从HDFS的写入和读取中,我发现了点东西
Posted 华为云开发者社区
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了从HDFS的写入和读取中,我发现了点东西相关的知识,希望对你有一定的参考价值。
本文分享自华为云社区《从HDFS的写入和读取中,我们能学习到什么》,作者: breakDawn 。
最近开发过程涉及了一些和文件读取有关的问题,于是对hdfs的读取机制感到兴趣,顺便深入学习了1下。
写入
- 客户端向NameNode发出写文件请求,告诉需要写的文件名和路径、用户
- NameNode检查是否已存在文件、检查权限。如果通过,会返回一个输出流对象
- 注意此时会按照“日志先行“原则,写入NameNode的editLog
- 客户端按照128MB的大小切分文件。 也就是block大小
- 客户端把nameNode传来的DataNode列表和Data数据一同发送给 最近的第一个DataNode节点。
- 第一个dataNode节点收到数据和DataNode列表时, 会先根据列表,找到下一个自己要连接的最近DataNode, 删除自己后,再一样往下发。以此类推,发完3台或者N台。
- 传输单位是packet,包,比block小一点。
- dataNode每写完一个block块, 则返回ACK信息给上一个节点进行确认。(注意是写完block才确认)
- 写完数据, 关闭输出流, 发送完成信息给DataNode
写过程的核心总结:
- 客户端只向一个dataNode写数据,然后下一个dataNode接着往另一个dataNode写,串联起来。
- 按128MB分block。 每次传数据按pack传。 校验按照chunk 校验,每次chunk都会写入pack。
- 写完block才发ACK确认。
Q: NameNode的editlog有什么用?怎么起作用的?
A:
作用:
- 硬盘中需要有一份元数据的镜像——FSImage
- 每次要修改元数据就信息时,必须得改文件(hdfs没有数据库)
- 可能会比较久,改的时候如果断电了,就丢失这个操作了
为了避免丢失,引入editlog,每次修改元数据前,先追加方式写入editlog, 然后再处理,这样即使断电了也能修复。
一般都是那些更改操作有断开风险,为了确保能恢复,都会引入这类操作。
Q: 什么时候发送完成信号? 全部节点都写入完成吗
A:
发送完成信号的时机取决于集群是强一致性还是最终一致性,强一致性则需要所有DataNode写完后才向NameNode汇报。最终一致性则其中任意一个DataNode写完后就能单独向NameNode汇报,HDFS一般情况下都是强调强一致性
Q: 怎么验证写入时的数据完整性?
A:
-
因为每个chunk中都有一个校验位,一个个chunk构成packet,一个个packet最终形成block,故可在block上求校验和。
-
当客户端创建一个新的HDFS文件时候,分块后会计算这个文件每个数据块的校验和,此校验和会以一个隐藏文件形式保存在同一个 HDFS 命名空间下。就是.meta文件
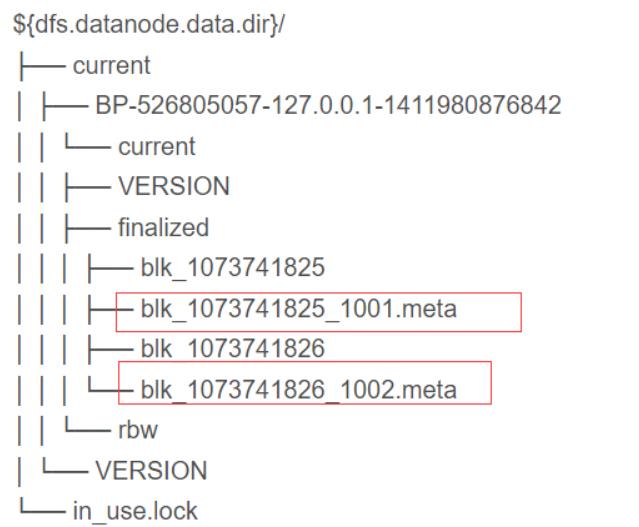
-
当client端从HDFS中读取文件内容后,它会检查分块时候计算出的校验和(隐藏文件里)和读取到的文件块中校验和是否匹配,如果不匹配,客户端可以选择从其他 Datanode 获取该数据块的副本。
Q: 写入时怎么确定最近节点?
A:
按照按照hadoop时设置的机架、数据中心、节点来估算
假设有数据中心d1机架r1中的节点n1。该节点可以表示为/d1/r1/n1。利用这种标记,这里给出四种距离描述。
- Distance(/d1/r1/n1, /d1/r1/n1)=0(同一节点上的进程)
- Distance(/d1/r1/n1, /d1/r1/n2)=2(同一机架上的不同节点)
- Distance(/d1/r1/n1, /d1/r3/n2)=4(同一数据中心不同机架上的节点)
- Distance(/d1/r1/n1, /d2/r4/n2)=6(不同数据中心的节点)
读取
读取就比较简单了,没有那种复杂的串行过程。NameNode直接告诉客户端去哪读就行了。
- client访问NameNode,查询元数据信息,获得这个文件的数据块位置列表,返回输入流对象。
- 就近挑选一台datanode服务器,请求建立输入流 。
- DataNode向输入流中中写数据,以packet为单位来校验。
- 关闭输入流
以上是关于从HDFS的写入和读取中,我发现了点东西的主要内容,如果未能解决你的问题,请参考以下文章