Spring读源码系列01---Spring核心类及关联性介绍
Posted 大忽悠爱忽悠
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spring读源码系列01---Spring核心类及关联性介绍相关的知识,希望对你有一定的参考价值。
Spring读源码系列01---Spring核心类及关联性介绍
- Spring核心类
阅读本系列之前,建议先从本专栏的两个不同视角学习spring的系列作为入门学习点(这两个系列会持续更新),先大体理解spring的架构设计与精髓,然后再来阅读本系列,深入源码分析,而不再纸上谈兵。
从整体来学spring系列文章:
Spring复杂的BeanFactory继承体系该如何理解? ----上
Spring复杂的BeanFactory继承体系该如何理解? ----中
Spring复杂的BeanFactory继承体系该如何理解?—中下
Spring复杂的BeanFactory继承体系该如何理解?—下
该系列持续更新中…
独特视角学习spring系列文章:
该系列持续更新中…
正式开始之前,还是说一下,本系列参考spring深度源码解析第一版书籍整理而来,这本书比较的老,但是我认为spring核心变化不大,还是可以学习一下的
Spring核心类
引子
- 准备一个简单的bean
public class Bean
- 准备一个简单的配置文件
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd">
<bean id="bean" class="org.deepSpring.Bean"/>
</beans>
- 准备一个简单的容器
public class DeepSpringStudy
public static void main(String[] args)
ClassPathResource resource = new ClassPathResource("bean.xml");
boolean exists = resource.exists();
BeanFactory xmlBeanFactory = new XmlBeanFactory(resource);
Object bean = xmlBeanFactory.getBean("bean");
System.out.println(bean);
- 进行一波简单的测试

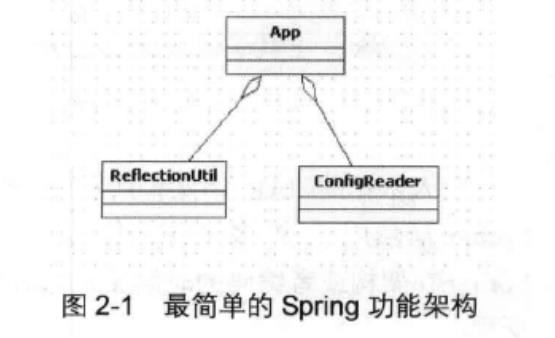
上面的程序执行思路可以简化到上面这幅图描述的这样
- reader负责读取配置文件相关信息,放在内存中
- reflectionUtil负责读取放在内存中的信息,然后反射创建对象
- 完成逻辑的串联工作
DefaultListableBeanFactory

