深度学习100例 | 第36天:FMD材料识别
Posted K同学啊
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深度学习100例 | 第36天:FMD材料识别相关的知识,希望对你有一定的参考价值。
- 🔗 运行环境:python3
- 🚩 作者:K同学啊
- 🥇 选自专栏:《深度学习100例》
- 🔥 精选专栏:《新手入门深度学习》
- 📚 推荐专栏:《Matplotlib教程》
- 🧿 优秀专栏:《Python入门100题》
大家好,我是K同学啊!
在100例系列之前文章中,我们对图像识别(图片分类)这类任务都是通过image_dataset_from_directory()方法直接采用默认的标签编码为整数的加载方式,这次我将采用标签编码为向量的形式(可参考one-hot编码)进行加载,大家注意查看代码与以往有何不同。即label_mode = "categorical"。与此同时,在评价指标metrics处增加了Precision、Recall、AUC等值,实现了训练模型的同时记录这些指标,更加便利后面的分析工作。
本次我们实现的是FMD材料识别,该数数据集包含塑料、金属、皮革、布料等十种物体的1000张图片,每种物体100张图片。最后的识别效果达到了100%。
🚀 我的环境:
- 语言环境:Python3.6.5
- 编译器:jupyter notebook
- 深度学习环境:TensorFlow2.4.1
- 显卡(GPU):NVIDIA GeForce RTX 3080
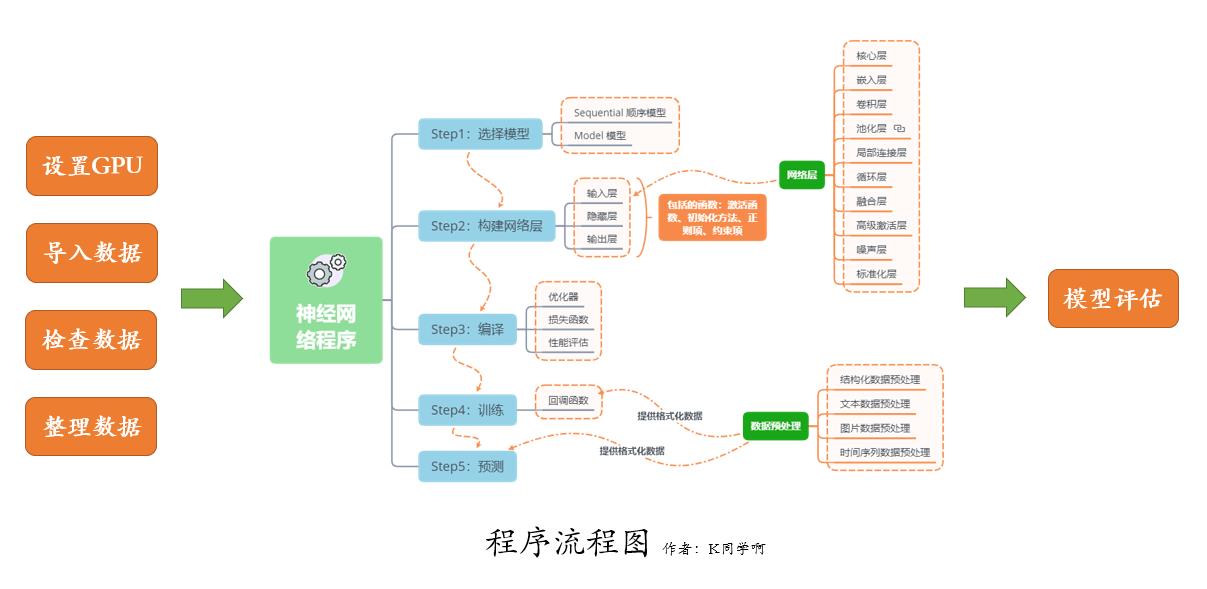
我们的代码流程图如下所示:
文章目录
一、准备数据
1. 设置GPU
import matplotlib.pyplot as plt
import numpy as np
#隐藏警告
import warnings
warnings.filterwarnings("ignore") #忽略警告信息
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
from tensorflow.keras import layers
import tensorflow as tf
gpus = tf.config.list_physical_devices("GPU")
if gpus:
tf.config.experimental.set_memory_growth(gpus[0], True) #设置GPU显存用量按需使用
tf.config.set_visible_devices([gpus[0]],"GPU")
# 打印显卡信息,确认GPU可用
print(gpus)
[PhysicalDevice(name='/physical_device:GPU:0', device_type='GPU')]
2. 加载数据
data_dir = "./FMD/image/"
img_height = 224
img_width = 224
batch_size = 32
"""
关于image_dataset_from_directory()的详细介绍可以参考文章:https://mtyjkh.blog.csdn.net/article/details/117018789
"""
train_ds = tf.keras.preprocessing.image_dataset_from_directory(
data_dir,
validation_split=0.3,
subset="training",
label_mode = "categorical",
seed=12,
image_size=(img_height, img_width),
batch_size=batch_size)
Found 1000 files belonging to 10 classes.
