python爬虫从0到1 - Scrapy框架的实战应用
Posted 苏凉.py
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python爬虫从0到1 - Scrapy框架的实战应用相关的知识,希望对你有一定的参考价值。
文章目录
前言
在上文中我们学习了Scrapy框架的介绍,以及如何在scrapy框架中创建项目和创建/运行爬虫文件,那么接下来我们一起进入scrapy的实战应用吧!!
(一)yield介绍
- 带有yield的函数不再是一个普通函数,而是生成器generator,可用于迭代。
- yield是一个类似于return的关键字,迭代一次遇到yield时就返回yield后面的值。注:下一次迭代时,从上一次迭代遇到的yield后面的代码(下一行)执行。
- 简要理解:yield就是一个return返回的一个值,并且记住这个返回的位置,下次迭代就从这个位置后开始。
(二)管道封装
1 .创建项目和爬虫文件
首先我们根据上篇文章的方法创建项目以及爬虫文件
- 创建项目
scrapy startproject dangdang
- 创建爬虫文件
scrapy genspider dangtushu url
2.查找数据
通过xpath语法在网页中提取我们想要的数据(书名,图片,价格)
- 查找图片
src_list = response.xpath("//div[@class='cover']//a/img/@src")
- 查找书名
name_list = response.xpath("//div[@class='tushu']//a/text()")
- 查找价格
price_list = response.xpath("//div[@class='goumai']//span/span[@class='redC30']/text()")
- 输出内容
for i in range(len(name_list)):
src = src_list[i].extract()
name = name_list[i].extract()
price = price_list[i].extract()
3.定义数据
当我们使用Scrapy框架下载数据时,我们需先在items.py文件中说明我们要下载的数据。
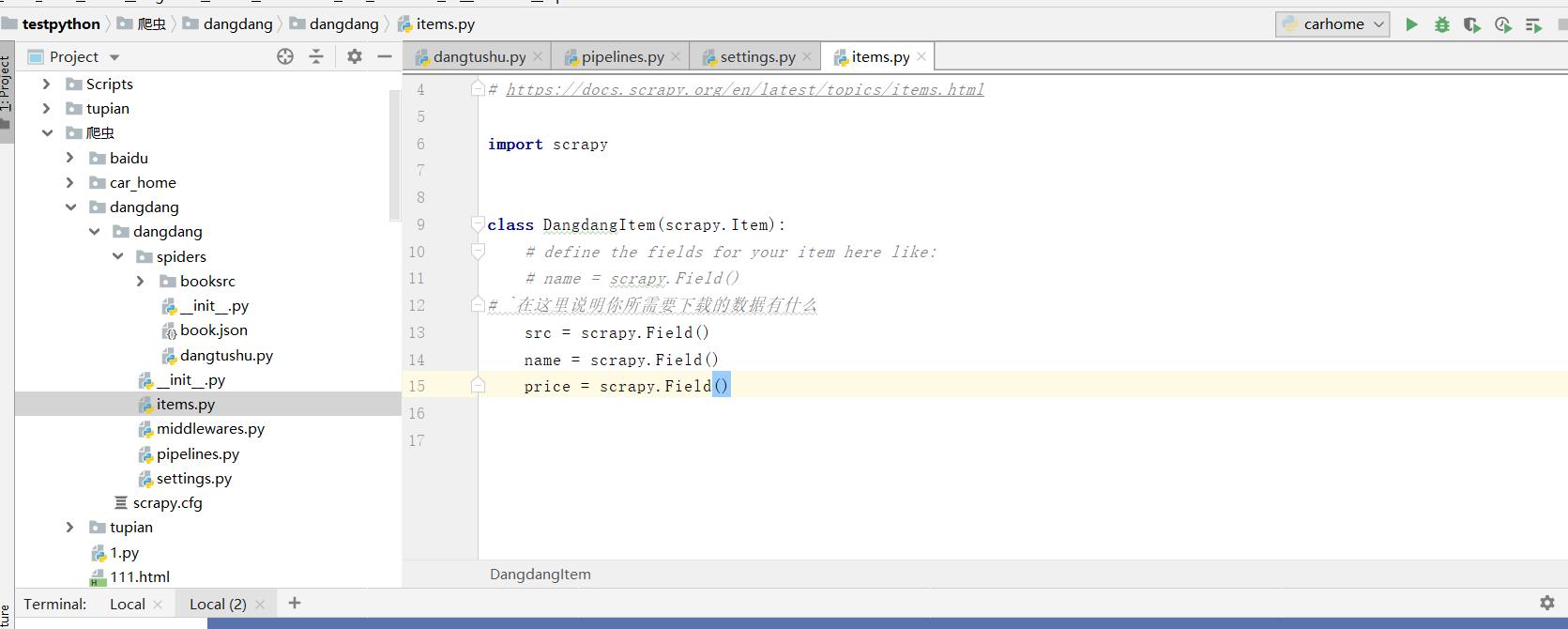
src = scrapy.Field()
name = scrapy.Field()
price = scrapy.Field()
4.将数据传入管道(pipelines)
- 将items.py 文件中的类导入到爬虫文件中
from dangdang.items import DangdangItem
- 将数据出传入管道下载
book =DangdangItem(src = src , name =name ,price = price)
# 将book的值传给pipelines
yield book
5.通过管道下载数据
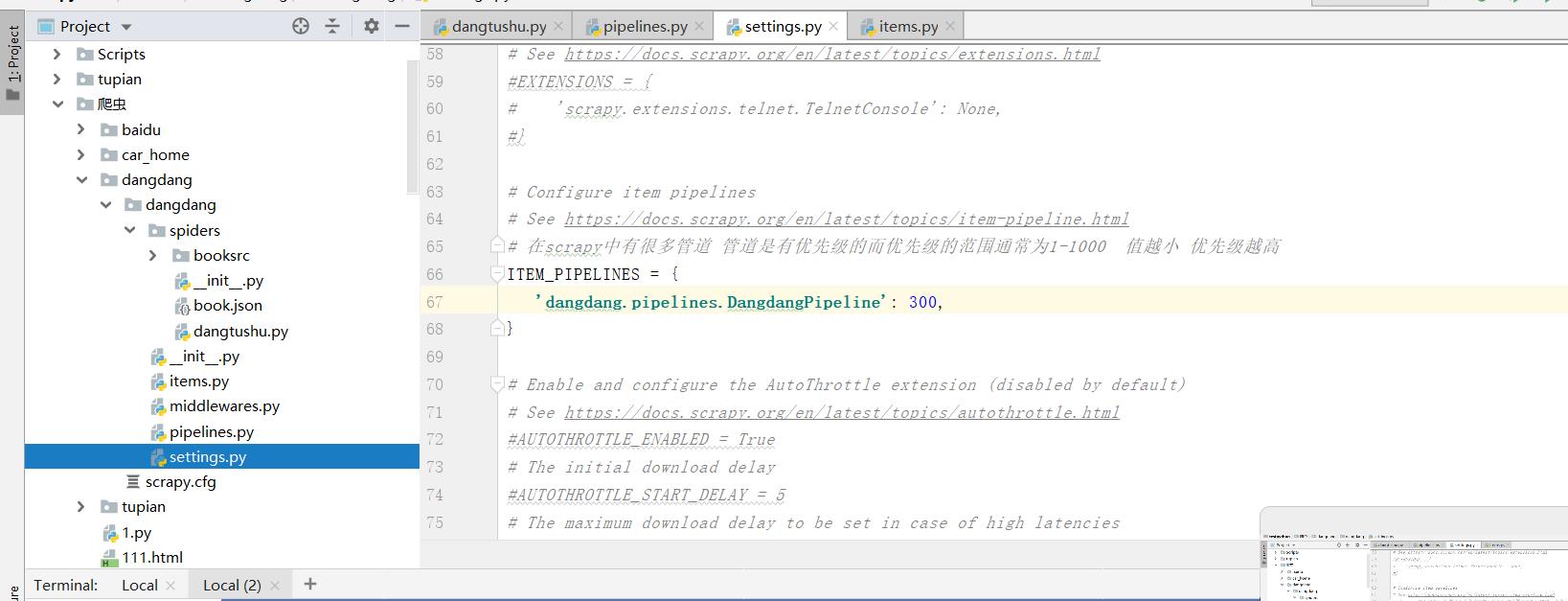
