实现DDD领域驱动设计: Part 2
Posted dotNET跨平台
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了实现DDD领域驱动设计: Part 2相关的知识,希望对你有一定的参考价值。
原文链接: https://dev.to/salah856/implementing-domain-driven-design-part-ii-2i36
实现:构建块
这是本系列的重要部分。我们将通过示例介绍和解释一些明确的规则。在实现领域驱动设计时,你可以遵循这些规则并应用到你的解决方案中。
示例
示例将使用GitHub使用的一些概念,例如你已经熟悉的问题、存储库、标签和用户。
下图显示了一些聚合、聚合根、实体、值对象以及它们之间的关系:
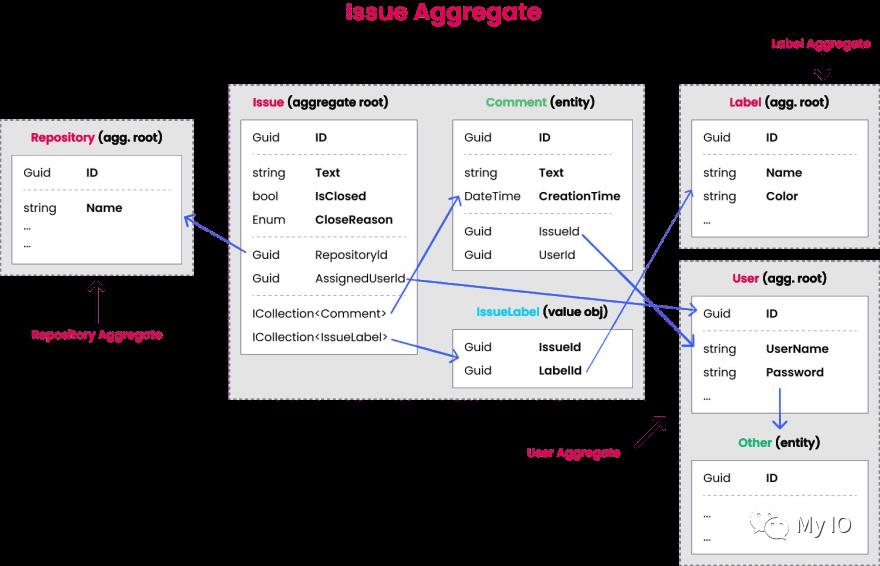
问题聚合由包含评论和问题标签集合的问题聚合根组成。
其他聚合显示很简单,因此我们将关注问题聚合:

聚合
如前所述,聚合是由聚合根对象绑定在一起的一组对象(实体和值对象)。
聚合/聚合根原则
业务规则
实体负责执行与自身属性相关的业务规则。聚合根实体还对其子集合实体负责。
聚合应通过实现领域规则和约束来保持其自身的完整性和有效性。
这意味着,与DTO不同,实体具有实现某些业务逻辑的方法。实际上,我们应该尽可能在实体中实现业务规则。
单个单元
检索聚合并保存为单个单元,其中包含所有子集合和属性。例如,如果你想为问题添加评论,你需要这样做。
从包含所有子集合(评论和问题标签)的数据库中获取问题。
使用Issue类上的方法添加新评论,例如Issue.AddComment(...)。
将问题(包含所有子集合)作为单个数据库操作(更新)保存到数据库中。
对于以前使用EF Core和关系数据库的开发人员来说,这可能看起来很奇怪。
获取所有细节的问题似乎没有必要且效率低下。为什么我们不直接对数据库执行SQL插入命令而不查询任何数据呢?
答案是我们应该实现业务规则并保持代码中的数据一致性和完整性。
如果我们有一个业务规则,比如“用户不能评论锁定问题”,我们如何在不从数据库中检索问题的情况下检查问题的锁定状态?
