基础I/O
Posted 任我驰骋°
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了基础I/O相关的知识,希望对你有一定的参考价值。
基础IO
前言
文件 = 内容+属性
FIFE*, C
stdin: 标准输入,键盘
stdout:标准输出,显示器
stderr:标准错误,显示器
Linux 下一切皆文件。
为什么语言都要开放这些标准流?
语言也是需要进行交互的。
一、回顾C文件接口
写文件
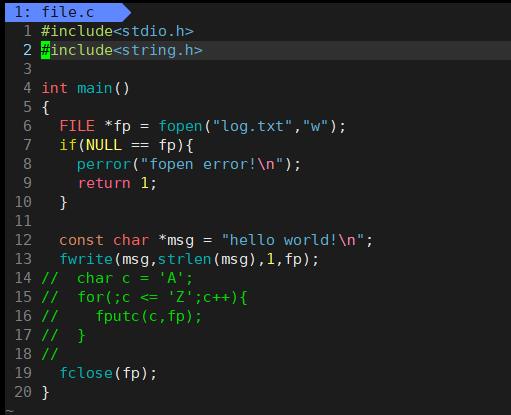
将内容写到log.txt中,

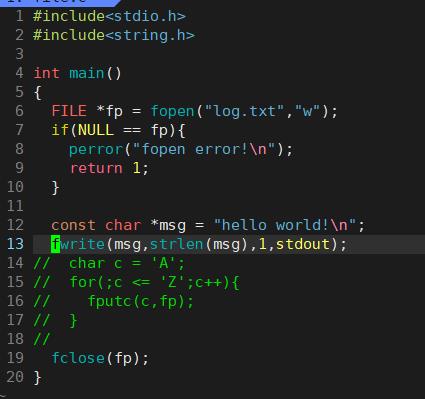
将内容输出到显示器中,将fp改为stdout即可。

stdin & stdout & stderr
C默认会打开三个输入输出流,分别是stdin, stdout, stderr
仔细观察发现,这三个流的类型都是FILE*, fopen返回值类型,文件指针
二、系统文件I/O
操作文件,除了上述C接口(当然,C++也有接口,其他语言也有),我们还可以采用系统接口来进行文件访问,先来直接以代码的形式,实现和上面一模一样的代码。
接口介绍
open
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
int open(const char *pathname, int flags);
int open(const char *pathname, int flags, mode_t mode);
pathname: 要打开或创建的目标文件
flags: 打开文件时,可以传入多个参数选项,用下面的一个或者多个常量进行“或”运算,构成flags。
参数:
O_RDONLY: 只读打开
O_WRONLY: 只写打开
O_RDWR : 读,写打开
这三个常量,必须指定一个且只能指定一个
O_CREAT : 若文件不存在,则创建它。需要使用mode选项,来指明新文件的访问权限
O_APPEND: 追加写
返回值:
成功:新打开的文件描述符
失败:-1
mode_t理解:直接 man 手册,比什么都清楚。
open 函数具体使用哪个,和具体应用场景相关,如目标文件不存在,需要open创建,则第三个参数表示创建文件的默认权限,否则,使用两个参数的open。
0 & 1 & 2
Linux进程默认情况下会有3个缺省打开的文件描述符,分别是标准输入0, 标准输出1, 标准错误2.
0,1,2对应的物理设备一般是:键盘,显示器,显示器所以输入输出还可以采用如下方式:
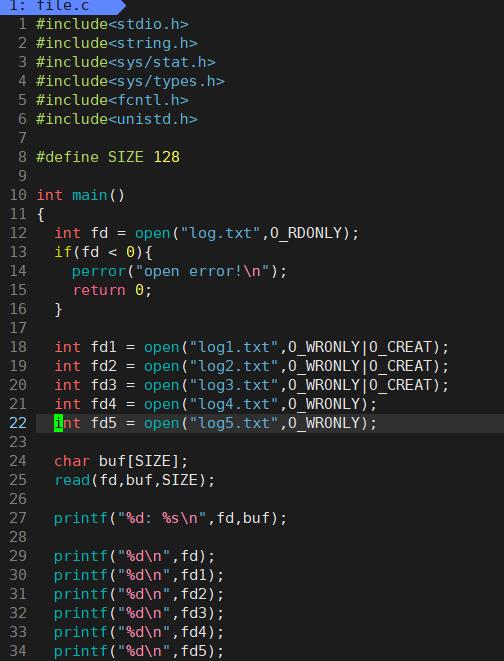
运行的结果为:
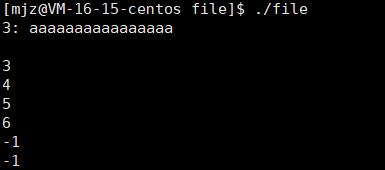
可以看到这里是直接从3开始的,为什么没有0,1,2呢?