Using 700 files for training.
"""
关于image_dataset_from_directory()的详细介绍可以参考文章:https://mtyjkh.blog.csdn.net/article/details/117018789
"""
val_ds = tf.keras.preprocessing.image_dataset_from_directory(
data_dir,
validation_split=0.3,
subset="validation",
label_mode = "categorical",
seed=12,
image_size=(img_height, img_width),
batch_size=batch_size)
Found 1000 files belonging to 10 classes.
Using 700 files for training.
由于原始数据集不包含测试集,因此需要创建一个。使用 tf.data.experimental.cardinality 确定验证集中有多少批次的数据,然后将其中的 20% 移至测试集。
val_batches = tf.data.experimental.cardinality(val_ds)
test_ds = val_ds.take(val_batches // 5)
val_ds = val_ds.skip(val_batches // 5)
print('Number of validation batches: %d' % tf.data.experimental.cardinality(val_ds))
print('Number of test batches: %d' % tf.data.experimental.cardinality(test_ds))
Number of validation batches: 18
Number of test batches: 4
class_names = train_ds.class_names
print(class_names)
['fabric', 'foliage', 'glass', 'leather', 'metal', 'paper', 'plastic', 'stone', 'water', 'wood']
AUTOTUNE = tf.data.AUTOTUNE
def preprocess_image(image, label):
return (image/255.0, label)
# 归一化处理
train_ds = train_ds.map(preprocess_image, num_parallel_calls=AUTOTUNE)
val_ds = val_ds.map(preprocess_image, num_parallel_calls=AUTOTUNE)
test_ds = test_ds.map(preprocess_image, num_parallel_calls=AUTOTUNE)
train_ds = train_ds.cache().prefetch(buffer_size=AUTOTUNE)
val_ds = val_ds.cache().prefetch(buffer_size=AUTOTUNE)
plt.figure(figsize=(15, 10)) # 图形的宽为15高为10
plt.suptitle('关注微信公众号(K同学啊)获取源码')
for images, labels in train_ds.take(1):
for i in range(32):
ax = plt.subplot(5, 8, i + 1)
plt.imshow(images[i])
plt.title(class_names[np.argmax(labels[i])])
plt.axis("off")

二、构建模型
model = tf.keras.Sequential([
layers.Conv2D(16, 3, padding='same', activation='relu'),
layers.MaxPooling2D(),
layers.Conv2D(32, 3, padding='same', activation='relu'),
layers.MaxPooling2D(),
layers.Conv2D(64, 3, padding='same', activation='relu'),
layers.MaxPooling2D(),
layers.Conv2D(64, 3, padding='same', activation='relu'),
layers.MaxPooling2D(),
layers.Conv2D(64, 3, padding='same', activation='relu'),
layers.MaxPooling2D(),
layers.Flatten(),