- 开启管道
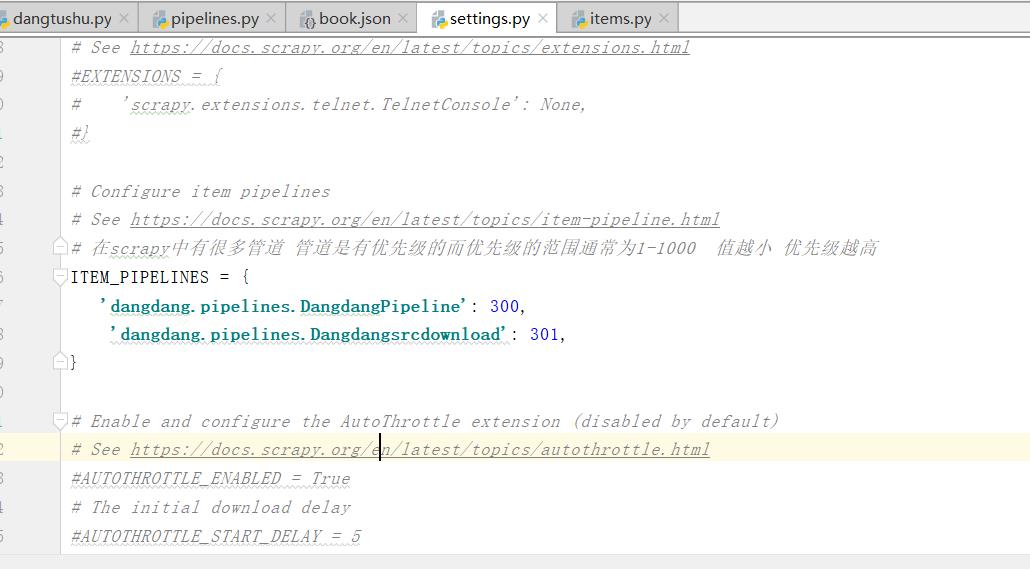
在我们使管道下载数据之前,需要在settings.py文件中手动打开管道(将其注释打开)。
注:在scrapy中有很多管道 管道是有优先级的而优先级的范围通常为1-1000 值越小 优先级越高
- 下载数据
2.1.with open方法
注:这种方法有局限性:每传递一次对象就要打开一次文件,对于文件的额操作频繁,不推荐使用
#open方法中 w模式会对每一个对象打开一次并且覆盖上一个对象,因此需要用a模式(追加)
with open('tushu.json','a',encoding='utf-8')as fp:
# write 方法必须要写一个字符串,而不能为一个对象
fp.write(str(item))
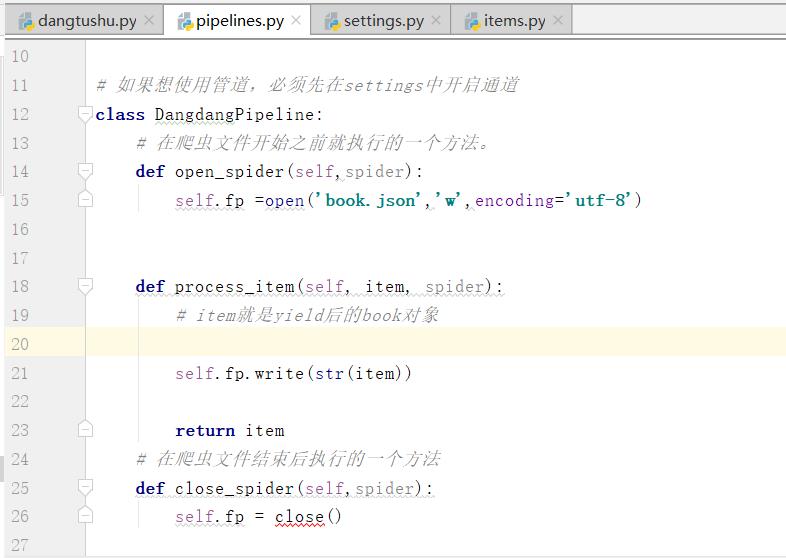
2.2.定义函数的方法
在爬虫文件开始之前就执行的一个方法。
def open_spider(self,spider):
self.fp =open('book.json','w',encoding='utf-8')
self.fp.write(str(item))
在爬虫文件结束后执行的一个方法
def close_spider(self,spider):
self.fp = close()
在控制台输入scrapy crawl dangtushu 执行爬虫文件就可以下载数据啦!!
(三)多条管道下载
在上述下载了json数据,我们还需要下载图片到本地,因此我们需要再开启另一条管道。
