翻译: 2.6 概率论 深入神经网络 pytorch
Posted AI架构师易筋
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了翻译: 2.6 概率论 深入神经网络 pytorch相关的知识,希望对你有一定的参考价值。
以某种形式,机器学习就是做出预测。考虑到患者的临床病史,我们可能想要预测患者明年心脏病发作的可能性。在异常检测中,我们可能想要评估飞机喷气发动机的一组读数是否正常运行。在强化学习中,我们希望代理在环境中智能地行动。这意味着我们需要考虑在每个可用操作下获得高回报的概率。当我们构建推荐系统时,我们还需要考虑概率。例如,假设性地说我们为一家大型在线书商工作。我们可能想要估计特定用户购买特定书籍的概率。为此,我们需要使用概率语言。整个课程,专业,论文,职业,甚至部门,都致力于概率。所以很自然,我们在本节中的目标不是教授整个学科。相反,我们希望让您起步,教给您足够的知识,让您可以开始构建您的第一个深度学习模型,并为您提供足够的主题,如果您愿意,您可以开始自己探索它.
我们已经在前面的章节中提到了概率,但没有明确说明它们是什么,也没有给出具体的例子。现在让我们更严肃地考虑第一种情况:根据照片区分猫和狗。这听起来很简单,但实际上是一项艰巨的挑战。首先,问题的难度可能取决于图像的分辨率。

图 2.6.1不同分辨率的图像(10 x 10, 20 x 20, 40 x 40, 80 x 80, 和 160 x 160 像素)。

现在考虑第二种情况:给定一些天气监测数据,我们想预测明天台北下雨的概率。如果是夏季,下雨的概率可能为 0.5。
在这两种情况下,我们都有一些有趣的价值。在这两种情况下,我们都不确定结果。但这两种情况有一个关键的区别。在第一种情况下,图像实际上不是狗就是猫,我们只是不知道是哪一个。在第二种情况下,结果实际上可能是一个随机事件,如果你相信这样的事情(大多数物理学家也是如此)。因此,概率是一种灵活的语言,用于推理我们的确定性水平,它可以有效地应用于广泛的环境中。
2.6.1 基本概率论¶

每个值的一种自然方法是对该值进行单独计数,然后将其除以投掷总数。这给了我们一个给定事件概率的估计。大数定律告诉我们,随着投掷次数的增加,这个估计将越来越接近真实的潜在概率。在详细介绍这里发生的事情之前,让我们尝试一下。
首先,让我们导入必要的包。
%matplotlib inline
import torch
from torch.distributions import multinomial
from d2l import torch as d2l
接下来,我们将希望能够掷骰子。在统计学中,我们称这种从概率分布 抽样中抽取样本的过程。将概率分配给许多离散选择的分布称为多项分布。稍后我们将给出分布的更正式定义,但在较高层次上,将其视为对事件的概率分配。
要绘制单个样本,我们只需传入一个概率向量。输出是另一个相同长度的向量:它在索引处的值i 是采样结果对应的次数i .
fair_probs = torch.ones([6]) / 6
multinomial.Multinomial(1, fair_probs).sample()
tensor([1., 0., 0., 0., 0., 0.])
如果你多次运行采样器,你会发现每次都得到随机值。与估计骰子的公平性一样,我们经常希望从相同的分布中生成许多样本。使用 Python 循环执行此操作会非常慢for,因此我们使用的函数支持一次绘制多个样本,返回我们可能想要的任何形状的独立样本数组。
multinomial.Multinomial(10, fair_probs).sample()
tensor([3., 1., 3., 0., 0., 3.])
既然我们知道如何对模具卷进行采样,我们就可以模拟 1000 卷。然后,我们可以在每 1000 次滚动后计算每个数字滚动了多少次。具体来说,我们计算相对频率作为真实概率的估计。
# Store the results as 32-bit floats for division
counts = multinomial.Multinomial(1000, fair_probs).sample()
counts / 1000 # Relative frequency as the estimate
tensor([0.1790, 0.1660, 0.1570, 0.1700, 0.1610, 0.1670])

