论文阅读强化学习与知识图谱关系路径发现
Posted 囚生CY
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了论文阅读强化学习与知识图谱关系路径发现相关的知识,希望对你有一定的参考价值。
- 论文标题:DeepPath: A Reinforcement Learning Method for Knowledge Graph Reasoning
- 中文标题:深度路径:知识图谱推理的强化学习方法
- 项目代码:GitHub@DeepPath
- 论文下载:arxiv@1707.06690
序言
最近把之前写综述看的一百多篇paper整理了一下,然后准备抽几篇感觉不错的写点详细的笔注,这篇是讲知识图谱补全中关系路径方法比较好的一篇,看下来感觉的确方法是有创新性的,一些想法很值得借鉴。
最近走回正轨,身体仍然处于恢复期,虽然现在情势并不太乐观,但是仍然要做好充分的准备,万一上半年有比赛能参加是一定要去的,只是一个寒假长了10斤(68kg$\\rightarrow$73kg),压力特别大,很难回到去年年底时的巅峰状态了,返校半个多月基本每天都有训练,耐力始终上不去,实在是令人很不快。老王一个寒假没怎么练,拉垮得比我还厉害,不过他还是报了上半年的厦马,于是我也跟着报了个名,反正大概率也抽不上,希望四月份的上海半马和扬州的世马测试赛能办得了就好了。
慢慢来吧,事情都是急不得的了。
文章目录
- 序言
- 摘要 Abstract
- 1 引入 Introduction
- 2 相关工作 Related Work
- 3 方法 Methodology
- 4 实验 Experiment
- 5 结论与未来工作 Conclusion and Future Work
- 致谢 Acknowledgments
- 参考文献
摘要 Abstract
- 本文研究如何在大规模的知识图谱中进行推理。
- 本文提出一种强化学习框架用于学习多级关系路径(multi-hop relational paths),具体而言,强化学习的状态(state)是基于知识图谱嵌入(knowledge graph embeddings)的连续型向量,智能体是基于策略的(policy-based agent),即根据策略网络(policy network)进行更新迭代。具体而言,智能体在知识图谱向量空间中通过采样最可信的关系来扩展其路径以实现推理。
- 相较于之前的工作,本文在强化学习的奖励函数(reward function)中考虑了精确性(accuracy),多样性(diversity),功效性(efficiency)。
- 实验表明,本文提出的方法在Freebase与NELL(Never-Ending Language Learning datasets)两个知识图谱数据集上比一种基于路径排序(path-ranking)的算法以及一种知识图谱嵌入方法要表现得更好。
1 引入 Introduction
-
本文的研究是多级推理(multi-hop reasoning),即根据知识图谱中的实体关系信息学习得到显式推理公式(explicit inference formulas)。比如,若知识图谱中包含如下两组事实:
- 内马尔效力于巴塞罗那;
- 巴塞罗那属于西甲联盟;
则机器应当能够学习得到如下的公式:
