自己动手写个数据库系统:磁盘的基本原理和数据库底层文件系统实现
Posted tyler_download
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了自己动手写个数据库系统:磁盘的基本原理和数据库底层文件系统实现相关的知识,希望对你有一定的参考价值。
我做过操作系统,完成过tcpip协议栈,同时也完成过一个具体而微的编译器,接下来就剩下数据库了。事实上数据库的难度系数要大于编译器,复杂度跟操作系统差不多,因此我一直感觉不好下手。随着一段时间的积累,我感觉似乎有了入手的方向,因此想试试看,看能不能也从0到1完成一个具有基本功能,能执行一部分sql语言的数据库系统。由于数据库系统的难度颇大,我也不确定能完成到哪一步,那么就脚踩香蕉皮,滑到哪算哪吧。
目前数据库分为两大类,一类就是mysql这种,基于文件系统,另一类是redis,完全基于内存。前者的设计比后者要复杂得多,原因在于前者需要将大量数据存放在磁盘上,而磁盘相比于内存,其读写速度要慢上好几个数量级,因此如何组织数据在磁盘上存放,如何通过操控磁盘尽可能减少读写延迟,这就需要设计精妙而又复杂的算法。首先我们先看看为何基于文件的数据库系统要充分考虑并且利用磁盘的特性。
一个磁盘通常包含多个可以旋转的磁片,磁片上有很多个同心圆,也称为”轨道“,这些轨道是磁盘用于存储数据的磁性物质。而轨道也不是全部都能用于存储数据,它自身还分成了多个组成部分,我们称为扇区,扇区才是用于存储数据的地方。扇区之间存在缝隙,这些缝隙无法存储数据,因此磁头在将数据写入连续多个扇区时,需要避开这些缝隙。磁片有上下两面,因此一个磁片会被两个磁头夹住,当要读取某个轨道上的数据时,磁头会移动到对应轨道上方,然后等盘片将给定扇区旋转到磁头正下方时才能读取数据,盘片的结构如下
一个磁盘会有多个盘片以及对应的磁头组成,其基本结构如下:
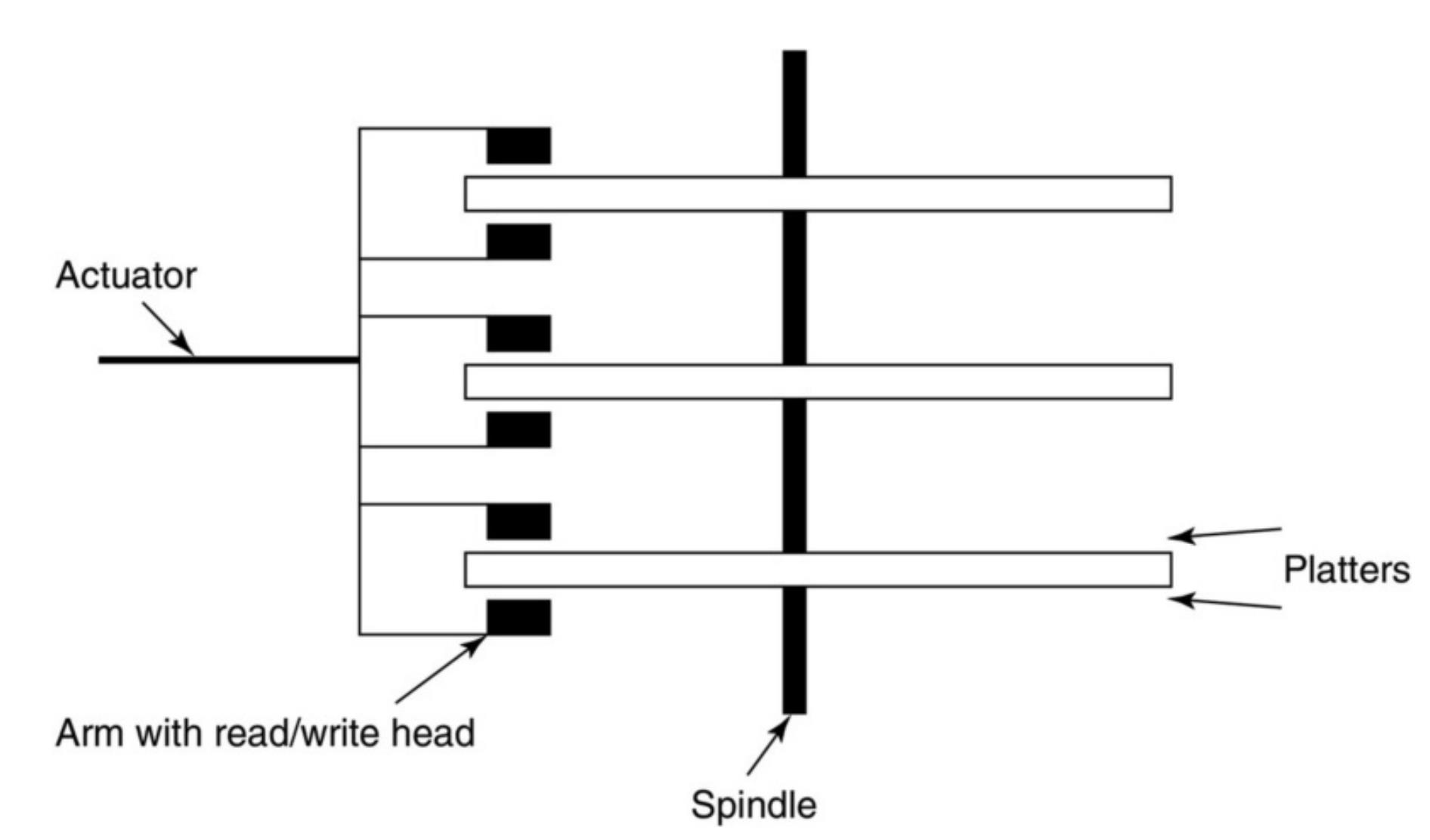