//该类已经过时了,不推荐使用
@Deprecated
@SuppressWarnings("serial", "all")
public class XmlBeanFactory extends DefaultListableBeanFactory
//该方法就多了一个XmlBeanDefinitionReader
private final XmlBeanDefinitionReader reader = new XmlBeanDefinitionReader(this);
public XmlBeanFactory(Resource resource) throws BeansException
this(resource, null);
public XmlBeanFactory(Resource resource, BeanFactory parentBeanFactory) throws BeansException
super(parentBeanFactory);
//通过这个XmlBeanDefinitionReader去解析配置文件,将解析后的信息放入内存中
this.reader.loadBeanDefinitions(resource);
DefaultListableBeanFactory的继承体系
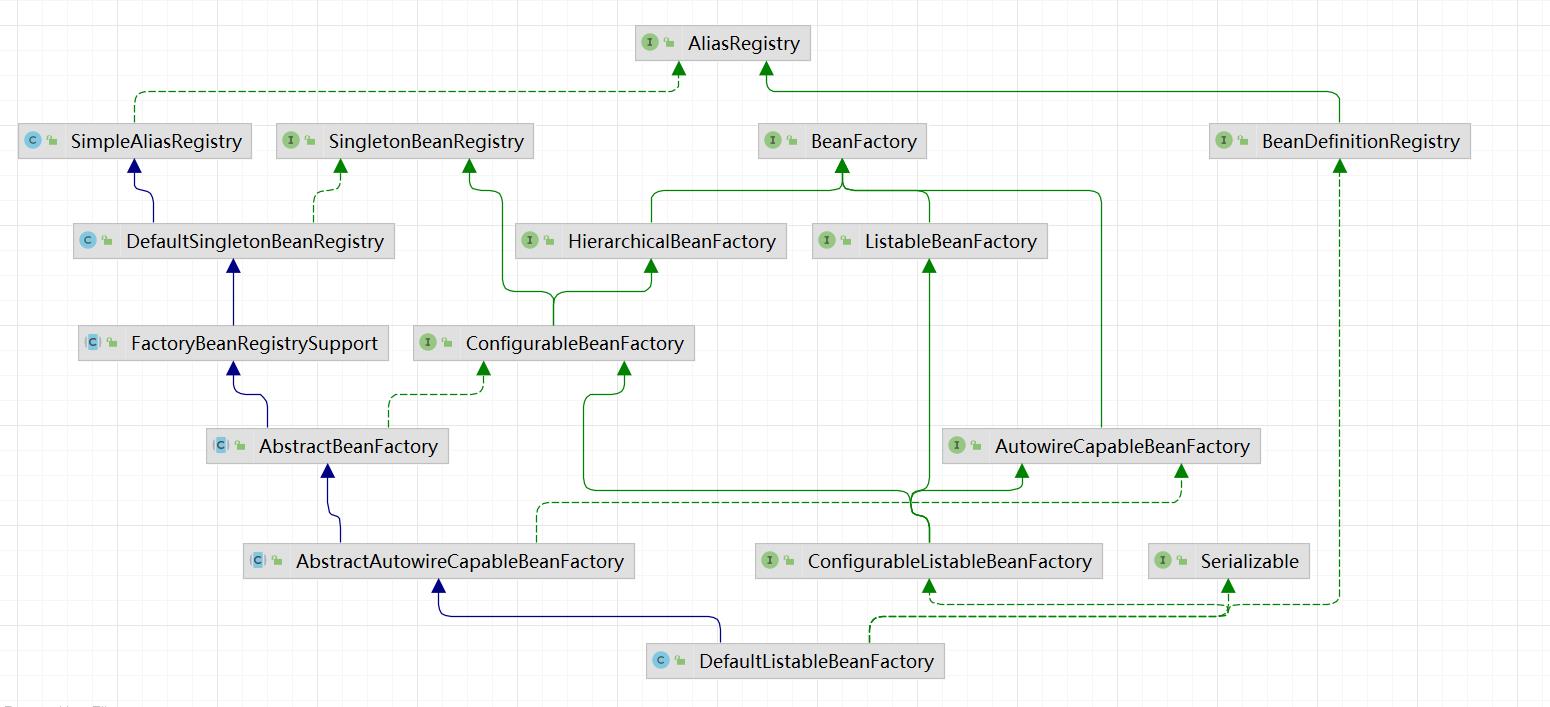
这张图大家先至少看一遍把,然后根据名字去猜测每个类的作用是什么
大家主要看一下下面这张图,理解一下
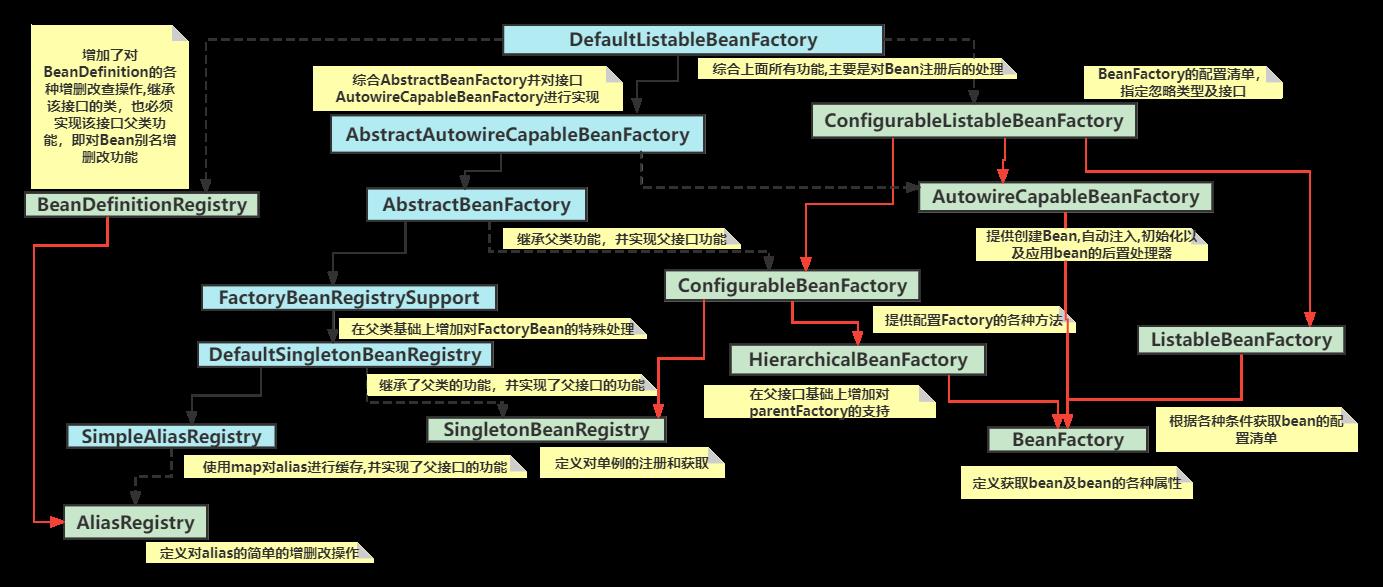
为什么要设计成接口继承接口,这样和所有功能写在一个接口中不是一样的吗?
这样做的目的,是为了复用接口的功能,同样是符合接口的单一职责功能,是一种设计模式的思想,例如:如果后面我只想在BeanFactory底层接口的基础上进行扩展,那么就只需要继承顶层这个接口即可,不需要去实现其他与BeanFactory不相关的方法

