Java之有序集合&hashMap
Posted Huterox
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Java之有序集合&hashMap相关的知识,希望对你有一定的参考价值。
文章目录
前言
这个主要是说一下比较有意思的API,关于哈希集合方面的使用,这个主要是有时候在比赛的时候,直接拿过来用的话会方便很多。
TreeSet
这个呢是一个集合,首先说一下特点,这个玩意呢,首先他是一个集合,通过我们定义或者默认的hash函数,能够具备集合的数学性质。同样的,我们还可以设置一个比较器实现有序的存储。并且查找的时间复杂度大概在 logn ,还是相当不错的,在一些实在是想不到的题目里面合理地使用api可以事半功倍,就比如先前介绍的java大数问题是吧,当然使用这个的时候,不一定是最优解,不过抗住大部分的测试案例应该还是可以滴。
基础数据类型
这里的话要分两种使用方式,一个是基础数据类型的,一个是自己定义的复杂类型,或者使用的复杂类型的。对于基础数据类型我们直接add即可,对于复杂的,我们必须实现比较器。
public static void test1()
TreeSet<Integer> set = new TreeSet<>();
set.add(2);
set.add(1);
set.add(9);
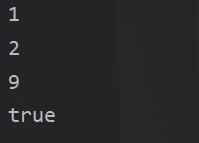
for (Integer integer : set)
System.out.println(integer);
System.out.println(set.contains(9));
可以看到添加是无序的,但是输出是有序的。
这个就是最基本的使用,但是这个显然还不够。
请看接下来的操作。
public static void test1()
TreeSet<Integer> set = new TreeSet<>();
set.add(2);
set.add(1);
set.add(9);
for (Integer integer : set)
System.out.println(integer);
System.out.println(set.contains(9));
System.out.println("最小的是:"+set.first());
System.out.println("最大的是:"+set.last());
System.out.println("删除最小的元素:"+set.pollFirst());
System.out.println("删除最大的元素:"+set.pollLast());
System.out.println("删除最下的元素后剩下");
for (Integer integer : set)
System.out.println(integer);
System.out.println("重新添加元素");
set.add(2);
set.add(1);
set.add(9);
for (Integer integer : set)
System.out.println(integer);
System.out.println("在集合当中<=7最近的元素是:"+set.floor(7));
System.out.println("在集合当中>=7最近的元素是:"+set.ceiling(7));
set.remove(1);
set.remove(9);
System.out.println("删除1,9之后剩下的元素");
for (Integer integer : set)
System.out.println(integer);
结果如下:

复杂数据类型
关于复杂数据类型的操作其实,咱们只需要实现一个比较器即可。
下面是我们定义的数据类型
class Node
public Node(int x, int y)
this.x = x;
this.y = y;
public int x=0;
public int y=0;
@Override
public String toString()
return "Node" +
"x=" + x +
", y=" + y +
'';
之后我们实现一个比较器
class NodeCompere implements Comparator<Node>
@Override
public int compare(Node o1, Node o2)
return (o1.x - o2.x);
之后使用
public static void test2()
TreeSet<Node> set = new TreeSet<>(new NodeCompere());
set.add(new Node(1,1));
set.add(new Node(3,1));
set.add(new Node(2,1));
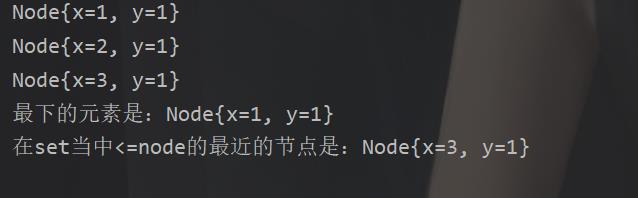
for (Node node : set)
System.out.println(node);
同样的:
public static void test2()
TreeSet<Node> set = new TreeSet<>(new NodeCompere());
set.add(new Node(1,1));
set.add(new Node(3,1));
set.add(new Node(2,1));
for (Node node : set)
System.out.println(node);
System.out.println("最下的元素是:"+set.first());
Node node = new Node(5, 1);
System.out.println("在set当中<=node的最近的节点是:"+set.floor(node));
这里的话比较的规则也确实是你定义的比较器
小技巧
除了上面的方式我们可以实现集合有序外,事实上我们还可以直接使用链表来实现set接口来实现有序的集合输出。
例如这道蓝桥杯的题目
试题 历届真题 修改数组【第十届】【省赛】【A组】
资源限制
时间限制:1.0s 内存限制:256.0MB
问题描述
给定一个长度为 N 的数组 A = [A₁, A₂, · · · AN],数组中有可能有重复出现的整数。
现在小明要按以下方法将其修改为没有重复整数的数组。小明会依次修改
A₂, A₃, · · · , AN。
当修改 Ai 时,小明会检查 Ai 是否在 A₁ ∼ Ai−₁ 中出现过。如果出现过,则小明会给 Ai 加上 1 ;如果新的 Ai 仍在之前出现过,小明会持续给 Ai 加 1 ,直到 Ai 没有在
A₁ ∼ Ai−₁ 中出现过。
当 AN 也经过上述修改之后,显然 A 数组中就没有重复的整数了。现在给定初始的 A 数组,请你计算出最终的 A 数组。
输入格式
第一行包含一个整数 N。
第二行包含 N 个整数 A₁, A₂, · · · , AN 。
输出格式
输出 N 个整数,依次是最终的 A₁, A₂, · · · , AN。
样例输入
5
2 1 1 3 4
样例输出
2 1 3 4 5
评测用例规模与约定
对于 80% 的评测用例,1 ≤ N ≤ 10000。
