Spark详细总结
Posted 爱上攻城狮2021
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark详细总结相关的知识,希望对你有一定的参考价值。
一:算子统计
flatmap
map
mapValues
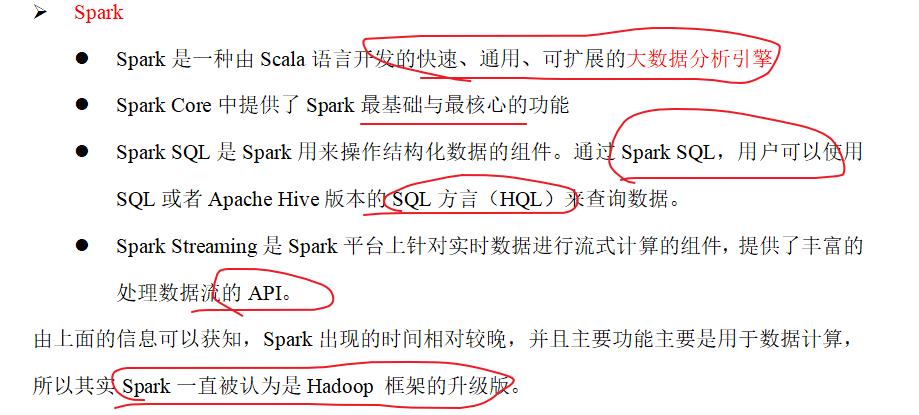
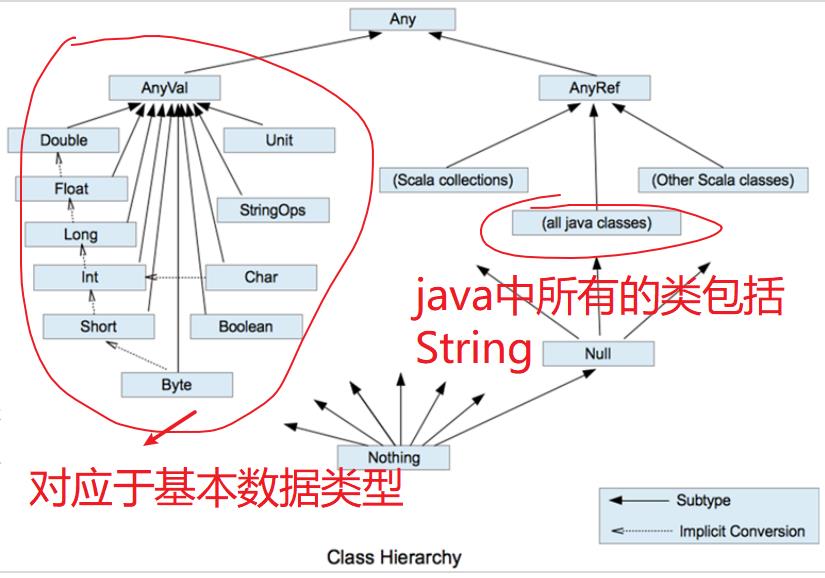
一:Spark简介
park和Hadoop的根本差异是多个作业之间的数据通信问题 : Spark多个作业之间数据通信是基于内存,而Hadoop是基于磁盘。
Spark的缓存机制比HDFS的缓存机制高效。


二:wordCount()分析 (flatmap() 与 map())
flatmap与map我的理解:
读取数据是一行一行读的,(如果每一行的数据源是 (Hello World Hello Spark)
)
补充:
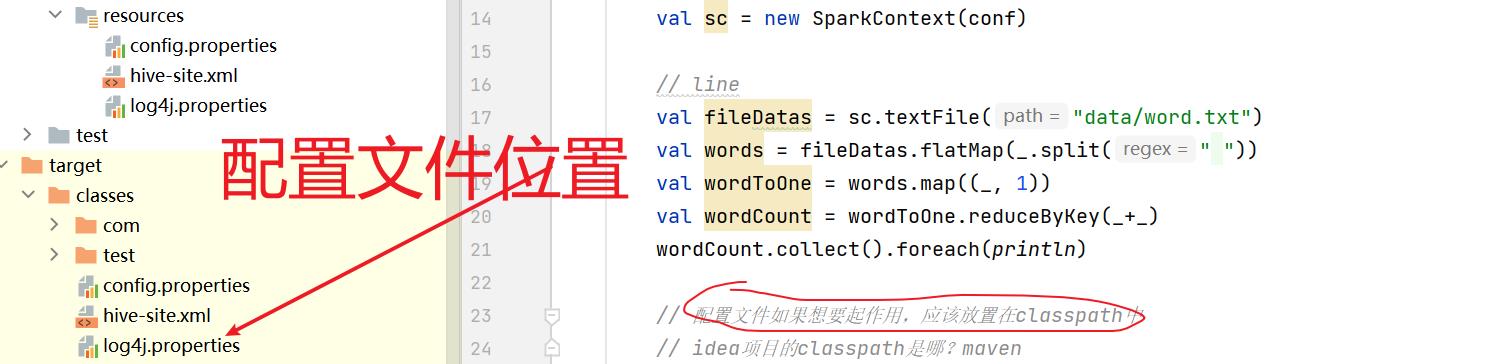
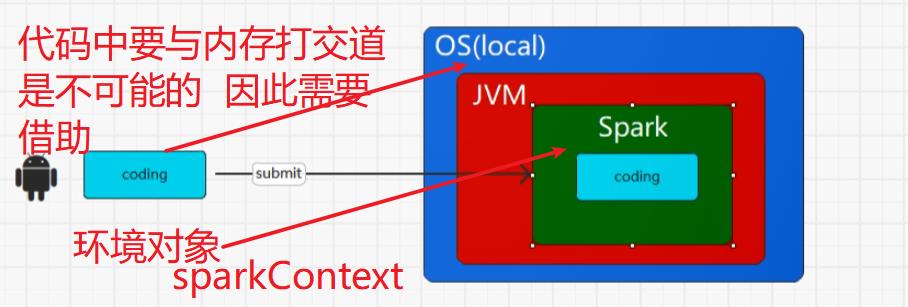
用任何一个框架都需要一个环境对象 sc就是SparkContext的环境对象(环境配置对象参数)
val spakConf = new SparkConf().setMaster("local[*]").setAppName("WordCount").set("spark.testing.memory", "2147480000")val sc = new SparkContext(spakConf)
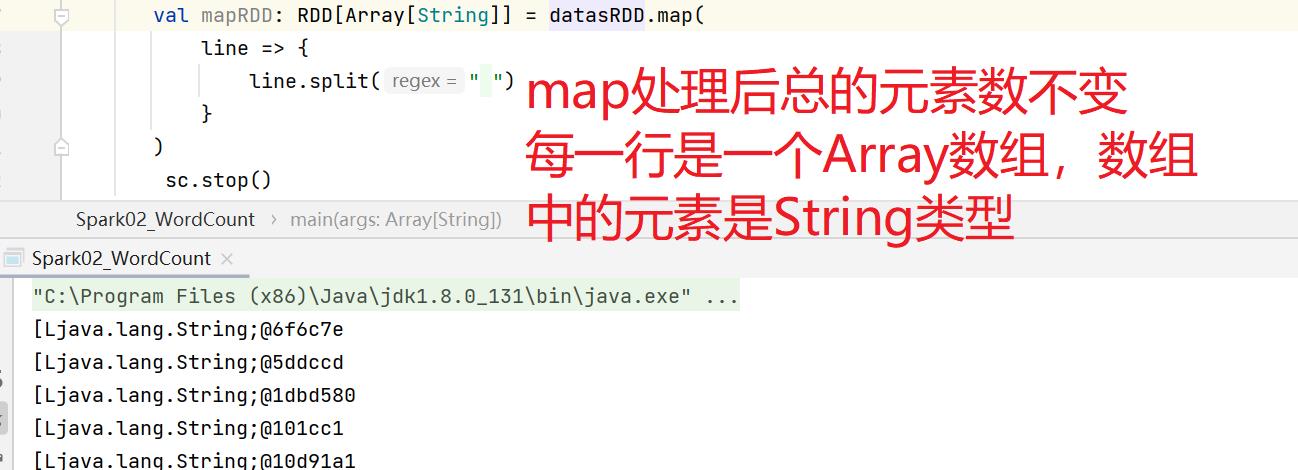



