[侯捷 C++内存管理] 标准分配器实现
Posted 鱼竿钓鱼干
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了[侯捷 C++内存管理] 标准分配器实现相关的知识,希望对你有一定的参考价值。
[侯捷 C++内存管理] 标准分配器实现
文章目录
VC6 标准分配器之实现
VC6 malloc()
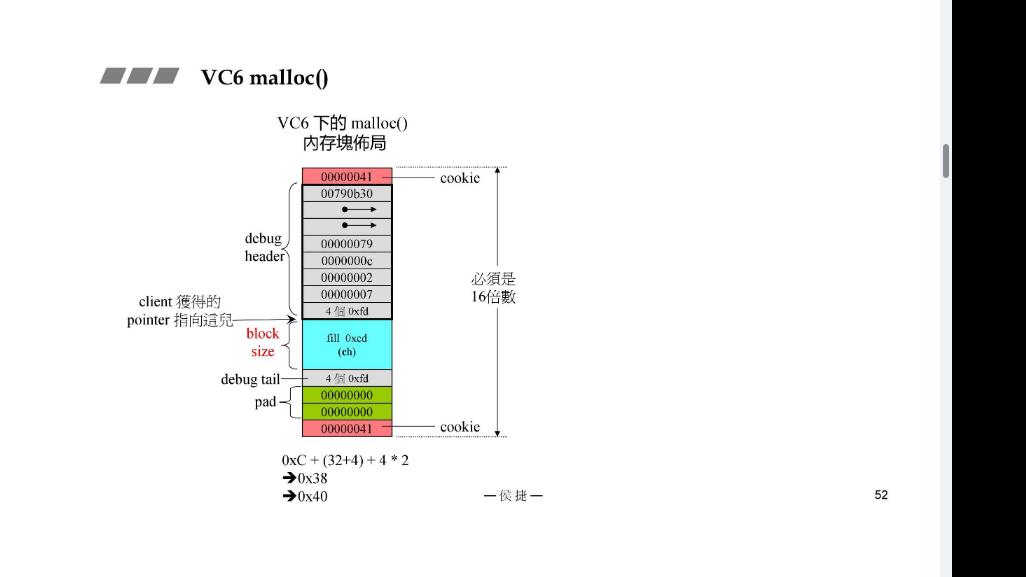
我们现在希望能够去除上下的cookie以节省内存
去除cookie的先决条件是区块要一样大小。容器里所有元素是同样的大小
VC6 allocator
VC6:哎,我就是不做内存管理设计,我就是玩
VC6 的 allocator没做任何的内存管理,只是把malloc换一个样貌。就是用::operator new和::operator delete完成任务罢了
VC里所有的容器的第二个模板参数都是这个偷懒的allocator,我们使用容器最终的元素分配都是靠malloc去做的,具体是以指定的元素类型为单位。

BC5 标准库分配器之实现
BC5和VC6的标准库分配器实现基本完全一样

G2.9 分配器的实现

G2.9的标准分配器和前面两个并没有太大区别,但是要注意到。defalloc.h里的标准库分配器并没有被任何容器包含,这很奇怪。
我们惊讶地发现,容器用的并不是std::allocator而是std::alloc

alloc是一个class,我们直接以alloc::allocate()的方式调用,说明allocate()和deallocate()是allocate里的静态函数。
另外值得注意的是,alloc::allocate(512)接受的是字节而非元素。
而今安在哉
到了G4.9我貌似找不到G2.9里的std::alloc了,这个好东西难道被去掉了吗?并没有,只是换了一个名字而已。G4.9标准库里有许多extented allocators其中的_pool_alloc就是G2.9的`alloc的化身
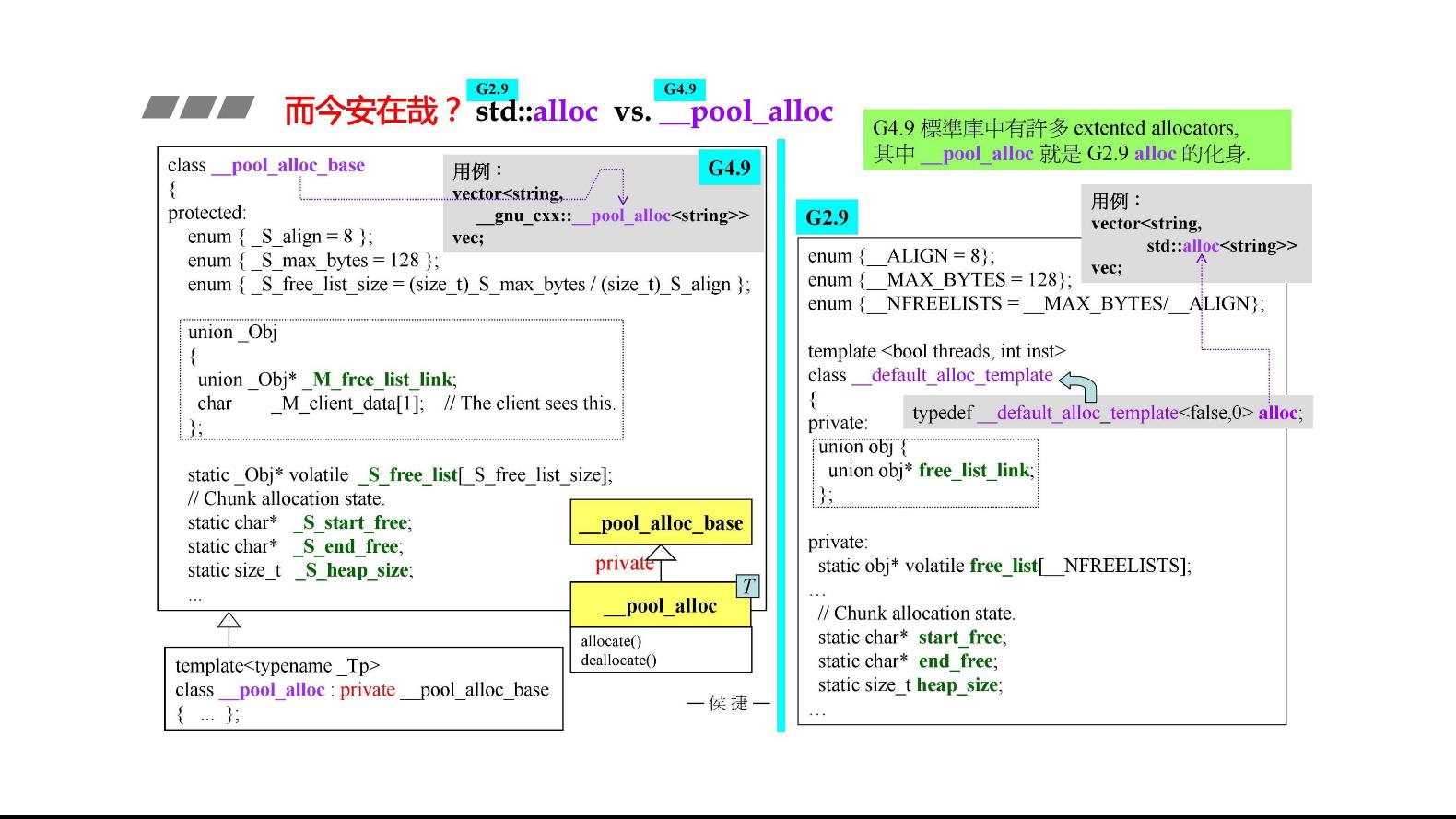
//如果你想在G4.9使用__pool_alloc这种好东西,可以看下面这个例子
vector<string,__gun_cxx::__pool_alloc<string>>vec;

G4.9 标准库分配器之实现
先前我们已经看到,G2.9的std::alloc到了G4.9变成体制外的__pool_alloc了。那么,G4.9体制内的标准分配器有什么变化呢?