因此,只有在应用程序代码中有相关对象可用时,我们才能执行业务规则。
示例:向问题添加评论
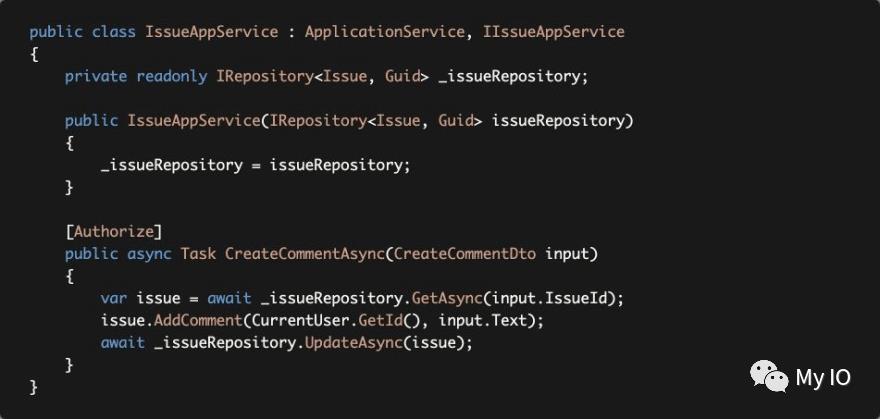
_issueRepository.GetAsync方法默认检索包含所有详细信息(子集合)的问题作为单个单元。
虽然这适用于MongoDB,但你需要为EF Core配置聚合详细信息。但是,一旦你进行了配置,存储库就会自动处理它。
_issueRepository.GetAsync方法提供一个可选参数includeDetails,你可以在需要时传递false以禁用此行为。
Issue.AddComment获取userId和评论文本,实现必要的业务规则并将评论添加到问题的Comments集合中。
最后,我们使用_issueRepository.UpdateAsync来保存更改到数据库。
事务边界
聚合通常被视为事务边界。
如果用例使用单个聚合,将其作为单个单元读取和保存,则对聚合对象所做的所有更改都将作为原子操作一起保存,你不需要显式的数据库事务。
但是,在现实生活中,你可能需要在单个用例中更改多个聚合实例,并且你需要使用数据库事务来确保原子更新和数据一致性。
可序列化
聚合(具有根实体和子集合)应该是可序列化的,并且可以作为单个单元在线传输。
例如,MongoDB在保存到数据库时将聚合序列化为JSON文档,并在从数据库读取时从JSON反序列化。
以下规则可以保证可序列化性。
聚合/聚合根规则和最佳实践
以下规则确保实施上述原则。
仅按ID引用其他聚合
第一条规则说Aggregate只能通过其Id引用其他聚合。这意味着你不能将导航属性添加到其他聚合。
该规则使得实现可序列化原则成为可能。
它还可以防止不同的聚合相互操纵以及将聚合的业务逻辑泄露给彼此。
在下面的示例中,你会看到两个聚合根GitRepository和Issue:
