:高阶分类-核方法与SVM
Posted xiaopihaierletian
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了:高阶分类-核方法与SVM相关的知识,希望对你有一定的参考价值。
分类
这一章讲高阶分类,自然我们还学过其他一些分类器,无论是高阶还是低阶的,它们是:
- 决策树
- 贝叶斯分类器
- 神经网络(作为分类器的使用是第六章课后题的一个要求)。
- 线性分类器
- 核方法和支持向量机(SVMs)
例子
本章使用一个小小的例子,用于分析得出,各种分类器优势和弱势。因此,我们要明白:将一个复杂的数据集扔给算法,然后希望算法直接产生精确的分类,这是不可能的。我们必须学会:
- 选择正确的算法
- 对数据集进行适当的预处理
例子描述
本章还是使用一个实际的例子来进行对比分类算法和学习新算法。这个实际的例子是,给一男一女配对,看他们是否能否成为情侣,有点像婚姻介绍所。这个婚姻介绍所,收集了很单身男女的信息,然后我们用算法来算出这某一对是否可能成为情侣。作为一个例子,我们收集的信息略显简短,但是非常适用。针对每一个人,我们收集:
- 年龄
- 是否吸烟
- 是否要孩子
- 兴趣列表
- 家庭住址
那我们怎么知道哪两个人适合成为情侣呢?也许我们用人的思维来看就我们想把不吸烟的男的和女的介绍到一起。但是我们在利用机器学习的原理来判断两人是否适合成为情侣的时候,使用了训练集来训练我们的算法,也就说,这是一个监督类算法。书中为我们提供了训练集,我们可以把这个训练集看成是历史悠久的婚姻介绍所过往的记录。书中用csv格式为我们提高了500条数据,文件名:matchmaker.csv,我们来看其中一条:
39 yes no skiing:knitting:dancing220 W 42nd St New York NY43noyessoccer:reading:scrabble824 3rd Ave New York NY0
请注意,这只是一行。也许排版问题,过长会导致换行,但是这在matchmaker.csv文件中是一行的。一行数据的排列方式是:
- 男的信息开始:年龄/是否吸烟/是否要孩子/兴趣列表/家庭住址
- 接着女的信息:年龄/是否吸烟/是否要孩子/兴趣列表/家庭住址
- 最后一个0表示没有配对成功。如果配对成功用1来表示。

只有男的年龄和女的年龄,以及是否配对成功。
数据我们有了,我们做的就是利用这个数据集,使用合适的算法,为新来的用户找出和他配对的对象。
加载数据
首先当然是把数据读入内存,书中的做法很奇怪,居然还是写了一个类:[python] view plain copy
- class matchrow:
- def __init__(self,row,allnum=False):
- if allnum:
- self.data=[float(row[i]) for i in range(len(row)-1)]
- else:
- self.data=row[0:len(row)-1]
- self.match=int(row[len(row)-1])#match表示是否配对成功的1或者0
- #allnum参数表示是只加载年龄还是加载全部数据
- def loadmatch(f,allnum=False):
- rows=[]
- for line in file(f):
- rows.append(matchrow(line.split(','),allnum))
- return rows
图形展示数据
如果还是一列一列的观察就没有意义了。我们首先要使用图形的方式来展示一下数据,进而分析,对于年龄,我们用男性的年龄到x轴,女性的年龄到y轴,让我们来看看实现的代码:[python] view plain copy
- from pylab import *
- def plotagematches(rows):
- #读出配对成功的x坐标和y坐标
- xdm,ydm=[r.data[0] for r in rows if r.match==1],[r.data[1] for r in rows if r.match==1]
- #读出不配对成功的x坐标和y坐标
- xdn,ydn=[r.data[0] for r in rows if r.match==0],[r.data[1] for r in rows if r.match==0]
- #画绿点
- plot(xdm,ydm,'go')
- #画红点
- plot(xdn,ydn,'ro')
- show()
[python] view plain copy
- a=loadmatch('agesonly.csv')
- plotagematches(a)
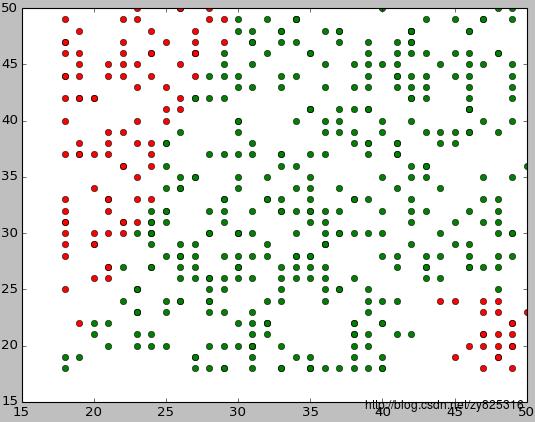
对面这个散布图进行分析。我们就会发现两点:
- 配对成功的年龄都比较接近,年龄相差越大,越不易配对成功
- 年龄越大,年龄的相差尽管大,配对成功的还是比较多的。
利用决策树进行分类
在我们第7章例子中,决策树是依据数据边界值来对数据进行划分的,比如浏览网页的次数,大于多少次和小于多少次。如果我们使用这样的方式对年龄来进行分类呢?如下图所示:
很显然,结果是糟糕的。因为,成不成对关键是看差距,不能简单的认为男的大于多少,女的小于多少就容易成对。如果从图像的角度来看,就是这样的:

决策树做的分类就在图中画了一条垂直线或者是水平线,但是最后水平线的上线或者垂直线的左右,都混杂了两种分类。所以,决策是不成功的。
所以,有两点非常重要:- 数据含义不清楚之前,不要轻易使用,而散布图有利于我们分析数据
- 对于多个数值的输入,并且输入之间还存在关系的,适合用决策树。所以,我们隆重推荐基本的线性分类
基本的线性分类
虽然简单,但是是基础。
原理
寻找每个分类所有数据的平均值,构造一个代表该分类中心位置的点。对一个新数据,看其对哪个分类更近就知道其的分类了。对于本实验来说来说,我们所谓的分类就是两种,就是配对的1和不配对的2。
代码:
[python] view plain copy
- def lineartrain(rows):
- averages=
- counts=
- for row in rows:
- #得到该坐标点所属的分类
- c1=row.match
- #下面两句应该只有第一次出现的时候才会有用把
- averages.setdefault(c1,[0.0]*(len(row.data)))
- counts.setdefault(c1,0)
- #将该坐标点加入averages中
- for i in range(len(row.data)):
- averages[c1][i]+=float(row.data[i])
- #记录该分类有多少个坐标点
- counts[c1]+=1
- #将总和除以计数值以求得平均值
- for c1,avg in averages.items():
- for i in range(len(avg)):
- avg[i]/=counts[c1]
- return averages
- 执行代码:
- agesonly=loadmatch('agesonly.csv')
- print lineartrain(agesonly)
[python] view plain copy
- >>>
- 0: [26.914529914529915, 35.888888888888886], 1: [35.48041775456919, 33.01566579634465]
- >>>

其中X点就计算出来的均指点,而且还有一条划分数据的直线,处于两个X点的中间位置。因此,所有在直接左侧的坐标点都表示不想匹配,而右侧的坐标点更接近于相匹配。
给新数据分类
对一个新数据,那么我们就将其作为新点,判断其接近于哪个分类点。两点之间的距离的算法可以用欧几里得来计算。但是书中要求使用向量、点积的方式来计算。
点积又称数据积&
以上是关于:高阶分类-核方法与SVM的主要内容,如果未能解决你的问题,请参考以下文章