因为0,1,2这三个接口是默认被打开的。
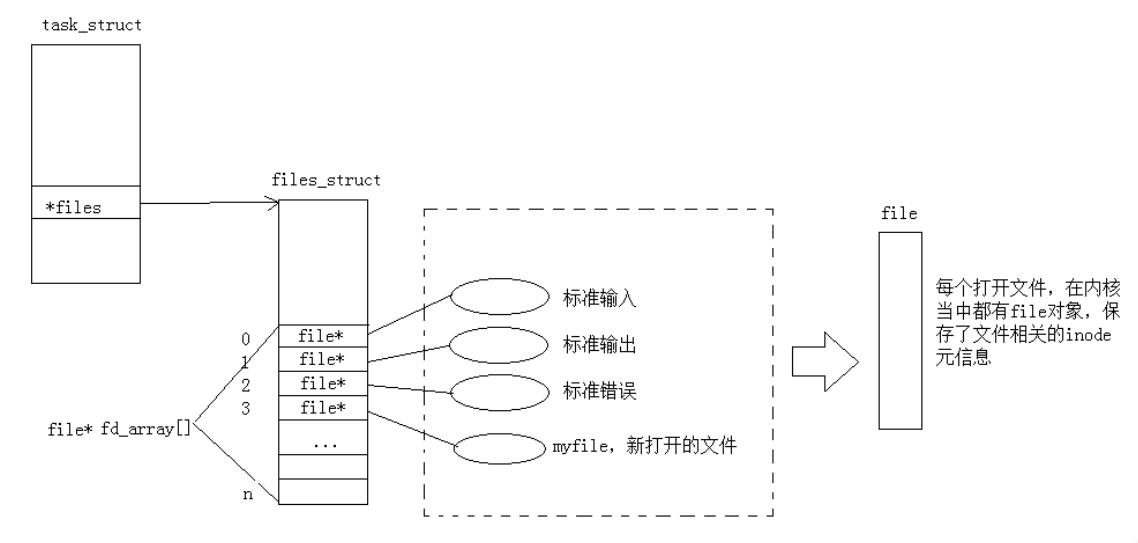
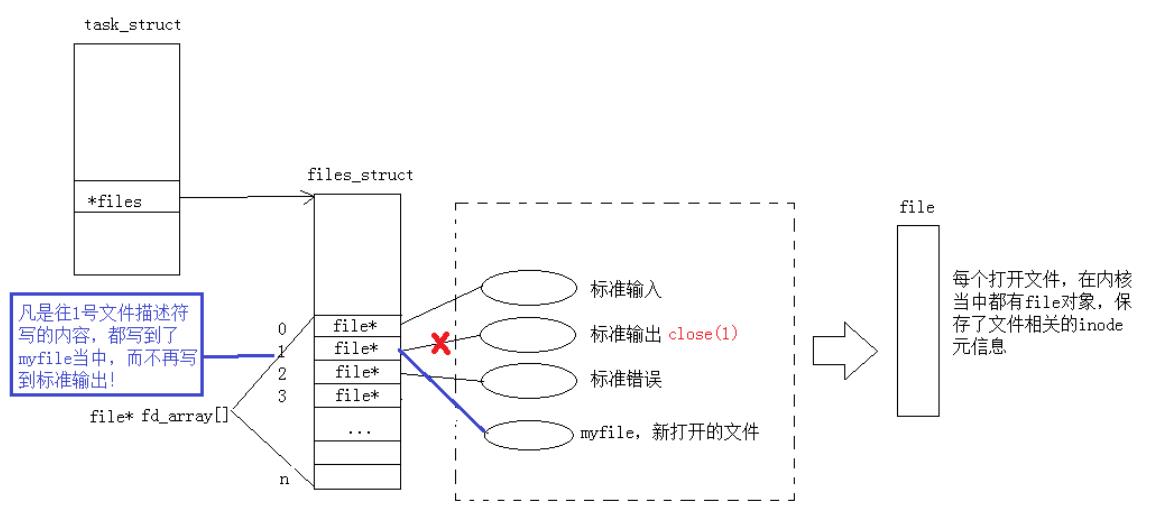
我们现在知道,文件描述符就是从0开始的小整数。当我们一打开文件,操作系统就要创建相应的数据结构来描述目标文件。于是就有了file结构体。它表示一个已经打开的文件对象。而进程执行的open系统调用,必须让进程和文件关联起来。于是每一个进程都有一个*file指针,只想一张表files_struct,该表最主要的就是包含着一个指针数组,每一个元素就是一个指向文件打开的指针!所以,本质上文件描述符就是该数组的下标。所以用文件描述符就可以找到响应的文件。
文件描述符的分配规则