我们还可以想象这些概率如何随着时间的推移向真实概率收敛。让我们进行 500 组实验,每组抽取 10 个样本。
counts = multinomial.Multinomial(10, fair_probs).sample((500,))
cum_counts = counts.cumsum(dim=0)
estimates = cum_counts / cum_counts.sum(dim=1, keepdims=True)
d2l.set_figsize((6, 4.5))
for i in range(6):
d2l.plt.plot(estimates[:, i].numpy(),
label=("P(die=" + str(i + 1) + ")"))
d2l.plt.axhline(y=0.167, color='black', linestyle='dashed')
d2l.plt.gca().set_xlabel('Groups of experiments')
d2l.plt.gca().set_ylabel('Estimated probability')
d2l.plt.legend();
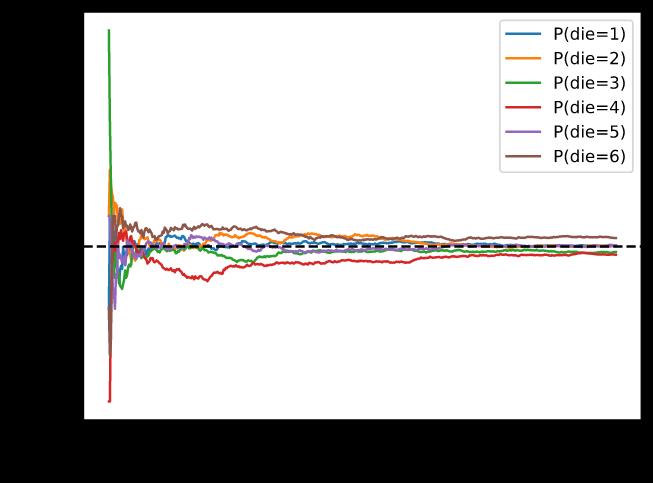
每条实线对应于骰子的六个值中的一个,并给出了我们在每组实验后评估的骰子出现该值的估计概率。黑色虚线给出了真实的潜在概率。随着我们通过进行更多实验获得更多数据,
2.6.1.1 概率论公理

2.6.1.2 随机变量

请注意,离散随机变量(例如骰子的侧面)与连续随机变量之间存在细微差别比如一个人的体重和身高。询问两个人的身高是否完全相同是没有意义的。如果我们进行足够精确的测量,您会发现地球上没有两个人的身高完全相同。事实上,如果我们进行足够精细的测量,当你醒来和睡觉时,你的身高不会相同。因此,询问某人身高为 1.80139278291028719210196740527486202 米的概率是没有意义的。鉴于世界人口,概率实际上是 0。在这种情况下,询问某人的身高是否落入给定的区间(例如 1.79 到 1.81 米之间)更有意义。在这些情况下,我们量化我们将值视为密度的可能性. 正好 1.80 米的高度没有概率,但非零密度。在任何两个不同高度之间的间隔中,我们有非零概率。在本节的其余部分,我们考虑离散空间中的概率。对于连续随机变量的概率,您可以参考 第 18.6 节。
2.6.2. 处理多个随机变量
很多时候,我们会希望一次考虑多个随机变量。例如,我们可能想要模拟疾病和症状之间的关系。给定一种疾病和症状,比如“流感”和“咳嗽”,患者可能会或可能不会发生。虽然我们希望两者的概率接近于零,但我们可能希望估计这些概率及其彼此之间的关系,以便我们可以应用我们的推论来实现更好的医疗保健。
作为一个更复杂的例子,图像包含数百万个像素,因此有数百万个随机变量。在许多情况下,图像会带有标签,用于识别图像中的对象。我们也可以将标签视为随机变量。我们甚至可以将所有元数据视为随机变量,例如位置、时间、光圈、焦距、ISO、焦距和相机类型。所有这些都是共同发生的随机变量。当我们处理多个随机变量时,有几个感兴趣的数量。
2.6.2.1 联合概率

