计算机组成原理 — CPU — 主存访问
Posted 范桂飓
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了计算机组成原理 — CPU — 主存访问相关的知识,希望对你有一定的参考价值。
目录
文章目录
片内布局
前端总线是 Intel 在 1990 年在芯片中使用的通信接口,AMD 在 CPU 中也引入了类似的接口,它们的作用都是在 CPU 和 Main Memory Controller(也称作北桥)之间传递数据。前端总线在刚设计时不仅灵活,而且成本很低,但是这种设计很难支持芯片中越来越多的 CPU:
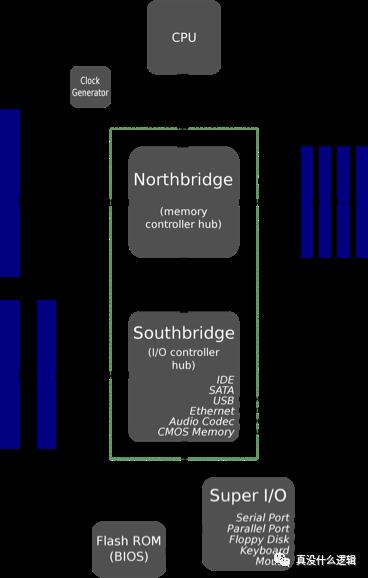
如果 CPU 不能从 Main Memory 中快速获取指令和数据,那么它会花费大量的事件等待读写 Main Memory 中的数据,所以越高端的处理器越需要高带宽和低延迟,而速度较慢的前端总线无法满足这样的需求。
Intel 和 AMD 分别引入了点对点连接的 HyperTransport 和 QuickPath Interconnect(QPI)机制解决这个问题,上图中的南桥被新的传输机制取代了,CPU 通过集成在内部的内存控制访问内存,通过 QPI 连接其他 CPU 以及 I/O 控制器。