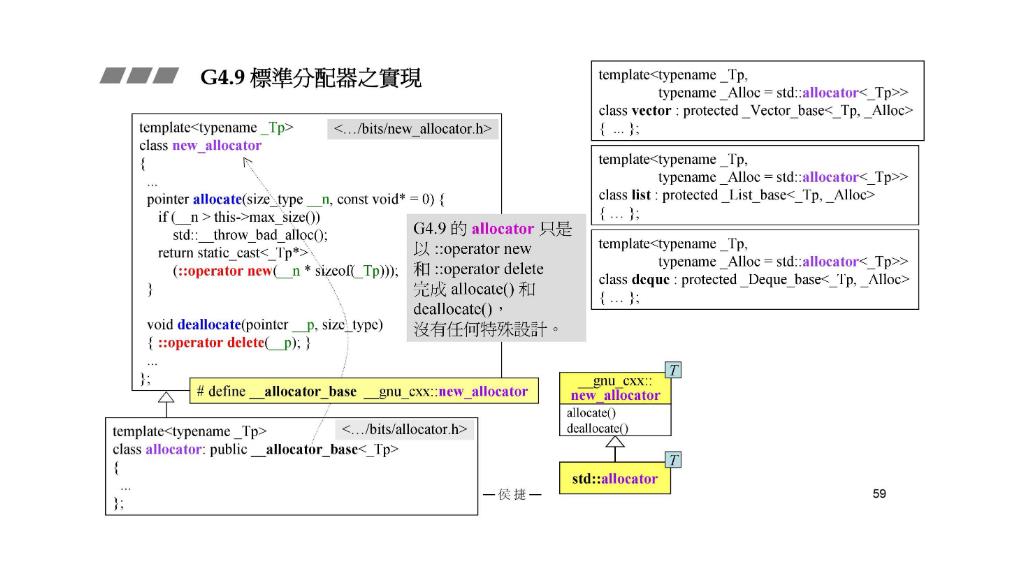
G4.9的std::allocator虽然多了个继承,但是换汤不换药啊(脑内开始范大将军名场面),还是没有做啥特别设计
G4.9 pool allocator 用例
pool allocator相比std::allocator的好处就是可以消除cookie。
试想一下,一个元素cookie为8 bytes那么一百万个元素呢?省下的内存可不小啊!

cout<<sizeof(__gun_cxx::__pool_alloc<int>)<<endl;//1,表明是个空类
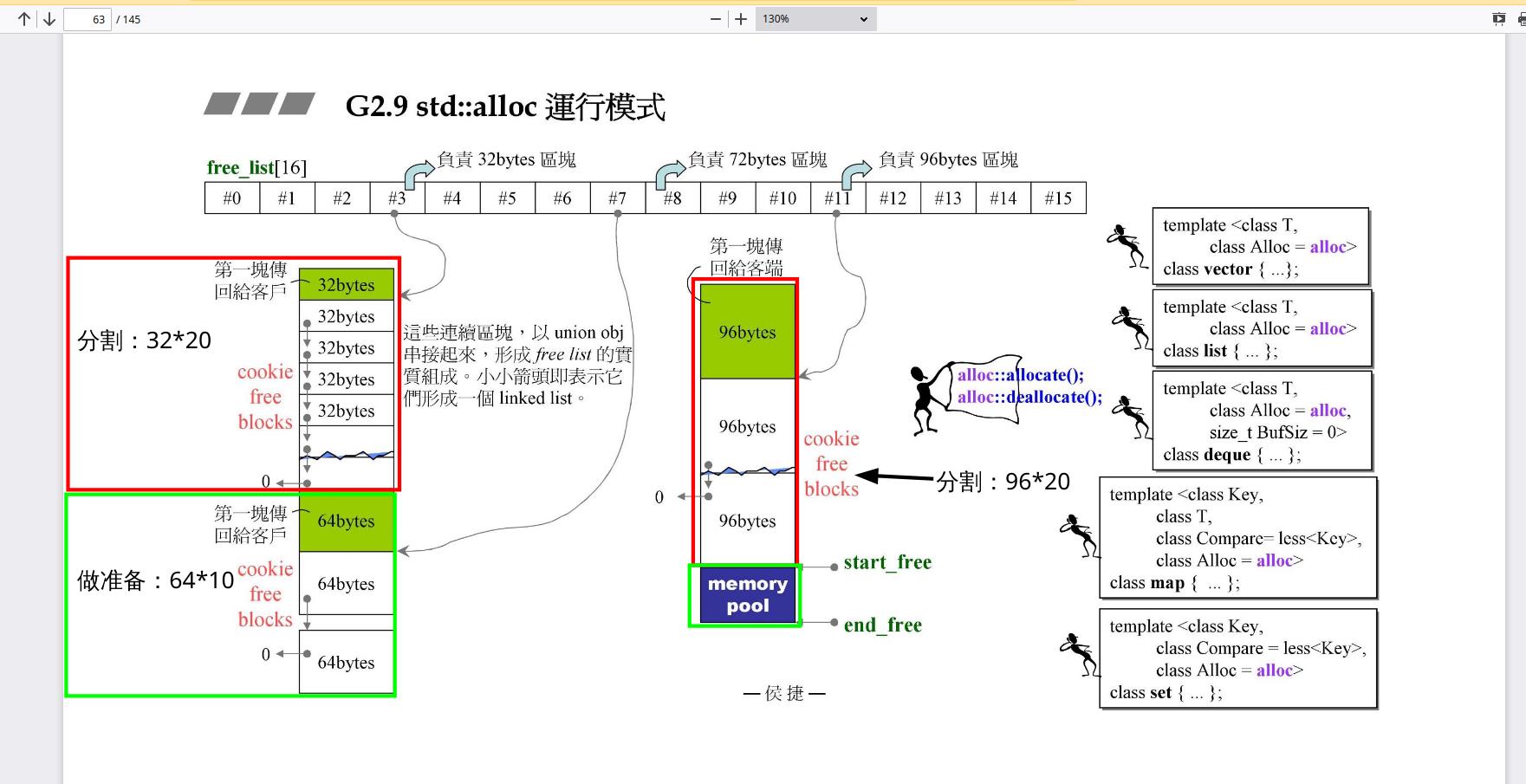
G2.9 std::alloc 运行模式
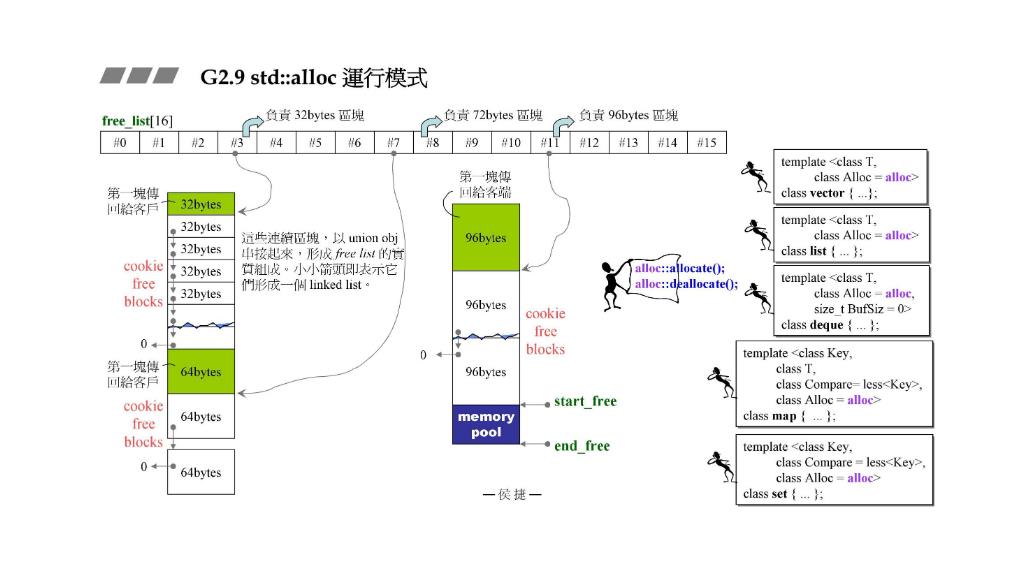
16条链表分别负责8、16、24、32……字节,如果容器发出来的需求不是8的倍数,那么会调整到8的倍数。负责范围[8-128],如果超过了这个范围,那么就会调用malloc来负责(malloc会有cookie,std::alloc没有cookie。
如果选了32字节的,那就挖一大块(20个,不要问为什么,或许是经验值)来作分割。实际上看到左边那个32和64的free lit我们可以看到他们是连着的,这意味着挖的时候其实挖了2*20个,一半用来分割,另一半的先不作处理做准备