2.6.2.2 条件概率
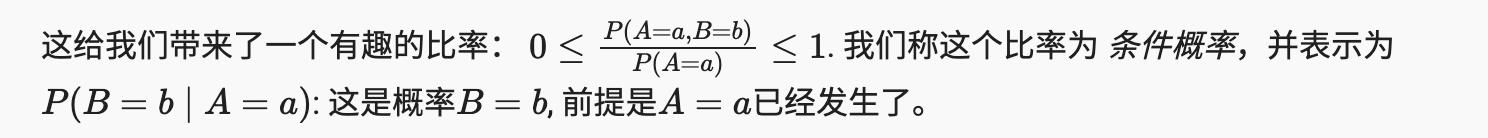
2.6.2.3 贝叶斯定理

2.6.2.4。边缘化
如果我们想从另一件事推断出一件事,贝叶斯定理非常有用,比如因果关系,但我们只知道相反方向的属性,正如我们将在本节后面看到的那样。为了使这项工作发挥作用,我们需要的一项重要操作是边缘化。这是确定的操作P(B)从P(A, B). 我们可以看到概率B相当于考虑了所有可能的选择A并聚合所有这些的联合概率:
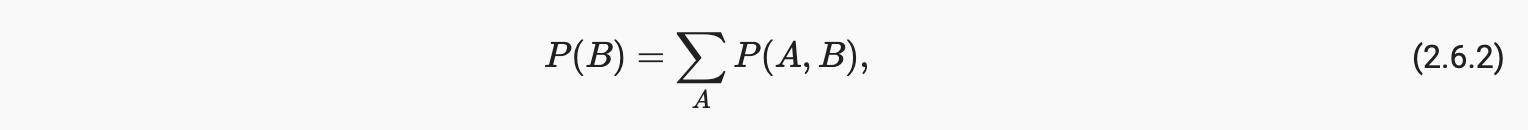
这也称为求和规则。作为边缘化结果的概率或分布称为边缘概率或 边缘分布。
2.6.2.5 独立

2.6.2.6。应用
让我们测试一下我们的技能。假设医生对患者进行 HIV 检测。该测试相当准确,如果患者健康但报告他有病,则只有 1% 的概率会失败。此外,如果患者确实感染了艾滋病毒,它永远不会检测不到艾滋病毒。我们用D1
表示诊断(1如果是肯定的并且0如果为负)和H表示 HIV 状态 (1如果是肯定的并且0如果为负)。 2.6.2.6 节列出了这样的条件概率。
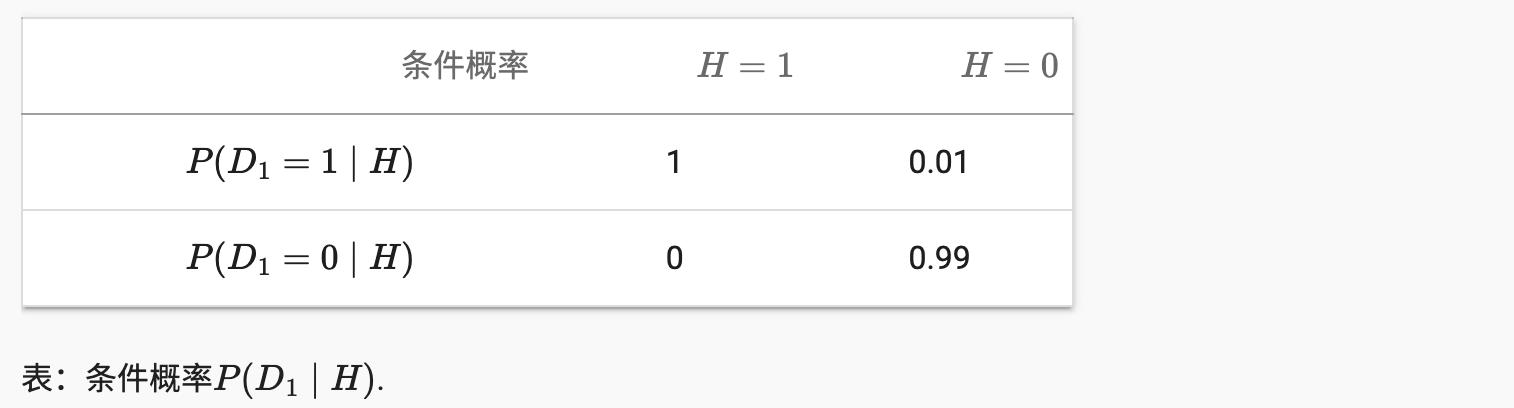