从上图看到,每个盘片都被两个磁头夹住,这里需要注意的是,所有磁头在移动时都必须同时运动,也就是当某个磁头想要读取某个轨道时,所有磁头都必须同时移动到给定轨道,不能说一个磁头移动到第10轨道,让后另一个磁头挪到第8轨道,同时在同一时刻只能有一个磁头进行读写,基于这些特点使得磁片的读写速度非常慢。
有四个因素会影响影响磁盘读写速度,分别为容量,旋转速度,传输速度和磁头挪动时间。容量就是整个磁盘所能存储的数据量,现在一个盘片的数据容量能达到40G以上。旋转速度是指磁盘旋转一周所需时间,通常情况下磁盘一分钟能旋转5400到15000转。传输速率就是数据被磁头最后输送到内存的时间。磁头挪到时间是指磁头从当前轨道挪动到目标轨道所需要的时间,这个时间最长就是当磁头从最内部轨道移动到最外部轨道所需时间,为了后面方便推导,我们磁头挪动的平均时间设置为5ms。
假设我们有一个2个盘片的磁盘,其一分钟能转10000圈,磁盘移动的平均时间是5ms,每个盘面包含10000个轨道,每个轨道包含500000字节,于是我们能得到以下数据
首先是磁盘容量,它的计算为 500,000字节 * 10000 个轨道 * 4个盘面 = 20,000,000,000字节,大概是20G
我们看看传输率,一分钟能转10000圈,于是一秒能转10000 / 60 = 166圈,一个轨道含有500000字节,于是一秒能读取 166 * 500000 这么多字节,约等于83M。
接下来我们计算一下磁盘的读写速度,这个对数据库的运行效率影响很大。我们要计算的第一个数据叫旋转延迟,它的意思是当磁头挪到给定轨道后,等待磁盘将数据起始出旋转到磁头正下方的时间,显然我们并不知道要读取的数据在轨道哪个确切位置,因此我们认为平均旋转0.5圈能达到给定位置,由于1秒转166圈,那么转一圈的时间是 (1 / 166)秒,那么转半圈的时间就是(1 / 166) * 0.5 约等于 3ms。
我们看传输1个字节所需时间,前面我们看到1秒读取大概83MB的数据,也就是1秒读取83,000,000字节,于是读取一个字节的时间是 (1 / 83,000,000) 大概是0.000012ms。于是传输1000字节也就是1MB的时间是0.000012 * 1000 也就是0.012毫秒.
