(RN)Region Normalization for Image Inpainting
Posted 马鹏森
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了(RN)Region Normalization for Image Inpainting相关的知识,希望对你有一定的参考价值。
论文地址:AAAI 2020. https://arxiv.org/pdf/1911.10375v1.pdf
motivation:传统的image inpainting的方式利用FN(feature normalization)来帮助网络训练,但是他们往往是在整个图像上进行,没有考虑到corrupted region的像素对于mean/variance的影响,这篇文章通过RN(regional normalization)把空间像素根据mask分别不同的区域,然后在不同的区域上分别计算mean和variance。
key idea: 设计了两种RN用于图像的inpaint,两种方法都是区域归一化:
(1) Basic RN(RN-B),它基于输入的mask对corrupted区域和uncorrupted区域分别进行归一化,解决了均值和方差的偏移问题;(前者是基础版,需要输入mask)
(2) Learnable RN(RN-L),自动检测潜在的损坏和未损坏的区域进行单独的归一化,并执行全局仿射变换来增强它们的融合。最终在网络的浅层使用RN-B在深层使用RN-L。(后者是可学习版,只需要输入feature maps即可。)
网络整体结构:
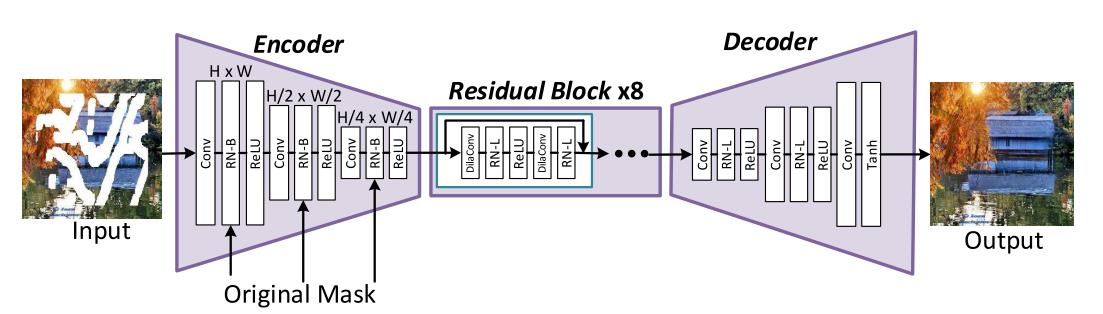
由Encoder、Residual Block、Decoder三部分组成。其中Encoder采用RN-B方法,Residual Block和Decoder采用RN-L方法。
判别器: 照搬 PatchGAN (Isola et al. 2017; Zhu et al. 2017) 的结构。同时采用了其损失函数,共包括四部分:reconstruction loss,adversarial loss,perceptual loss and style loss。
网络结构和损失函数上并没有创新的地方,将不同的已有的优秀方法拼凑而成。
4、文中创新点的地方:Region Normalization 的定义
对于每一个输入的feature map 其都有四个维度:N,C,H,W。分别代表batch size(批数量),channels(通道数),height(特征图的高),weith(特征宽)。既然是区域(region)归一化,就肯定有不同的区域,作者给出如下表示:
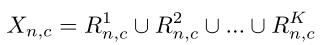
除了n,c还有H,W,所以每一批次feature maps 根据H,W两个维度来划分成若干块区域。RN算法的思想比较容易懂,绿色部分代表损坏的数据、红色部分代表未损坏的数据,两部分数据分别归一化。如下图:
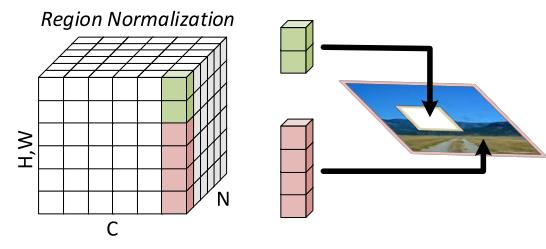
以n,c为索引确定待处理区域。将待处理区域分割为若干子区域。分别对若干region进行normalization然后合并。
对不同region分别进行normalization的操作时相同的:
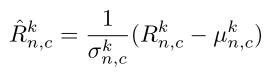
就是一个减去均值然后除以标准差的过程。均值和标准差的计算也是传统的方法,只是注意对统一region内像素进行计算。
这儿作者说明此方法其实是对Instance Normalization (IN)方法的一个拓展,当划分的region数量为1时,就是IN方法。 在图像修复领域,就把region数量设为2,一类完好区域,一类masked区域。
5、作者通过两种方式RN-B和RN-L运用RN方法