因此,我们得到
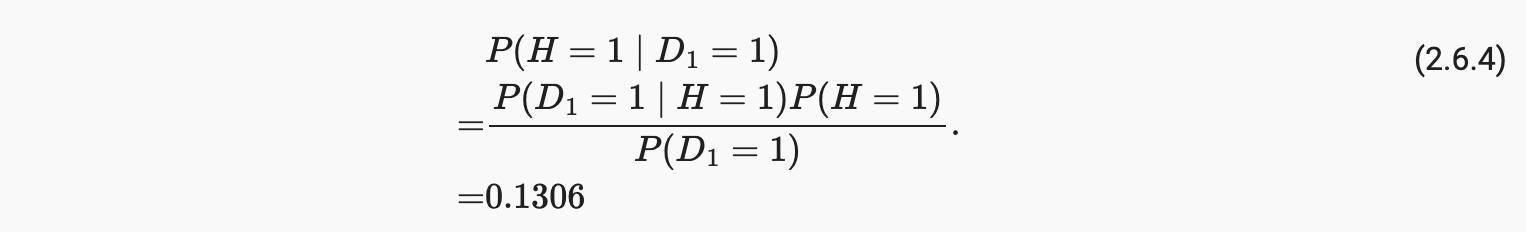
换句话说,尽管使用了非常准确的测试,但患者实际感染 HIV 的可能性仅为 13.06%。正如我们所看到的,概率可能是违反直觉的。
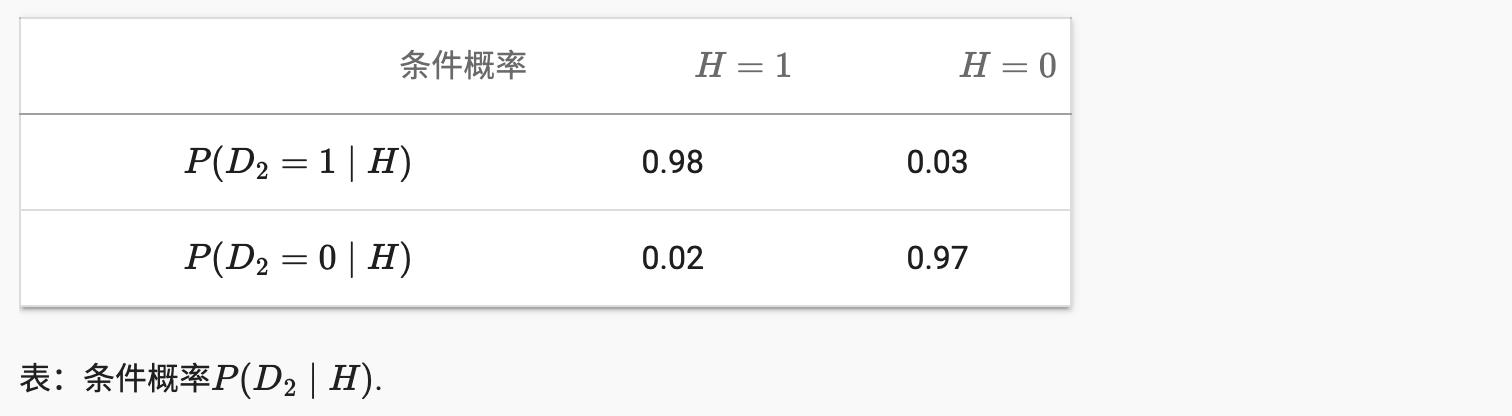
患者收到如此可怕的消息后该怎么办?很可能,患者会要求医生进行另一次测试以获得清晰。第二个测试有不同的特点,它不如第一个,如第 2.6.2.6 节所示。