layers.Dense(128, activation='relu'),
layers.Dense(len(class_names) ,activation='softmax')
])
在准备对模型进行训练之前,还需要再对其进行一些设置。
"""
关于评估指标的相关内容可以参考文章:https://mtyjkh.blog.csdn.net/article/details/123786871
"""
METRICS = [
tf.keras.metrics.TruePositives(name='tp'),
tf.keras.metrics.FalsePositives(name='fp'),
tf.keras.metrics.TrueNegatives(name='tn'),
tf.keras.metrics.FalseNegatives(name='fn'),
tf.keras.metrics.CategoricalAccuracy(name='accuracy'),
tf.keras.metrics.Precision(name='precision'),
tf.keras.metrics.Recall(name='recall'),
tf.keras.metrics.AUC(name='auc'),
tf.keras.metrics.AUC(name='prc', curve='PR'), # precision-recall curve
]
model.compile(optimizer="adam",
loss='categorical_crossentropy',
metrics=METRICS)
三、训练模型
epochs=50
history = model.fit(
train_ds,
validation_data=val_ds,
epochs=epochs
)
Epoch 1/50
22/22 [==============================] - 5s 62ms/step - loss: 2.3098 - tp: 0.0000e+00 - fp: 0.0000e+00 - tn: 6300.0000 - fn: 700.0000 - accuracy: 0.1014 - precision: 0.0000e+00 - recall: 0.0000e+00 - auc: 0.4956 - prc: 0.0981 - val_loss: 2.2927 - val_tp: 0.0000e+00 - val_fp: 0.0000e+00 - val_tn: 5148.0000 - val_fn: 572.0000 - val_accuracy: 0.1591 - val_precision: 0.0000e+00 - val_recall: 0.0000e+00 - val_auc: 0.5827 - val_prc: 0.1344
......
Epoch 49/50
22/22 [==============================] - 0s 18ms/step - loss: 2.3677e-04 - tp: 700.0000 - fp: 0.0000e+00 - tn: 6300.0000 - fn: 0.0000e+00 - accuracy: 1.0000 - precision: 1.0000 - recall: 1.0000 - auc: 1.0000 - prc: 1.0000 - val_loss: 2.2560e-04 - val_tp: 572.0000 - val_fp: 0.0000e+00 - val_tn: 5148.0000 - val_fn: 0.0000e+00 - val_accuracy: 1.0000 - val_precision: 1.0000 - val_recall: 1.0000 - val_auc: 1.0000 - val_prc: 1.0000
Epoch 50/50
22/22 [==============================] - 0s 18ms/step - loss: 2.2028e-04 - tp: 700.0000 - fp: 0.0000e+00 - tn: 6300.0000 - fn: 0.0000e+00 - accuracy: 1.0000 - precision: 1.0000 - recall: 1.0000 - auc: 1.0000 - prc: 1.0000 - val_loss: 2.1012e-04 - val_tp: 572.0000 - val_fp: 0.0000e+00 - val_tn: 5148.0000 - val_fn: 0.0000e+00 - val_accuracy: 1.0000 - val_precision: 1.0000 - val_recall: 1.0000 - val_auc: 1.0000 - val_prc: 1.0000
eva = model.evaluate(test_ds)
