面试官:请你谈谈ConcurrentHashMap
Posted androidstarjack
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了面试官:请你谈谈ConcurrentHashMap相关的知识,希望对你有一定的参考价值。
点击上方关注 “终端研发部”
设为“星标”,和你一起掌握更多数据库知识没啥深入实践的理论系同学,在使用并发工具时,总是认为把HashMap改为ConcurrentHashMap,就完美解决并发了呀。或者使用写时复制的CopyOnWriteArrayList,性能更佳呀!技术言论虽然自由,但面对魔鬼面试官时,我们更在乎的是这些真的正确吗?
线程重用导致用户信息错乱
生产环境中,有时获取到的用户信息是别人的。查看代码后,发现是使用了ThreadLocal缓存获取到的用户信息。

ThreadLocal适用于变量在线程间隔离,而在方法或类间共享的场景。若用户信息的获取比较昂贵(比如从DB查询),则在ThreadLocal中缓存比较合适。问题来了,为什么有时会出现用户信息错乱?
案例
使用ThreadLocal存放一个Integer值,代表需要在线程中保存的用户信息,初始null。先从ThreadLocal获取一次值,然后把外部传入的参数设置到ThreadLocal中,模拟从当前上下文获取用户信息,随后再获取一次值,最后输出两次获得的值和线程名称。
固定思维认为,在设置用户信息前第一次获取的值始终是null,但要清楚程序运行在Tomcat,执行程序的线程是Tomcat的工作线程,其基于线程池。而线程池会重用固定线程,一旦线程重用,那么很可能首次从ThreadLocal获取的值是之前其他用户的请求遗留的值。这时,ThreadLocal中的用户信息就是其他用户的信息。
bug 重现
在配置文件设置Tomcat参数-工作线程池最大线程数设为1,这样始终是同一线程在处理请求:
server.tomcat.max-threads=1先让用户1请求接口,第一、第二次获取到用户ID分别是null和1,符合预期
用户2请求接口,bug复现!第一、第二次获取到用户ID分别是1和2,显然第一次获取到了用户1的信息,因为Tomcat线程池重用了线程。两次请求线程都是同一线程:http-nio-45678-exec-1。
写业务代码时,首先要理解代码会跑在什么线程上:
Tomcat服务器下跑的业务代码,本就运行在一个多线程环境(否则接口也不可能支持这么高的并发),并不能认为没有显式开启多线程就不会有线程安全问题
线程创建较昂贵,所以Web服务器会使用线程池处理请求,线程会被重用。使用类似ThreadLocal工具存放数据时,需注意在代码运行完后,显式清空设置的数据。
解决方案
在finally代码块显式清除ThreadLocal中数据。即使新请求过来,使用了之前的线程,也不会获取到错误的用户信息。修正后代码:

ThreadLocal利用独占资源的解决线程安全问题,若就是要资源在线程间共享怎么办?就需要用到线程安全的容器。使用了线程安全的并发工具,并不代表解决了所有线程安全问题。
ThreadLocalRandom 可将其实例设置到静态变量,在多线程下重用吗?
current()的时候初始化一个初始化种子到线程,每次nextseed再使用之前的种子生成新的种子:
UNSAFE.putLong(t = Thread.currentThread(), SEED,
r = UNSAFE.getLong(t, SEED) + GAMMA);如果你通过主线程调用一次current生成一个ThreadLocalRandom实例保存,那么其它线程来获取种子的时候必然取不到初始种子,必须是每一个线程自己用的时候初始化一个种子到线程。可以在nextSeed设置一个断点看看:
UNSAFE.getLong(Thread.currentThread(),SEED);ConcurrentHashMap真的安全吗?
