计算机视觉算法——Transformer学习笔记
Posted Leo-Peng
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了计算机视觉算法——Transformer学习笔记相关的知识,希望对你有一定的参考价值。
算机视觉算法——Transformer学习笔记
计算机视觉算法——Transformer学习笔记
清明假期被封在家里,我就利用这三天时间学习了下著名的Transfomer,参考的主要是Blibli UP主霹雳吧啦Wz的视频教程,过程有不懂的我就自己查资料,补充了一些自己的理解观点,目前还没有机会对Transformer进行实践,只是进行了简单的理论学习,有问题欢迎读者指出交流。
参考内容:
11.1 Vision Transformer(vit)网络详解
Vision Transformer 超详细解读 (原理分析+代码解读) (一)
12.1 Swin-Transformer网络结构详解
1. Vision Transformer
Transformer来源于2017年的一篇论文《Attention Is All You Need》,Transformer的提出最开始是针对NLP领域的,在此之前,NLP领域里使用的主要是RNN、LSTM这样一些网络,这些网络都存在一些问题,一方面是记忆长度有限,另一方面是无法并行,而Transeformer理论上记忆长度是无限长的,并且可以做到并行化。
而Vision Transformer是2020年发表于CVPR的论文《An Image Worth 16x16 Words: Transformers for Image Recognition as Scale》提出的,论文性能对比如下:
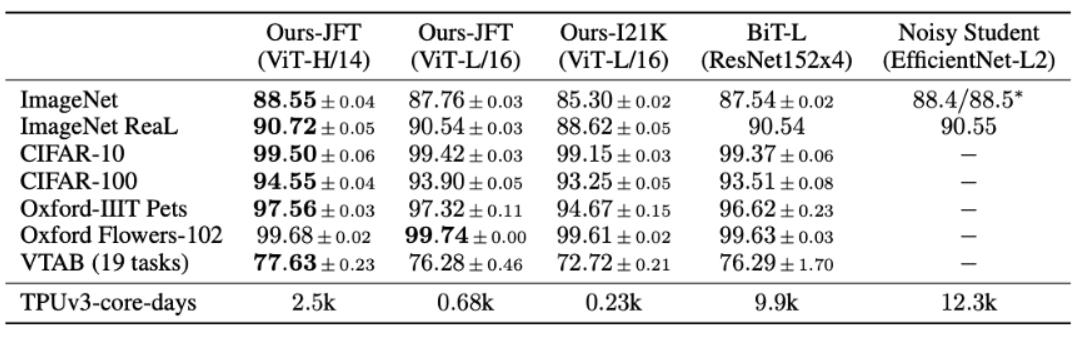
1.1 网络结构
Vision Transform的网络结构如下图所示:
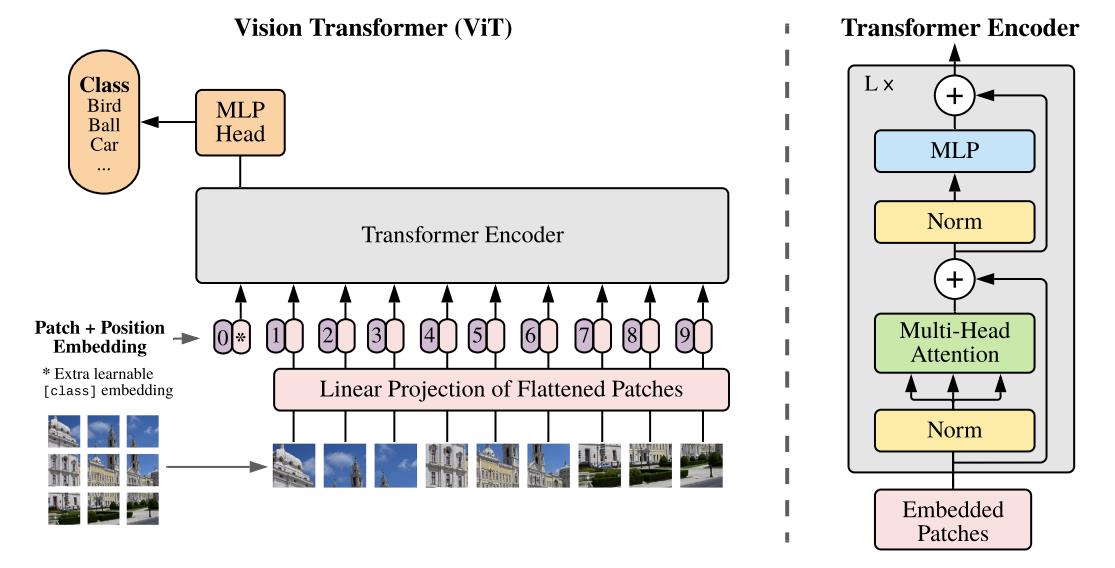
- 首先将输入图片切分成 16 × 16 × 3 16\\times16\\times3 16×16×3大小的Patch,然后将Patch经过Embedding层进行编码,进行编码后每一个Patch就得到一个长度为 768 × 1 768\\times1 768×1的向量,这个向量称为Token(可以理解为就是一路输入),在代码实现中中,是使用一个卷积核大小为 16 × 16 16\\times16 16×16,步距为 16 16 16的卷积核个数为 768 768 768卷积层实现的,对于一个 244 × 244 × 3 244\\times244\\times3 244×244×3的输入图像,通过卷积后就得到 14 × 14 × 768 14\\times14\\times768 14×14×768特征层,然后我们将特征层的 H H H和 W W W方向进行展平就获得一个 196 × 768 196\\times768 196×768的二维向量,也即 196 196 196个Token。