embedded pointers
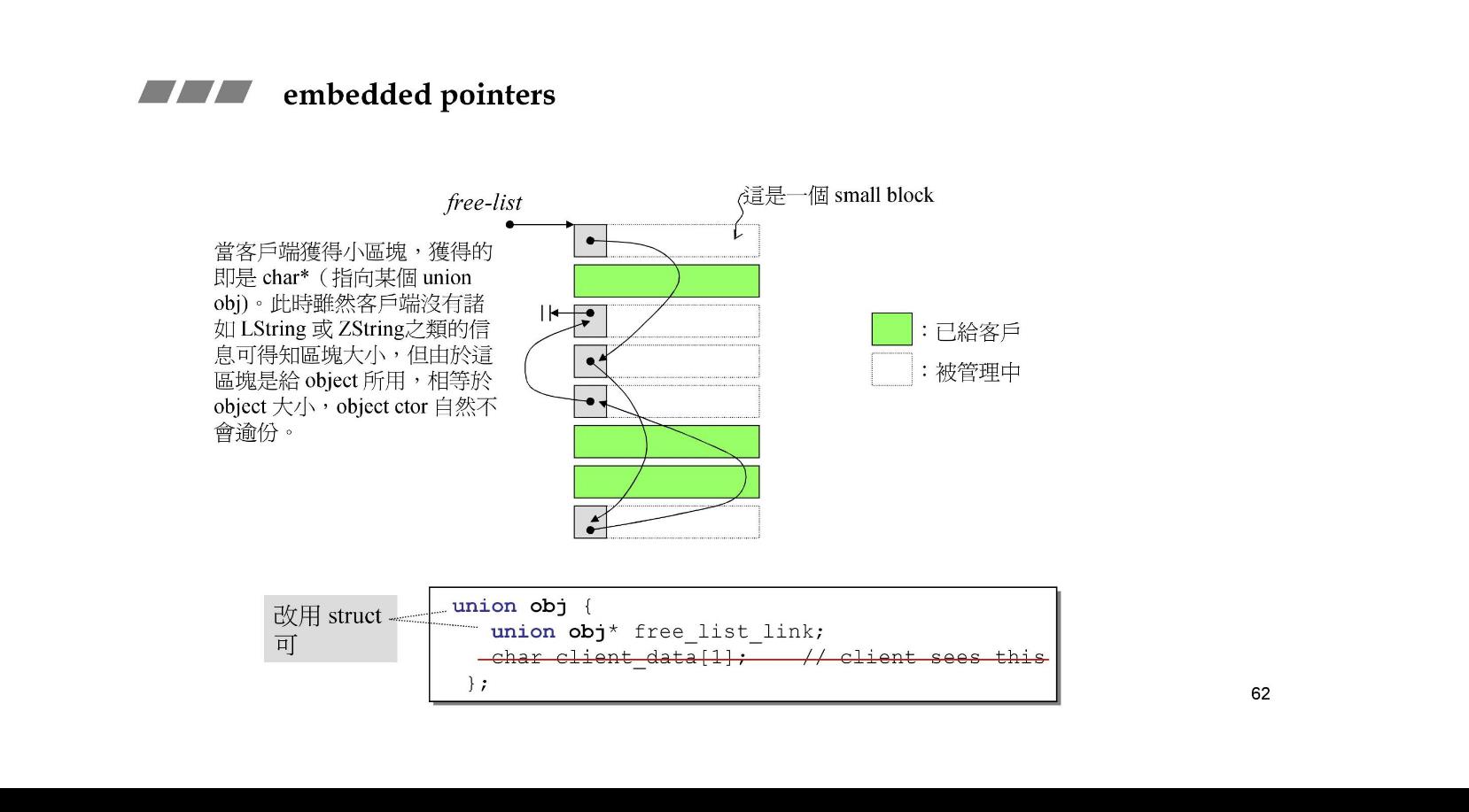
如果,客户(容器)要这块,那么链表的第一块就给出去。给出去的时候,容器就开始把这一块当作元素空间往里面填值,覆盖掉里面的指针(前四个字节)。并且给的时候free list的头已经给到下一块了。
等到容器归还内存的时候,又把前面的四个字节当作指针
但是如果对象小于四个字节,就不能被借用了,不过这样的情况比较少
G2.9 std::alloc 运行一瞥

分配器的客户:容器
具体动作:看pool,先把pool里的挖到链表里。如果还不够就再去索求申请,注入pool
一帆风顺
STEP1:容器申请 32bytes,我们先看用于准备的pool。由于pool为空,所以我们用malloc索取(注意图里的cookie)并向pool注入
32
∗
20
∗
2
+
R
o
u
n
d
U
p
(
0
>
>
4
)
=
1280
32*20*2+RoundUp(0>>4)=1280
32∗20∗2+RoundUp(0>>4)=1280,其中
R
o
u
n
d
U
p
(
)
RoundUp()
RoundUp()是用来调整到
16
16
16 的边界的追加量,而且这个追加量会越来越大。
然后前
19
19
19个分到free list里,剩下1个用于备用。