playerPlaysForTeam ( P , T ) ∧ teamPlaysInLeague ( T , L ) ⇒ playerPlaysInLeague ( P , L ) \\textplayerPlaysForTeam(P,T)\\wedge\\textteamPlaysInLeague(T,L)\\Rightarrow \\textplayerPlaysInLeague(P,L) playerPlaysForTeam(P,T)∧teamPlaysInLeague(T,L)⇒playerPlaysInLeague(P,L)
在测试过程中,通过嵌入学习到的公式,系统能够自动推断出实体间可能存在的缺失关系(即知识图谱补全)。 -
参考文献[16 17 18]中提出的路径排序算法(Path-Ranking Algorithm,下简称为PRA)是在大规模知识图谱中学习推理路径的流行方法。PRA使用的是随机游走(random-walk)策略,智能体通过执行多次有限制的深度优先搜索(bounded depth-first search)来寻找关系路径。
然后与弹性网络(elastic-net,即在损失函数中同时加入一次正则项与二次正则项)相结合,PRA通过监督学习挑选出更合理的路径。
然而PRA是在全离散空间(fully discrete space)进行搜索,因此它难以评估与比较知识图谱中相似的实体与关系。
-
本文提出使用强化学习来搜索关系路径以实现多级推理。相较于PRA,本文使用的参考文献[2]中基于翻译的(translation-based)嵌入方法来编码强化学习智能体的连续状态,并在知识图谱的向量空间环境(environment)中进行推理。
智能体通过采样关系不断扩展其路径,为确保智能体更好地学习关系路径,本文使用参考文献[22]中提出的策略梯度训练(policy gradient training)方法,并在强化学习的奖励函数中引入精确性,多样性,功效性三个新指标,最终在Freebase与NELL知识图谱数据集(参考文献[3])上取得了更好的实验结果。
-
本文的贡献有三:
- 首次将强化学习方法用于学习知识图谱中的关系路径;
- 通过在奖励函数引入三个新指标,使得路径发现更加灵活与可控;
- 本文的方法可以推广到大规模的知识图谱中,并依然表现得比PRA更好;
2 相关工作 Related Work
-
PRA起源于参考文献[16 17 18],此后有学者对其做出改进:
- 参考文献[6 7]在PRA中引入计算特征相似度。
- 参考文献[26]提出一种递归的随机游走方法来结合知识图谱与文本,该方法对逻辑程序(logic program)进行结构化学习(structure learning),并同时从文本中挖掘信息。
- 随机游走的问题在于超节点(supernodes)与大量的公式连接形成庞大的扇出区(fan-out area,通常指深度学习中下一层的节点数),使得推理缓慢且精确性降低。(这个其实还是易于理解的,即随机游走可能会学习得到大量潜在的关系路径,神经网络需要对这些路径进行评估,比如最后以softmax层输出多分类结果,则输出的节点数会非常庞大,分类精确性自然很差)
-
关于多级推理的深度学习方法:
- 参考文献[25]提出一种卷积神经网络模型的解决方案,其建立的模型基于句法依存路径(lexicalized dependency paths),因句法解析的错误使得网络传播中也会发生错误。
- 参考文献[9]使用知识图谱嵌入来回答路径查询(path queries)。
- 参考文献[29]提出一种卷积神经网络模型来建模关系路径用于知识图谱补全,但是它训练太多的小模型,因而无法推广到大规模的情形。
- 近期大部分的知识图谱推理方法(参考文献[5 23])仍然依赖于学习PRA路径,且只是在离散空间中搜索。
-