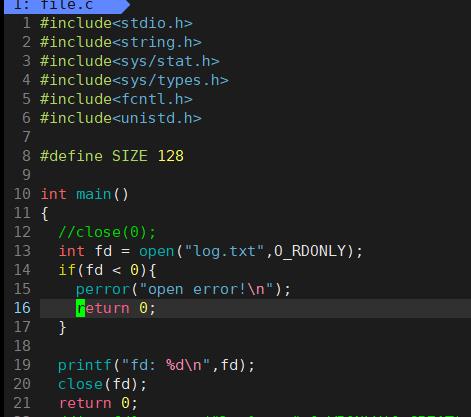

我们发现文件描述符默认的输出是3。‘
关闭0的话再看:
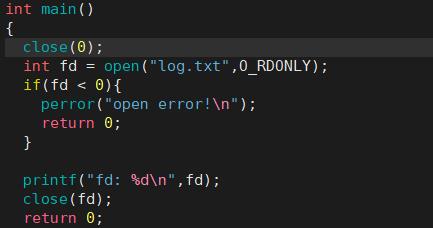

发现是结果是: fd: 0 或者 fd 2 可见,文件描述符的分配规则:在files_struct数组当中,找到当前没有被使用的最小的一个下标,作为新的文件描述符。
重定向
那如果关闭1呢?看代码:
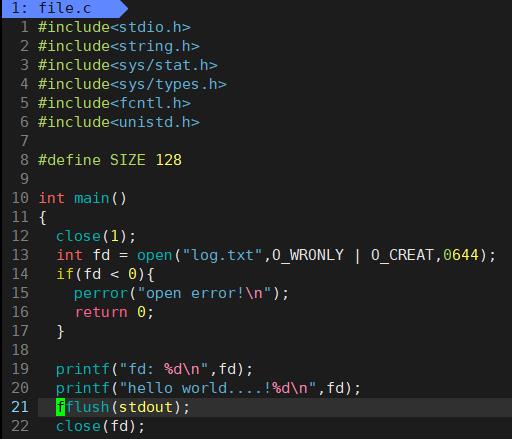

可以看到应该要输出在显示屏上的内容输出到了log.txt文件中,这就是重定向输出。其中,fd=1。这种现象叫做输出重定向。常见的重定向有:>, >>, <。
那么,重定向的本质是什么呢?