我们看将磁盘上1个字节读入内存的时间。首先是磁头挪到给定字节所在的轨道,也就是5毫秒,然后等待给定1字节所在位置旋转到磁头下方,也就是3毫秒,然后这个字节传输到内存,也就是上面计算的0.000012毫秒,于是总共需要时间大概是8.000012毫秒。
同理将1000字节从磁盘读入内存或从内存写入磁盘所需时间就是5 + 3 + 0.012 = 8.012毫秒。这里是一个关键,我们看到读取1000个字节所需时间跟读取1个字节所需时间几乎相同,因此要加快读写效率,一个方法就是依次读写大块数据。前面我们提到过一个轨道由多个扇区组成,磁盘在读写时,一次读写的最小数据量就是一个扇区的大小,通常情况下是512字节。
由于磁盘读写速度在毫秒级,而内存读写速度在纳秒级,因此磁盘读写相等慢,这就有必要使用某些方法改进读写效率。一种方法是缓存,磁盘往往会有一个特定的缓冲器,它一次会将大块数据读入缓存,等下次程序读取磁盘时,它现在缓存里查看数据是否已经存在,存在则立即返回数据,要不然再从磁盘读取。这个特性对数据库系统来说作用不大,因此后者必然会有自己的缓存。磁盘缓存的一个作用在于预获取,当程序要读取给定轨道的第1个扇区,那么磁盘会把整个轨道的数据都读入缓存,比较读取整个轨道所用时间并不比读取1个扇区多多少。
我们前面提到过,当磁头移动时,是所有磁头同时移动到给定轨道,这个特性就有了优化效率的机会,如果我们把同一个文件的的数据都写入到不同盘面上的同一个轨道,那么读取文件数据时,我们只需要挪到磁头一次即可,这种不同盘面的同一个轨道所形成的集合叫柱面。如果文件内容太大,所有盘面上同一个轨道都存放不下,那么另一个策略就是将数据存放到相邻轨道,这样磁头挪动的距离就会短。
另一种改进就是使用多个磁盘,我们把一个文件的部分数据存储在第一个磁盘,另一部分数据存储在其他磁盘,由于磁盘数据的读取能同步进行,于是时间就能同步提升。通常情况下,”民用“级别的数据库系统不需要考虑磁盘结构,这些是操作系统控制的范畴,最常用的MySQL数据库,它对磁盘的读写也必须依赖于操作系统,因此我们自己实现数据库时,也必然要依赖于系统。因此在实现上我们将采取的方案是,我们把数据库的数据用系统文件的形式存储,但是我们把系统文件抽象成磁盘来看待,在磁盘读写中,我们通常把若干个扇区作为一个统一单元来读写,这个统一单元叫块区,于是当我们把操作系统提供的文件看做”磁盘“时,我们读写文件也基于”块区“作为单位,这里看起来有点抽象,在后面代码实现中我们会让它具体起来。
接下来我们看看如何实现数据库系统最底层的文件系统,这里需要注意的是,我们不能把文件当做一个连续的数组来看待,而是要将其作为“磁盘”来看待,因此我们会以区块为单位来对文件进行读写。由于我们不能越过操作系统直接操作磁盘,因此我们需要利用操作系统对磁盘读写的优化能力来加快数据库的读取效率,基本策略就是,我们要将数据以二进制的文件进行存储,操作系统会尽量把同一个文件的数据存储在磁盘同一轨道,或是距离尽可能接近的轨道之间,然后我们再以”页面“的方式将数据从文件读入内存,具体的细节可以从代码实现中看出来,首先创建根目录simple_db,然后创建子目录file_manager,这里面用于实现数据库系层文件系统功能,在file_manager中添加block_id.go,实现代码如下:
package file_manager
import (
"crypto/sha256"
"fmt"
)
type BlockId struct
file_name string //区块所在文件
blk_num uint64 //区块的标号
func NewBlockId(file_name string, blk_num uint64) *BlockId
return &BlockId
file_name: file_name,
blk_num: blk_num,
func (b *BlockId) FileName() string
return b.file_name
func (b *BlockId) Number() uint64
return b.blk_num
func (b *BlockId) Equals(other *BlockId) bool
return b.file_name == other.file_name && b.blk_num == other.blk_num
func asSha256(o interface) string
h := sha256.New()
h.Write([]byte(fmt.Sprintf("%v", o)))
return fmt.Sprintf("%x", h.Sum(nil))
func (b *BlockId) HashCode() string
return asSha256(*b)
BlockId的作用是对区块的抽象,它对应二进制文件某个位置的一块连续内存的记录,它的成分比较简单,它只包含了块号和它所包含数据来自于哪个文件。接下来继续创建Page.go文件,它作用是让数据库系统分配一块内存,然后将数据从二进制文件读取后存储在内存中,其实现代码如下:
package file_manager
import (
"encoding/binary"
)
type Page struct
buffer []byte
func NewPageBySize(block_size uint64) *Page
bytes := make([]byte, block_size)
return &Page
buffer: bytes,
func NewPageByBytes(bytes []byte) *Page
return &Page
buffer: bytes,
func (p *Page) GetInt(offset uint64) uint64
num := binary.LittleEndian.Uint64(p.buffer[offset : offset+8])
return num
func uint64ToByteArray(val uint64) []byte
b := make([]byte, 8)
binary.LittleEndian.PutUint64(b, val)
return b
func (p *Page) SetInt(offset uint64, val uint64)
b := uint64ToByteArray(val)
