leetcode之并查集+记忆化搜索+回溯+最小生成树刷题总结1
Posted nuist__NJUPT
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了leetcode之并查集+记忆化搜索+回溯+最小生成树刷题总结1相关的知识,希望对你有一定的参考价值。
leetcode之并查集+记忆化搜索+回溯+最小生成树刷题总结1
1-连接所有点的最小费用
题目连接:题目连接戳这里!!!
思路:cruskal+并查集
根据题意,我们得到了一张 n 个节点的完全图,任意两点之间的距离均为它们的曼哈顿距离。现在我们需要在这个图中取得一个子图,恰满足子图的任意两点之间有且仅有一条简单路径,且这个子图的所有边的总权值之和尽可能小。能够满足任意两点之间有且仅有一条简单路径只有树,且这棵树包含 n 个节点。我们称这棵树为给定的图的生成树,其中总权值最小的生成树,我们称其为最小生成树。
最小生成树有一个非常经典的解法:Kruskal。
我们首先将这张完全图中的边全部提取到边集数组中,然后对所有边进行排序,从小到大进行枚举,每次贪心选边加入答案。使用并查集维护连通性,若当前边两端不连通即可选择这条边。
class Solution
public int minCostConnectPoints(int[][] points)
int n = points.length ;
DisjointSetUnion dsu = new DisjointSetUnion(n) ;
List<Edge> edges = new ArrayList<Edge>() ;
for(int i=0; i<n; i++)
for(int j=0; j<n; j++)
edges.add(new Edge(dist(points,i,j),i,j)) ;
Collections.sort(edges, new Comparator<Edge>() //对所有边进行由小到大排序
public int compare(Edge edge1, Edge edge2)
return edge1.len - edge2.len ;
) ;
int ans = 0, num = 1 ;
for(Edge edge : edges)
int len = edge.len, x = edge.x, y = edge.y ;
if(dsu.unionSet(x,y))
ans += len;
num ++ ;
if(num == n)
break ;
return ans ;
public int dist(int [][] points, int x, int y)
return Math.abs(points[x][0]-points[y][0])+Math.abs(points[x][1]-points[y][1]) ;
//使用并查集检查是否联通
class DisjointSetUnion
int n ;
int [] f ;
public DisjointSetUnion(int n)
this.n = n ;
this.f = new int [n] ;
for(int i=0; i<n; i++)
f[i] = i ;
public int find(int x)
if(x!=f[x])
f[x] = find(f[x]) ;
return f[x] ;
public boolean unionSet(int x, int y)
int fx = find(x), fy = find(y) ;
if(fx==fy)
return false ;
f[fx] = fy ;
return true ;
class Edge //定义一个边类
int len, x, y ;
public Edge(int len, int x, int y)
this.len = len ;
this.x = x ;
this.y = y ;
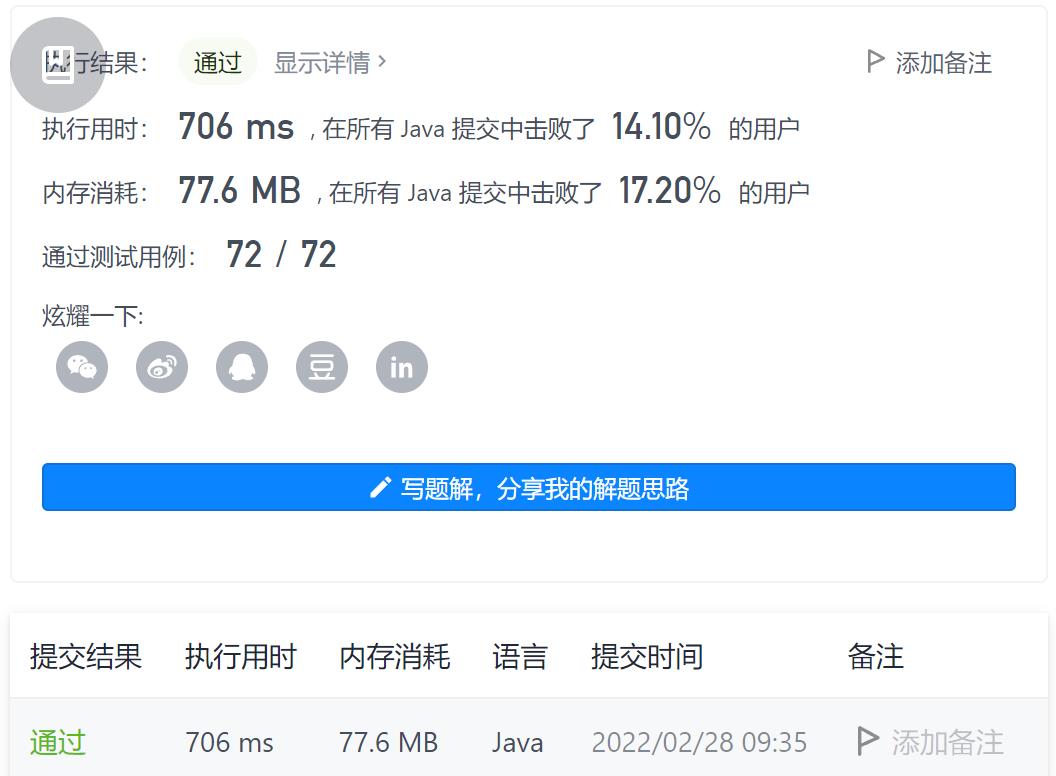
2-最少体力消耗路径
题目链接:题目连接戳这里!!!