我们都知道ConcurrentHashMap是个线程安全的哈希表容器,但它仅保证提供的原子性读写操作线程安全。
案例
有个含900个元素的Map,现在再补充100个元素进去,这个补充操作由10个线程并发进行。开发人员误以为使用ConcurrentHashMap就不会有线程安全问题,于是不加思索地写出了下面的代码:在每一个线程的代码逻辑中先通过size方法拿到当前元素数量,计算ConcurrentHashMap目前还需要补充多少元素,并在日志中输出了这个值,然后通过putAll方法把缺少的元素添加进去。
为方便观察问题,我们输出了这个Map一开始和最后的元素个数。

访问接口
分析日志输出可得:
初始大小900符合预期,还需填充100个元素
worker13线程查询到当前需要填充的元素为49,还不是100的倍数
最后HashMap的总项目数是1549,也不符合填充满1000的预期
bug 分析
ConcurrentHashMap就像是一个大篮子,现在这个篮子里有900个桔子,我们期望把这个篮子装满1000个桔子,也就是再装100个桔子。有10个工人来干这件事儿,大家先后到岗后会计算还需要补多少个桔子进去,最后把桔子装入篮子。ConcurrentHashMap这篮子本身,可以确保多个工人在装东西进去时,不会相互影响干扰,但无法确保工人A看到还需要装100个桔子但是还未装时,工人B就看不到篮子中的桔子数量。你往这个篮子装100个桔子的操作不是原子性的,在别人看来可能会有一个瞬间篮子里有964个桔子,还需要补36个桔子。
ConcurrentHashMap对外提供能力的限制:
使用不代表对其的多个操作之间的状态一致,是没有其他线程在操作它的。如果需要确保需要手动加锁
诸如size、isEmpty和containsValue等聚合方法,在并发下可能会反映ConcurrentHashMap的中间状态。因此在并发情况下,这些方法的返回值只能用作参考,而不能用于流程控制。显然,利用size方法计算差异值,是一个流程控制
诸如putAll这样的聚合方法也不能确保原子性,在putAll的过程中去获取数据可能会获取到部分数据
解决方案
整段逻辑加锁:
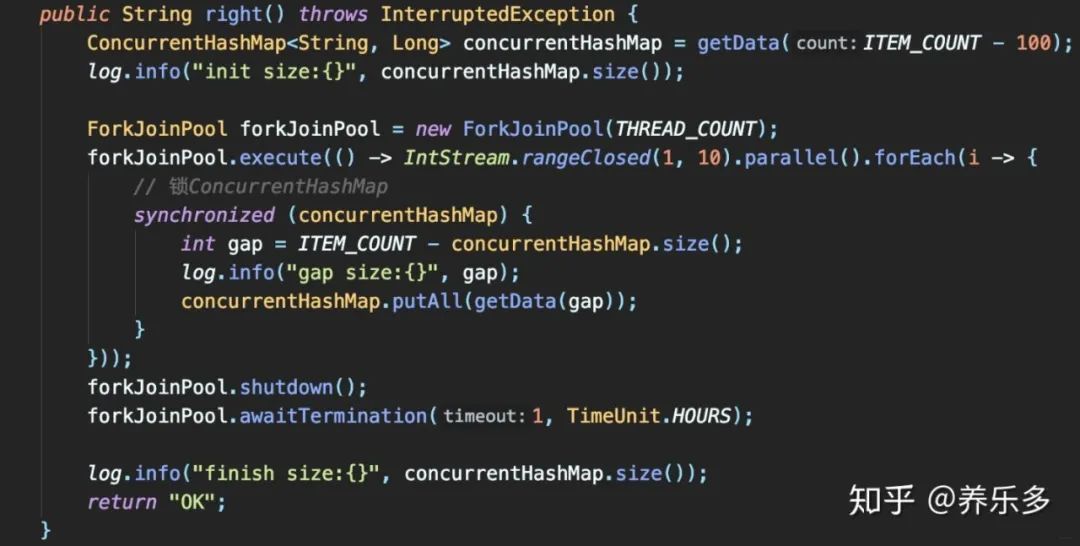
只有一个线程查询到需补100个元素,其他9个线程查询到无需补,最后Map大小1000
既然使用ConcurrentHashMap还要全程加锁,还不如使用HashMap呢?不完全是这样。