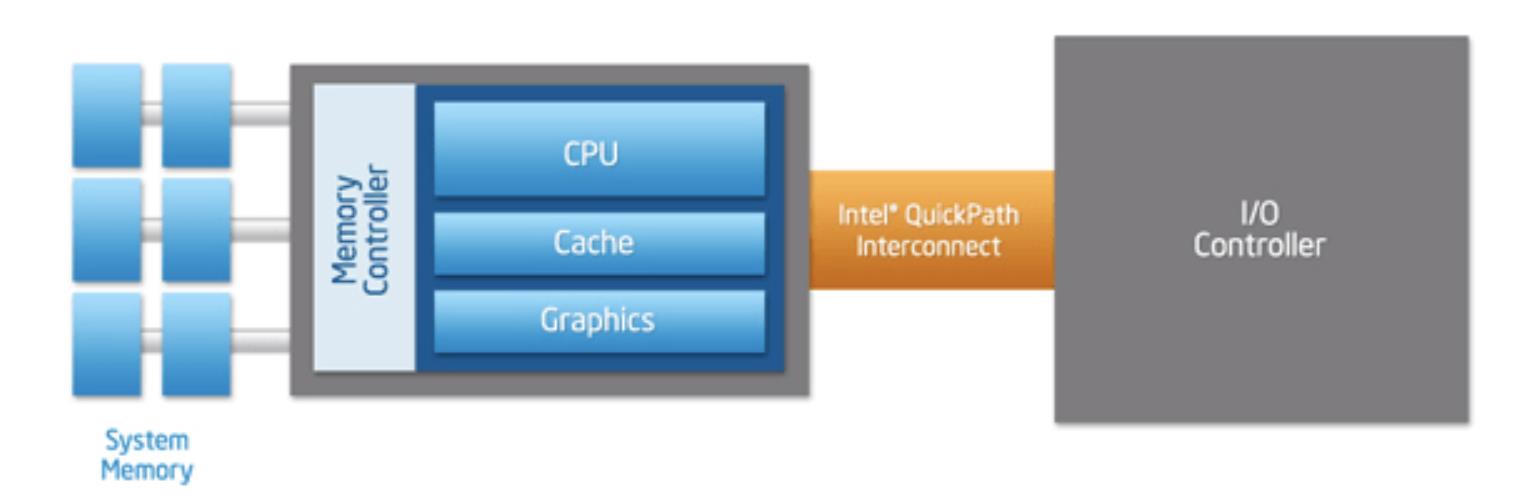
使用 QPI 让 CPU 直接连接其他组件确实可以提高效率,但是随着 CPU 核心数量的增加,这种连接的方式限制了核心的数量,所以 Intel 在 Sandy Bridge 微架构中引入了如下所示的环形总线(Ring Bus)。
Sandy Bridge 在架构中引入了片内的 GPU 和视频解码器,这些组件也需要与 CPU 共享 L3 Cache,如果所有的组件都与 L3 Cache 直接连接,那么片内会出现大量的连接,而这是芯片工程师不能接受的。
片内环形总线连接了 CPU、GPU、L3 Cache、PCIe Controller、DMI 和 Main Memory等部分,其中包含四个功能各异的环:数据、请求、确认和监听,这种设计减少了不同组件内部的连接同时也具有较好的可扩展性。
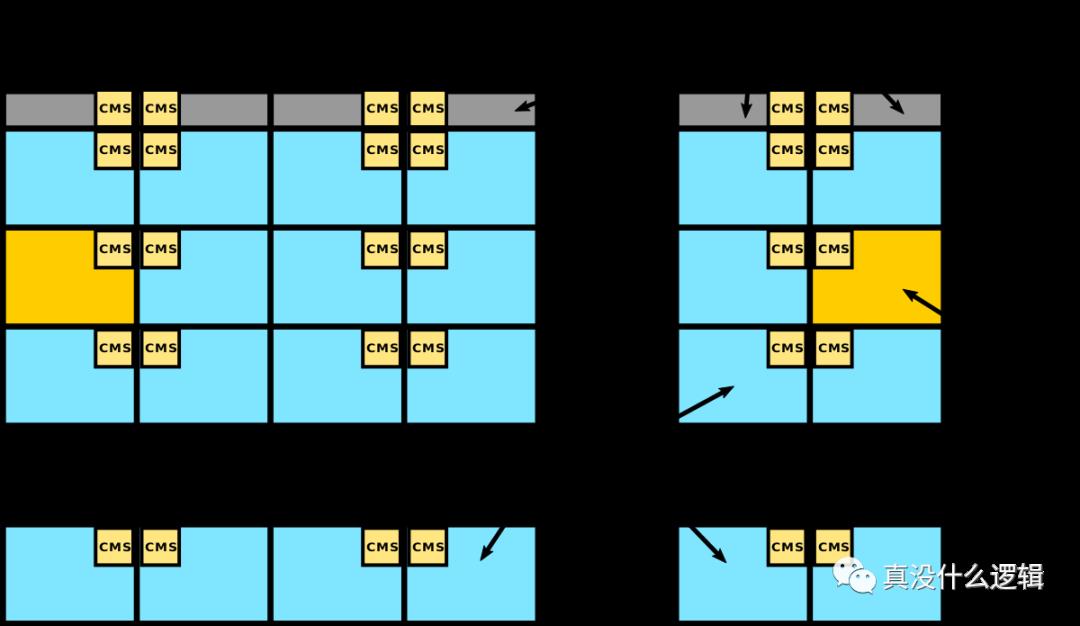
然而随着 CPU 核心数量的继续增加,环形的连接会不断变大,这会增加环的大小进而影响整个环上组件之间的访问延迟,导致该设计遇到瓶颈。Intel 由此引入了一种新的网格微架构(Mesh Interconnect Architecture)。