思路:并查集
我们将这 m*n 个节点放入并查集中,实时维护它们的连通性。
由于我们需要找到从左上角到右下角的最短路径,因此我们可以将图中的所有边按照权值从小到大进行排序,并依次加入并查集中。当我们加入一条权值为 x 的边之后,如果左上角和右下角从非连通状态变为连通状态,那么 x 即为答案。
class Solution
public int minimumEffortPath(int[][] heights)
int m = heights.length ;
int n = heights[0].length ;
List<int[]> edges = new ArrayList<int[]>() ;
for(int i=0; i<m; i++)
for(int j=0; j<n; j++)
int id = i * n + j ;
if(i>0)
edges.add(new int [] id-n, id, Math.abs(heights[i][j]-heights[i-1][j])) ;
if(j>0)
edges.add(new int [] id-1, id, Math.abs(heights[i][j]-heights[i][j-1])) ;
Collections.sort(edges, new Comparator<int[]>() //按照边的权值由小到大排序
public int compare(int [] edge1, int [] edge2)
return edge1[2] - edge2[2] ;
) ;
UnionFind uf = new UnionFind(m*n) ;
int ans = 0 ;
for(int [] edge : edges)
int x = edge[0], y = edge[1], v = edge[2] ;
uf.unite(x,y) ;
if(uf.connected(0,m*n-1))
ans = v ;
break ;
return ans ;
// 并查集模板
class UnionFind
int[] parent;
int n ;
public UnionFind(int n)
this.n = n;
this.parent = new int[n];
for (int i = 0; i < n; ++i)
parent[i] = i;
public int findset(int x)
return parent[x] == x ? x : (parent[x] = findset(parent[x]));
public boolean unite(int x, int y)
x = findset(x);
y = findset(y);
if (x == y)
return false;
parent[y] = x;
return true;
public boolean connected(int x, int y)
x = findset(x);
y = findset(y);
return x == y;
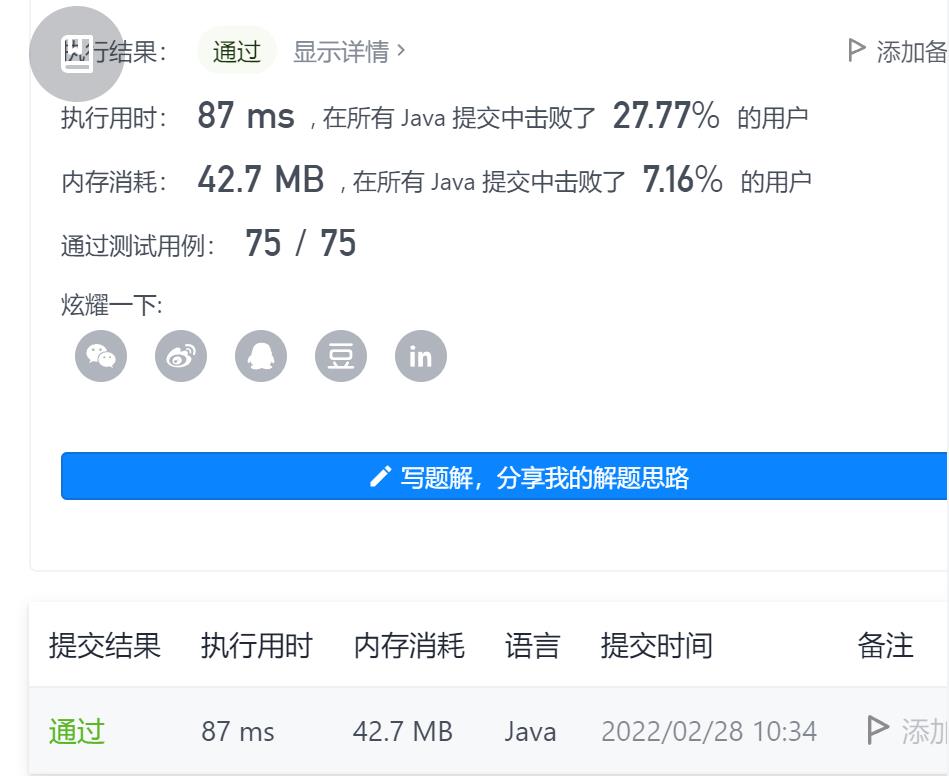
3-交换字符串中的元素
题目链接:题目链接戳这里!!!