ConcurrentHashMap提供了一些原子性的简单复合逻辑方法,用好这些方法就可以发挥其威力。这就引申出代码中常见的另一个问题:在使用一些类库提供的高级工具类时,开发人员可能还是按照旧的方式去使用这些新类,因为没有使用其真实特性,所以无法发挥其威力。
知己知彼,百战百胜
案例
使用Map来统计Key出现次数的场景。
使用ConcurrentHashMap来统计,Key的范围是10
使用最多10个并发,循环操作1000万次,每次操作累加随机的Key
如果Key不存在的话,首次设置值为1。
show me code:
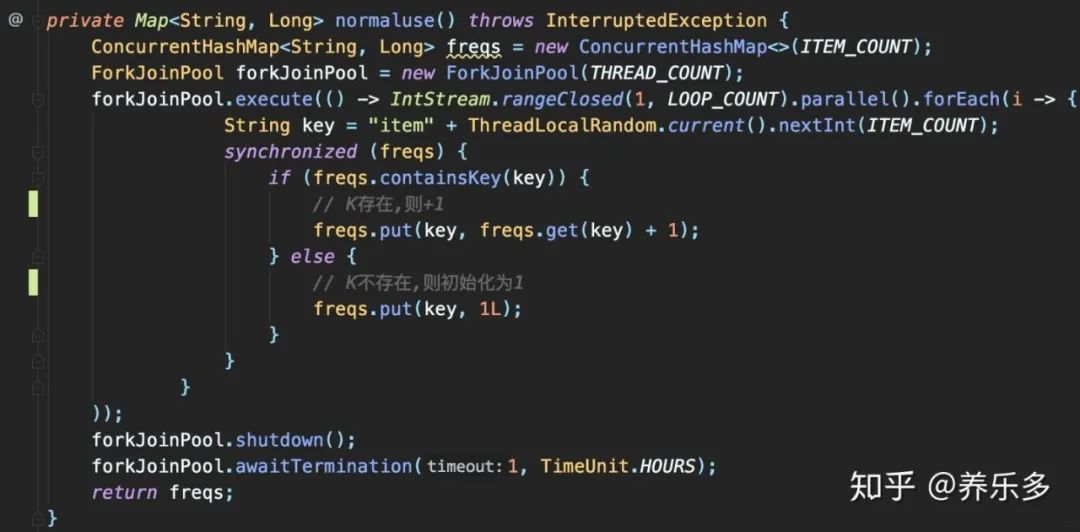
有了上节经验,我们这直接锁住Map,再做
判断
读取现在的累计值
+1
保存累加后值
这段代码在功能上的确毫无没有问题,但却无法充分发挥ConcurrentHashMap的性能,优化后:
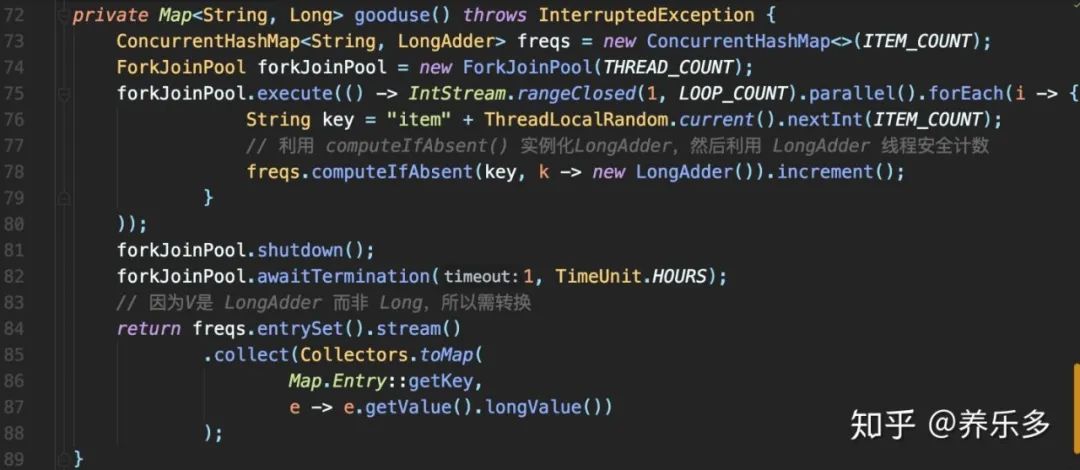
ConcurrentHashMap的原子性方法computeIfAbsent做复合逻辑操作,判断K是否存在V,若不存在,则把Lambda运行后结果存入Map作为V,即新创建一个LongAdder对象,最后返回V 因为computeIfAbsent返回的V是LongAdder,是个线程安全的累加器,可直接调用其increment累加。这样在确保线程安全的情况下达到极致性能,且代码行数骤减。
性能测试
使用StopWatch测试两段代码的性能,最后的断言判断Map中元素的个数及所有V的和是否符合预期来校验代码正确性
性能测试结果:比使用锁性能提升至少5倍。
computeIfAbsent高性能之道
Java的Unsafe实现的CAS。它在JVM层确保写入数据的原子性,比加锁效率高:
static final <K,V> boolean casTabAt(Node<K,V>[] tab, int i,
Node<K,V> c, Node<K,V> v)
return U.compareAndSetObject(tab, ((long)i << ASHIFT) + ABASE, c, v);
所以不要以为只要用了ConcurrentHashMap并发工具就是高性能的高并发程序。
辨明 computeIfAbsent、putIfAbsent
当Key存在的时候,如果Value获取比较昂贵的话,putIfAbsent就白白浪费时间在获取这个昂贵的Value上(这个点特别注意)
Key不存在的时候,putIfAbsent返回null,小心空指针,而computeIfAbsent返回计算后的值