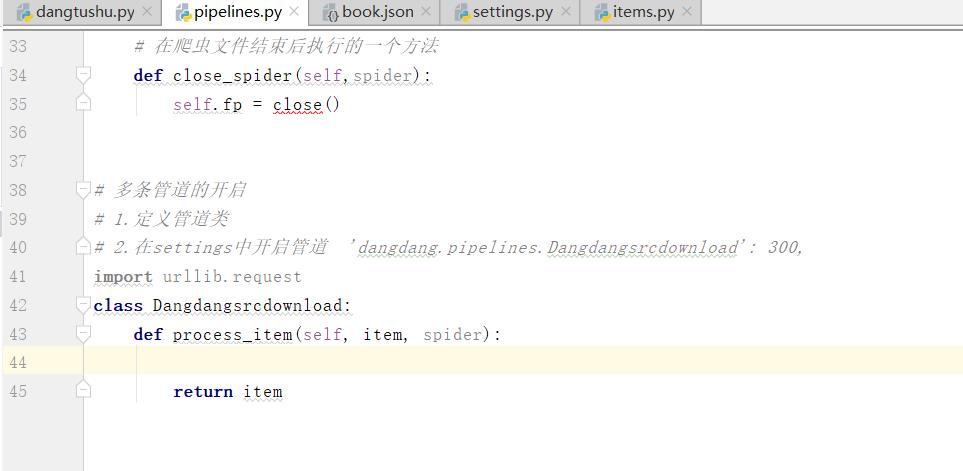
1.定义管道类
多条管道的开启,和上面一条管道类似,但我们需要重新定义一个类:
class Dangdangsrcdownload:
def process_item(self, item, spider):
return item
2.在settings中开启管道
'dangdang.pipelines.Dangdangsrcdownload': 301,
3.下载数据
在这里我们可以应用之前学到的urllib库来下载图片
import urllib.request
class Dangdangsrcdownload:
def process_item(self, item, spider):
# 下载图片
url = item.get('src')
filename ='./booksrc/' + item.get('name') + '.jpg'
urllib.request.urlretrieve(url = url ,filename= filename)
return item
同样再控制台输入指定来执行爬虫文件
运行结果:

感兴趣的小伙伴,可以私聊我要全部源码哦!
本篇文章到这里就结束啦,这里也是详细的给大家讲解的scrapy框架的基本使用,有不足的地方欢迎再评论区补充!!记得三连哦!!!!
以上是关于python爬虫从0到1 - Scrapy框架的实战应用的主要内容,如果未能解决你的问题,请参考以下文章