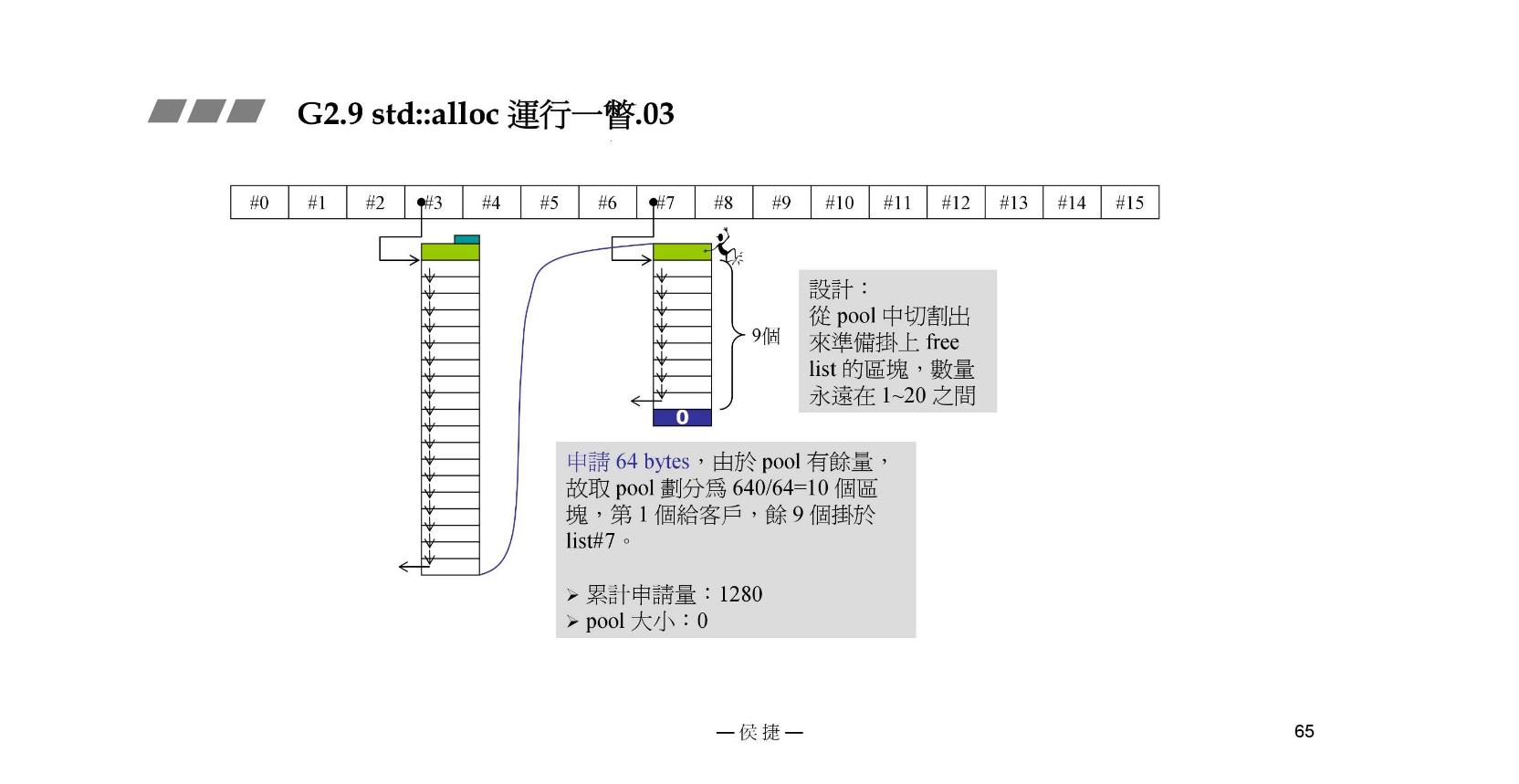
STEP2:接着上一步,我们接下来申请 64 bytes。先看 pool,因为STEP1之后pool里有 640 bytes,所以将其分为
640
/
64
=
10
640/64=10
640/64=10个内存块,第一个给客户,剩下九个挂到list#7。注意list#7的不是malloc的所以没有cookie
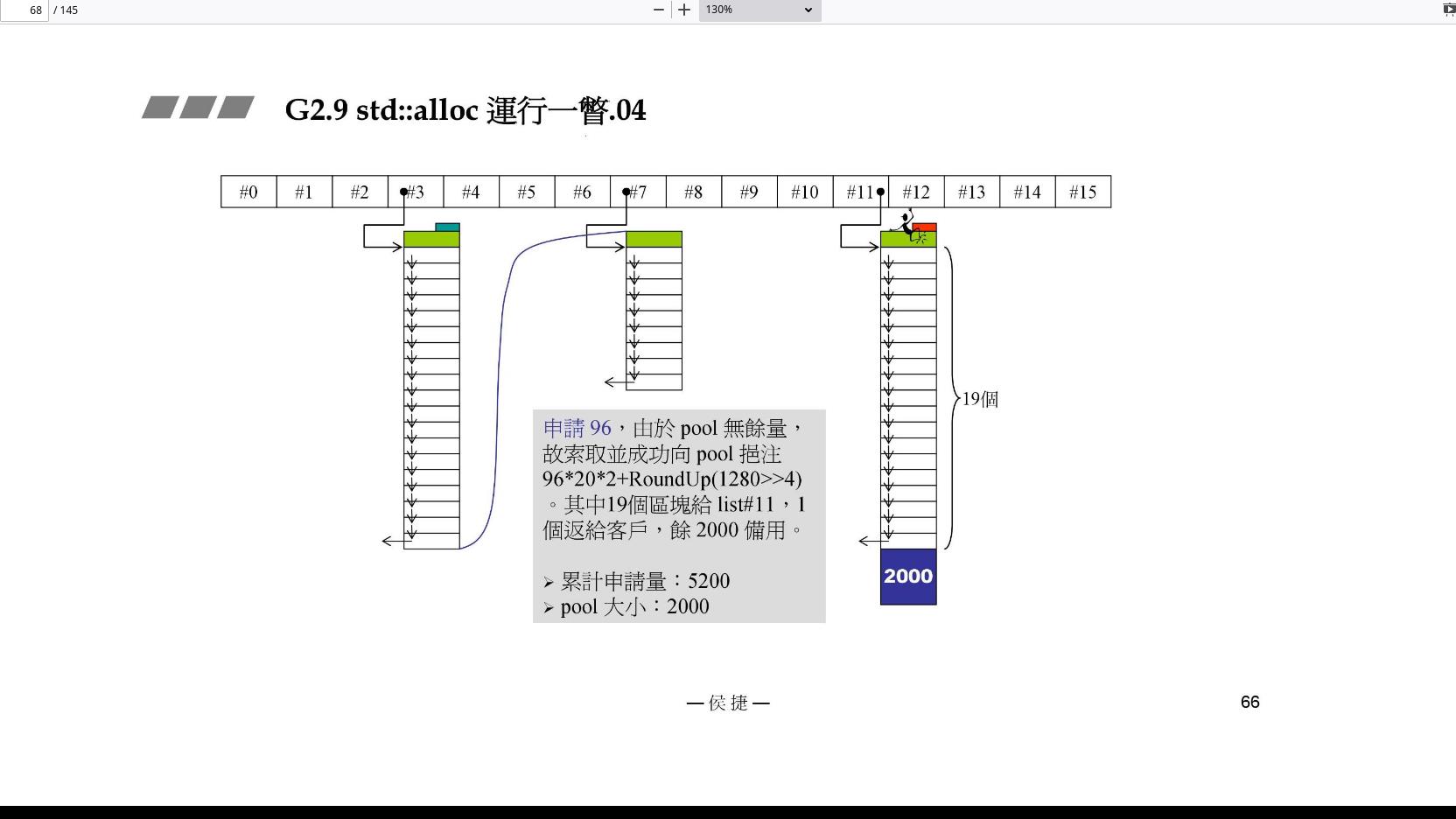
STEP3:接着上一步,我们接下来申请 96 bytes。先看 pool,因为STEP2之后pool里有 0 bytes,所以我们用malloc索取并向pool注入
96
∗
20
∗
2
+
R
o
u
n
d
U
p
(
1280
>
>
4
)
=
3920
96*20*2+RoundUp(1280>>4)=3920
96∗20∗2+RoundUp(1280>>4)=3920。其中追加量,RoundUp(
目
前
的
累
计
申
请
量
<
<
4
目前的累计申请量<<4
目前的累计申请量<<4)会越来越多,这会导致一个安全阀门。其中19个区块给list#11,1个给用户,剩下2000备用。
STEP4:申请88,应该找第
88
/
8
−
1
=
10
88/8-1=10