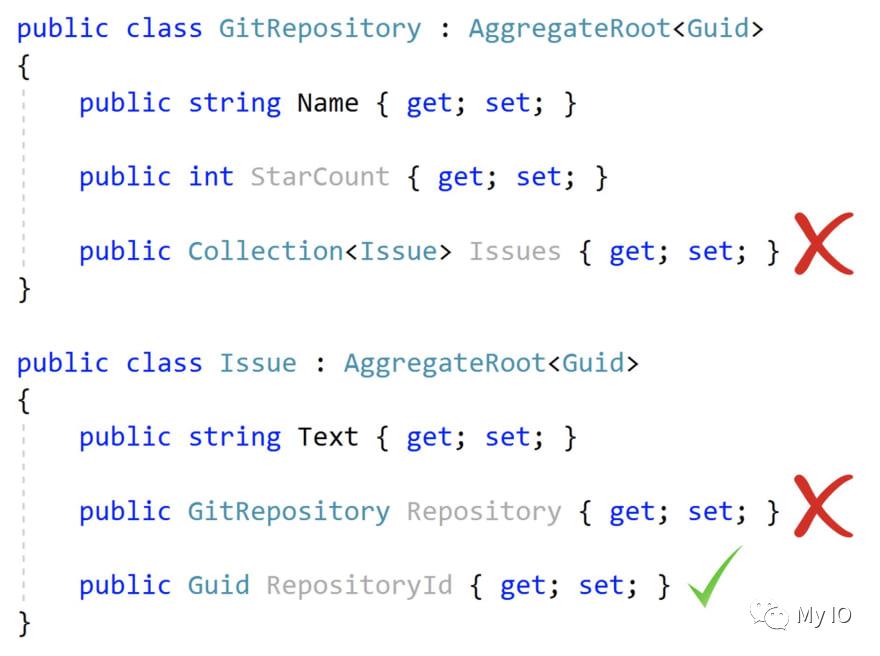
GitRepository不应该有问题的集合,因为它们是不同的聚合。
问题不应具有相关GitRepository的导航属性,因为它是不同的聚合。
问题可以有RepositoryId(作为 Guid)。
因此,当你遇到问题并需要与此问题相关的GitRepository时,你需要通过RepositoryId从数据库中显式查询它。
保持较小的聚合
一种好的做法是使聚合保持简单和小。
这是因为聚合将被加载并保存为单个单元和读/写一个大对象有性能问题。请参见下面的示例:

角色聚合具有一组UserRole值对象,用于跟踪分配给该角色的用户。
请注意,UserRole不是另一个聚合,对于“仅按 Id 引用其他聚合”规则来说这不是问题。
然而,这在实际中是一个问题。在现实生活场景中,一个角色可能被分配给数千(甚至数百万)用户,每当你从数据库中查询角色时,加载数千个项目是一个重要的性能问题(请记住:聚合由其子集合加载为单个单元)。
聚合根/实体上的主键
聚合根通常有一个Id属性作为它的标识符(Primark Key:PK)。我们更喜欢Guid作为聚合根实体的PK。
聚合中的实体(不是聚合根)可以使用复合主键。

Organization有一个Guid标识符(Id)。
OrganizationUser是Organization的子集合,具有由OrganizationId和UserId组成的复合主键。
聚合根/实体的构造函数
构造函数位于实体生命周期开始的位置。精心设计的构造函数有一些职责:
获取所需的实体属性作为参数以创建有效实体。应该强制只传递必需的参数,并且可能将非必需的属性作为可选参数。
检查参数的有效性。
初始化子集合。
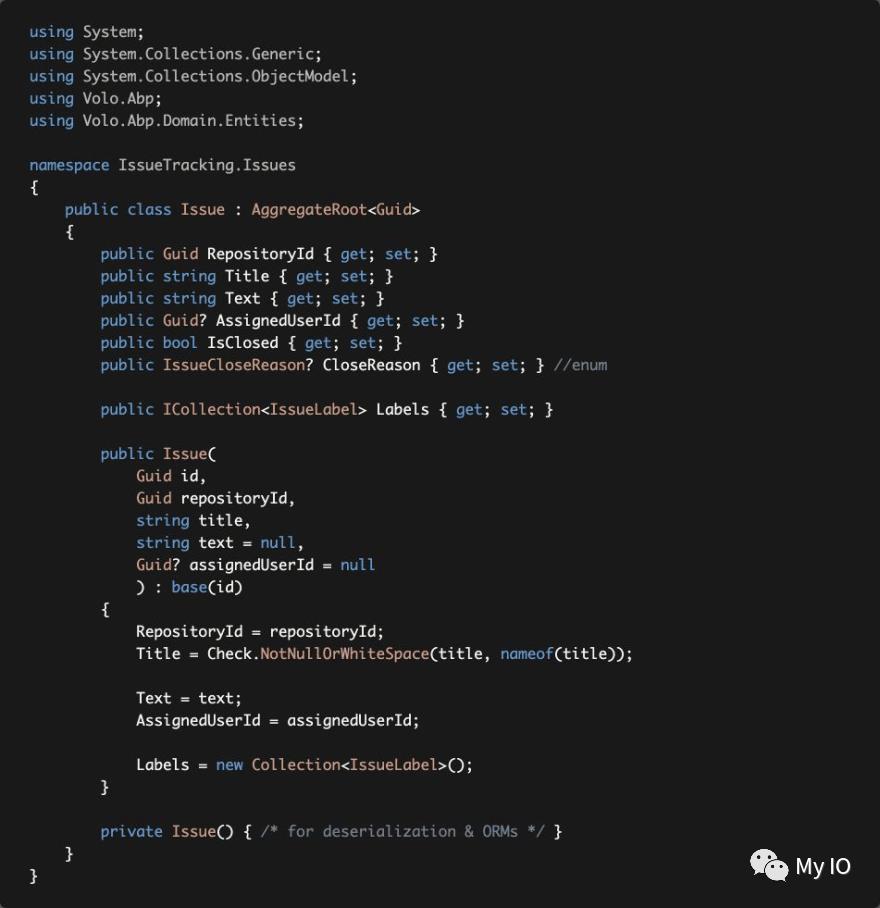