三、FIFE缓冲区
因为IO相关函数与系统调用接口对应,并且库函数封装系统调用,所以本质上,访问文件都是通过fd访问的。
所以C库当中的FILE结构体内部,必定封装了fd。
先来看代码:
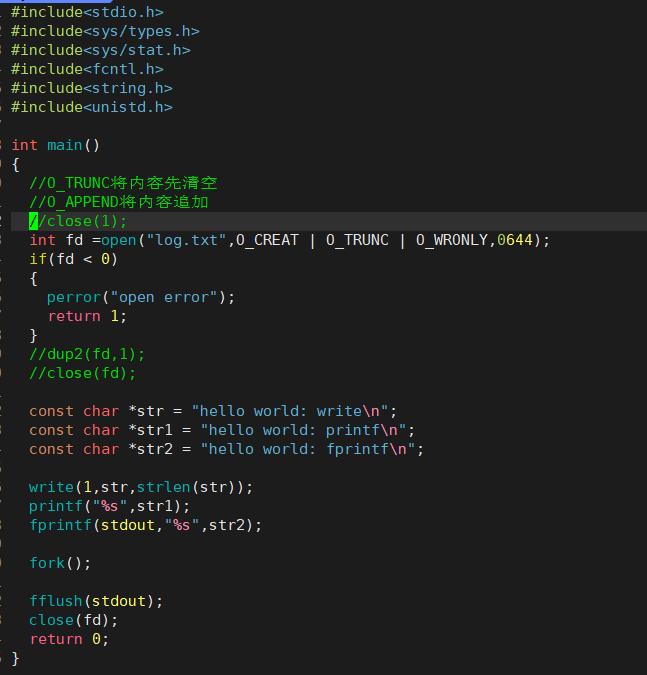

这里输出到显示屏上时都只输出一次。
这里我们再把close(1)打开。
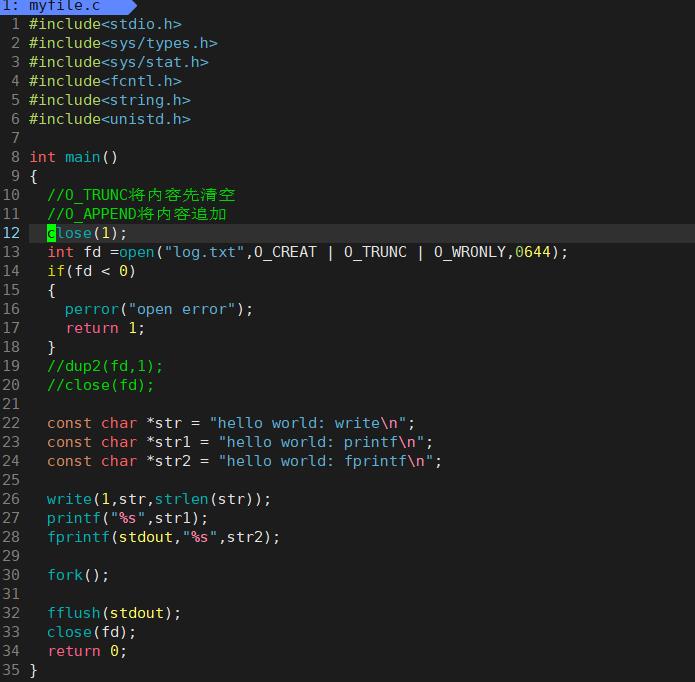
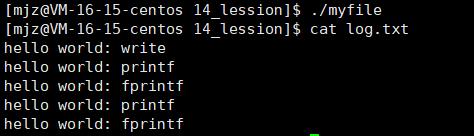
这里我们看到write打印了一次而printf和fprintf打印了两次。
由此我们总结:
printf,fprintf是库函数。
write是系统调用。
缓冲区
显示器:行缓冲(遇到\\n就直接打印)
文件:全缓冲(最后全一起打印)
而我们放在缓冲区中的数据,就不会被立即刷新,甚至fork之后。
但是进程退出之后,会统一刷新,写入文件当中。
但是fork的时候,父子数据会发生写时拷贝,所以当你父进程准备刷新的时候,子进程也就有了同样的一份数据,随即产生两份数据。
write 没有变化,说明没有所谓的缓冲。
所以用户级缓冲区是C标准库提供的。
重定向:会影响缓冲方式。
C语言有缓冲区其本质上可提高程序的效率。 printf fwrite 是库函数, write 是系统调用,库函数在系统调用的“上层”, 是对系统调用的“封装”,但是 write 没有缓冲区,而 printf fwrite 有,足以说明,该缓冲区是二次加上的,又因为是C,所以由C标准库提供。
使用 dup2 系统调用
先看段代码:
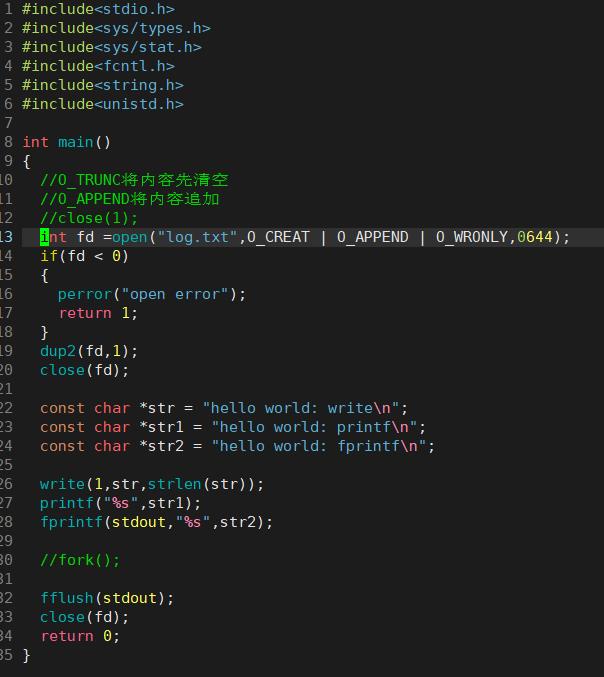
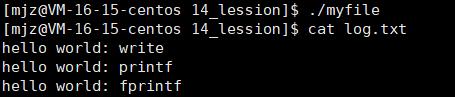