88/8−1=10号链表,由于pool剩下2000。所以取pool划分20个区块(尽量多但不能超20),第1个个给客户,剩下19个挂到list#10.pool剩下
2000
−
88
∗
20
=
240
2000-88*20=240
2000−88∗20=240
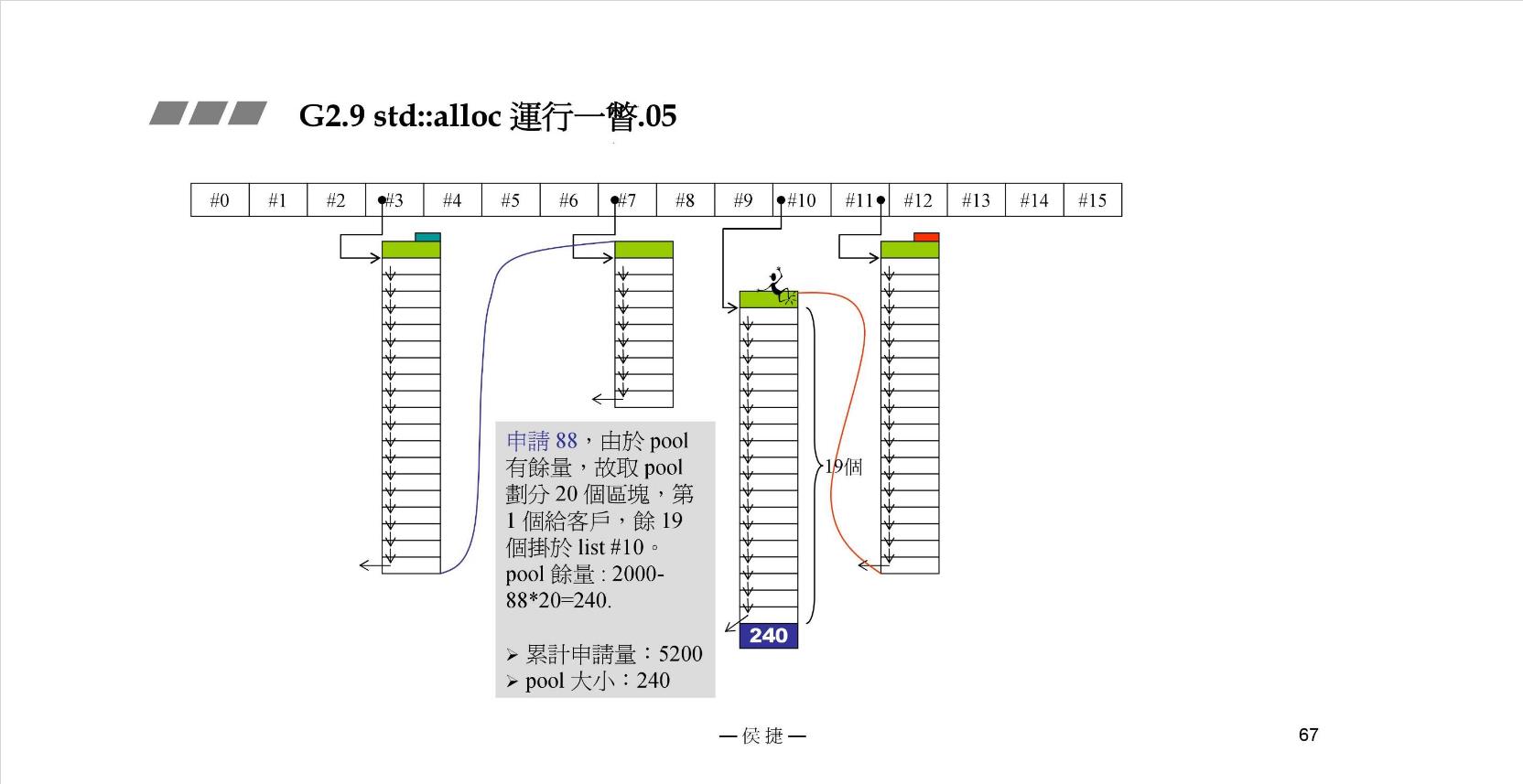
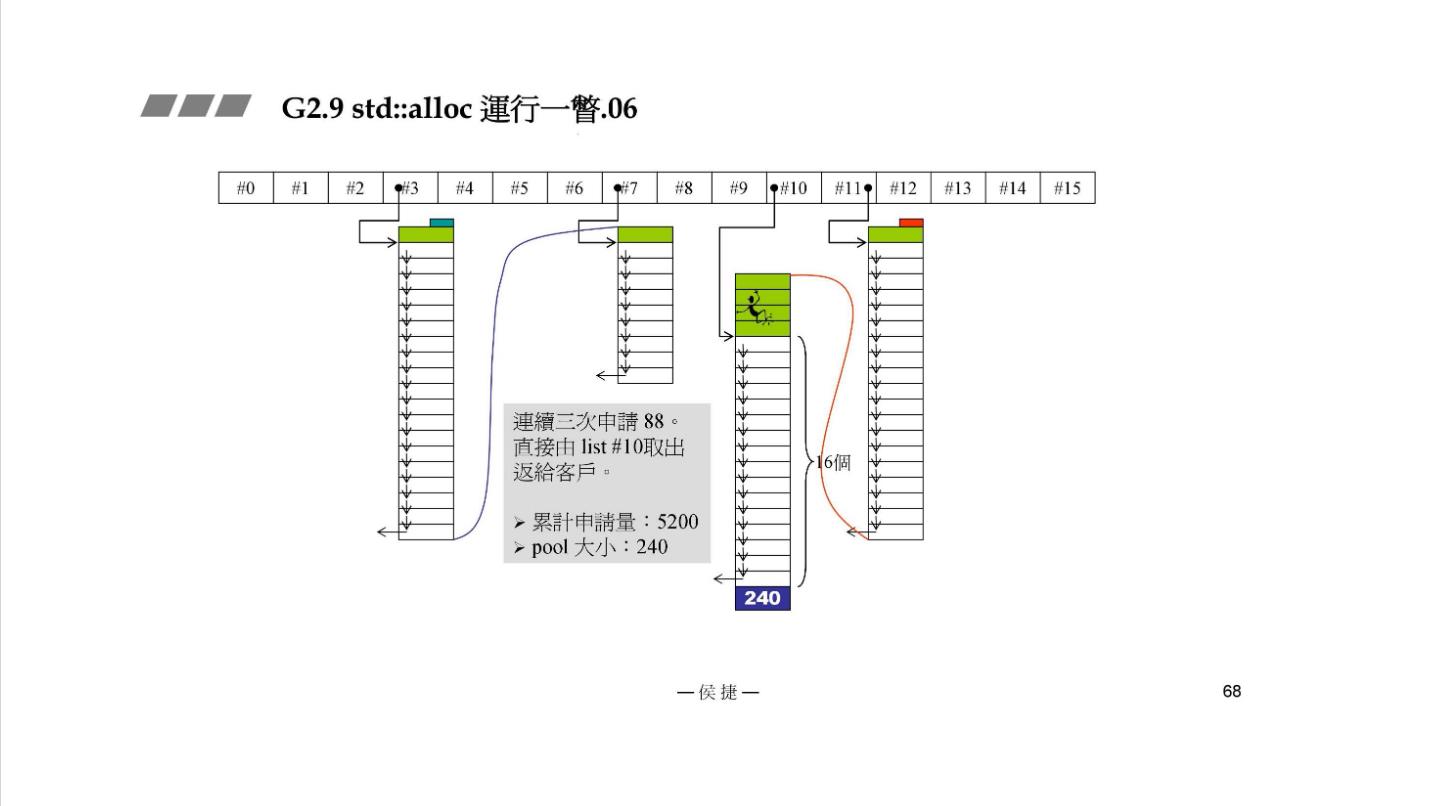
STEP5:连续 3 次 申请 88。直接从 #10 链表给客户
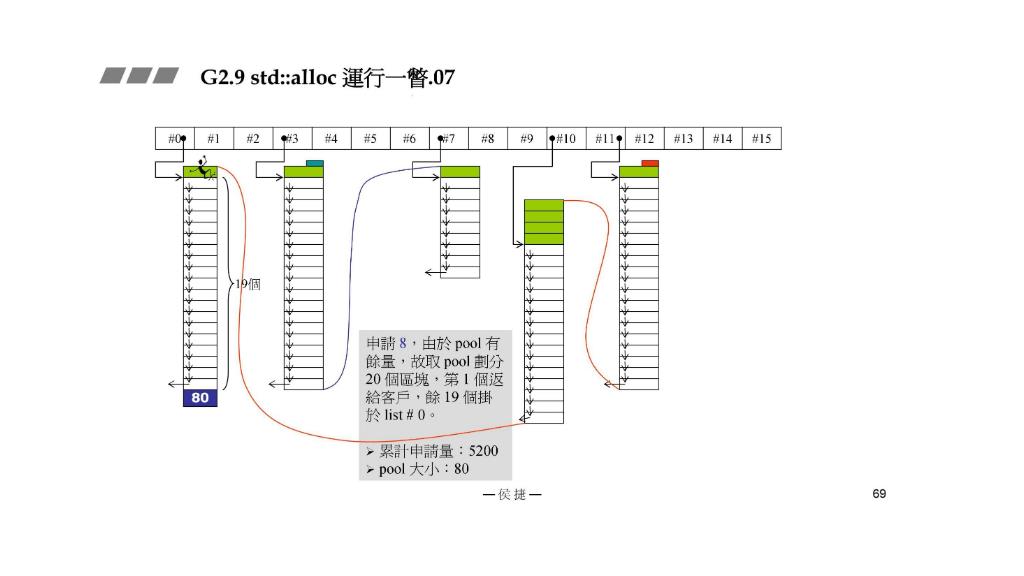
STEP6:申请8,由于 pool 有余量,所以取 pool划分 20 个区块,1个给客户,剩下19个挂于 list #0
看了上面几张图片可能会迷惑我们的pool怎么跑来跑去的很麻烦啊,实际上我们写代码实现的时候只需要两个指针一指就可以了
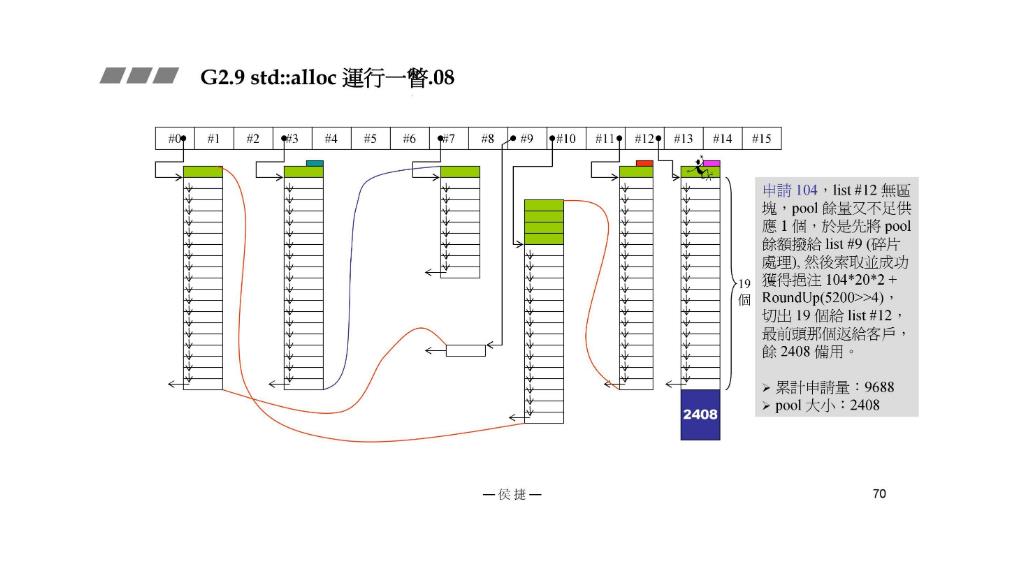
STEP7:申请
104
104
104,list #12没有区块,pool余量又不足提供一个(成碎片了),于是先将pool剩下的碎片(
80
80
80)分给list #9。然后索取并成功获得
104
∗
20
∗
2
+
R
o
u
n
d
U
p
(
5200
>
>
4
)
104*20*2+RoundUp(5200>>4)