问题类通过在其构造函数中获取最小必需属性作为参数来正确强制创建有效实体。
构造函数验证输入(如果给定值为空,Check.NotNullOrWhiteSpace(...) 将抛出 ArgumentException)。
它初始化子集合,因此在创建问题后尝试使用标签集合时不会出现空引用异常。
构造函数还获取id并传递给基类。我们不会在构造函数中生成Guid,以便能够将此责任委托给另一个服务。
ORM需要私有的空构造函数。我们将其设为私有以防止在我们自己的代码中意外使用它。
实体属性访问器和方法
上面的例子对你来说可能很奇怪!例如,我们强制在构造函数中传递一个非空的Title。
但是,开发人员可以在没有任何控制的情况下将Title属性设置为null。这是因为上面的示例代码只关注构造函数。
如果我们用公共设置器声明所有属性(如上面的示例问题类),我们不能强制实体在其生命周期中的有效性和完整性。
所以:
当你需要在设置该属性时执行任何逻辑时,请为该属性使用私有setter。
定义公共方法来操作这些属性。
示例:以受控方式更改属性的方法

RepositoryId setter 设为私有,在创建问题后无法更改它,因为这是我们在此领域中想要的:无法将问题移动到另一个存储库。
Text和AssignedUserId具有公共设置器,因为它们没有限制。它们可以是null或任何其他值。我们认为没有必要定义单独的方法来设置它们。如果我们以后需要,我们可以添加方法并使设置器私有。由于领域层是一个内部项目,它不会暴露给客户,因此在领域层中进行重大更改不是问题。
IsClosed和IssueCloseReason是成对属性。定义了Close和ReOpen方法来一起改变它们。通过这种方式,我们可以防止无故关闭问题。
实体中的业务逻辑和异常
在实体中实现验证和业务逻辑时,你经常需要管理异常情况。