printf是C库当中的IO函数,一般往 stdout 中输出,但是stdout底层访问文件的时候,找的还是fd:1, 但此时,fd:1下标所表示内容,已经变成了myfile的地址,不再是显示器文件的地址,所以,输出的任何消息都会往文件中写入,进而完成输出重定向。
其中O_TRUNCS将内容先清空
O_APPEND将内容追加
四、理解文件系统
文件=属性+内容
inode 只有1个
属性集合
block 可有n个
内容
filesystem
//基本情况
//空间一共是多大
//已经使用&&没有被使用
//inode
//block
//group
当我们使用ls -l读取存储在磁盘上的文件信息,然后显示出来时,其内部工作原理如下图所示:
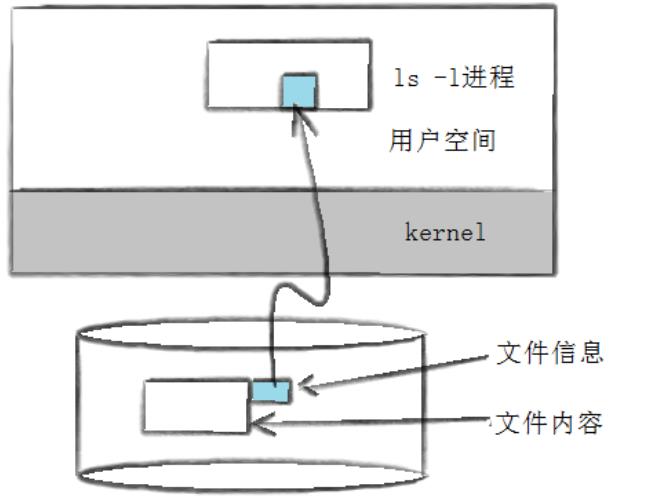
通过ls -l进程获得文件的信息内容。
inode
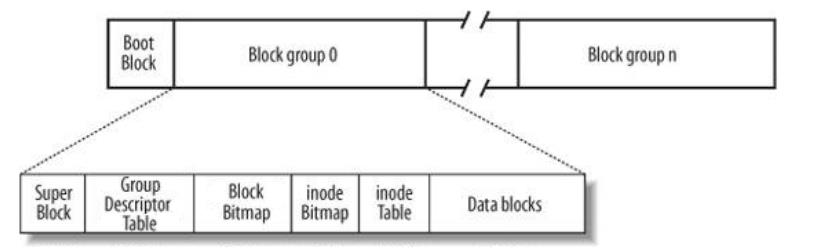
inode:文件的属性 文件:inode==1:1
Data blocks:数据 文件:inode:datablock == 1:1:n
inode必须包含datablocks对应的映射关系
unsigned map[n]
inode id:表示一个inode
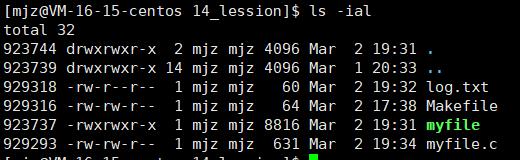
前面的923744就是文件的inode
一个文件的inode是多少取决于它在位图上的位置。inode bitmap。
在硬盘中创建一个文件的步骤为:先找到分区和块组,在i位图上找到一个未被使用的inode,然后再把文件的属性信息填到inode中映射的数据块上。
另外,目录也是文件=inode+数据块(文件名:inode id)
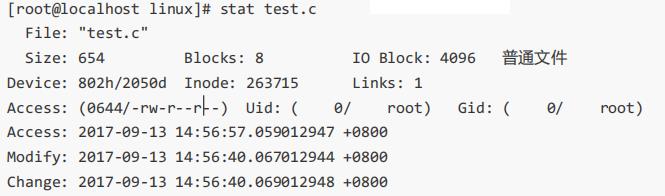
stat命令:能够看到更多信息
五、软硬链接