104∗20∗2+RoundUp(5200>>4),切出
19
19
19 个给list #12最前面的那个给客户,剩下 2048备用
STEP8:申请
112
112
112,由于pool有余量,从pool中取
20
20
20 个区块,
1
1
1个给客户,留
19
19
19个挂到list #13
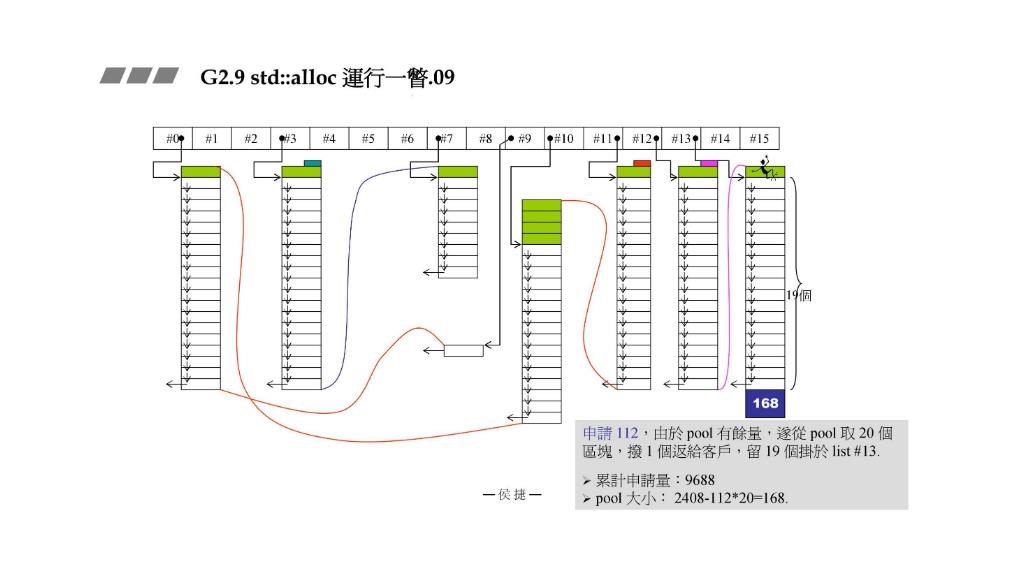
STEP9:申请
48
48
48,由于pool有余量,从pool中取
3
3
3个区块,
1
1
1个给客户,
2
2
2个挂到list #5
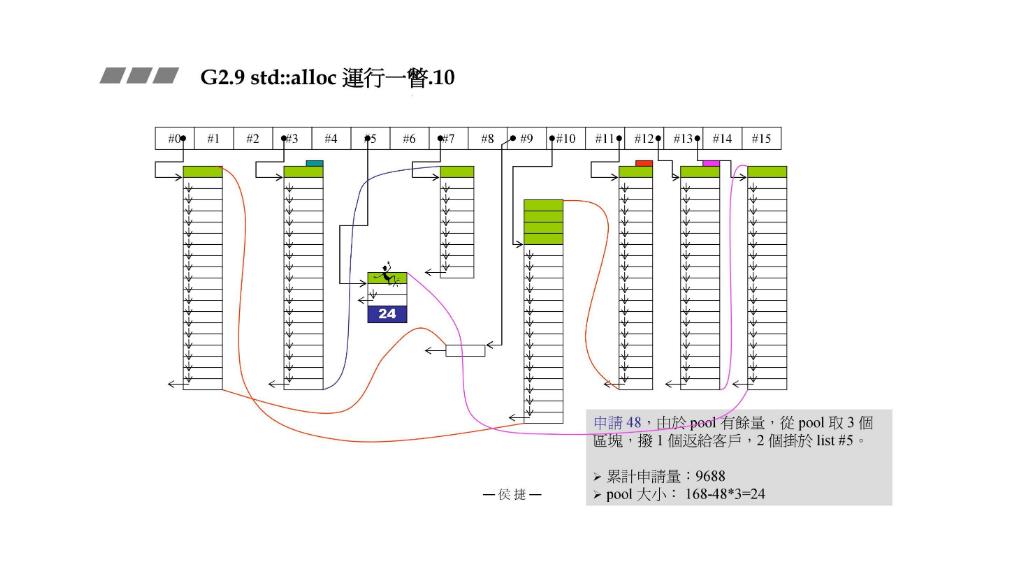
遭遇苦难
STEP10:申请
72
72
72,pool余量不足以供应
1
1
1个,于是先处理碎片把pool给list #2。然后索取
72
∗
20
∗
2
+
R
o
u
n
d
U
p
(
9688
>
>
4
)
72*20*2+RoundUp(9688>>4)
72∗20∗2+RoundUp(9688>>4),但是现在已经没法从sysytem heap索取那么多了,于是alloc已经申请的资源里找最接近 的
80
80
80 (list #9)回填给pool ,然后切出
72
72
72给客户,剩下
8
8
8