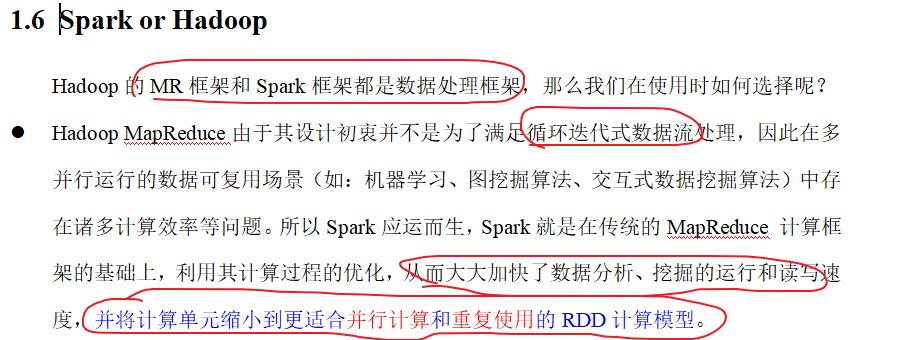
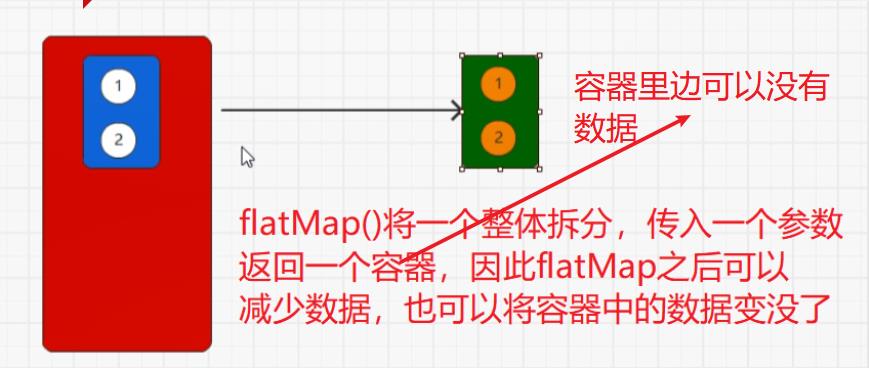
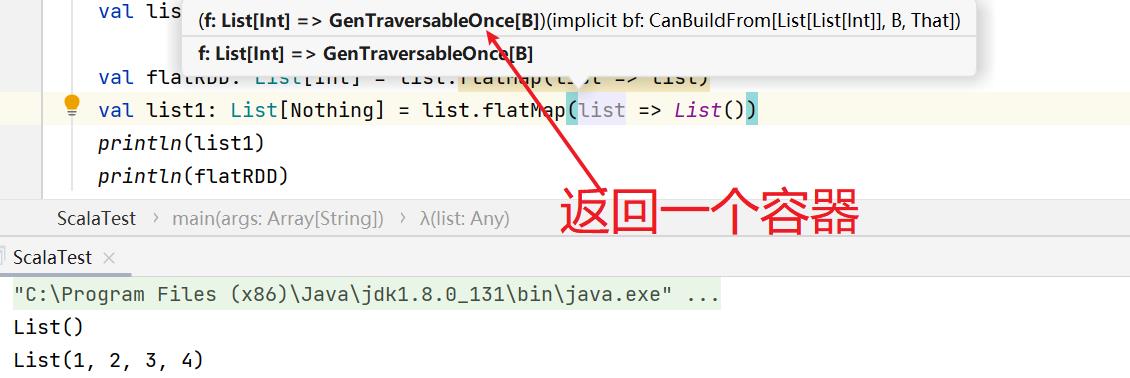
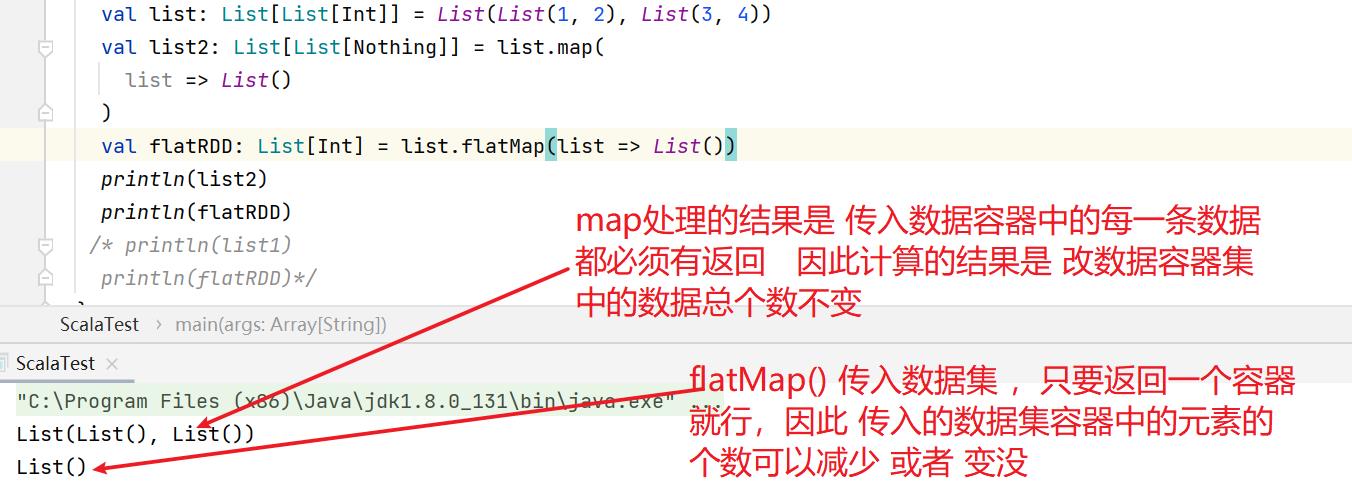
flatMap()将整体拆分成为个体。
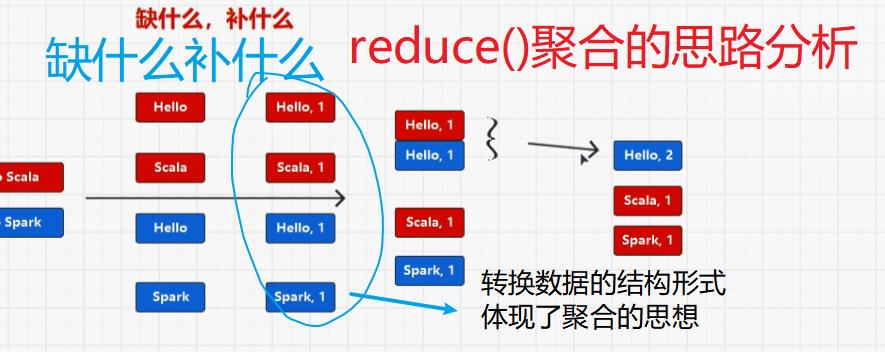
val wordGroup: RDD[(String, Iterable[(String, Int)])] = fileDataRDD.flatMap(_.split(" ")) .map((_, 1)) .groupBy(_._1) wordGroup.mapValues( list => list.map(_._2) list.map(_._2).sum list.map(_._2).reduce(_+_) list.map(_._2).size ) val wordCount: RDD[(String, Int)] = wordGroup.mapValues(_.map(_._2).reduce(_ + _)) wordGroup.collect().foreach(println)
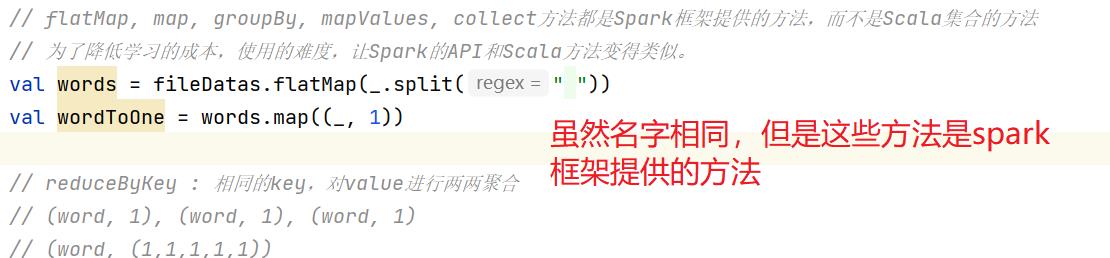
// flatMap, map, groupBy, mapValues, collect方法都是Spark框架提供的方法,而不是Scala集合的方法 // 为了降低学习的成本,使用的难度,让Spark的API和Scala方法变得类似。 val words = fileDatas.flatMap(_.split(" ")) val wordToOne = words.map((_, 1)) // reduceByKey : 相同的key,对value进行两两聚合 // (word, 1), (word, 1), (word, 1) // (word, (1,1,1,1,1)) val wordCount = wordToOne.reduceByKey(_+_) wordCount.collect().foreach(println)