软连接:具有独立的inode,是一个独立的文件。软链接可以直接把需要运行的项目进程建立连接使运行变得方便:
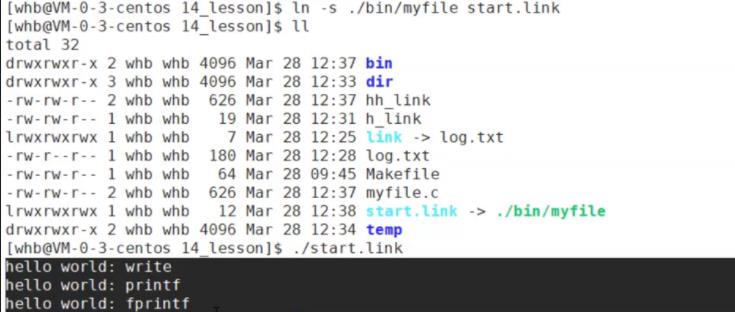
硬链接:和指向的文件共享同一个inode,不是一个独立的文件。相当于一个相同的文件的另一个名字,与原文件建立一个链接。
六、动静态库
静态库与动态库
静态库(.a):程序在编译链接的时候把库的代码链接到可执行文件中。程序运行的时候将不再需要静库。
库静态链接,将对应代码拷贝进bin,体积比较大,bin可移植性强。链接的时候纳入进来,可能比较占用资源(硬盘,内存)。
动态库(.so):程序在运行的时候才去链接动态库的代码,多个程序共享使用库的代码。体积比较小。
生成静态库

现将静态库打包,然后在查看静态库中的目录列表:

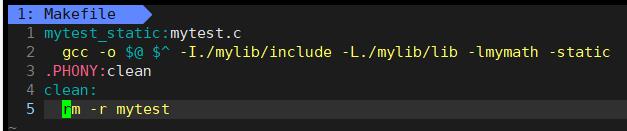
这里-I选项可查找到头文件所在目录,-L可查找到lib文件所在目录,最后生成静态库文件。
生成动态库
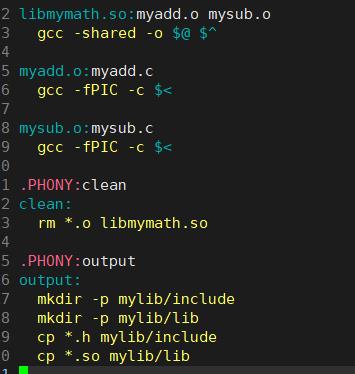
其中生成动态库时要注意以下三点:
shared: 表示生成共享库格式
fPIC:产生位置无关码(position independent code)
库名规则:libxxx.so
在Makefile中配置make output发布版本可直接生成mylib的文件库。
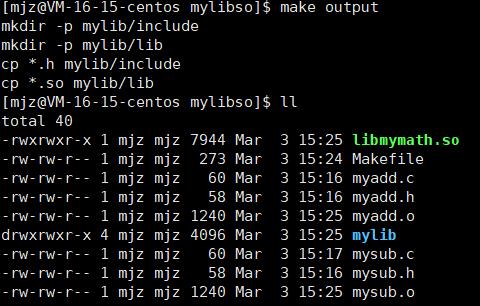
使用动态库
1、拷贝.so文件到系统共享库路径下, 一般指/usr/lib。
2、更改 LD_LIBRARY_PATH。

可看到所依赖的库为我们自己写的动态库。
3、ldconfig 配置/etc/ld.so.conf.d/,ldconfig更新。
以上是关于基础I/O的主要内容,如果未能解决你的问题,请参考以下文章