PyTorch学习笔记:PyTorch进阶训练技巧
Posted GoAI
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了PyTorch学习笔记:PyTorch进阶训练技巧相关的知识,希望对你有一定的参考价值。
PyTorch实战:PyTorch进阶训练技巧
往期学习资料推荐:
本系列目录:
后续继续更新!!!!
Task05 PyTorch进阶训练技巧
import torch
import torch.nn as nn
import torch.nn.functional as F1 自定义损失函数
-
以函数方式定义:通过输出值和目标值进行计算,返回损失值
-
以类方式定义:通过继承
nn.Module,将其当做神经网络的一层来看待
以DiceLoss损失函数为例,定义如下:
DSC = \\frac2|X∩Y||X|+|Y|DSC=∣X∣+∣Y∣2∣X∩Y∣class DiceLoss(nn.Module):
def __init__(self, weight=None, size_average=True):
super(DiceLoss,self).__init__()
def forward(self, inputs, targets, smooth=1):
inputs = F.sigmoid(inputs)
inputs = inputs.view(-1)
targets = targets.view(-1)
intersection = (inputs * targets).sum()
dice = (2.*intersection + smooth)/(inputs.sum() + targets.sum() + smooth)
return 1 - dice2 动态调整学习率
-
Scheduler:学习率衰减策略,解决学习率选择的问题,用于提高精度
-
PyTorch Scheduler策略:
-
使用说明:需要将
scheduler.step()放在optimizer.step()后面 -
自定义Scheduler:通过自定义函数对学习率进行修改
3 模型微调
-
概念:找到一个同类已训练好的模型,调整模型参数,使用数据进行训练。
-
模型微调的流程
- 在源数据集上预训练一个神经网络模型,即源模型
- 创建一个新的神经网络模型,即目标模型,该模型复制了源模型上除输出层外的所有模型设计和参数
- 给目标模型添加一个输出大小为目标数据集类别个数的输出层,并随机初始化改成的模型参数
- 使用目标数据集训练目标模型
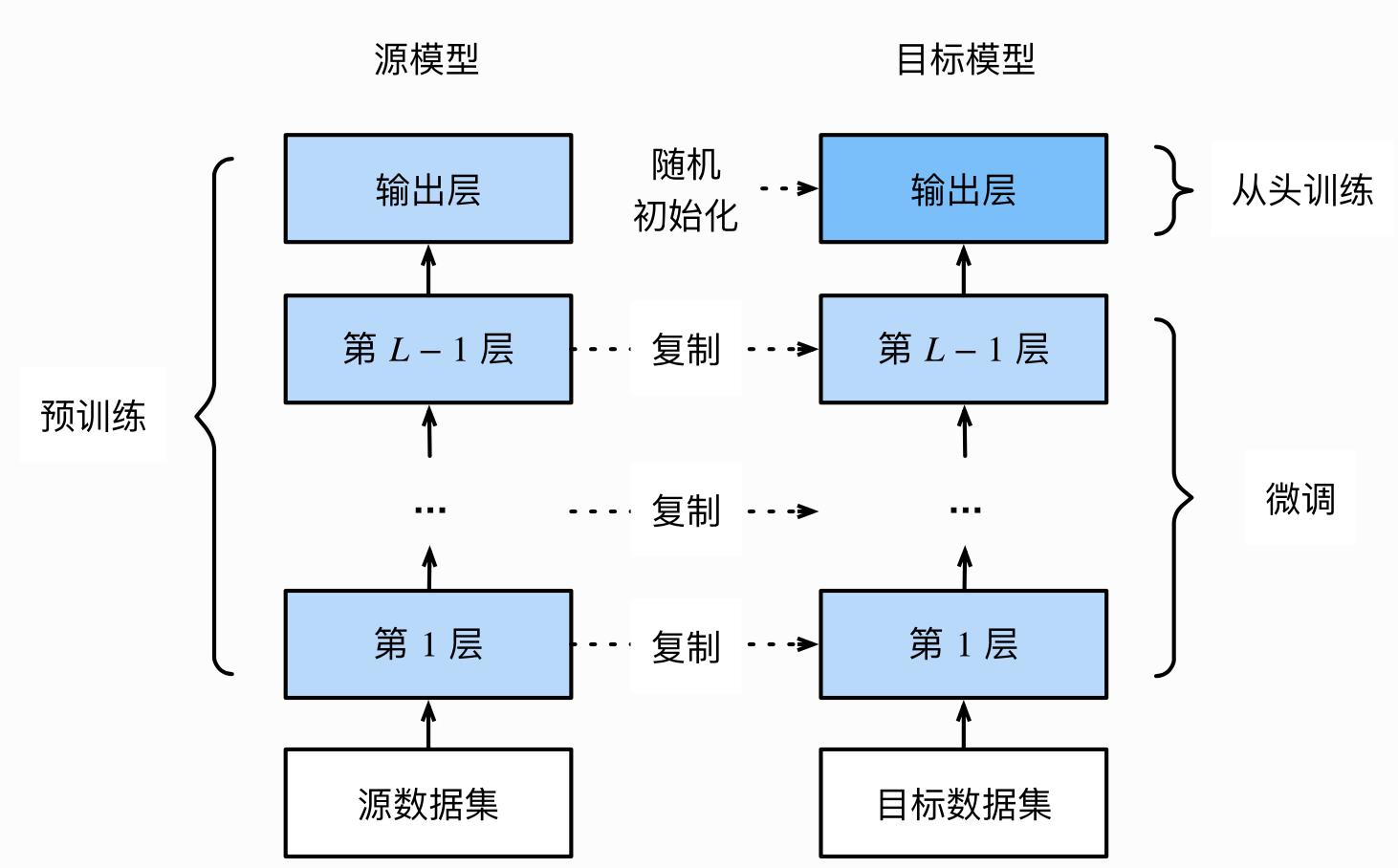
-
使用已有模型结构:通过传入
pretrained参数,决定是否使用预训练好的权重 -
训练特定层:使用
requires_grad=False冻结部分网络层,只计算新初始化的层的梯度def set_parameter_requires_grad(model, feature_extracting): if feature_extracting: for param in model.parameters(): param.requires_grad = False import torchvision.models as models # 冻结参数的梯度 feature_extract = True model = models.resnet50(pretrained=True) set_parameter_requires_grad(model, feature_extract) # 修改模型 num_ftrs = model.fc.in_features model.fc = nn.Linear(in_features=512, out_features=4, bias=True) model.fc Linear(in_features=512, out_features=4, bias=True)注:在训练过程中,model仍会回传梯度,但是参数更新只会发生在
fc层。
4 半精度训练
-
半精度优势:减少显存占用,提高GPU同时加载的数据量
-
设置半精度训练:
- 导入
torch.cuda.amp的autocast包 - 在模型定义中的
forward函数上,设置autocast装饰器 - 在训练过程中,在数据输入模型之后,添加
with autocast()
- 导入
-
适用范围:适用于数据的size较大的数据集(比如3D图像、视频等)
5 总结
- 自定义损失函数可以通过二种方式:函数方式和类方式,建议全程使用PyTorch提供的张量计算方法。
- 通过使用PyTorch中的scheduler动态调整学习率,也支持自定义scheduler
- 模型微调主要使用已有的预训练模型,调整其中的参数构建目标模型,在目标数据集上训练模型。
- 半精度训练主要适用于数据的size较大的数据集(比如3D图像、视频等)。
以上是关于PyTorch学习笔记:PyTorch进阶训练技巧的主要内容,如果未能解决你的问题,请参考以下文章