Intel 的 Mesh 架构是一个二维的 CPU 阵列,网络中有两种不同的组件,一种是上图中蓝色的 CPU 核心,另一种是上图中黄色的集成内存控制器,这些组件不会直接相连,相邻的模块会通过聚合网格站(Converged Mesh Stop、CMS)连接,这与我们今天看到的服务网格非常相似。
当不同组件需要传输数据时,数据包会由 CMS 负责传输,先纵向路由后水平路由,数据到达目标组件后,CMS 会将数据传给 CPU 或者集成的 Memory Controller。
CPU 访问内存
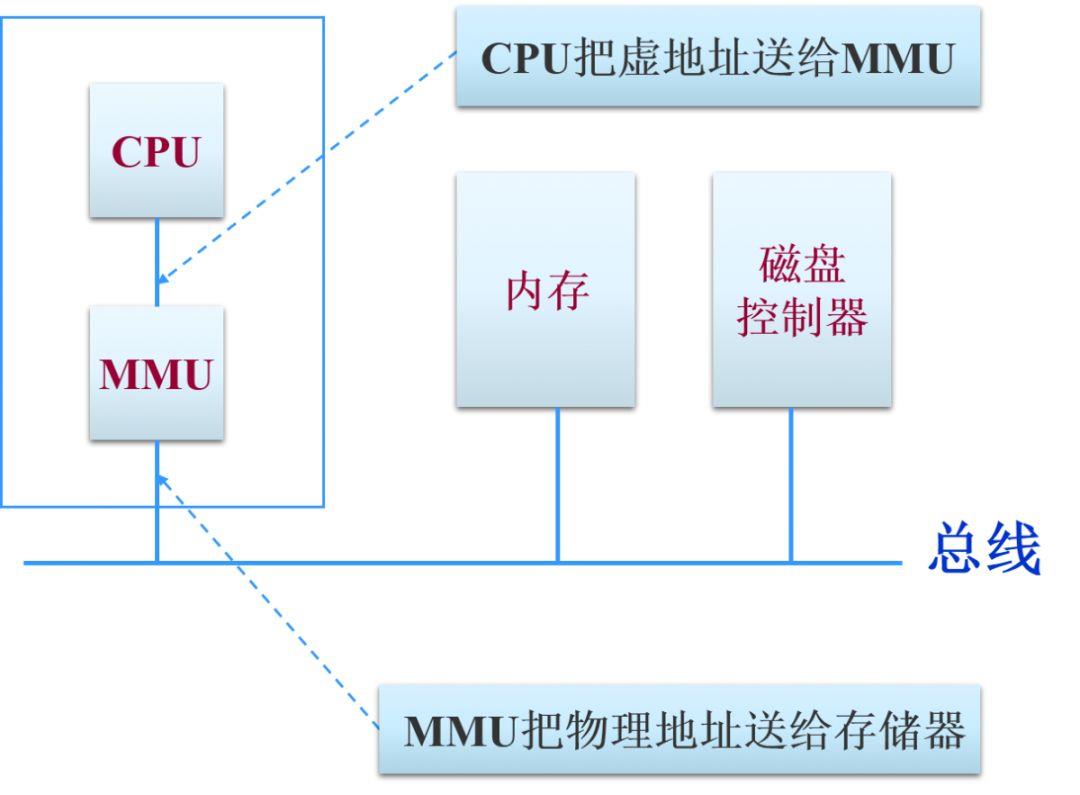
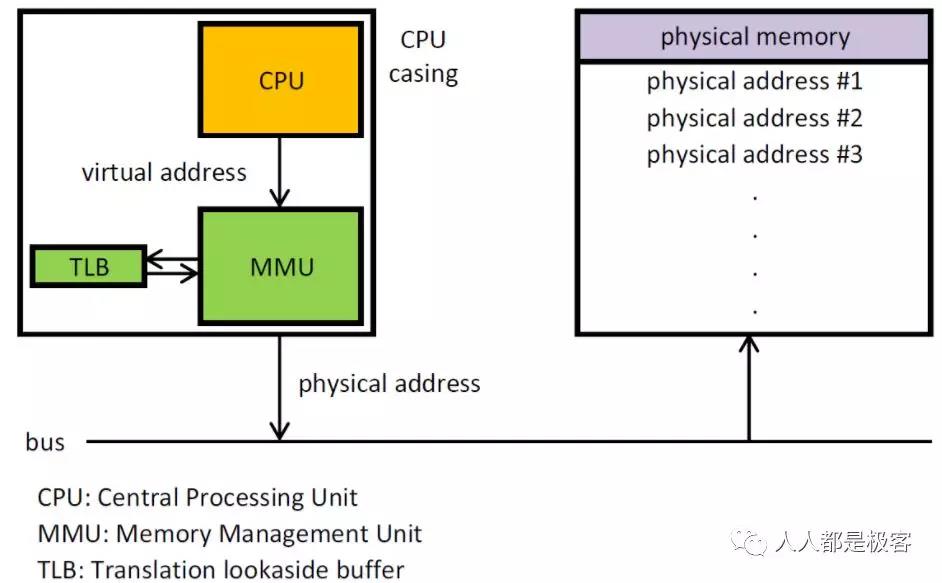
从图中可以清晰地看出,CPU、MMU、DDR 这三部分在硬件上是如何分布的。首先 CPU 在访问内存的时候都需要通过 MMU 把虚拟地址转化为物理地址,然后通过总线访问内存。MMU 开启后 CPU 看到的所有地址都是虚拟地址,CPU 把这个虚拟地址发给 MMU 后,MMU 会通过页表在页表里查出这个虚拟地址对应的物理地址是什么,从而去访问外面的 DDR(内存条)。
所以搞懂了 MMU 如何把虚拟地址转化为物理地址也就明白了 CPU 是如何通过 MMU 来访问内存的。