XmlBeanDefinitionReader

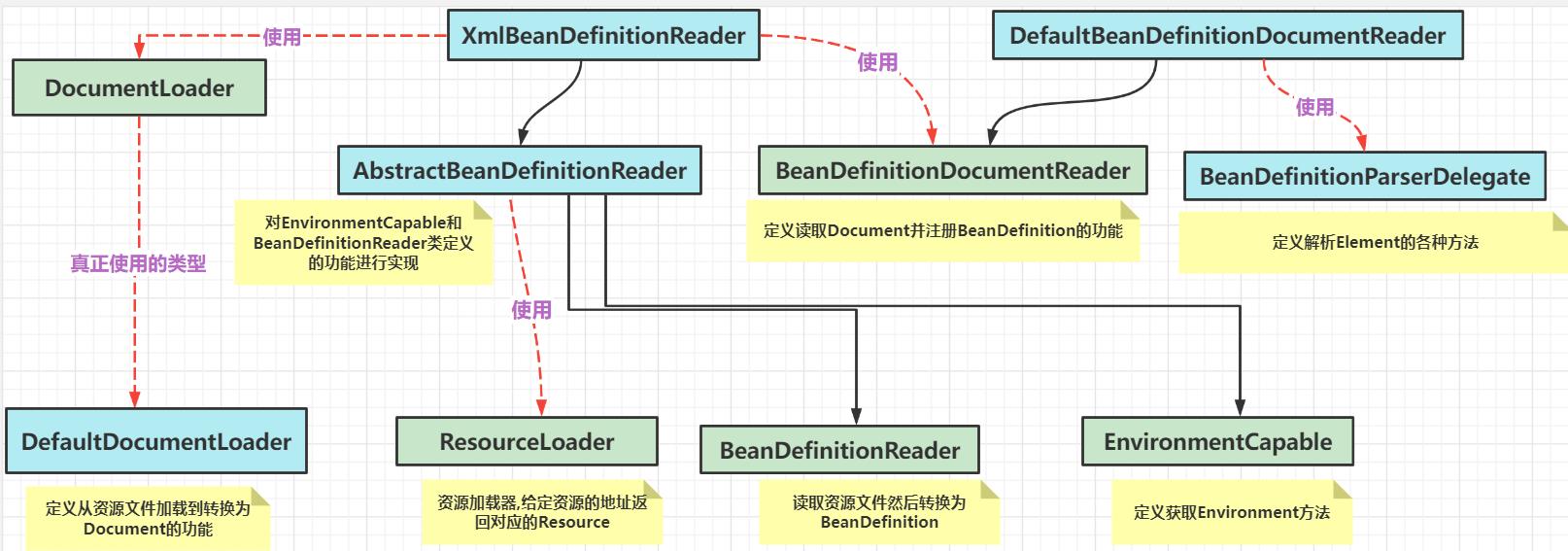


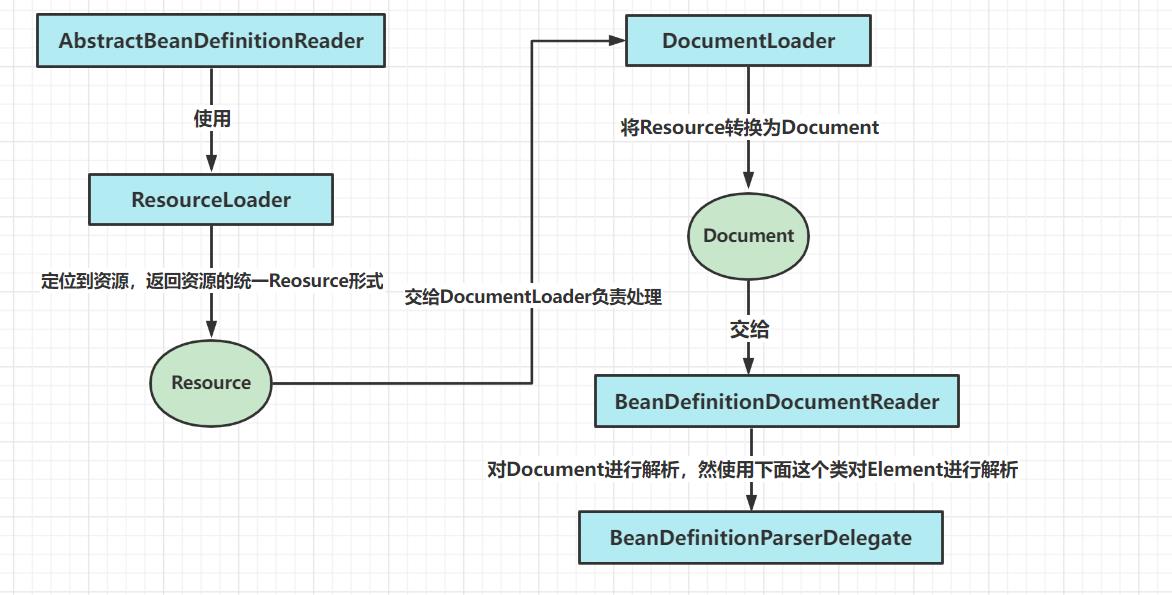
容器的基础XmlBeanFactory
我们下面来研究一下这行代码:
BeanFactory xmlBeanFactory = new XmlBeanFactory(new ClassPathResource("bean.xml"));
xmlBeanFactory初始化时序图如下:
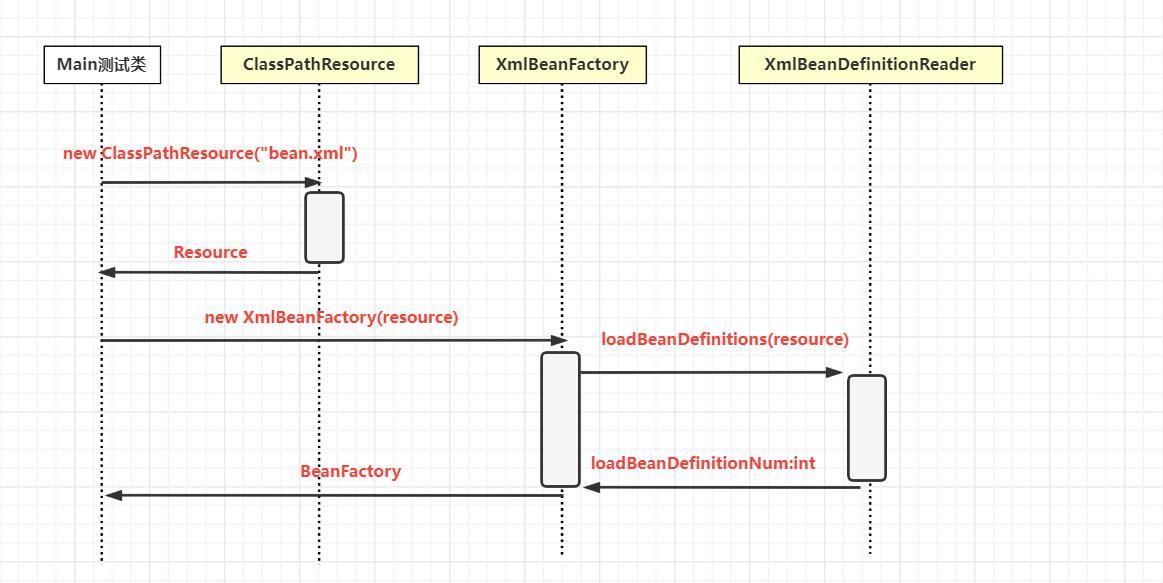