copy(p.buffer[offset:], b)
func (p *Page) GetBytes(offset uint64) []byte
len := binary.LittleEndian.Uint64(p.buffer[offset : offset+8]) //8个字节表示后续二进制数据长度
new_buf := make([]byte, len)
copy(new_buf, p.buffer[offset+8:])
return new_buf
func (p *Page) SetBytes(offset uint64, b []byte)
length := uint64(len(b))
len_buf := uint64ToByteArray(length)
copy(p.buffer[offset:], len_buf)
copy(p.buffer[offset+8:], b)
func (p *Page) GetString(offset uint64) string
str_bytes := p.GetBytes(offset)
return string(str_bytes)
func (p *Page) SetString(offset uint64, s string)
str_bytes := []byte(s)
p.SetBytes(offset, str_bytes)
func (p *Page) MaxLengthForString(s string) uint64
bs := []byte(s) //返回字符串相对于字节数组的长度
uint64_size := 8 //存储字符串时预先存储其长度,也就是uint64,它占了8个字节
return uint64(uint64_size + len(bs))
func (p *Page) contents() []byte
return p.buffer
从代码看,它支持特定数据的读取,例如从给定偏移写入或读取uint64类型的整形,或是读写字符串数据,我们添加该类对应的测试代码,创建page_test.go:
package file_manager
import (
"testing"
"github.com/stretchr/testify/require"
)
func TestSetAndGetInt(t *testing.T)
page := NewPageBySize(256)
val := uint64(1234)
offset := uint64(23) //指定写入偏移
page.SetInt(offset, val)
val_got := page.GetInt(offset)
require.Equal(t, val, val_got)
func TestSetAndGetByteArray(t *testing.T)
page := NewPageBySize(256)
bs := []byte1, 2, 3, 4, 5, 6
offset := uint64(111)
page.SetBytes(offset, bs)
bs_got := page.GetBytes(offset)
require.Equal(t, bs, bs_got)
func TestSetAndGetString(t *testing.T)
// require.Equal(t, 1, 2) 先让测试失败,以确保该测试确实得到了执行
page := NewPageBySize(256)
s := "hello, 世界"
offset := uint64(177)
page.SetString(offset, s)
s_got := page.GetString(offset)
require.Equal(t, s, s_got)
func TestMaxLengthForString(t *testing.T)
//require.Equal(t, 1, 2)
s := "hello, 世界"
s_len := uint64(len([]byte(s)))
page := NewPageBySize(256)
s_len_got := page.MaxLengthForString(s)
require.Equal(t, s_len, s_len_got)
func TestGetContents(t *testing.T)
//require.Equal(t, 1, 2)
bs := []byte1, 2, 3, 4, 5, 6
page := NewPageByBytes(bs)
bs_got := page.contents()
require.Equal(t, bs, bs_got)
从测试代码我们可以看到Page类的用处,它就是为了读写uint64,和字符串等特定的数据,最后我们完成的是文件管理器对象,生成file_manager.go,然后实现代码如下:
package file_manager
import (
"os"
"path/filepath"
"strings"
"sync"
)
type FileManager struct
db_directory string
block_size uint64
is_new bool
open_files map[string]*os.File
mu sync.Mutex
func NewFileManager(db_directory string, block_size uint64) (*FileManager, error)
file_manager := FileManager
db_directory: db_directory,
block_size: block_size,
is_new: false,
open_files: make(map[string]*os.File),
if _, err := os.Stat(db_directory); os.IsNotExist(err)
//目录不存在则创建
file_manager.is_new = true
err = os.Mkdir(db_directory, os.ModeDir)
if err != nil
return nil, err
else
//目录存在,则先清楚目录下的临时文件