现在我们可以应用边缘化和乘法规则:
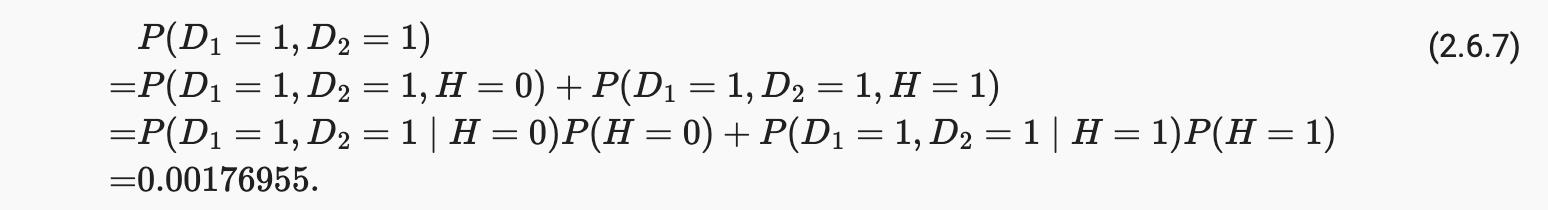
最后,两次检测均呈阳性的患者感染 HIV 的概率为
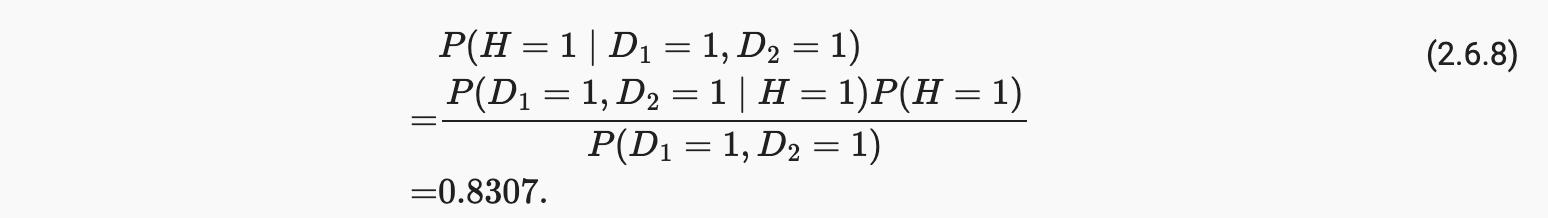
也就是说,第二次测试让我们获得了更高的信心,即并非一切都好。尽管第二次测试的准确度远低于第一次,但它仍然显着改善了我们的估计。
2.6.3. 期望和方差
为了总结概率分布的关键特征,我们需要一些度量。随机变量 的期望(或平均值)表示为
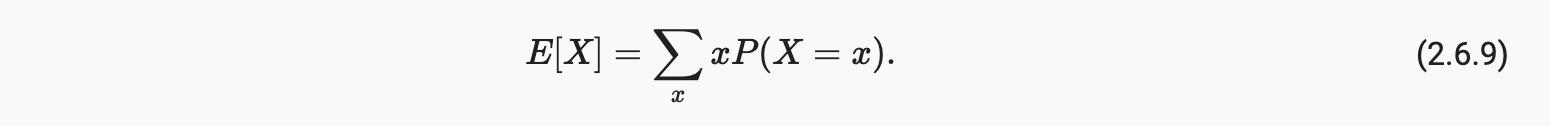
当输入一个函数f(x)是从分布中抽取的随机变量P具有不同的价值x, 的期望f(x)计算为
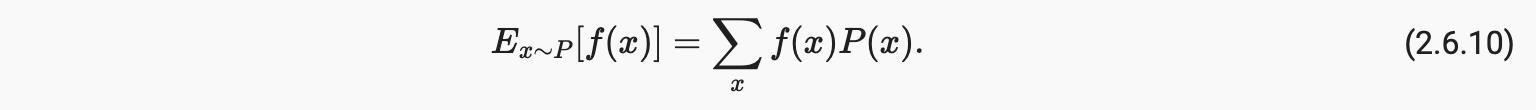
在许多情况下,我们希望通过随机变量的多少来衡量 X偏离了它的预期。这可以通过方差来量化
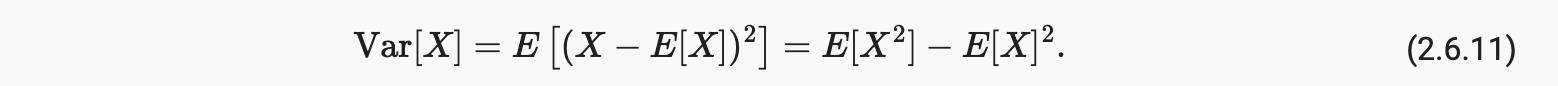
它的平方根称为标准差。随机变量的函数的方差通过函数偏离函数期望的程度来衡量,作为不同的值x的随机变量从其分布中采样:
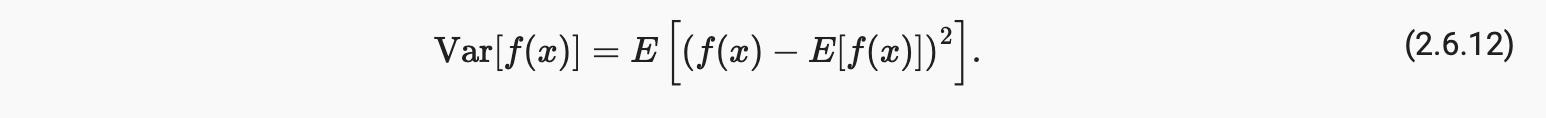
2.6.4 概括
-
我们可以从概率分布中采样。
-
我们可以使用联合分布、条件分布、贝叶斯定理、边缘化和独立假设来分析多个随机变量。
-
期望和方差提供了有用的度量来总结概率分布的关键特征。
2.6.5 练习