思路:并查集
1-并查集对每个元素索引,实现属于同一联通分量元素的合并
2-遍历字符串s,找出每个索引在并查集中的代表元,同属于一个代表元的元素放到一起。
3-对同属于每一个联通分量中的字符按照ASCII码进行升序排序。
4-重新生成一个长度和s相同的字符串,对于每一个索引,查询索引在并查集中的代表元,再从哈希表中获得这个代表元对应的字符集列表,从中移除 ASCII 值最小的字符依次拼接起来。
public class Solution
public String smallestStringWithSwaps(String s, List<List<Integer>> pairs)
if (pairs.size() == 0) //没有交换
return s;
int n = s.length() ;
UnionFind uf = new UnionFind(n) ;
for(int i=0; i<pairs.size(); i++) //根据索引构建并查集
int index1 = pairs.get(i).get(0) ;
int index2 = pairs.get(i).get(1) ;
uf.union(index1,index2) ;
char [] c = s.toCharArray() ;
Map<Integer,PriorityQueue<Character>> map = new HashMap<>(n) ;
for(int i=0; i<n; i++) //遍历元素,找到代表元,并代表元相同的放到一个集合,并按字典序排序
int root = uf.find(i) ;
if(map.containsKey(root))
map.get(root).add(c[i]) ;
else
PriorityQueue<Character> minHeap = new PriorityQueue<>() ;
minHeap.add(c[i]) ;
map.put(root,minHeap) ;
StringBuilder ans = new StringBuilder() ;
for(int i=0; i<n; i++)
int root = uf.find(i) ;
ans.append(map.get(root).poll()) ;
return ans.toString() ;
class UnionFind
int n ;
int [] parent ;
public UnionFind(int n)
this.n = n ;
this.parent = new int [n] ;
for(int i=0; i<n; i++)
parent[i] = i ;
public int find(int x)
if(x != parent[x])
parent[x] = find(parent[x]) ;
return parent[x] ;
public void union(int x, int y)
int root1 = find(x) ;
int root2 = find(y) ;
if(root1==root2)
return ;
parent[root1] = root2 ;
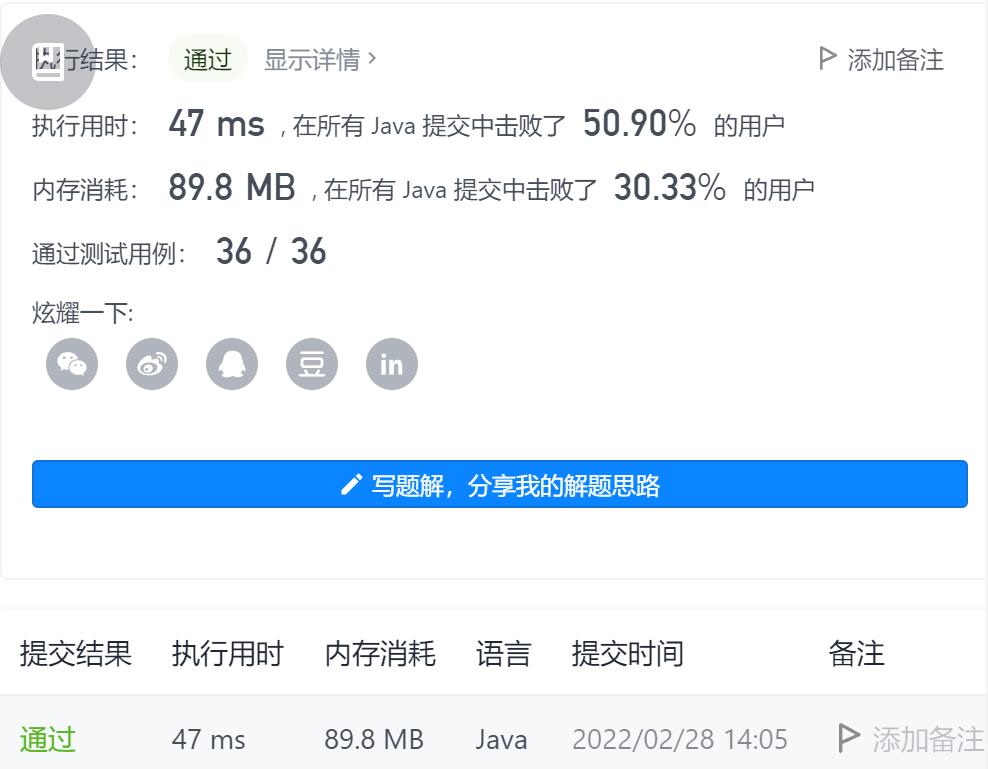
4-可能的二分法
题目链接:题目链接戳这里!!!