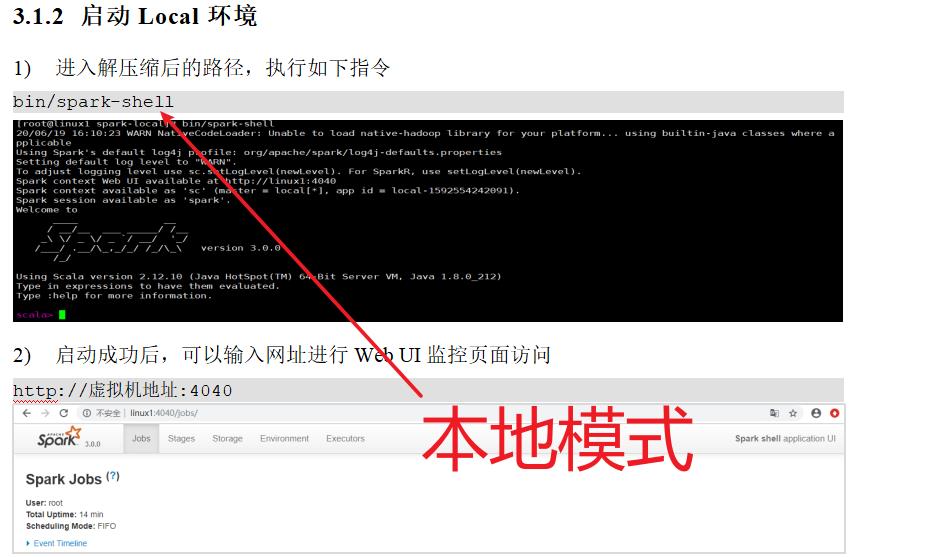
三:spark环境


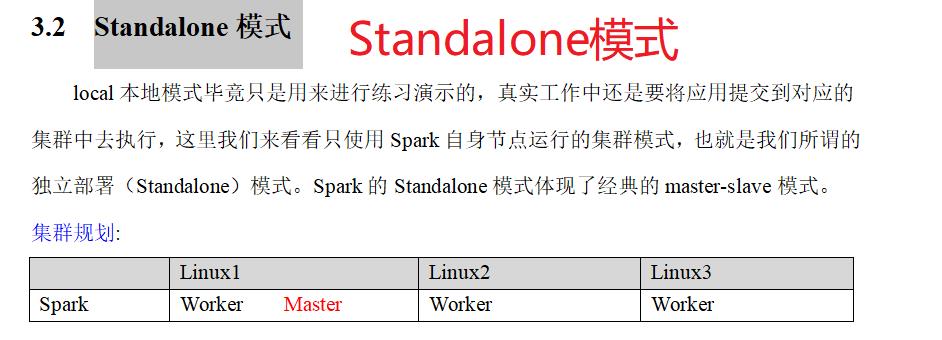

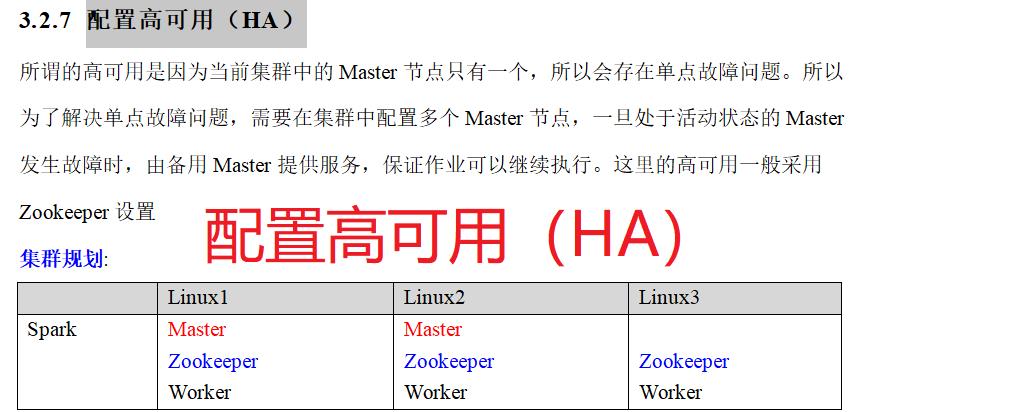


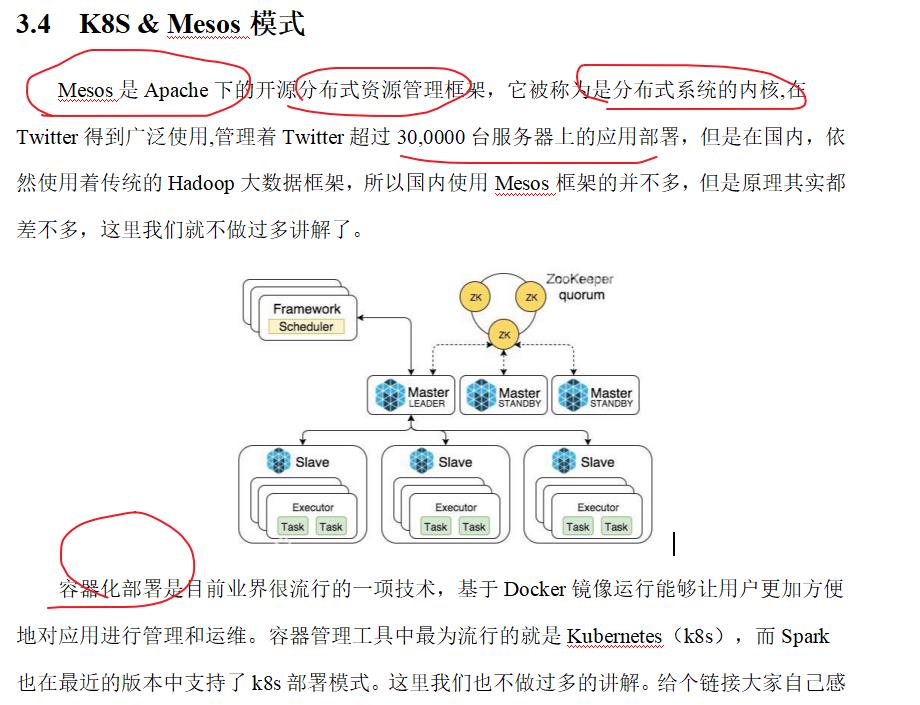

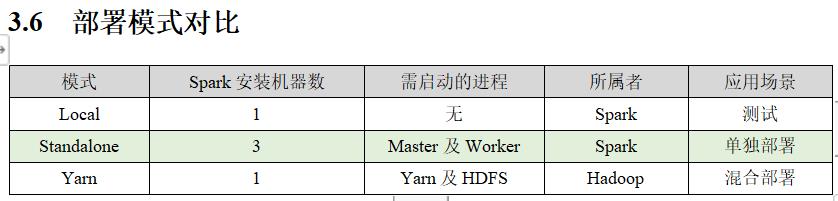

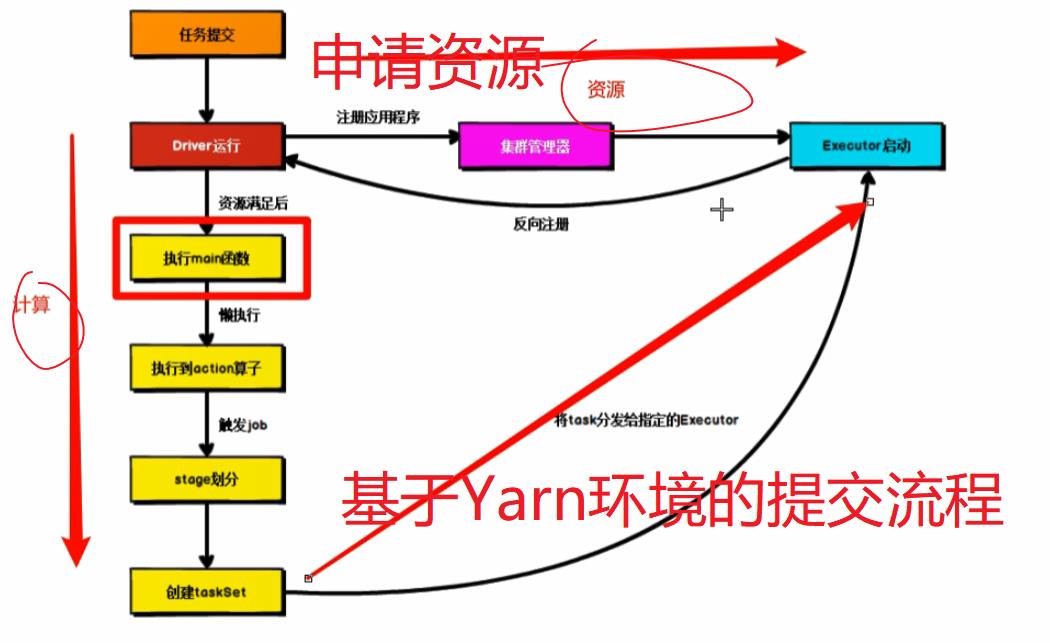
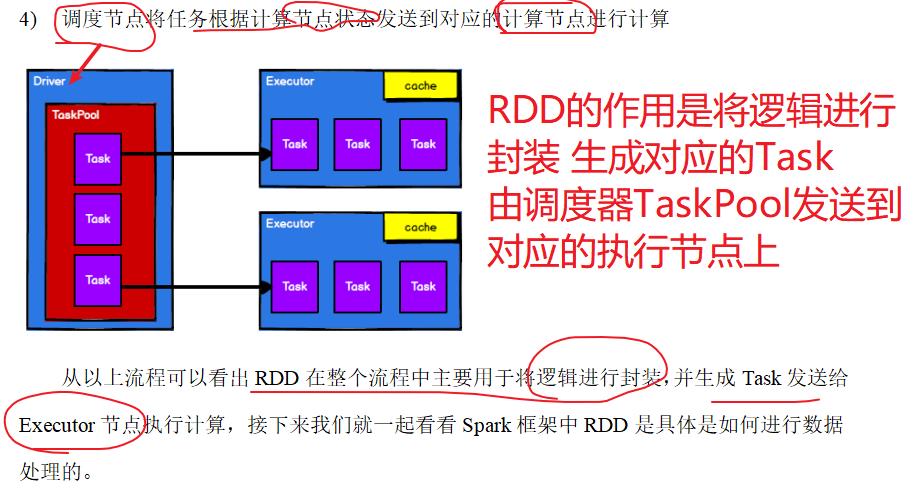
