大话实时计算
Posted 彭宇成
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大话实时计算相关的知识,希望对你有一定的参考价值。
上期内容回顾
第一期经典问题回顾与解读
观点:大数据 = hive sql ≈ java web
理由:大数据不就是写一些hive sql 搞搞ETL,做几张统计分析用的简单报表 - 这个java web 也可以做啊,多简单!
解读:大数据与java web完全不同;大数据远非hive sql这种单一的传统的离线分析技术,还有实时计算,机器学习 。。。
第一,大数据跟java web完全不同 - 即使业务只是出报表,做分析!?你要面对的是海量数据,是百亿级、千亿级的数据量!java web 能处理么?用大数据技术,你要考虑分布式海量数据存储,大规模分布式并行计算,要理解hadoop和spark底层的复杂技术原理,解决各种大数据场景下出现的问题,最后才能针对海量数据产出一些普通的业务报表和分析报告。因此,单从做报表分析来说,真正海量数据的报表分析也不简单 - 而这,用传统的java web技术也根本做不到?数据没法存,更没法快速的取。
从业务上来考虑,如何能够对大量的数据进行大型数据仓库的建模?如何能够构建360度全方位分析的数据分析平台?如何能够依靠构建出来的数据分析平台真正对公司的产品设计、运营管理、企业管理提供真正有价值的支撑性分析报告?如何能够对海量数据做到有效的数据治理与数据管理?
第二,大数据 = hive sql ? 产生这种误解,主要是当前金融中心数据量并不大(TB级别,具体多少有待进一步统计),所以用hive 跑跑sql语句,也不会碰到什么大问题。虽然在用hadoop,但是并不能称得上真正做大数据?做出来的东西没有太大的意义,技术上也碰不到什么问题。大数据远非hive sql,还有实时计算,机器学习等(再说,越来越多的大公司正在用spark sql +hive[数据仓库] 替代传统的hive sql 做离线分析)
注: 以上内容大部分摘自中华石杉 相关言论,致谢。
结论
大数据真正能给部门带来实际价值任重道远:需要公司高层更多理解,更多支持,也需要猿友们持久的努力!
本期内容摘要
大话实时计算二 之 scala光速入门与案例解读spark streaming
主题
- 函数式编程初体验与 Scala快速入门
- Spark运行时状态图解与RDD经典算子演练
- 案例解读spark streaming
场景
地 点:B604
主 讲:Mr.Snail
主 题:scala光速入门与案例解读spark streaming
时 间:2016/10/26 19:00 - 20:00
摘要
1、函数式编程初体验与 Scala光速入门
1.1 函数式编程 VS 过程式编程 VS 面向对象编程
? 现在有这样一个数学表达式:
(1 + 2) * 3 - 4过程式编程:
var a = 1 + 2;
var b = a * 3;
var c = b - 4;函数式编程:
var result = subtract(multiply(add(1,2), 3), 4);面向对象编程:
public class Calculator
public int add(int i,int j)(return i+j;)
main
int result = new Calculator().subtract(new Calculator().multiply(new Calculator().add(1,2),3),4);
1.2 Scala光速入门
注 :代码解读函数式编程在scala中的应用
2、Spark运行时状态图解与RDD基本操作
2.1 运行时状态图解
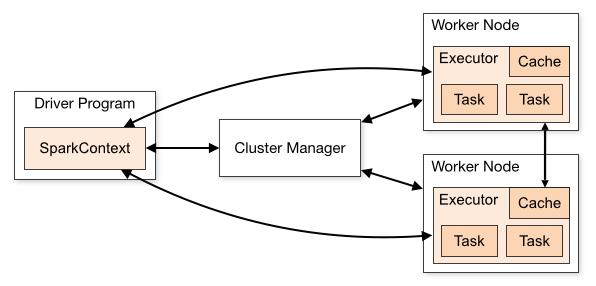
2.1.1 基本术语解读
- local
- Standalone
- Apache Mesos
- Hadoop YARN
…

2.2 RDD基本操作
(记得加上那张图片:两态)
注:
1、通过 spark-submit 演示常用算子的用法(word-count案例)
2、通过webUI进一步解读程序
3、案例解读 spark streaming
注 : 0、介绍kafka的基本使用 1、说明窗口函数的应用 2、代码走读 word-count-online.java
总结
God bless me
参考
以上是关于大话实时计算的主要内容,如果未能解决你的问题,请参考以下文章