参考文献[19]提出的神经符号机器(Neural symbolic machine,下简称为NSM)也采用了强化学习方法,但是与本文的研究有所区别。NSM是学习复合程序(compose program)用以对自然语言问题进行作答,本文的模型则是用以向知识图谱中添加新的事实(即知识图谱补全)。
NSM学习生成得到一系列的行为(actions),并将它们依次合并作为可执行程序(executable program),NSM的行为空间(action space)是一系列预先设置号的标记,而本文的目标是发现推理路径,因此行为空间即知识图谱中的关系空间。
参考文献[12]中提出得是一个与NSM类似的框架,目前已经被应用于可视化的推理任务中。
3 方法 Methodology
- 再次强调:本文所要解决的多级推理问题是预测实体对之间可能缺失的关系。
- 本文将路径发现问题抽象为序列决策制定问题,从而可以被强化学习方法解决。
- 本文提出的强化学习框架中的智能体是基于策略的(policy-based),在知识图谱向量空间的环境中进行交互,以学习选取得到最可信的推理路径。
- 本节的第二小节与第三小节中将分别阐述模型训练以及如何根据智能体找到的路径进行关系推理的一种路径约束搜索算法(path-constrained search algorithm)。
3.1 关系推理的强化学习 Reinforcement Learning for Relation Reasoning
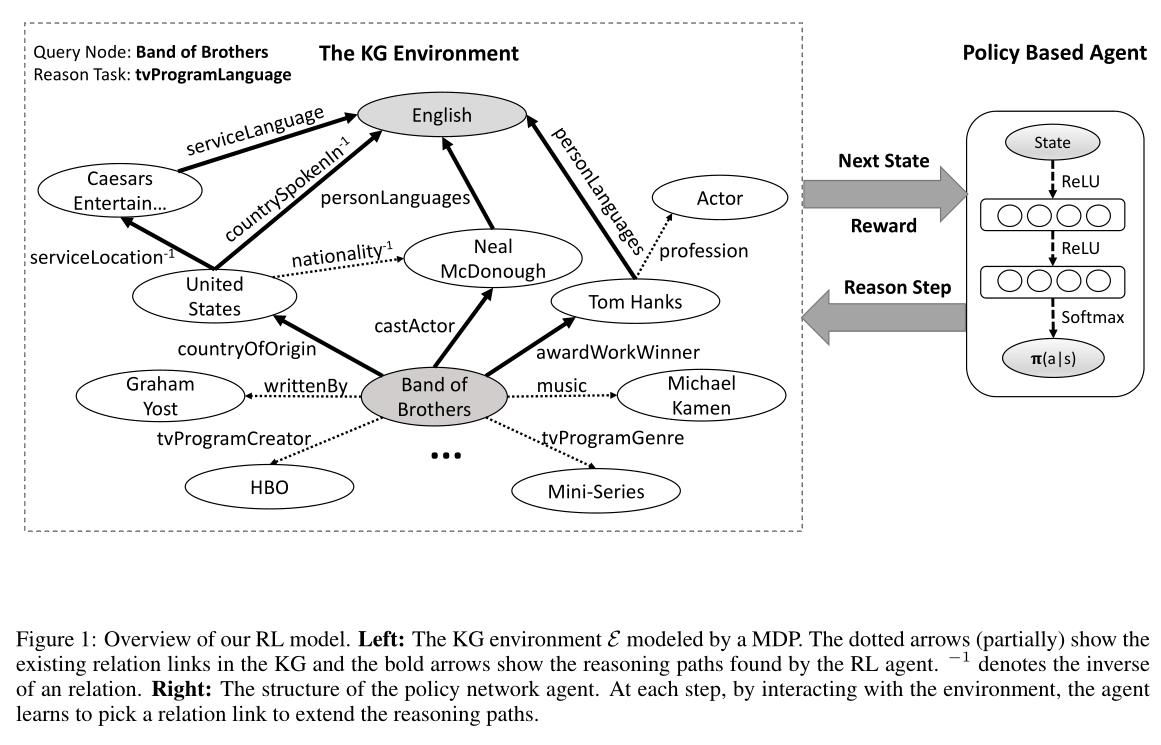
-
根据Figure 1中的描述,强化学习模型由两部分构成:
-
外部环境 E \\mathcalE E:确定智能体与知识图谱的动态交互,由马尔克夫决策过程(Markov Decision Process,下简称为MDP)建模得到。
具体而言,四元组 ( S , A , P , R ) (\\mathcalS,A,P,R) (S,A,P,R)用于定义表示MDP,其中 S \\mathcalS S表示连续的状态空间, A = a 1 , a 2 , . . . , a n \\mathcalA=\\a_1,a_2,...,a_n\\ A=a1,a2,...,an是一系列可用的行为, P ( S t + 1 = s ′ ∣ S t = s , A t = a ) \\mathcalP(S_t+1=s'|S_t=s,A_t=a) P(St+1=s′∣St=s,At=a)表示转移概率矩阵(transition probability matrix), R ( s , a ) \\mathcalR(s,a) R(s,a)表示每个 ( s , a ) (s,a) (s,a)对的奖励函数。
-
智能体:由策略网络(policy network)表示,策略函数为 π θ ( s , a ) = p ( a ∣ s ; θ ) \\pi_\\theta(s,a)=p(a|s;\\theta) πθ(s,a)=p(a∣s;θ),即将状态向量映射为一个随机策略(stochastic policy)。其中, θ \\theta θ表示神经网络参数,使用随机梯度下降法(stochastic gradient descent,下简称为SGD)进行迭代更新。
-
-
与参考文献[21]中提出的DQN模型相比,基于策略的强化学习方法更适合于本文所研究的知识图谱场景。原因有二:
- 知识图谱中的路径发现问题,通常涉及的行为空间是非常大的,因此容易使得DQN模型难以收敛;
- DQN模型通常基于价值(Q值)得到一个贪心的策略,策略网络则能够学习随机策略以防止智能体陷于某个中间态(intermediate state)无法继续更新。
-
强化学习框架的组成:
-