对于所有评测用例,1 ≤ N ≤ 100000,1 ≤ Ai ≤ 1000000。
我们可以直接这样
import java.util.*;
public class Main
public static void main(String[] args)
Set<Integer> integers = new LinkedHashSet<>();
Scanner scanner = new Scanner(System.in);
int length = scanner.nextInt();
for(int i=0;i<length;i++)
int value = scanner.nextInt();
while (integers.contains(value))
value++;
integers.add(value);
Iterator<Integer> iterator = integers.iterator();
while (iterator.hasNext())
System.out.print(iterator.next()+" ");
当然这种方式并不能很好地通过数据集,只能拿到80分。不过有时候,没必要苛求完美,竞赛注意的还是效率和分值。没必要为了20的提升丢掉大分。
TreeMap
这个也同样重要,有时候,我们的往往会带有键值对去比较。当然这里其实也是完全可以通过复合数据类型,来代替 key - value的形式,不过这里也同样说一下。
这样的好处其实是在刚刚的例子里面,我们是通过 Node 的 x 来做比较的。实际上你可以选择直接把 x 当中key,其余部分变为value。
同样的这里也分对于基础类型和复合类型的操作,并且我们这里的比较主要是正对key的比较。
基础类型
这个基础类型与那个TreeSet类似,就不说了。
这里咱们主要说说复合类型。
复合类型
public static void test3()
TreeMap<Node,Integer> map = new TreeMap<>(new NodeCompere());
map.put(new Node(1,1),1);
map.put(new Node(3,1),2);
map.put(new Node(2,1),3);
Node node = new Node(5, 1);
System.out.println("在map当中<=node的最近的节点的key是:"+map.floorKey(node));
System.out.println("在map当中>=node的最近的节点的key是:"+map.ceilingKey(node));

你其实可以发现,我们用法其实完全是和TreeSet类似的,只不过我们在对应的方法后面加上了 key 这个后缀。
演示代码(完整)
OK,以上就是全部。底层实现那必然是红黑树,平衡树。
import java.util.Comparator;
import java.util.TreeMap;
import java.util.TreeSet;
public class TreeMapTest
public static void main(String[] args)
test3();
public static void test1()
TreeSet<Integer> set = new TreeSet<>();
set.add(2);
set.add(1);
set.add(9);
for (Integer integer : set)
System.out.println(integer);
System.out.println(set.contains(9));
System.out.println("最小的是:"+set.first());
System.out.println("最大的是:"+set.last());
System.out.println("删除最小的元素:"+set.pollFirst());
System.out.println("删除最大的元素:"+set.pollLast());
System.out.println("删除最下的元素后剩下");
for (Integer integer : set)
System.out.println(integer);
System.out.println("重新添加元素");
set.add(2);
set.add(1);
set.add(9);
for (Integer integer : set)
System.out.println(integer);
System.out.println("在集合当中<=7最近的元素是:"+set.floor(7));
System.out.println("在集合当中>=7最近的元素是:"+set.ceiling(7));
set.remove(1);
set.remove(9);
System.out.println("删除1,9之后剩下的元素");
for (Integer integer : set)
System.out.println(integer);
public static void test2()
TreeSet<Node> set = new TreeSet<>(new NodeCompere());
set.add(new Node(1,1));
set.add(new Node(3,1));
set.add(new Node(2,1));
for (Node node : set)
System.out.println(node);
System.out.println("最下的元素是:"+set.first());
Node node = new Node(5, 1);
System.out.println("在set当中<=node的最近的节点是:"+set.floor(node));
public static void test3()
TreeMap<Node,Integer> map = new TreeMap<>(new NodeCompere());
map.put(new Node(1,1),1);
map.put(new Node(3,1),2);
map.put(new Node(2,1),3);
Node node = new Node(5, 1);
System.out.println("在map当中<=node的最近的节点的key是:"+map.floorKey(node));
System.out.println("在map当中>=node的最近的节点的key是:"+map.ceilingKey(node));
class Node
public Node(int x, int y)
this.x = x;
this.y = y;
public int x=0;
public int y=0;
@Override
public String toString()
return "Node" +
"x=" + x +
", y=" + y +
'';
class NodeCompere implements Comparator<Node>
@Override
public int compare(Node o1,以上是关于Java之有序集合&hashMap的主要内容,如果未能解决你的问题,请参考以下文章