配置文件—>Resource

public interface InputStreamSource
InputStream getInputStream() throws IOException;

public interface Resource extends InputStreamSource
boolean exists();
default boolean isReadable()
return this.exists();
default boolean isOpen()
return false;
default boolean isFile()
return false;
URL getURL() throws IOException;
URI getURI() throws IOException;
File getFile() throws IOException;
default ReadableByteChannel readableChannel() throws IOException
return Channels.newChannel(this.getInputStream());
long contentLength() throws IOException;
long lastModified() throws IOException;
Resource createRelative(String var1) throws IOException;
@Nullable
String getFilename();
String getDescription();


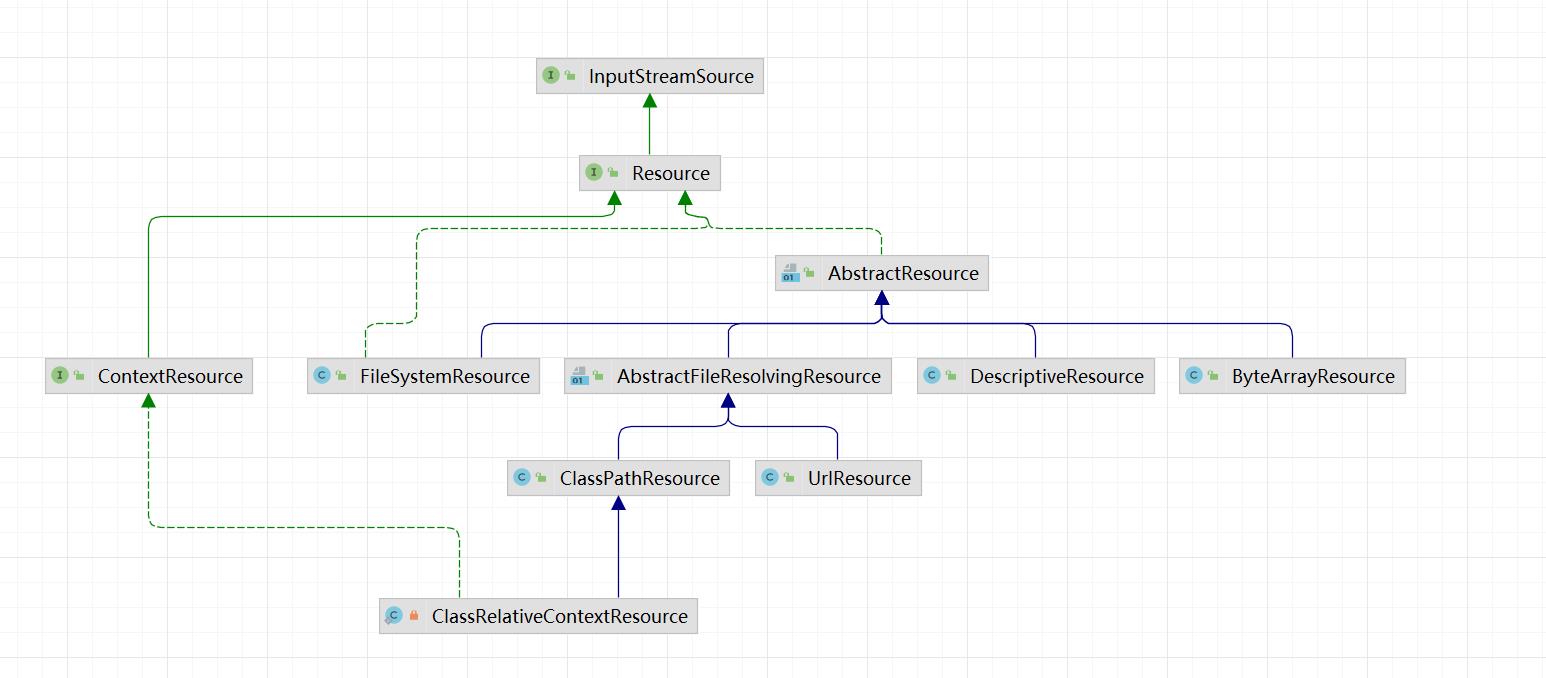
当然这里对ClassPathResource等资源实现类的代码也都非常简单容易理解,可以一起看一下:
简单看一下ClassPathResource的getInputStream()获取资源输入流的方法源码:
public InputStream getInputStream() throws IOException
InputStream is;
if (this.clazz != null)
//这里可以看出是从类路径下加载的资源
is = this.clazz.getResourceAsStream(this.path);
else if (this.classLoader != null)
//这里也可以看出来
is = this.classLoader.getResourceAsStream(this.path);
else
//也是从类路径下加载的资源
is = ClassLoader.getSystemResourceAsStream(this.path);
if (is == null)
throw new FileNotFoundException(this.getDescription() + " cannot be opened because it does not exist");
else
return is;
在来看看FileSystemResource的方法源码:
public InputStream getInputStream() throws IOException
try
//从文件系统中加载资源文件
return Files.newInputStream(this.filePath);
catch (NoSuchFileException var2)
throw new FileNotFoundException(var2.getMessage());
更多实现细节,请自行翻阅源码查看
进入源码追踪
XmlBeanFactory的构造函数

public XmlBeanFactory(Resource resource) throws BeansException
this(resource, null);
| |
| |
\\ /
public XmlBeanFactory(Resource resource, BeanFactory parentBeanFactory) throws BeansException
//调用父类DefaultListableBeanFactory--->继续调用父类AbstractAutowireCapableBeanFactory的构造方法
super(parentBeanFactory);
//调用XmlBeanDefinitionReader的loadBeanDefinitions从配置文件中加载bean的定义信息
this.reader.loadBeanDefinitions(resource);

public AbstractAutowireCapableBeanFactory()
super();
//这个比较重要---忽略给定接口的自动装配功能
ignoreDependencyInterface(BeanNameAware.class);
ignoreDependencyInterface(BeanFactoryAware.class);
ignoreDependencyInterface(BeanClassLoaderAware.class);
//这是spring3之后新增的代码---书上没讲,我也不清楚有啥用
if (NativeDetector.inNativeImage())
//指定初始化策略为简单的初始化策略即反射创建对象
this.instantiationStrategy = new SimpleInstantiationStrategy();
else
//指定初始化策略为cglib代理的策略
this.instantiationStrategy = new CglibSubclassingInstantiationStrategy();