四:Spark运行架构
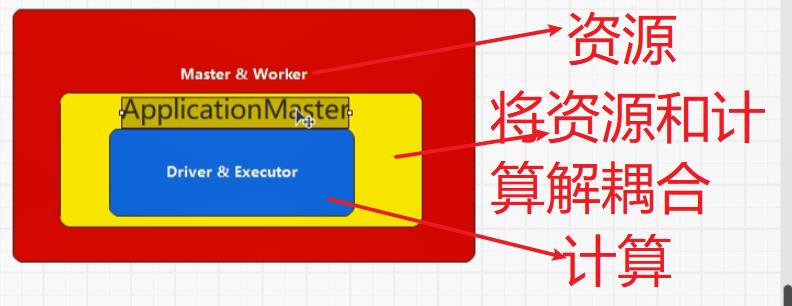
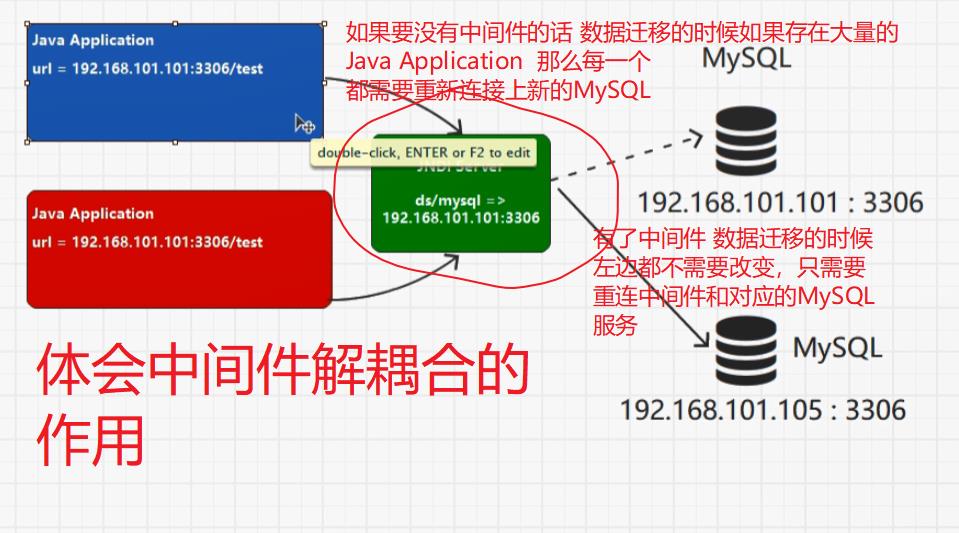
YARN中ApplicationMaster能做到资源和计算的解耦合,Driver和Executor使用的计算框架是Spark,因此也可以使用其它的框架,而YARN只做资源的调度使用
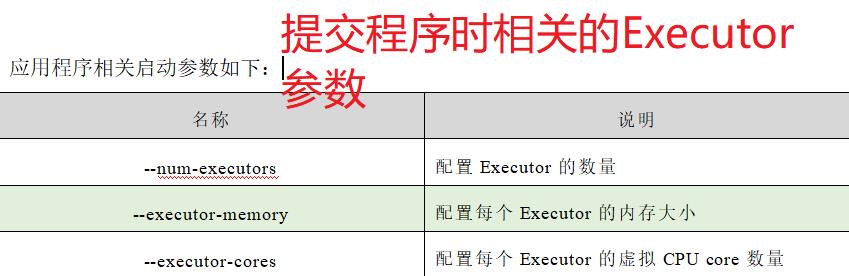
Spark应用程序提交到Yarn环境中执行的时候,一般会有两种部署执行的方式:Client和Cluster。两种模式主要区别在于:Driver程序的运行节点位置。

