mongodb监听oplog 全量+增量同步
Posted AresCarry
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了mongodb监听oplog 全量+增量同步相关的知识,希望对你有一定的参考价值。
一、前言
前一个项目中,涉及到了一次数据迁移,这次迁移需要从mongodb迁移到另一个mongodb实例上,两个源的数据结构是不一样的。涉及到增量和全量数据迁移,整体迁移数据量在5亿左右。本篇即讲理论,也讲实战,往下看↓!
二、迁移思路
通常的增量和全量迁移,思路基本一致:
- 在开启全量的时候,开始增量监听,记录下增量的主键id
- 当全量执行结束的时候,从新跑一边记录的增量主键id的记录,根据getbyId查询一下最新的记录,再upsert到新库中。
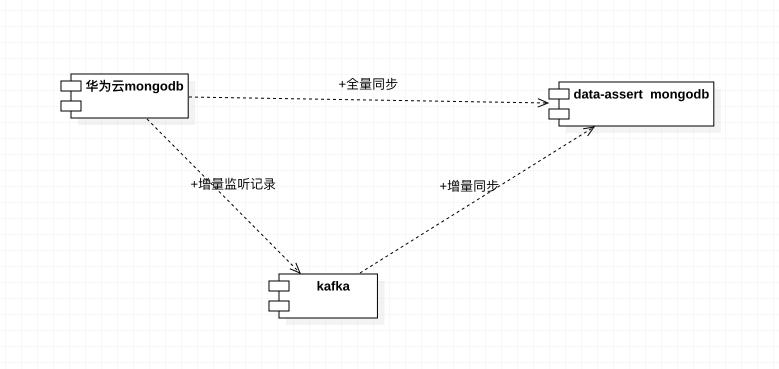
思路就是这么样的。
三、同步实战
全量同步
全量的操作是比较简单的,这里我们需要找到一个排序的键,然后一直从旧库不断的捞数据,改变数据个时候,再更新到新表中,我这里的主键是递增的,所以我会根据主键id来进行循环获取,开始的时候还会记录一下最大的主键,当我们执行到最大的主键的时候,全量就结束了。
我写了一个http接口,主动调用来全量同步数据。
/**
* 全量同步
*
* @return 是否成功
*/
@RequestMapping("/fullData")
public Boolean fullData()
//获取主键最大值
Query query = new Query();
query.with(new Sort(Sort.Direction.DESC, "_id"));
query.limit(1);
UserCompleteCountDTO max = firstMongoTemplate.findOne(query, UserCompleteCountDTO.class);
Integer maxUserId = max.getUserId();
Integer step = 100;
Integer beginId = 1;
Integer totalCount = 0;
while (true)
logger.info("beginId:", beginId);
Criteria criteria = new Criteria().where("_id").gte(beginId);
Query queryStep = new Query(criteria);
queryStep.limit(step).with(new Sort(new Sort.Order(Sort.Direction.ASC, "_id")));
List<UserCompleteCountDTO> historyDTOS = new ArrayList<>();
try
historyDTOS = firstMongoTemplate.find(queryStep, UserCompleteCountDTO.class);
catch (Exception e)
List<UserCompleteCountIdDTO> historyIdDTOS = new ArrayList<>();
historyIdDTOS = firstMongoTemplate.find(queryStep, UserCompleteCountIdDTO.class);
if (!CollectionUtils.isEmpty(historyIdDTOS))
for (UserCompleteCountIdDTO idDTO : historyIdDTOS)
int userId = idDTO.getUserId();
try
Criteria criteriaE = new Criteria().where("_id").is(userId);
Query queryE = new Query(criteriaE);
UserCompleteCountDTO one = firstMongoTemplate.findOne(queryE, UserCompleteCountDTO.class);
if (null != one)
historyDTOS.add(one);
catch (Exception e1)
logger.error("全量查询失败:id:", userId);
errorIdMapper.insert(userId);
totalCount = fullSync(historyDTOS, totalCount);