看不懂就先放放,因为这里我也有点迷糊
loadBeanDefinitions—加载Bean

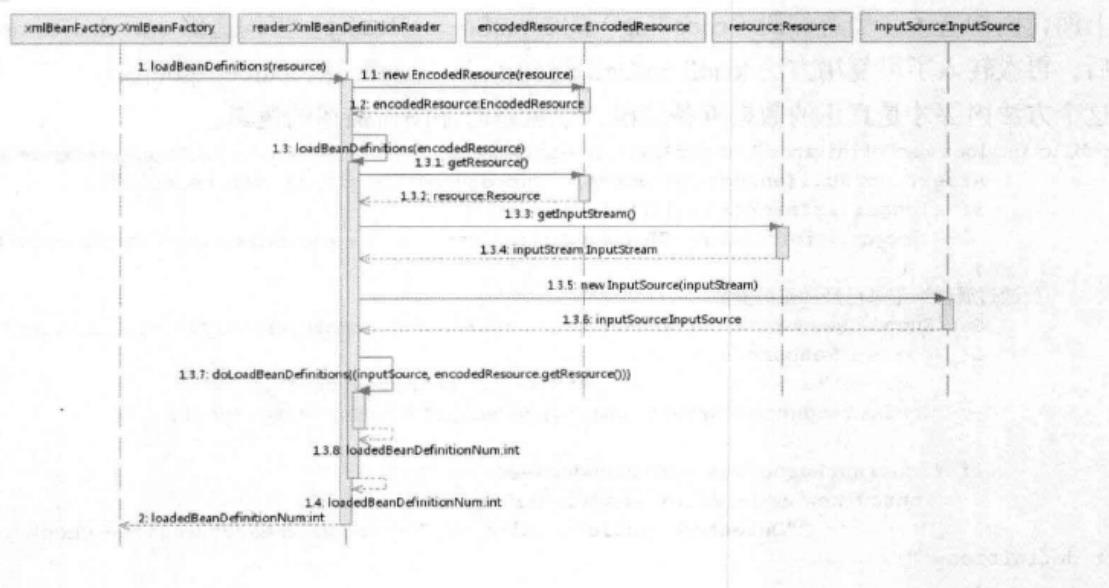
下面对时序图的处理过程进行梳理和分析:


XmlBeanDefinitionReader类:
public int loadBeanDefinitions(Resource resource) throws BeanDefinitionStoreException
return loadBeanDefinitions(new EncodedResource(resource));

EncodedResource类主要负责对字符进行编码处理:
public Reader getReader() throws IOException
if (this.charset != null)
return new InputStreamReader(this.resource.getInputStream(), this.charset);
else
return this.encoding != null ? new InputStreamReader(this.resource.getInputStream(), this.encoding) : new InputStreamReader(this.resource.getInputStream());

/**
* Load bean definitions from the specified XML file.
* @param encodedResource the resource descriptor for the XML file,
* allowing to specify an encoding to use for parsing the file
* @return the number of bean definitions found
* @throws BeanDefinitionStoreException in case of loading or parsing errors
*/
public int loadBeanDefinitions(EncodedResource encodedResource) throws BeanDefinitionStoreException
Assert.notNull(encodedResource, "EncodedResource must not be null");
if (logger.isTraceEnabled())
logger.trace("Loading XML bean definitions from " + encodedResource);
//通过属性记录已经加载的资源
Set<EncodedResource> currentResources = this.resourcesCurrentlyBeingLoaded.get();
//将当前需要加载的资源填入集合中
if (!currentResources.add(encodedResource))
throw new BeanDefinitionStoreException(
"Detected cyclic loading of " + encodedResource + " - check your import definitions!");
//从 encodedResource中获取已经封装号的Resource对象,并再次从Resource中获取其中的inputstream
try (InputStream inputStream = encodedResource.getResource().getInputStream())
//InputSource这个类不来自于spring,它的全路径是org.xml.sax.InputSource
InputSource inputSource = new InputSource(inputStream);
//如果设置了编码的话
if (encodedResource.getEncoding() != null)
//就从encodedResource中取出设置好的编码
inputSource.setEncoding(encodedResource.getEncoding());
//真正进入了核心逻辑
return doLoadBeanDefinitions(inputSource, encodedResource.getResource());
catch (IOException ex)
throw new BeanDefinitionStoreException(
"IOException parsing XML document from " + encodedResource.getResource(), ex);
finally
//从已加载结合中移除解析完毕的资源
currentResources.remove(encodedResource);
if (currentResources.isEmpty())
this.resourcesCurrentlyBeingLoaded.remove();
到这里为止,只是做了定位资源,指定文件编码格式两件事情,下面才是进入真正加载逻辑