err := filepath.Walk(db_directory, func(path string, info os.FileInfo, err error) error
mode := info.Mode()
if mode.IsRegular()
name := info.Name()
if strings.HasPrefix(name, "temp")
//删除临时文件
os.Remove(filepath.Join(path, name))
return nil
)
if err != nil
return nil, err
return &file_manager, nil
func (f *FileManager) getFile(file_name string) (*os.File, error)
path := filepath.Join(f.db_directory, file_name)
file, err := os.OpenFile(path, os.O_CREATE|os.O_RDWR, 0644)
if err != nil
return nil, err
f.open_files[path] = file
return file, nil
func (f *FileManager) Read(blk *BlockId, p *Page) (int, error)
f.mu.Lock()
defer f.mu.Unlock()
file, err := f.getFile(blk.FileName())
if err != nil
return 0, err
defer file.Close()
count, err := file.ReadAt(p.contents(), int64(blk.Number()*f.block_size))
if err != nil
return 0, err
return count, nil
func (f FileManager) Write(blk *BlockId, p *Page) (int, error)
f.mu.Lock()
defer f.mu.Unlock()
file, err := f.getFile(blk.FileName())
if err != nil
return 0, err
defer file.Close()
n, err := file.WriteAt(p.contents(), int64(blk.Number()*f.block_size))
if err != nil
return 0, err
return n, nil
func (f *FileManager) size(file_name string) (uint64, error)
file, err := f.getFile(file_name)
if err != nil
return 0, err
fi, err := file.Stat()
if err != nil
return 0, err
return uint64(fi.Size()) / f.block_size, nil
func (f *FileManager) Append(file_name string) (BlockId, error)
new_block_num, err := f.size(file_name)
if err != nil
return BlockId, err
blk := NewBlockId(file_name, new_block_num)
file, err := f.getFile(blk.FileName())
if err != nil
return BlockId, err
b := make([]byte, f.block_size)
_, err = file.WriteAt(b, int64(blk.Number()*f.block_size)) //读入空数据相当于扩大文件长度
if err != nil
return BlockId, nil
return *blk, nil
func (f *FileManager) IsNew() bool
return f.is_new
func (f *FileManager) BlockSize() uint64
return f.block_size
文件管理器在创建时会在给定路径创建一个文件夹,然后特定的二进制文件就会存储在该文件夹下,例如我们的数据库系统在创建一个表时,表的数据会对应到一个二进制文件,同时针对表的操作还会生成log等日志文件,这一系列文件就会生成在给定的目录下,file_manager类会利用前面实现的BlockId和Page类来管理二进制数据的读写,其实现如下:
package file_manager
import (
"os"
"path/filepath"
"strings"
"sync"
)
type FileManager struct
db_directory string
block_size uint64
is_new bool
open_files map[string]*os.File
mu sync.Mutex
func NewFileManager(db_directory string, block_size uint64) (*FileManager, error)
file_manager := FileManager
db_directory: db_directory,
block_size: block_size,
is_new: false,
open_files: make(map[string]*os.File),
if _, err := os.Stat(db_directory); os.IsNotExist(err)
//目录不存在则创建
file_manager.is_new = true
err = os.Mkdir(db_directory, os.ModeDir)
if err != nil
return nil, err
else
//目录存在,则先清楚目录下的临时文件
err := filepath.Walk(db_directory, func(path string, info os.FileInfo, err error) error