//判断全量是否完成
if ((CollectionUtils.isEmpty(historyDTOS) || historyDTOS.size() < step) && (beginId + step) >= maxUserId)
logger.info("全量同步结束!");
break;
UserCompleteCountDTO last = historyDTOS.get(historyDTOS.size() - 1);
beginId = last.getUserId() + 1;
try
Thread.sleep(5);
catch (InterruptedException e)
e.printStackTrace();
return true;
private Integer fullSync(List<UserCompleteCountDTO> list, Integer totalCount)
if (CollectionUtils.isEmpty(list))
return totalCount;
//同步数据库
List<DataDTO> insertDataList = new ArrayList<>();
for (UserCompleteCountDTO old : list)
List<DataDTO> dataDTOS = coverDataDTOList(old);
//赋值
insertDataList.addAll(dataDTOS);
ExecutorService executor = Executors.newFixedThreadPool(20);
try
if (!CollectionUtils.isEmpty(insertDataList))
List<List<DataDTO>> partition = Lists.partition(insertDataList, 100);
CountDownLatch countDownLatch = new CountDownLatch(partition.size());
for (List<DataDTO> partList : partition)
ImportTask task = new ImportTask(partList, countDownLatch);
executor.execute(task);
countDownLatch.await();
totalCount = totalCount + list.size();
logger.info("totalCount:", totalCount);
catch (Exception e)
logger.error("批量插入数据失败");
finally
// 关闭线程池,释放资源
executor.shutdown();
return totalCount;
class ImportTask implements Runnable
private List list;
private CountDownLatch countDownLatch;
public ImportTask(List data, CountDownLatch countDownLatch)
this.list = data;
this.countDownLatch = countDownLatch;
@Override
public void run()
if (null != list)
// 业务逻辑,例如批量insert或者update
BulkOperations operations = secondMongoTemplate.bulkOps(BulkOperations.BulkMode.UNORDERED, "xxxxx");
operations.insert(list);
BulkWriteResult result = operations.execute();
// 发出线程任务完成的信号
countDownLatch.countDown();
增量同步
增量同步需要我们来监听mongodb的日志:oplog。
什么是oplog?
oplog用于存储mongodb的增删改 和一些系统命令,查询的不会记录。类似于mysql的binlog日志。
mongodb的副本同步就是利用oplog进行同步的。主节点接收请求操作,然后记录在oplog中,副本节点异步复制这些操作。
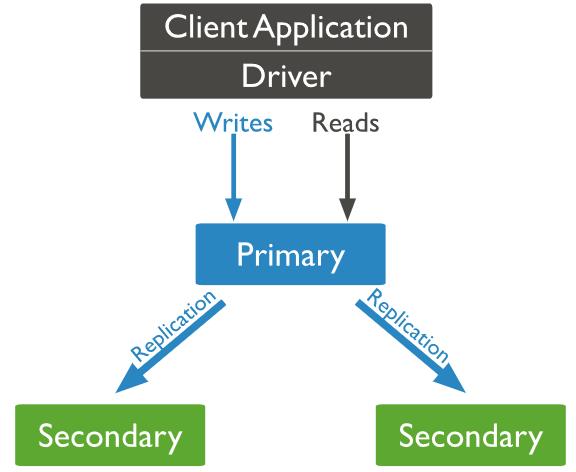
oplog存在哪里?