doLoadBeanDefinitions—真正将bean的定义信息从xml配置文件解析出来的过程
/**
* Actually load bean definitions from the specified XML file.
* @param inputSource the SAX InputSource to read from
* @param resource the resource descriptor for the XML file
* @return the number of bean definitions found
* @throws BeanDefinitionStoreException in case of loading or parsing errors
* @see #doLoadDocument
* @see #registerBeanDefinitions
*/
protected int doLoadBeanDefinitions(InputSource inputSource, Resource resource)
throws BeanDefinitionStoreException
try
//加载xml文件,获取对应的Document对象
Document doc = doLoadDocument(inputSource, resource);
//根据返回的Document注册bean的定义信息
int count = registerBeanDefinitions(doc, resource);
if (logger.isDebugEnabled())
logger.debug("Loaded " + count + " bean definitions from " + resource);
return count;
....全都是catch--当然这里抛出的异常也非常重要,值得各位去查看,但是限于篇幅原因,这里就不贴出来了
doLoadDocument将xml配置文件先解析为DOM树
这个过程书上详细讲了一下,但是这里我不打算作为重点展开,大概贴一下思路吧:
- 拿到XML文档的类型,是DTD还是XSD

如果不清楚啥是DTD和XSD可以自行了解一下,这里感兴趣可以去自己翻阅源码看一下大概的思路
- 使用XML解析器对xml文档进行解析,这里感兴趣的小伙伴可以自行去了解一下解析过程,不感星球的小伙伴,只需要知道这里会读取xml文档,并按照xml解析方法将xml文件解析映射到Document对象上


registerBeanDefinitions—解析并注册BeanDefinitions

XmlBeanDefinitionReader类:
public int registerBeanDefinitions(Document doc, Resource resource) throws BeanDefinitionStoreException
//使用DefaultBeanDefinitionDocumentReader实例化BeanDefinitionDocumentReader---如果你忘了,请回看上面的继承图
BeanDefinitionDocumentReader documentReader = createBeanDefinitionDocumentReader();
//在实例化BeanDefintionReader的时候会将BeanDefinitionRegistry传入,默认使用继承至DefaultListableBeanFactory的子类
//记录统计前BeanDefintion的加载个数
int countBefore = getRegistry().getBeanDefinitionCount();
//加载及注册Bean---重点
documentReader.registerBeanDefinitions(doc, createReaderContext(resource));
//记录本次加载的BeanDefintion个数
return getRegistry().getBeanDefinitionCount() - countBefore;
在实例化BeanDefintionReader的时候会将BeanDefinitionRegistry传入
public XmlBeanDefinitionReader(BeanDefinitionRegistry registry)
super(registry);

BeanDefinitionDocumentReader#registerBeanDefinitions方法----吊胃口中
//加载及注册Bean---重点---传入的是解析得到的DOM树,还有一个上下文环境
documentReader.registerBeanDefinitions(doc, createReaderContext(resource));
|
|
\\ /
public void registerBeanDefinitions(Document doc, XmlReaderContext readerContext)
//保存上下文环境
this.readerContext = readerContext;
//重点--真正干活的地方
//doc.getDocumentElement()传入提取出来的root标签---这里是beans标签
doRegisterBeanDefinitions(doc.getDocumentElement());
BeanDefinitionDocumentReader#doRegisterBeanDefinitions—准备一下,然后虚晃一枪

//传入的Element是根元素beans
protected void doRegisterBeanDefinitions(Element root)
//创建Bean定义解析器委托对象--由它完成bean定义解析工作
BeanDefinitionParserDelegate parent = this.delegate;