- StevenJokes 的解法
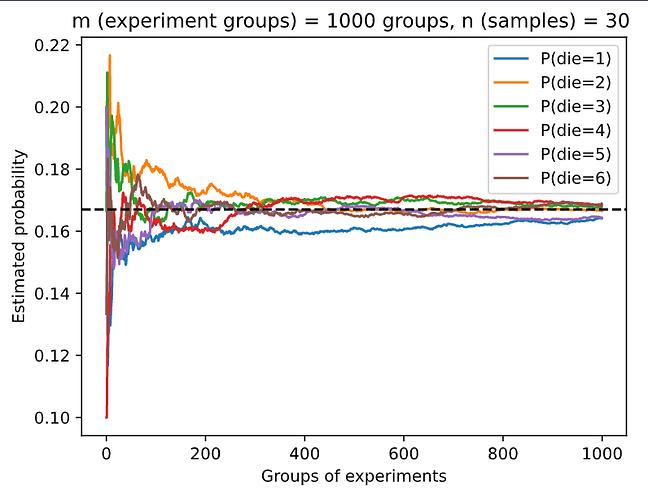
def experiment_fig(n, m):
counts = torch.from_numpy(np.random.multinomial(n, fair_probs, size=m))
cum_counts = counts.type(torch.float32).cumsum(axis=0)
estimates = cum_counts / cum_counts.sum(axis=1, keepdims=True)
d2l.set_figsize((6, 4.5))
for i in range(6):
d2l.plt.plot(estimates[:, i].numpy(),
label=("P(die=" + str(i + 1) + ")"))
d2l.plt.axhline(y=0.167, color='black', linestyle='dashed')
d2l.plt.gca().set_xlabel('Groups of experiments')
d2l.plt.gca().set_ylabel('Estimated probability')
d2l.plt.title(f'm (experiment groups) = m groups, n (samples) = n ')
d2l.plt.legend()
experiment_fig(30, 1000)
参考
https://d2l.ai/chapter_preliminaries/probability.html
以上是关于翻译: 2.6 概率论 深入神经网络 pytorch的主要内容,如果未能解决你的问题,请参考以下文章