oplog在local库:
master/slave 架构下
local.oplog.$main;
replica sets 架构下:
local.oplog.rs
sharding 架构下,mongos下不能查看oplog,可到每一片去看。
mongodb 监听代码:
我这里是把监听到的主键id记录到mysql中,当全量完成后,再开启增量同步,读取mysql中数据,同步到新表中
package com.soybean.data.service;
import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.JSONObject;
import com.mongodb.BasicDBObject;
import com.mongodb.CursorType;
import com.mongodb.MongoClient;
import com.mongodb.client.FindIterable;
import com.mongodb.client.MongoCollection;
import com.mongodb.client.MongoCursor;
import com.mongodb.client.MongoDatabase;
import com.soybean.data.mapper.IdMapper;
import com.soybean.data.util.MongoDBUtil;
import org.bson.BsonTimestamp;
import org.bson.Document;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.CommandLineRunner;
import org.springframework.stereotype.Component;
import org.springframework.util.CollectionUtils;
import org.springframework.util.StringUtils;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
import java.util.concurrent.TimeUnit;
import java.util.stream.Collectors;
@Component
public class MongoDBOpLogService implements CommandLineRunner
private static final Logger logger = LoggerFactory.getLogger(MongoDBOpLogService.class);
private static MongoClient mongoClient;
@Autowired
private IdMapper idMapper;
/**
* 服务启动记录增量数据到mysql
* @param strings
* @throws Exception
*/
@Override
public void run(String... strings) throws Exception
initMongoClient();
//获取local库
MongoDatabase database = getDatabase("local");
//监控库oplog.$main
MongoCollection<Document> runoob = getCollection(database, "oplog.rs");
try
//处理
dataProcessing(runoob);
catch (Exception e)
logger.error("error:", e);
private static void initMongoClient()
try
mongoClient = MongoDBUtil.initMongoHasUser();
catch (IOException e)
e.printStackTrace();
public static MongoDatabase getDatabase(String dataBase)
if (!mongoClient.getDatabaseNames().contains(dataBase))
throw new RuntimeException(dataBase + " no exist !");
MongoDatabase mongoDatabase = mongoClient.getDatabase(dataBase);
return mongoDatabase;
/**
* 获取表对象
*
* @param mongoDatabase
* @param testCollection
* @return
*/
public static MongoCollection<Document> getCollection(MongoDatabase mongoDatabase, String testCollection)
MongoCollection<Document> collection = null;
try
//获取数据库dataBase下的集合collecTion,如果没有将自动创建
collection = mongoDatabase.getCollection(testCollection);
catch (Exception e)
throw new RuntimeException("获取" + mongoDatabase.getName() + "数据库下的" + testCollection + "集合 failed !" + e);
return collection;
/**
* 获取数据流处理标准化
*
* @param collection
* @throws InterruptedException
*/
public void dataProcessing(MongoCollection<Document> collection) throws InterruptedException
//-1倒叙,初始化程序时,取最新的ts时间戳,监听mongodb日志,进行过滤,这里的ts尽量做到,服务停止时,存储到文件或者库,获取最新下标
FindIterable<Document> tsCursor = collection.find().sort(new BasicDBObject("$natural", -1)).limit(1);
Document tsDoc = tsCursor.first();
BsonTimestamp queryTs = (BsonTimestamp) tsDoc.get("ts");
try
Integer index = 1;
List<Integer> batchIds = new ArrayList<>();
while (true)
BasicDBObject query = new BasicDBObject("ts", new BasicDBObject("$gt", queryTs));
MongoCursor docCursor = collection.find(query)
.cursorType(CursorType.TailableAwait) //没有数据时阻塞休眠
.noCursorTimeout(true) //防止服务器在不活动时间(10分钟)后使空闲的游标超时。
.oplogReplay(true) //结合query条件,获取增量数据,这个参数比较难懂,见:https://docs.mongodb.com/manual/reference/command/find/index.html
.maxAwaitTime(1, TimeUnit.SECONDS) //设置此操作在服务器上的最大等待执行时间
.iterator();
while (docCursor.hasNext())
Document document = (Document) docCursor.next();
//更新查询时间戳
queryTs = (BsonTimestamp) document.get("ts");
String op = document.getString("op");
String database = document.getString("ns");
if (!"resourcebehaviorsystem.playCompleted".equalsIgnoreCase(database))
continue;
Document context = (Document) document.get("o");
Document where = null;
Integer id = null;
if (op.equals("u"))
where = (Document) document.get("o2");
id = Integer.valueOf(String.valueOf(where.get("_id")));
if (context != null)
context = (Document) context.get("$set");
if (op.equals("i"))
if (context != null)
id = Integer.valueOf(String.valueOf(context.get("_id")));
context = (Document) context.get("$set");
logger.info("操作时间戳:" + queryTs.getTime());
logger.以上是关于mongodb监听oplog 全量+增量同步的主要内容,如果未能解决你的问题,请参考以下文章