创建特定领域的例外。
必要时在实体方法中抛出这些异常。
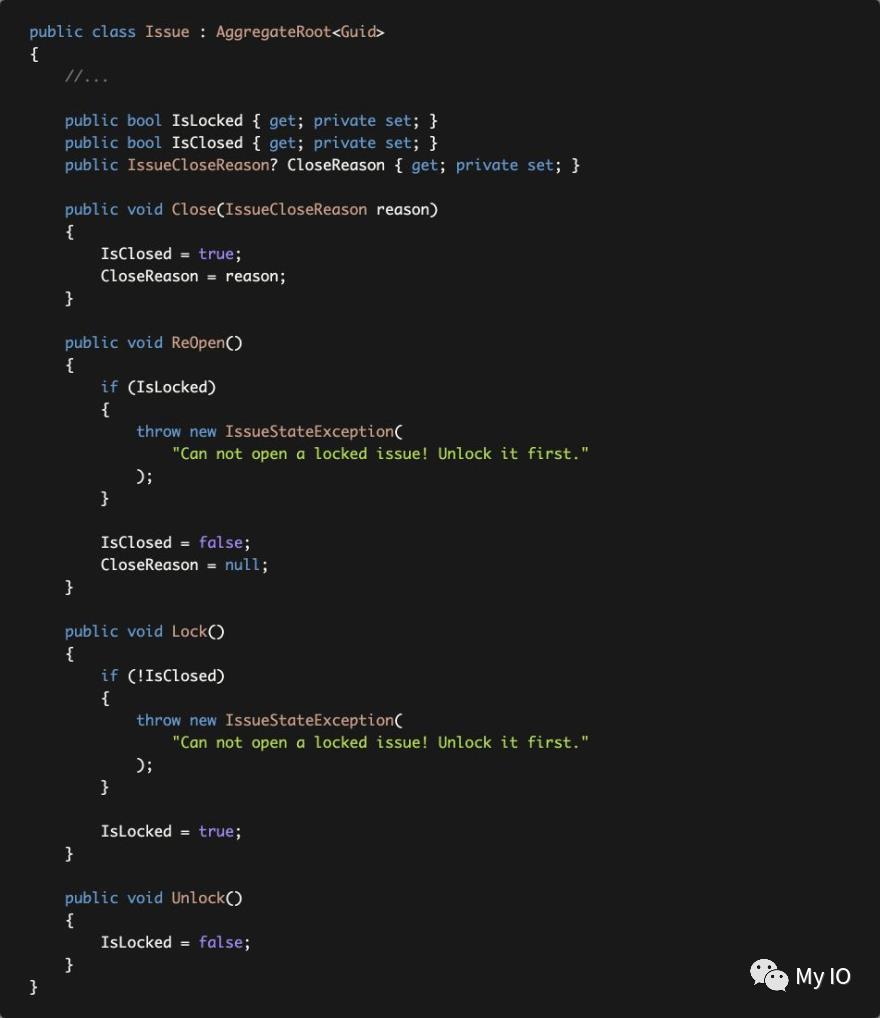
这里有两个业务规则:
已锁定的问题无法重新打开。
你不能锁定未解决的问题。
在这些情况下,问题类会抛出一个IssueStateException强制业务规则:
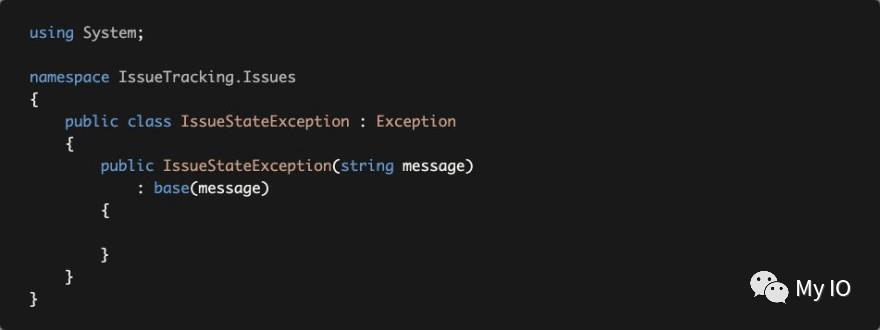
抛出此类异常有两个潜在问题;
如果出现此类异常,最终用户是否应该看到异常(错误)消息?如果是这样,你如何本地化异常消息?你不能使用本地化系统,因为你不能在实体中注入和使用IStringLocalizer。
对于Web应用程序或HTTP API,应该向客户端返回什么HTTP状态代码?
ABP的异常处理系统解决了这些和类似的问题。
示例:使用代码引发业务异常

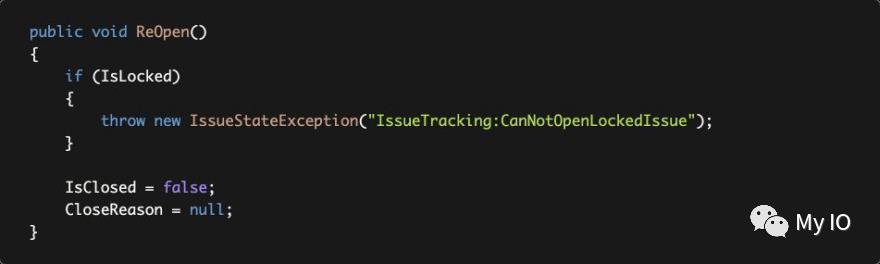
IssueStateException类继承了BusinessException类。对于从BusinessException派生的异常,ABP默认返回403(禁止)HTTP 状态代码(而不是500 - 内部服务器错误)。
该代码用作本地化资源文件中的键以查找本地化消息。
现在,我们可以更改ReOpen方法,如下所示:
并向本地化资源添加一个条目,如下所示:

当你抛出异常时,ABP会自动使用此本地化消息(基于当前语言)向最终用户显示。
异常代码(此处为IssueTracking:CanNotOpenLockedIssue)也被发送到客户端,因此它可以以编程方式处理错误情况。
如果你觉得这篇文章对你有所启发,请关注我的个人公众号”My IO“
以上是关于实现DDD领域驱动设计: Part 2的主要内容,如果未能解决你的问题,请参考以下文章