- 在以上基础上,再加上一个Class Token,因为以上 196 196 196个Token输入Transformer,必然会有 196 196 196个Token输出,我们选取哪一个作为最后的输出都不合适,因此作者Append的一路单独用于输出分类结果的Tocken,因此以上Transforer的输入就变成一个 197 × 768 197\\times768 197×768的二维向量。紧接着,会进行Positional Embedding操作,这一步的具体原理可以参考关键知识点。
- 将以上加入了Positional Embedding的 197 × 768 197\\times768 197×768的二维向量输入L个堆叠的的Transformer Encoder,最后从Class Token获得输出并输入MLP Head并最终得到分类的结果。
其中,Position Encoder主要是由Norm Block、Multi-Head Attention Block和MLP Block构成,MLP Block的结构由Linear+GELU+Dropout+Linear+Dropout的结构构成,Norm Block和Multi-Head Attention的结构可以参看下面的关键知识点。
用于输出的MLP Head可以为Linear+Tanh+Linear的结构或者直接为一层Linear,具体结构可以根据不同数据集做适当改变。
论文中一共给出了三种网络结构:
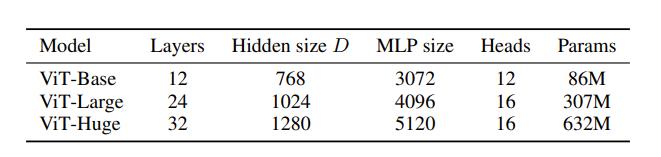
其中Layer为Transform Encoder重复堆叠的个数,Hidden Size为通过Embedding层后每个Token的维度,MLP Size是Transformer Encoder中MLP Block第一个全连接的节点个数,Heads代表Mutli-Head Attention的Head数。
1.2 关键知识点
1.2.1 Self-Attention
Self-Attention是Transformer中最重要的模块之一,Self-Attention最核心的公式就是下面这三个:
Attention
(
Q
,
K
,
V
)
=
softmax
(
Q
K
T
d
k
)
V
\\text Attention (Q, K, V)=\\operatornamesoftmax\\left(\\fracQ K^T\\sqrtd_k\\right) V
Attention (Q,K,V)=softmax(dkQKT)V
MultiHead
(
Q
,
K
,
V
)
=
Concat
(
h
e
a
d
1
,
…
,
head
h
)
W
O