思路1:邻接表+并查集
1-对于每个不喜欢的建立双向邻接表,将每个人,不喜欢的放到一个集合里。
2-对每个集合的元素进行并查集合并。
3-如果对于每个元素,其邻接元素与自己在同一个集合,则返回false,否则返回true.
class Solution
public boolean possibleBipartition(int n, int[][] dislikes)
if(dislikes.length==0)
return true ;
Map<Integer, List<Integer>> edges = new HashMap<>() ;
UnionFind uf = new UnionFind(n) ;
for(int [] dislike : dislikes)
List<Integer> temp1 = edges.getOrDefault(dislike[0],new ArrayList<>()) ;
temp1.add(dislike[1]) ;
edges.put(dislike[0],temp1) ;
List<Integer> temp2 = edges.getOrDefault(dislike[1], new ArrayList<>()) ;
temp2.add(dislike[0]) ;
edges.put(dislike[1],temp2) ;
for(int i : edges.keySet())
List<Integer> list = edges.get(i) ;
for(int neighbors : list)
if(uf.find(neighbors) == uf.find(i))
return false ;
uf.union(neighbors,list.get(0)) ;
return true ;
class UnionFind
int n ;
int [] parent ;
public UnionFind(int n)
this.n = n ;
this.parent = new int [n+1] ;
for(int i=1; i<=n; i++)
parent[i] = i ;
public int find(int x)
if(x != parent[x])
parent[x] = find(parent[x]) ;
return parent[x] ;
public void union(int x, int y)
int root1 = find(x) ;
int root2 = find(y) ;
if(root1==root2)
return ;
parent[root1] = root2 ;
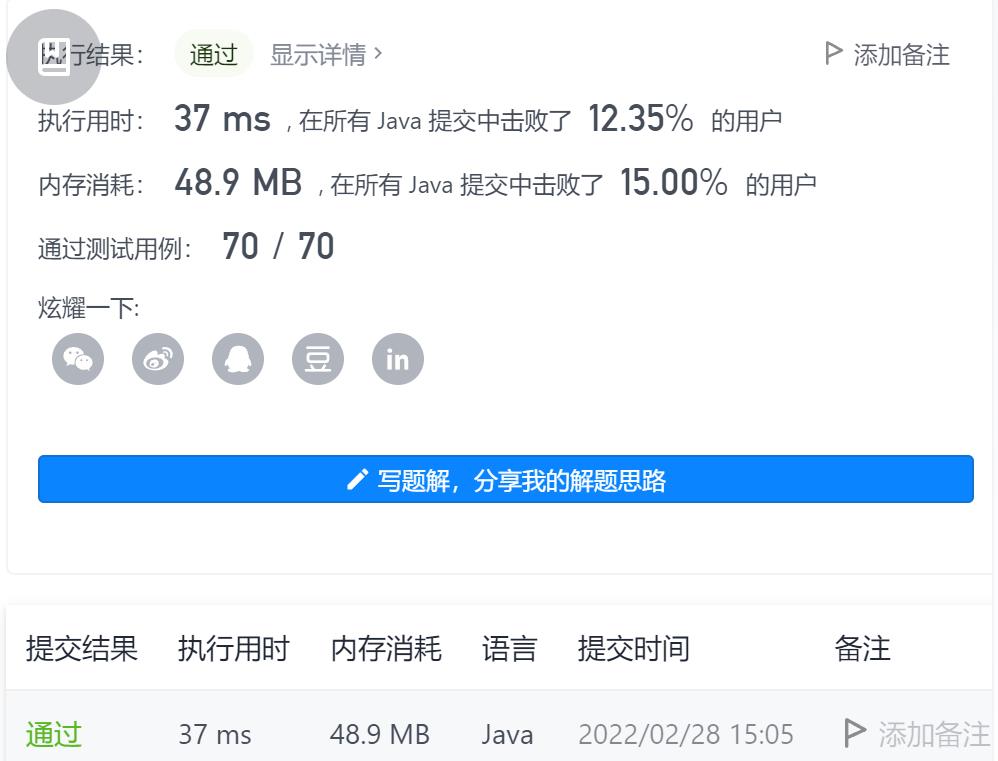
思路2:邻接表+dfs+染色法
尝试将每个人分配到一个组是很自然的想法。假设第一
以上是关于leetcode之并查集+记忆化搜索+回溯+最小生成树刷题总结1的主要内容,如果未能解决你的问题,请参考以下文章