print("\\n模型的识别准确率为:", eva[5])
4/4 [==============================] - 0s 18ms/step - loss: 2.2280e-04 - tp: 128.0000 - fp: 0.0000e+00 - tn: 1152.0000 - fn: 0.0000e+00 - accuracy: 1.0000 - precision: 1.0000 - recall: 1.0000 - auc: 1.0000 - prc: 1.0000
模型的识别准确率为: 1.0
四、模型评估
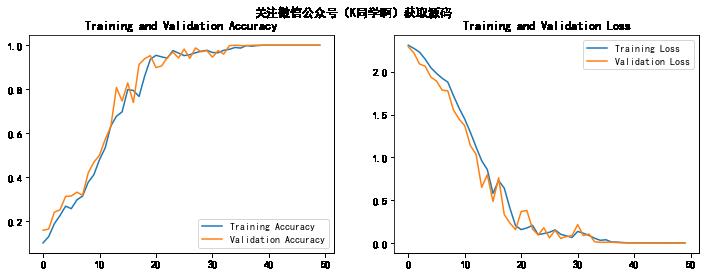
1. Accuracy与Loss图
"""
关于Matplotlib画图的内容可以参考我的专栏《Matplotlib实例教程》
专栏地址:https://blog.csdn.net/qq_38251616/category_11351625.html
"""
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs_range = range(epochs)
plt.figure(figsize=(12, 4))
plt.subplot(1, 2, 1)
plt.suptitle('关注微信公众号(K同学啊)获取源码')
plt.plot(epochs_range, acc, label='Training Accuracy')
plt.plot(epochs_range, val_acc, label='Validation Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.subplot(1, 2, 2)
plt.plot(epochs_range, loss, label='Training Loss')
plt.plot(epochs_range, val_loss, label='Validation Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()
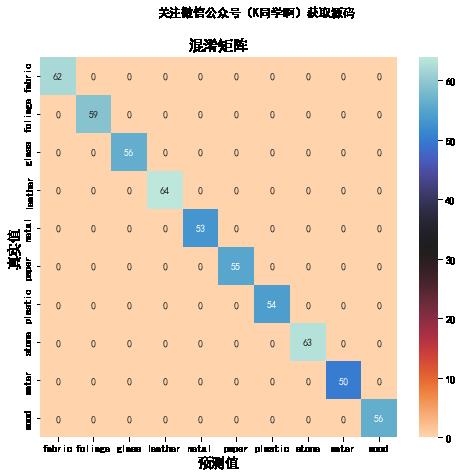
2. 混淆矩阵
from sklearn.metrics import confusion_matrix
import seaborn as sns
import pandas as pd
# 定义一个绘制混淆矩阵图的函数
def plot_cm(labels, predictions):
# 生成混淆矩阵
conf_numpy = confusion_matrix(labels, predictions)
# 将矩阵转化为 DataFrame
conf_df = pd.DataFrame(conf_numpy, index=class_names ,columns=class_names)
plt.figure(figsize=(8,7))
plt.suptitle('关注微信公众号(K同学啊)获取源码')
sns.heatmap(conf_df, annot=True, fmt="d", cmap="icefire_r")
plt.title('混淆矩阵',fontsize=15)
plt.ylabel('真实值',fontsize=14)
plt.xlabel('预测值',fontsize=14)
val_pre = []
val_label = []
for images, labels in val_ds:#这里可以取部分验证数据(.take(1))生成混淆矩阵
for image, label in zip(images, labels):
# 需要给图片增加一个维度
img_array = tf.expand_dims(image, 0)
# 使用模型预测图片中的人物
prediction = model.predict(img_array)
val_pre.append(np.argmax(prediction))
val_label.append([np.argmax(one_hot)for one_hot in [label]])
plot_cm(val_label, val_pre)
- 数据:📌【传送门】
最后再送大家一本,帮助大家拿到 BAT 等一线大厂 offer 的数据结构刷题笔记,是谷歌和阿里的大佬写的,对于算法薄弱或者需要提高的同学都十分受用(提取码:9go2 ):
以及我整理的7K+本开源电子书,总有一本可以帮到你 💖(提取码:4eg0)
以上是关于深度学习100例 | 第36天:FMD材料识别的主要内容,如果未能解决你的问题,请参考以下文章
深度学习100例 | 第24天-卷积神经网络(Xception):动物识别
深度学习100例-卷积神经网络(CNN)识别验证码 | 第12天
深度学习100例-卷积神经网络(CNN)猴痘病识别 | 第45天
深度学习100例-卷积神经网络(CNN)猴痘病识别 | 第45天