\\left.\\operatornameMultiHead(Q, K, V)=\\operatornameConcat( \\mathrmhead_1, \\ldots, \\text head _\\mathrmh\\right) W^O
MultiHead(Q,K,V)=Concat(head1,…, head h)WO
where head
=
Attention
(
Q
W
i
Q
,
K
W
i
K
,
V
W
i
V
)
\\text where head =\\text Attention \\left(Q W_i^Q, K W_i^K, V W_i^V\\right)
where head = Attention (QWiQ,KWiK,VWiV)下面我们先对第一个公式展开来讲,其过程分为如下图所示:
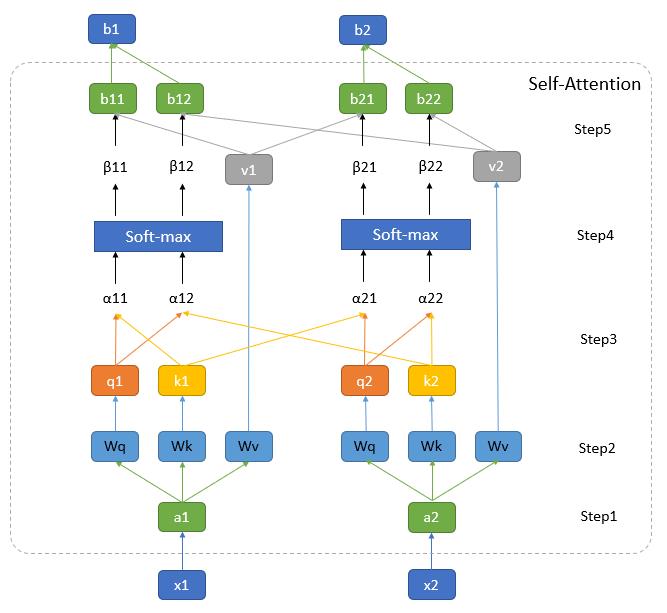
其中图中最下方的 x 1 x_1 x1和 x 2 x_2 x2为输入向量,在Vision Transformer中就是输入的图像Patch,图中最上方的 b 1 b_1 b1和 b 2 b_2 b2为经过Self-Attention编码后输出的特征,我将其中的步骤分为五步:
Step1:通过Embedding层将输入向量映射到一个更高的维度上。在Vision Transformer中这里有一层卷积层构成,这里我们可以先简单将其理解为将向量 x 1 x_1 x1和 x 2 x_2 x2映射通过某个函数 f ( x ) f(x) f(x)映射到了向量 a 1 a_1 a1和 a 2 a_2 a2。
Step2:将向量向量
a
i
a_i
ai分别与矩阵
W
q
W_q
Wq,
W
k
W_k
Wk和
W
v
W_v
Wv相乘得到
q
i
q_i
qi,
q
k
q_k
qk和
q
v
q_v
qv。在Vision Transformer中这里是由三个MLP组成,如果我们忽略偏置的话,我们就可以将抽象为三个矩阵,
W
q
W_q
Wq,
W
k
W_k
Wk和
W
v
W_v
Wv三个矩阵的参数是可以学习的,且针对不同的
a
i
a_i
ai参数是共享的。
其中,
q
i
q_i
qi是从
a
i
a_i
ai中提取的用于进行匹配的向量,我们称为query。
k
i
k_i
ki是从
a
i
a_i
ai中提取的待匹配的向量,我们称为key。
v
i
v_i
vi是从
a
i
a_i
ai中提取的用于描述信息的向量,我们成为value,在接下来的步骤中我们将利用不同
a
i
a_i
aiquery和key进行点乘获得权重,再利用该权重对value进行加权平均或者最后的输出。
Step3:依次遍历所有的 q i q_i qi和 k i k_i ki以 o ( n 2 ) o(n^2) o(n2)的计算复杂度进行向量点乘获得 α i \\alpha_i αi, α i \\alpha_i αi其实描述的是不同 a i a_i a以上是关于计算机视觉算法——Transformer学习笔记的主要内容,如果未能解决你的问题,请参考以下文章