mode := info.Mode()
if mode.IsRegular()
name := info.Name()
if strings.HasPrefix(name, "temp")
//删除临时文件
os.Remove(filepath.Join(path, name))
return nil
)
if err != nil
return nil, err
return &file_manager, nil
func (f *FileManager) getFile(file_name string) (*os.File, error)
path := filepath.Join(f.db_directory, file_name)
file, err := os.OpenFile(path, os.O_CREATE|os.O_RDWR, 0644)
if err != nil
return nil, err
f.open_files[path] = file
return file, nil
func (f *FileManager) Read(blk *BlockId, p *Page) (int, error)
f.mu.Lock()
defer f.mu.Unlock()
file, err := f.getFile(blk.FileName())
if err != nil
return 0, err
defer file.Close()
count, err := file.ReadAt(p.contents(), int64(blk.Number()*f.block_size))
if err != nil
return 0, err
return count, nil
func (f FileManager) Write(blk *BlockId, p *Page) (int, error)
f.mu.Lock()
defer f.mu.Unlock()
file, err := f.getFile(blk.FileName())
if err != nil
return 0, err
defer file.Close()
n, err := file.WriteAt(p.contents(), int64(blk.Number()*f.block_size))
if err != nil
return 0, err
return n, nil
func (f *FileManager) size(file_name string) (uint64, error)
file, err := f.getFile(file_name)
if err != nil
return 0, err
fi, err := file.Stat()
if err != nil
return 0, err
return uint64(fi.Size()) / f.block_size, nil
func (f *FileManager) Append(file_name string) (BlockId, error)
new_block_num, err := f.size(file_name)
if err != nil
return BlockId, err
blk := NewBlockId(file_name, new_block_num)
file, err := f.getFile(blk.FileName())
if err != nil
return BlockId, err
b := make([]byte, f.block_size)
_, err = file.WriteAt(b, int64(blk.Number()*f.block_size)) //读入空数据相当于扩大文件长度
if err != nil
return BlockId, nil
return *blk, nil
func (f *FileManager) IsNew() bool
return f.is_new
func (f *FileManager) BlockSize() uint64
return f.block_size
由于我们要确保文件读写时要线程安全,因此它的write和read接口在调用时都先获取互斥锁,接下来我们看看它的测试用例由此来了解它的作用,创建file_manager_test.go,实现代码如下:
package file_manager
import (
"testing"
"github.com/stretchr/testify/require"
)
func TestFileManager(t *testing.T)
// require.Equal(t, 1, 2) //确保用例能执行
fm, _ := NewFileManager("file_test", 400)
blk := NewBlockId("testfile", 2)
p1 := NewPageBySize(fm.BlockSize())
pos1 := uint64(88)
s := "abcdefghijklm"
p1.SetString(pos1, s)
size := p1.MaxLengthForString(s)
pos2 := pos1 + size
val := uint64(345)
p1.SetInt(pos2, val)
fm.Write(blk, p1)
p2 := NewPageBySize(fm.BlockSize())
fm.Read(blk, p2)
require.Equal(t, val, p2.GetInt(pos2))
require.Equal(t, s, p2.GetString(pos1))
通过运行上面测试用例可以得知file_manager的基本用法。它的本质是为磁盘上创建对应目录,并数据库的表以及和表操作相关的log日志以二进制文件的方式存储在目录下,同时支持上层模块进行相应的读写操作,它更详细的作用在我们后续的开发中会展现出来。
代码在这里下载:https://github.com/wycl16514/data-system-file-mananger.git,更多详细内容请扫码:

以上是关于自己动手写个数据库系统:磁盘的基本原理和数据库底层文件系统实现的主要内容,如果未能解决你的问题,请参考以下文章