MMU 是通过页表把虚拟地址转换成物理地址,页表是一种特殊的数据结构,放在系统空间的页表区存放逻辑页与物理页帧的对应关系,每一个进程都有一个自己的页表。
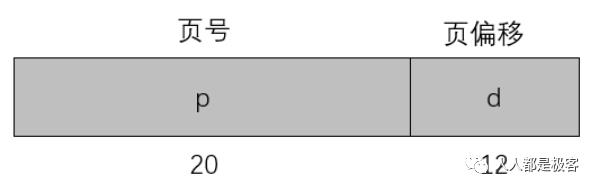
CPU 访问的虚拟地址可以分为:p(页号),用来作为页表的索引;d(页偏移),该页内的地址偏移。现在我们假设每一页的大小是 4KB,而且页表只有一级,那么页表长成下面这个样子(页表的每一行是 32 个 bit,前 20 bit 表示页号 p,后面 12 bit 表示页偏移 d):
CPU,虚拟地址,页表和物理地址的关系如下图:
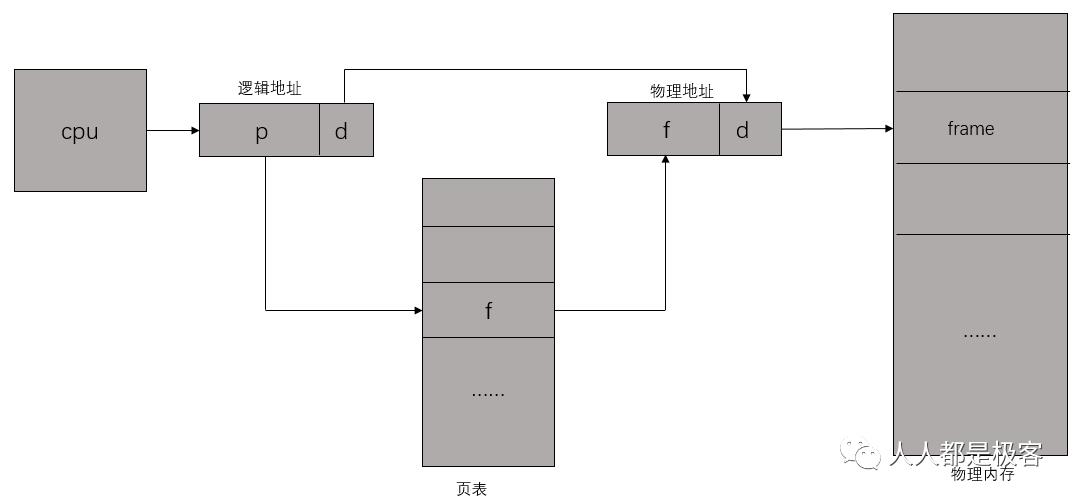
页表包含每页所在物理内存的基地址,这些基地址与页偏移的组合形成物理地址,就可送交物理单元。
上面我们发现,如果采用一级页表的话,每个进程都需要 1 个 4MB 的页表(假如虚拟地址空间为 32 位,即 4GB、每个页面映射 4KB 以及每条页表项占 4B,则进程需要 1M 个页表项,4GB/4KB = 1M),即页表(每个进程都有一个页表)占用 4MB(1M * 4B = 4MB)的内存空间)。