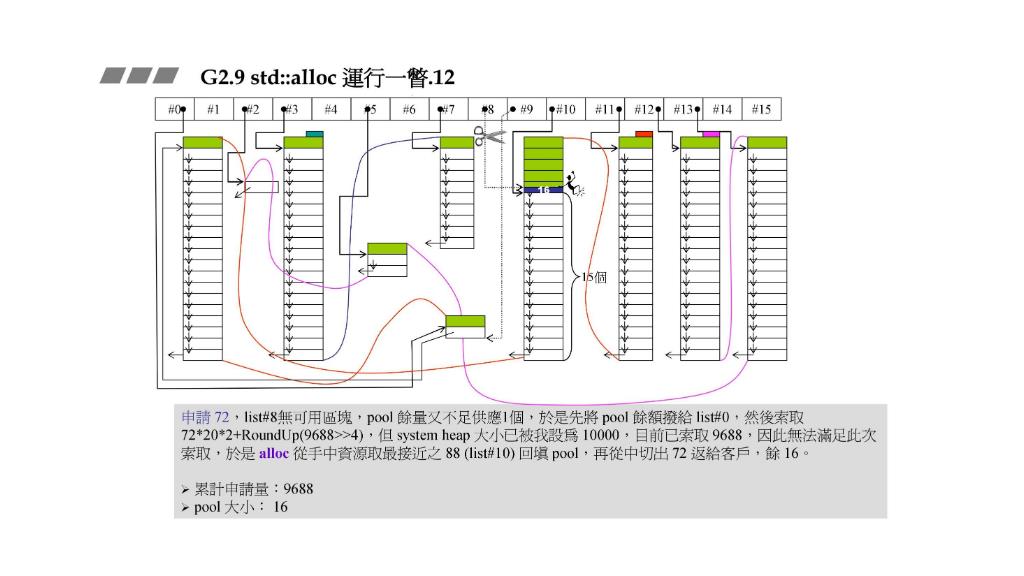
STEP11:申请
72
72
72,pool余量不足以供应
1
1
1个,于是先处理碎片把pool给list #0。然后索取
72
∗
20
∗
2
+
R
o
u
n
d
U
p
(
9688
>
>
4
)
72*20*2+RoundUp(9688>>4)
72∗20∗2+RoundUp(9688>>4),但是现在已经没法从sysytem heap索取那么多了,于是alloc已经申请的资源里找最接近 的
88
88
88 (list #9已经空啦,所以是list #10)回填给pool ,然后切出
72
72
72给客户,剩下
16
16
16
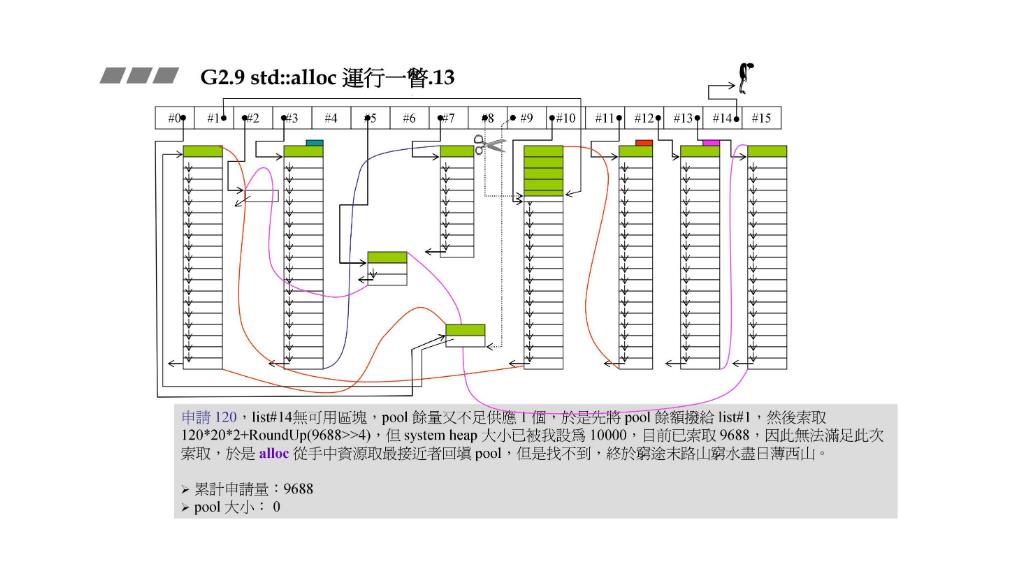
山穷水尽
STEP13:申请
120
120
120,pool余量不足以供应
1
1
1个,于是先处理碎片把pool给list #1。然后索取
72
∗
20
∗
2
+
R
o
u
n
d
U
p
(
9688
>
>
4
)
72*20*2+RoundUp(9688>>4)
72∗20∗2+RoundUp(9688>>4),但是现在已经没法从sysytem heap索取那么多了,于是alloc已经申请的资源里找最接近的,发现没有(list #14和list #15都是空的)结束了
柳暗花明?