1)RN-B(Basic Region Normalization)
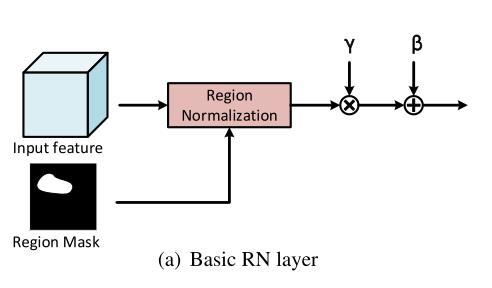
此方法根据输入的mask来划分original image 为两个区域(masked/unmasked),具体规则如下:

就是对于mask像素值为255的地方,判定为masked。将划分出的两个region分别用上述方法进行normalization,单独计算mean和varian然后合并得到完整的feature map。但是对于每个通道的feature,就有两组网络参数需要学习,不再是一个通道一组权重和偏差。
2)RN-L(Learnable Region Normalization)
在深层的网络里,各个corrupted area和uncorrupted area越发难以区分,相应的mask难以获得,这样RN-L对于corrupted区域进行预测,并且通过一个全局的放射系数帮助两个区域的融合。以下是RN-L的结构图:
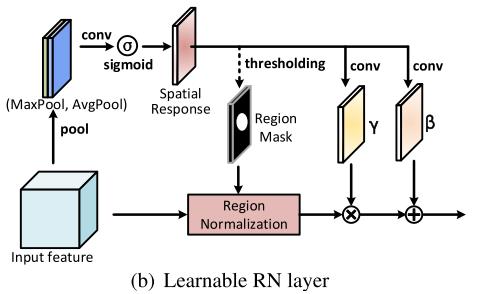
此方法不再需要手动输入mask来划分region。如上图所示,首先对输入的feature maps进行最大池化和均值池化(对channel axis)获得两个1×H×W的map,原文说 The two pooling operations are able to obtain an efficient feature descriptor.
将得到的两个池化层卷积后施加Sigmod激活函数得到 a spatial response map:
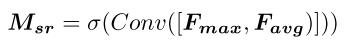
然后对 设置一个t=0.8的阈值来判断是否是masked区域(这儿我没太明白这么做的原理是什么,可能在上面提到的两个池化层操作的文章里面有解释):
设置一个t=0.8的阈值来判断是否是masked区域(这儿我没太明白这么做的原理是什么,可能在上面提到的两个池化层操作的文章里面有解释):
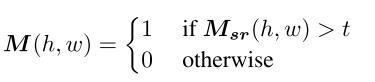
这儿0.8的阈值只在前向传播推断的过程发挥作用,不会影响反向传播中梯度的更新。(这句话的具体效果包括其此操作可能产生的影响我暂且没想明白,需要看代码理解这个地方)
在学习γ(scale)和β(shift) 参数时,文中说也是通过卷积操作得到:

这儿的卷积和上面对两个池化层的卷积需要去看代码来理解。γ和β在仿射变换的过程中会沿着channel 维度膨胀?
Thoughts
- 浅层的网络corrupted area和uncorrupted area分别normalization之后直接融合的话可能会在boundary的部分不平滑,可以借助上一Prior中提到的spatial adaptive loss作为最后的损失帮助网络平滑,但是这是在网络的输出,至于RN-B中如何平滑融合,我觉得可以在normalization并融合的模块里加一个boundary区域,也就是corrupted/uncorrupted/boundary,boundary的区域可以用三个的平均代替。
- 关于feature map的mask的获得,单纯地用阈值获得的方式是不够具有说服力的,最简单的方法是原图的mask内外阈值不应该一样。
- 关于深层的放射系数进行pixel-wise的计算这一点,我存在一定的疑问,仿射系数的作用是对归一化之后的像素进行缩放,因此在local的区域内我想这些系数应当是共享的,但是至于到底哪些区域应当共享确实是需要“分割确定”的。
[Note] Region Normalization for Image Inpainting - 知乎
Region Normalization 总结_一往而深深深深-CSDN博客
以上是关于(RN)Region Normalization for Image Inpainting的主要内容,如果未能解决你的问题,请参考以下文章