要做数据库性能方面的优化,分库分表采取的是分而治之的策略,分库目的是减轻单台MySQL实例存储压力及可扩展性,而分表是解决单张表数据过大以后查询的瓶颈问题,坦白说,这些问题也是所有关系型数据库的“硬伤”。
常用策略包括:垂直分表、水平分表、垂直分库、水平分库。
一、朴实无华的 - 分表
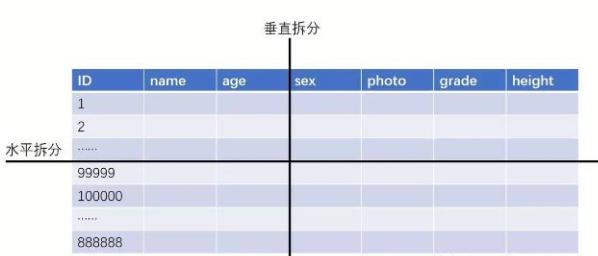
1、垂直分表
垂直分表,或者叫竖着切表,是不是感受到该策略是以字段为依据的!主要按照字段的活跃性、字段长度,将表中字段拆分到不同的表(主表和扩展表)中。
特点:
- 每个表的结构都不一样;
- 每个表的数据也不一样,
- 有一个关联字段,一般是主键或外键,用于关联
兄弟表数据; - 所有兄弟表的并集是该表的全量数据;
场景:
有几个字段属于热点字段,更新频率很高,要把这些字段单独切到一张表里,不然innodb行锁很恶心的,锁死你呀~~如用户表里的余额字段?不,我的余额就很稳定,一直是0。。有大字段,如text,存储压力很大,毕竟innodb数据和索引是同一个文件;同时,我又喜欢用SELECT *,你懂得,这磁盘IO消耗的,跟玩儿似的,谁都扛不住的。有明显的业务区分,或表结构设计时字段冗余;有些小伙伴看到第一点时,就发现陈哈哈是个菜鸡,用户表怎么会有余额字段?明显有问题啊!赶紧先到评论区喷陈哈哈一波~~然后笑嘻嘻的发现原来是个小尾巴,真不要脸是吧。。是的,因此不同业务我们要把具体字段拆开,这样才有利于业务后续扩展哦。
2、水平分表
水平分表,也叫“横着切”。。以行数据为依据进行切分,一般按照某列的自容进行切分。
如手机号表,我们可以通过前两位或前三位进行切分,如131、132、133 → phone_131、phone_132、phone_133,手机号有11位(100亿),量大是很正常的事儿,这年头谁家老头老太太每个手机呢是吧。这样切就把一张大表切成了好几十张小表,数据量不就下来了。有同学就问了那我怎么知道我这手机号查哪个表呢?一看你就没认真看前两行标红的点,为啥标红嘞?比如我查13100001111,那我截取前三位,动态拼接到查询的表名上,就行了。
特点:
- 每个表的结构都一样;
- 每个表的数据都不一样,没有交集;
- 所有表的并集是该表的全量数据;
场景:单表的数据量过大或增长速度很快,已经影响或即将会影响SQL查询效率,加重了CPU负担,提前到达瓶颈。记得水平分表越早越好,别问我为什么。。

二、花里胡哨的 - 分库
需要你注意的是,传统的分库和我们熟悉的集群、主从复制可不是一个事儿;多节点集群是将一个库复制成N个库,从而通过读写分离实现多个MySQL服务的负载均衡,实际是围绕一个库来搞的,这个库称为Master主库。而分库就不同了,分库是将这个主库一分为N,比如一分为二,然后针对这两个主库,再配置2N个从库节点。
3、垂直分库
纵向切库,太经典的切分方式,基于表进行切分,通常是把新的业务模块或集成公共模块拆分出去,比如我们最熟悉的单点登录、鉴权模块。熟悉的味道,记得有一次我把一些没用的表切到一个性能很好的服务器中,这服务器我专门用来学习,后来也不知被哪个狗腿子告密了~ 我**你个**,有种站出来,你个**东西😅😅。

特点:
- 每个库的表都不一样;
- 表不一样,数据就更不一样了~ 没有任何交集;
- 每个库相对独立,模块化
场景:可以抽象出单独的业务模块时,可以抽象出公共区时(如字典、公共时间、公共配置等),或者想有一台属于自己的服务器时?
4、水平分库
以行数据为依据,将一个库中的数据拆分到多个库中。大型分表体验一下?坦白说这种策略并不实用,因为会对后台开发很不友好,有很多坑,不建议采用,理解即可。
特点:
- 每个库的结构都一样;
- 每个库的数据都不一样,没有交集;
- 所有库的并集是全量数据;
场景:系统绝对并发量上来了,CPU内存压力大。分表难以根本上解决量的问题,并且还没有明显的业务归属来垂直分库,主库磁盘接近饱和。
其实,在实际工作中,我们在选择分库分表策略前,想到的应该是从缓存、读写分离、SQL优化等方面,因为这些能够更直接、代价更小的解决问题。要记住动表就是动根本,你永远不知道这张表后面会连带多少历史遗留问题,如果是个很大型的项目,遇到些问题你就跟经理提议要分库分表,小心被呼死~
每日小结
今天我们复习了面试中常问的三个实战问题,你做到心中有数了么?对了,如果你的朋友也在准备面试,请将这个系列扔给他,如果他认真对待,肯定会感谢你的!!好了,今天就到这里,学废了的同学,记得在评论区留言:打卡。,给同学们以激励。
以上是关于Java岗大厂面试百日冲刺Day42— 实战那些事儿3 (日积月累,每日三题)的主要内容,如果未能解决你的问题,请参考以下文章