当Key不存在的时候,putIfAbsent允许put null进去,而computeIfAbsent不能,之后进行containsKey查询是有区别的(当然了,此条针对HashMap,ConcurrentHashMap不允许put null value进去)
CopyOnWriteArrayList 之殇
再比如一段简单的非 DB操作的业务逻辑,时间消耗却超出预期时间,在修改数据时操作本地缓存比回写DB慢许多。原来是有人使用了CopyOnWriteArrayList缓存大量数据,而该业务场景下数据变化又很频繁。CopyOnWriteArrayList虽然是一个线程安全版的ArrayList,但其每次修改数据时都会复制一份数据出来,所以只适用读多写少或无锁读场景。所以一旦使用CopyOnWriteArrayList,一定是因为场景适宜而非炫技。
CopyOnWriteArrayList V.S 普通加锁ArrayList读写性能
测试并发写性能
测试结果:高并发写,CopyOnWriteArray比同步ArrayList慢百倍
测试并发读性能
测试结果:高并发读(100万次get操作),CopyOnWriteArray比同步ArrayList快24倍
高并发写时,CopyOnWriteArrayList为何这么慢呢?因为其每次add时,都用Arrays.copyOf创建新数组,频繁add时内存申请释放性能消耗大。
总结
Don't !!!
不要只会用并发工具,而不熟悉线程原理
不要觉得用了并发工具,就怎么都线程安全
不熟悉并发工具的优化本质,就难以发挥其真正性能
不要不结合当前业务场景,就随意选用并发工具,可能导致系统性能更差
Do !!!
认真阅读官方文档,理解并发工具适用场景及其各API的用法,并自行测试验证,最后再使用 并发bug本就不易复现, 多自行进行性能压力测试

BAT等大厂Java面试经验总结

想获取 Java大厂面试题学习资料
扫下方二维码回复「BAT」就好了
回复 【加群】获取github掘金交流群
回复 【电子书】获取2020电子书教程
回复 【C】获取全套C语言学习知识手册
回复 【Java】获取java相关的视频教程和资料
回复 【爬虫】获取SpringCloud相关多的学习资料
回复 【Python】即可获得Python基础到进阶的学习教程
回复 【idea破解】即可获得intellij idea相关的破解教程
关注我gitHub掘金,每天发掘一篇好项目,学习技术不迷路!如果喜欢就给个“在看”以上是关于面试官:请你谈谈ConcurrentHashMap的主要内容,如果未能解决你的问题,请参考以下文章