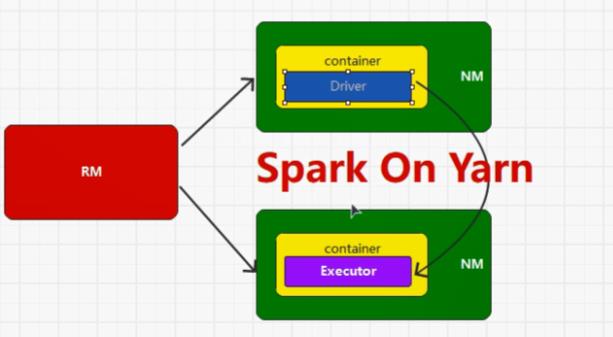






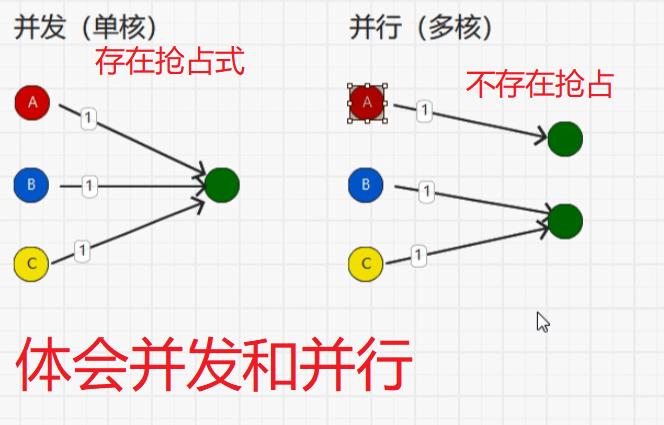




五:Spark核心编程
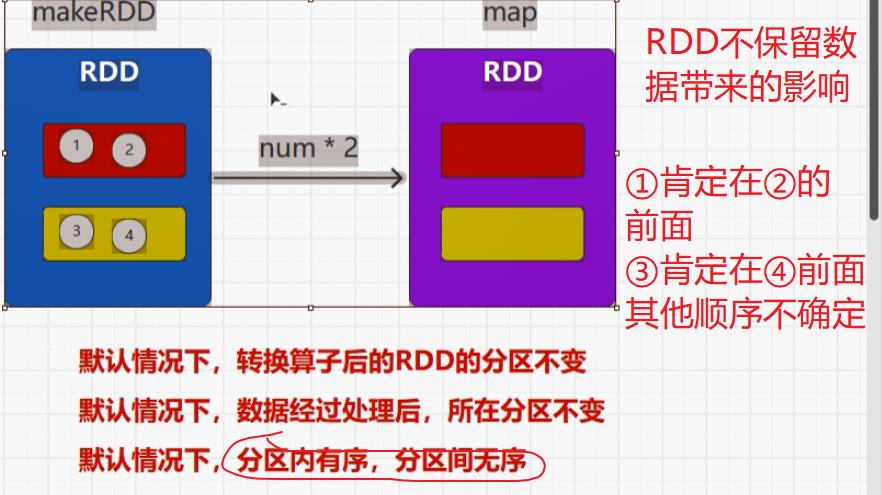
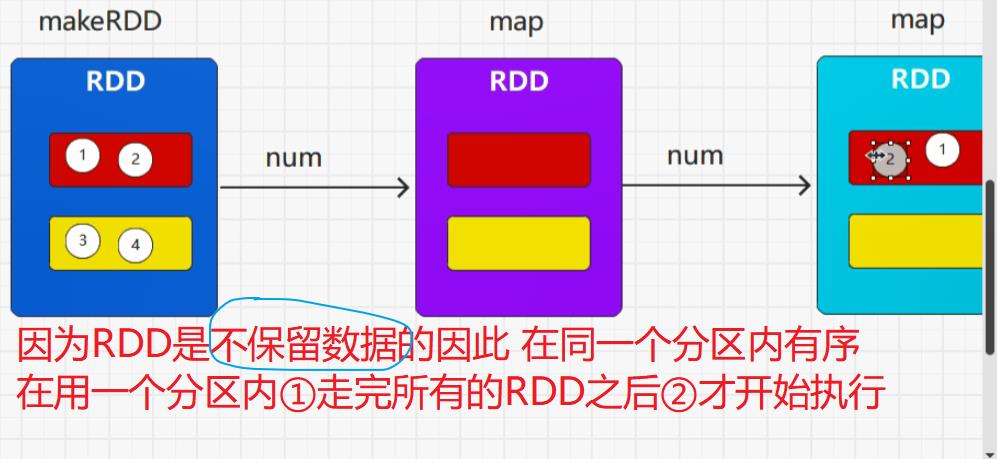
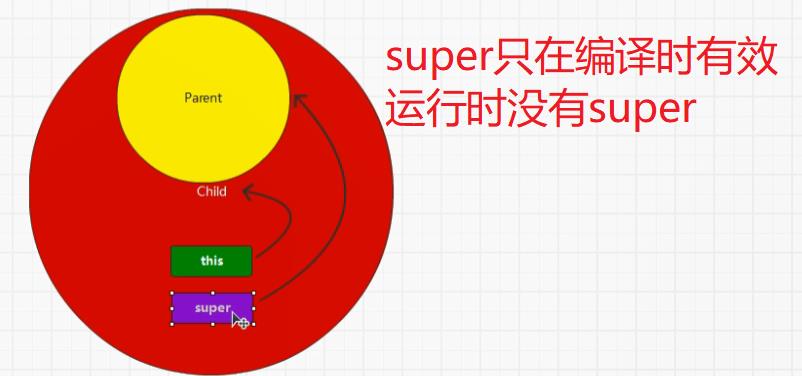
首先,装饰者模式只会进行功能组合,不会执行,另外RDD的装饰者模式与IO的装饰者模式的区别在于,RDD不保留数据,只对数据进行处理,而IO中有缓冲区可以保留数据。


