实验三 初步掌握Spark程序设计
Posted UserOrz
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了实验三 初步掌握Spark程序设计相关的知识,希望对你有一定的参考价值。
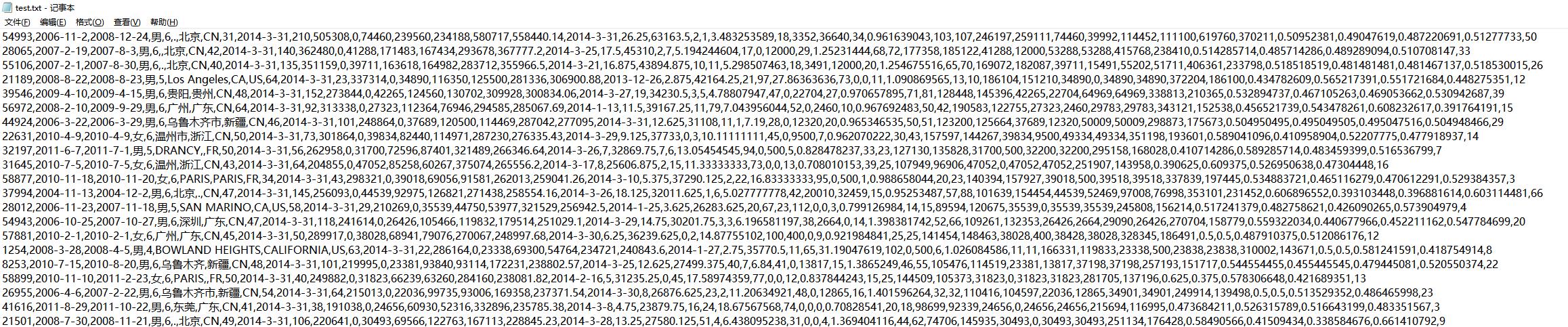
1. 统计文本中性别为“男”的用户数。
文件格式如图
package com.spark.homework.initSpark
import org.apache.spark.SparkConf, SparkContext
import org.apache.spark.rdd.RDD
object count_male
def main(args: Array[String]): Unit =
// TODO 建立和Spark框架的连接
val sparkConf = new SparkConf().setAppName("test").setMaster("local[*]")
val sc = new SparkContext(sparkConf)
// TODO 执行业务操作1
//1、读取文件
val value: RDD[String] = sc.textFile("..\\\\data\\\\test.txt")
//2、提取出包含男的行
val rdd = value.filter(x => x.contains("男"))
//3、统计数量
println(rdd.count())
// TODO 关闭连接
sc.stop();
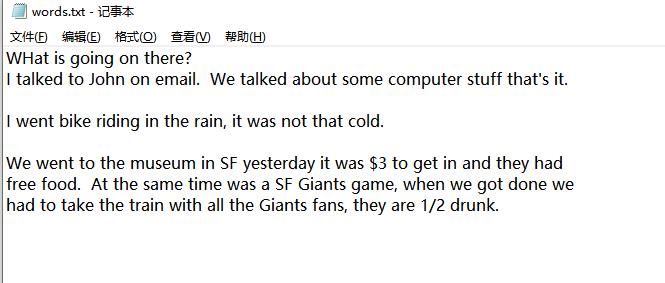
2、单词计数,将单词数超过3的结果存储到文件
文件内容
package com.spark.homework.initSpark
import org.apache.spark.SparkConf, SparkContext
import org.apache.spark.rdd.RDD
object WordCount
def main(args: Array[String]): Unit =
// TODO 建立和Spark框架的连接
val sparkConf = new SparkConf().setAppName("WordCount").setMaster("local[*]")
val sc = new SparkContext(sparkConf)
// TODO 执行业务操作1
//1、读取文件
val value: RDD[String] = sc.textFile("..\\\\data\\\\words.txt")
//2、切分单词
val words = value.flatMap(x => x.split(Array[Char](',',' ','?','.')))
//3、合并单词
var word = words.map(x => (x, 1)).reduceByKey(_+_)
//4、过滤数量大于3
word = word.filter(x => x._2 > 3 && x._1 != "")
//查看
word.collect().foreach(x => println(x))
//存储
word.repartition(1).saveAsTextFile("/file")
// TODO 关闭连接
sc.stop();
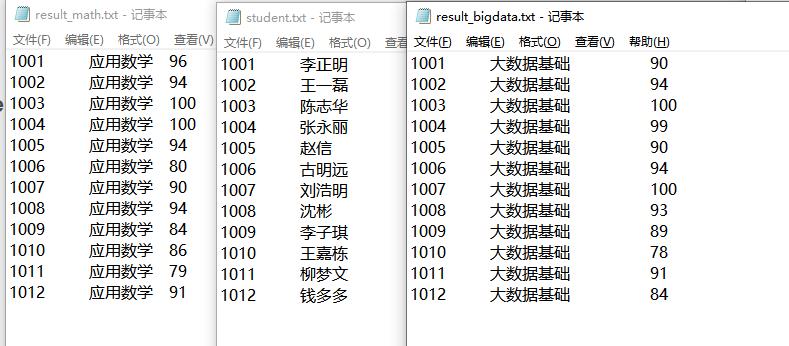
3、不使用combineByKey算子,计算学生成绩平均值。
分为三个文件
package com.spark.homework.initSpark
import org.apache.spark.SparkConf, SparkContext
import org.apache.spark.rdd.RDD
import scala.math.Ordering.String
object AvgStu
def main(args: Array[String]): Unit =
// TODO 建立和Spark框架的连接
val sparkConf = new SparkConf().setAppName("WordCount").setMaster("local[*]")
val sc = new SparkContext(sparkConf)
// TODO 执行业务操作1
//1、读取文件
var student: RDD[String] = sc.textFile("..\\\\data\\\\student.txt")
var math: RDD[String] = sc.textFile("..\\\\data\\\\result_math.txt")
var bigdata: RDD[String] = sc.textFile("..\\\\data\\\\result_bigdata.txt")
//2、切分
val stu = student.map(x => x.split("\\t")).map(x => (x(0),x(1)))
val math_grade = math.map(x => x.split("\\t")).map(x => (x(0), x(2)))
val bigdata_grade = bigdata.map(x => x.split("\\t")).map(x => (x(0), x(2)))
//3、合并
val rdd = stu.leftOuterJoin(math_grade).leftOuterJoin(bigdata_grade).map(x => (x._1,x._2._1._1,x._2._1._2,x._2._2))
//4、计算
val ans = rdd.map(x => (x._1, x._2, (x._3.get.toInt + x._4.get.toInt) / 2))
ans.collect().foreach(x => println(x))
// TODO 关闭连接
sc.stop();
输出

以上是关于实验三 初步掌握Spark程序设计的主要内容,如果未能解决你的问题,请参考以下文章
20182309 2019-2020-1 《数据结构与面向对象程序设计》实验三报告