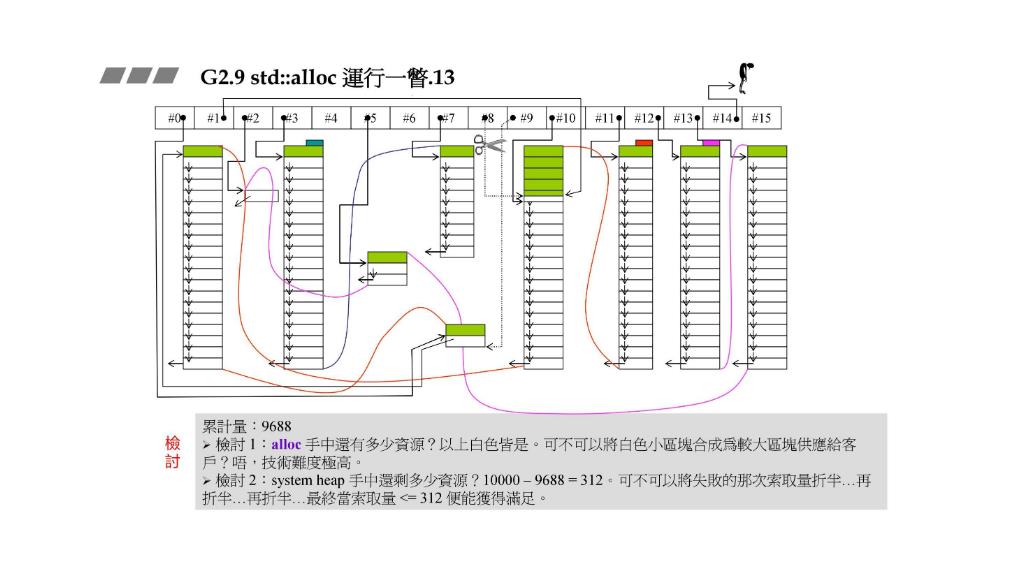
std::alloc在 STEP12 就投降举白旗了。这另我们感到诧异,明明还有出路啊。
- 我们已经拿的资源里还有那么多没有的小区块,为什么不把他们合并了?技术上好像挺难的
system heap还剩 312 312 312为什么不拿来用?将索取量不断折半直到可以申请
蓦然回首
来回顾一下std::alloc流程图吧
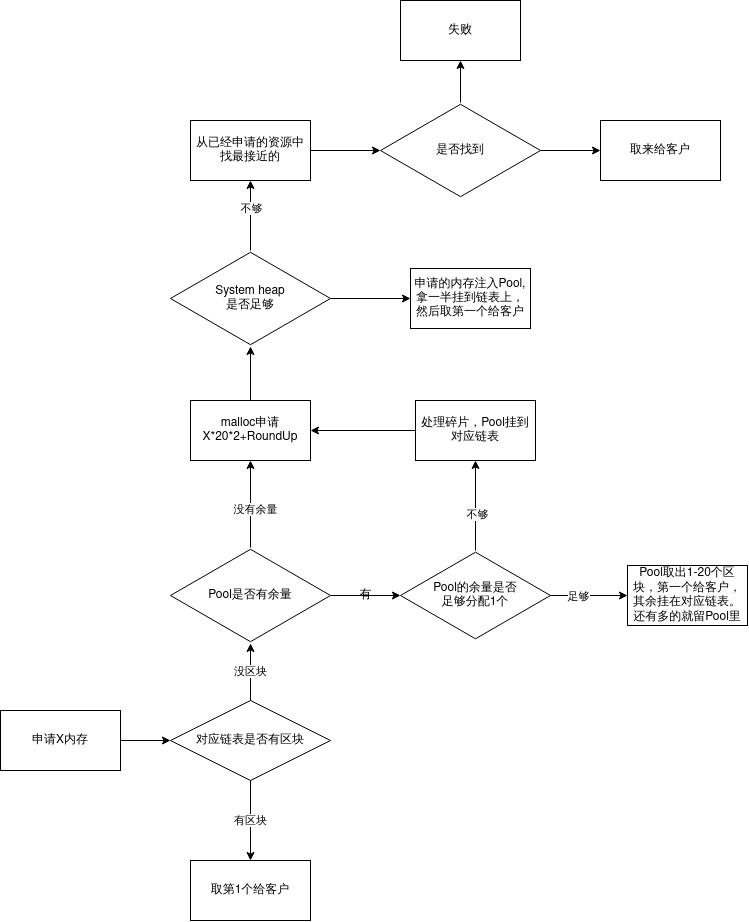
G2.9 std::alloc 源码剖析
暂时放一放实现细节
G2.9 std::alloc 细节讨论

小细节
部分代码可读性很差
-
#136和#210,多级指针生命就不要连着写了 -
#197和207准备变量和使用变量隔太远了,中间发生一些复杂的过程,这回让debug变得困难 -
#034一言难尽,括号套娃了
#208、#218、#255的写法很奇怪,但实际上是值得学习的。这样写可以避免把==写成=,把字面量放左边可以让编译器帮你检查
大灾难
上面都是一些细节问题,现在看到#212-#214这块描述的是malloc失败的时候(柳暗花明的那节)的处理
注释的意思是,如果malloc失败了,会从已有的资源里找到最接近需求的拿来用。
但是我们不尝试更小的请求,因为这会在多进程机器里导致大灾难。
更小的请求也就是我们先前的疑惑:system heap`还剩 312 312 312为什么不拿来用?将索取量不断折半直到可以申请。
那么这个大灾难是什么?为什么说是多进程机器?
std::alloc的策略实际上是一种竭泽而渔的方法,这在单进程的情况下确实没啥大问题。但是多进程机器中并不是只有这一个进程,竭泽而渔会导致其他进程没法正常运行,现在想来
R
o
u
d
U
p
RoudUp
RoudUp 附加量的不断增长大概也是为了这个吧。
物归原主
由于dealloc的先天缺陷,没有调用free或delete将内存还给操作系统。
先天缺陷:std::alloc成功的去掉了cookie节省了内存,但同时也因为cookie的缺失,我们没法知道应该释放多少内存了,也就没法把内存还给操作系统
后面我们会在loki的分配器里看到更好的设计
以上是关于[侯捷 C++内存管理] 标准分配器实现的主要内容,如果未能解决你的问题,请参考以下文章