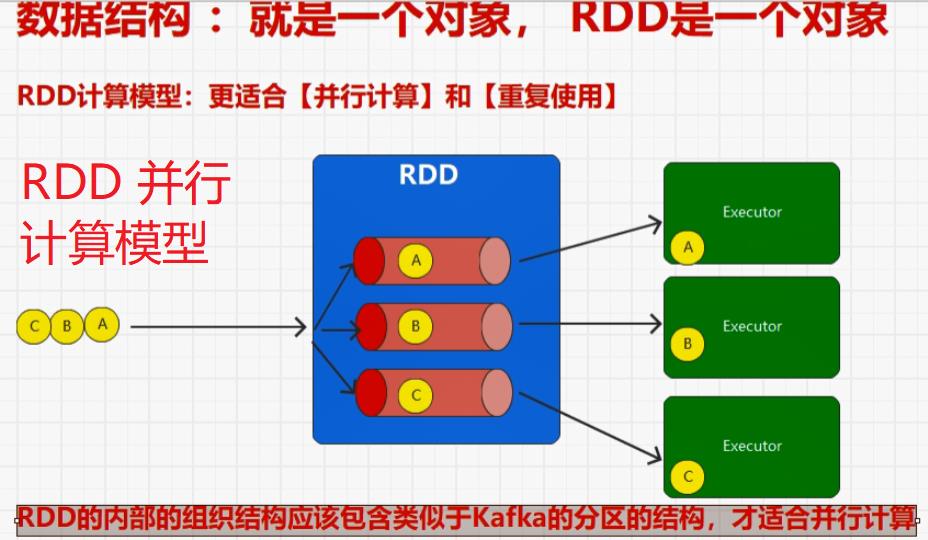
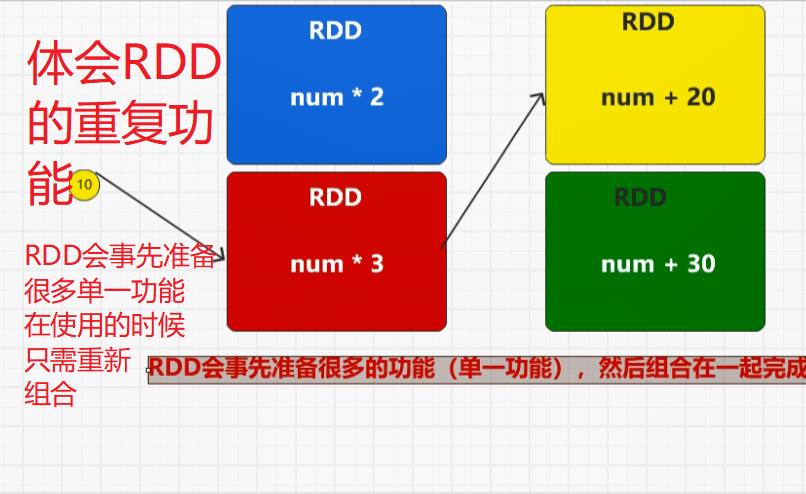
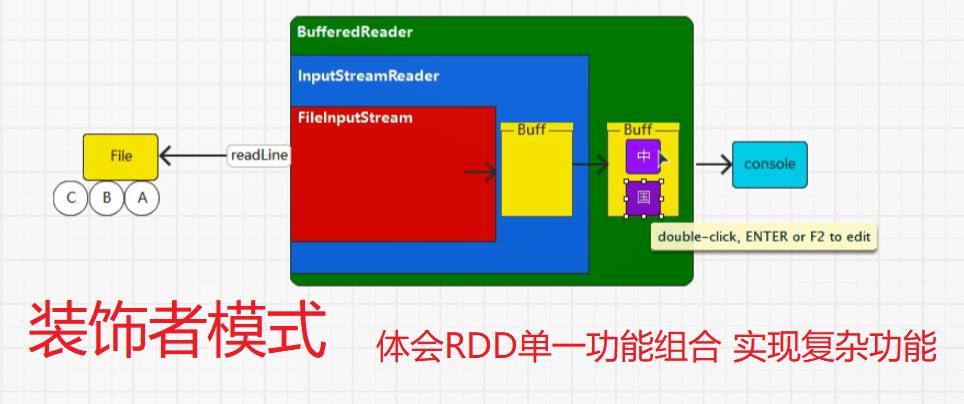








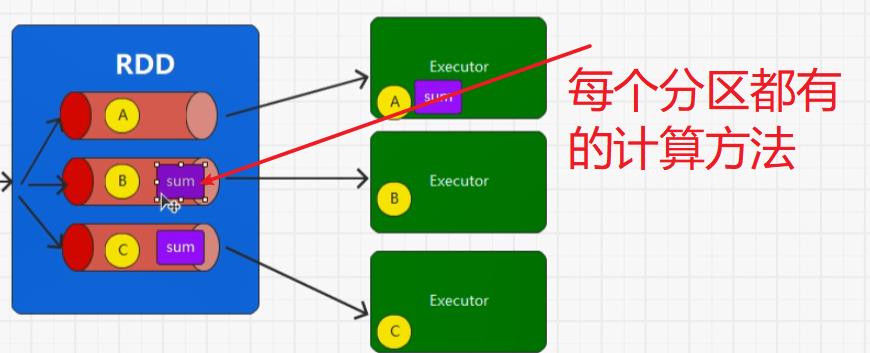
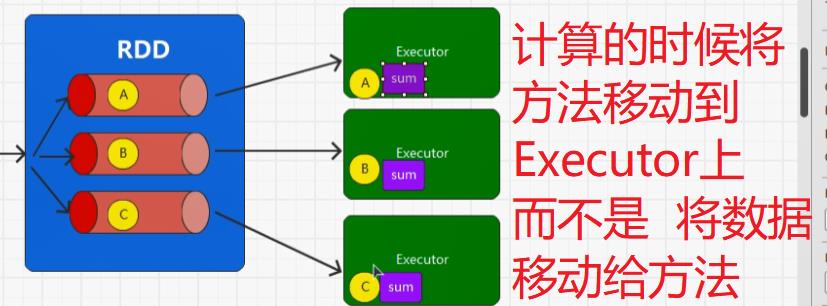