然而对于大多数程序来说,其使用到的空间远未达到 4GB,何必去映射不可能用到的空间呢?也就是说,一级页表覆盖了整个 4GB 虚拟地址空间,但如果某个一级页表的页表项没有被用到,也就不需要创建这个页表项对应的二级页表了,即可以在需要时才创建二级页表。做个简单的计算,假设只有 20% 的一级页表项被用到了,那么页表占用的内存空间就只有 0.804MB(1K * 4B + 0.2 * 1K * 1K * 4B = 0.804MB)。
除了在需要的时候创建二级页表外,还可以通过将此页面从磁盘调入到内存,只有一级页表在内存中,二级页表仅有一个在内存中,其余全在磁盘中(虽然这样效率非常低),则此时页表占用了8KB(1K * 4B + 1 * 1K * 4B = 8KB),对比上一步的 0.804MB,占用空间又缩小了好多倍!总而言之,采用多级页表可以节省内存。
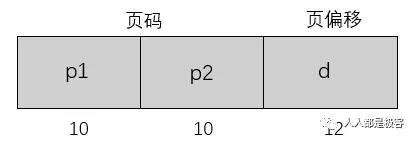
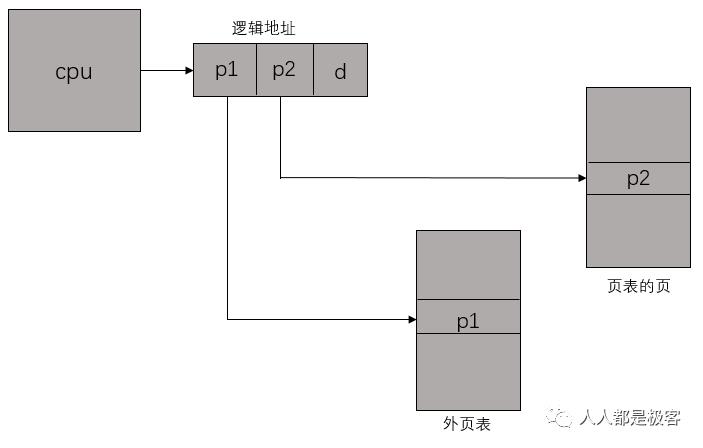
二级页表就是将页表再分页。仍以之前的 32 位系统为例,一个逻辑地址被分为 20 位的页码和 12 位的页偏移 d。因为要对页表进行再分页,该页号可分为 10 位的页码 p1 和 10 位的页偏移 p2。其中 p1 用来访问外部页表的索引,而 p2 是是外部页表的页偏移。
以上是关于计算机组成原理 — CPU — 主存访问的主要内容,如果未能解决你的问题,请参考以下文章