行为(Actions):给定实体对 ( e s , e t ) (e_s,e_t) (es,et)和它们的关系 r r r,我们希望智能体能够找到最富含有用信息的(informative)路径来链接该实体对。
从源实体 e s e_s es开始,智能体利用策略网络来选取最可信的关系来扩展其路径,直到抵达目标实体 e t e_t et为止。为使策略网络的输出维数相一致,我们将行为空间定义为知识图谱中的所有关系的集合。
-
状态(States):知识图谱中的实体与关系通常表示为离散符号,如Freebase(参考文献[1])与NELL(参考文献[4])中都包含巨量的三元组,因此想要在状态空间中建模所有的离散符号几乎是不可能的。
于是本文认为可以使用如TransE(参考文献[2])与TransH(参考文献[27])等知识图谱嵌入方法将实体与关系表示为特征向量,以达到降维的目的。此时我们需要记录智能体的当前所在的实体位置以及它下一个即将达到的实体,具体而言:
s t = ( e t , e target − e t ) s_t=(e_t,e_\\texttarget-e_t) st=(et,etarget−et)
其中 e t e_t et表示当前实体的嵌入, e t a r g e t e_\\rm target etarget表示目标实体的嵌入,初始状态下有 e t = e s o u r c e e_t=e_\\rm source et=esource。注意这里并没有将关系嵌入包含在状态中,因为关系嵌入在路径发现过程中是一个常数,对模型训练是没有帮助的。然而我们还是发现如果使用一系列正样本来训练智能体用于发现某个特定的关系,智能体也可以发现关系的语义(即关系嵌入)。
-
奖励(Rewards):为了使得智能体能够更好的找到预测路径,本文在奖励函数中引入新指标指标。
-
全局精确性(Global accuracy):前面提到行为空间是非常庞大的,因此可想而知智能体做出的大部分序列决策都是错误的,错误的路径会导致路径长度成指数级增长,因此定义如下的指标:
r G L O B A L = + 1 if the path reaches e t a r g e t − 1 otherwise r_\\rm GLOBAL=\\left\\\\beginaligned&+1&&\\textif the path reaches e_\\rm target\\\\&-1&&\\textotherwise\\endaligned\\right. rGLOBAL=+1−1if the path reaches etargetotherwise
即只要路径最终找到了目标实体,就赋值为正,否则赋值为负。 -
路径功效性(Path efficiency):就关系推理任务而言,本文发现短路径往往比长路径提供更可靠的推理证据。因此定义如下的指标:
r E F F I C I E N C Y = 1 length ( p ) r_\\rm EFFICIENCY=\\frac1\\textlength(p) rEFFICIENCY=length(p)1
其中路径 p p p定义为一系列关系的序列: r 1 → r 2 → . . . → r n r_1\\rightarrow r_2\\rightarrow ...\\rightarrow r_n r1→r2→...→r以上是关于论文阅读强化学习与知识图谱关系路径发现的主要内容,如果未能解决你的问题,请参考以下文章3.知识图谱相关学习资料汇总,提供系统化的知识图谱学习路径。一份详细的指南,补全你知识的漏洞
大厂技术实现 | 爱奇艺文娱知识图谱的构建与应用实践 @自然语言处理系列
-
-