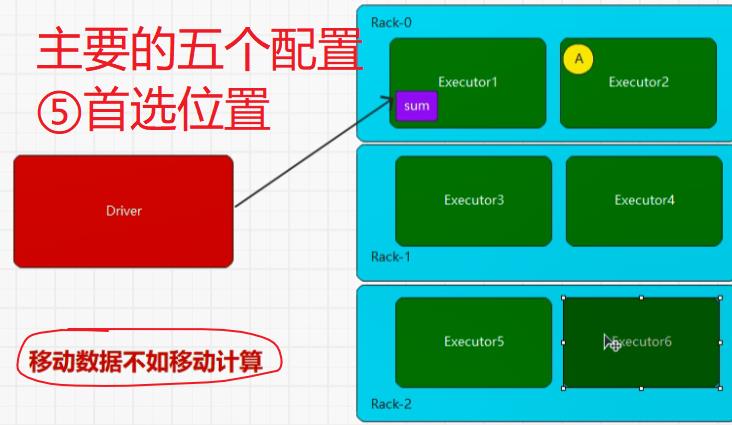
5.1:执行原理


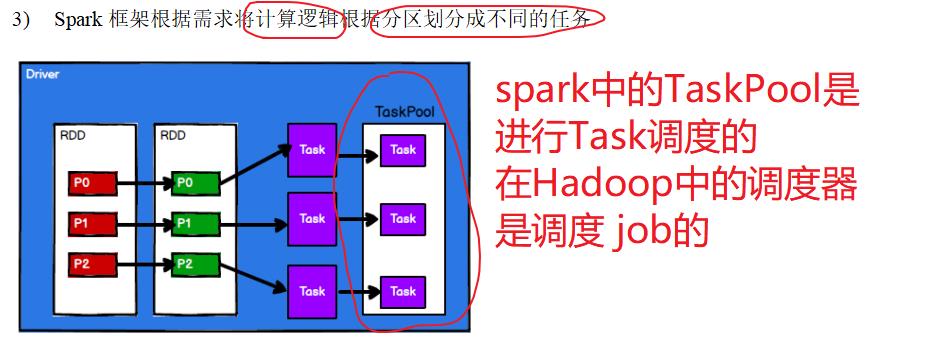
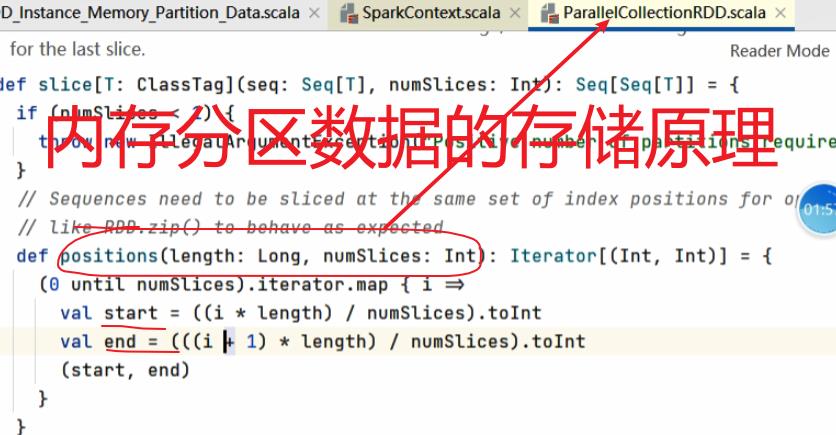
六:内存磁盘如何分区及存储原理
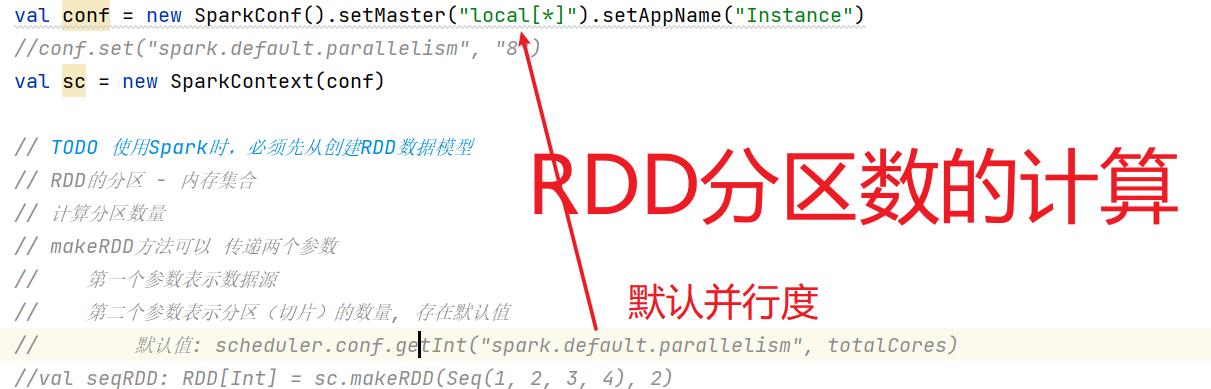
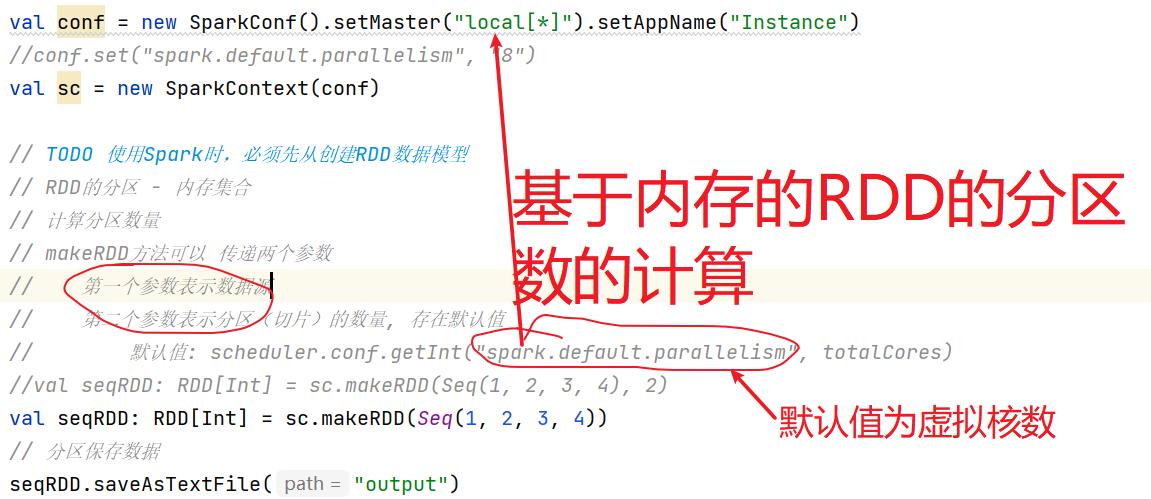
6.1:算子的创建:
因为简明知意,makeRDD用的比较多
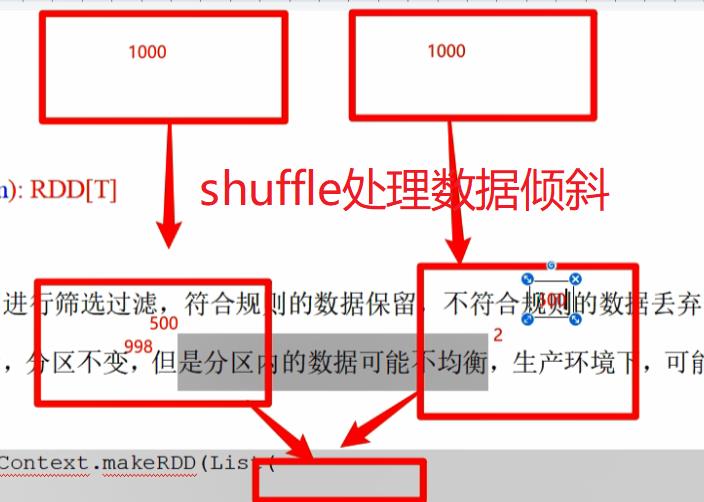
分区数量是如何计算的(只要牵涉的到分区就会出现数据倾斜现象)












七:算子来啦(转换与行为算子)
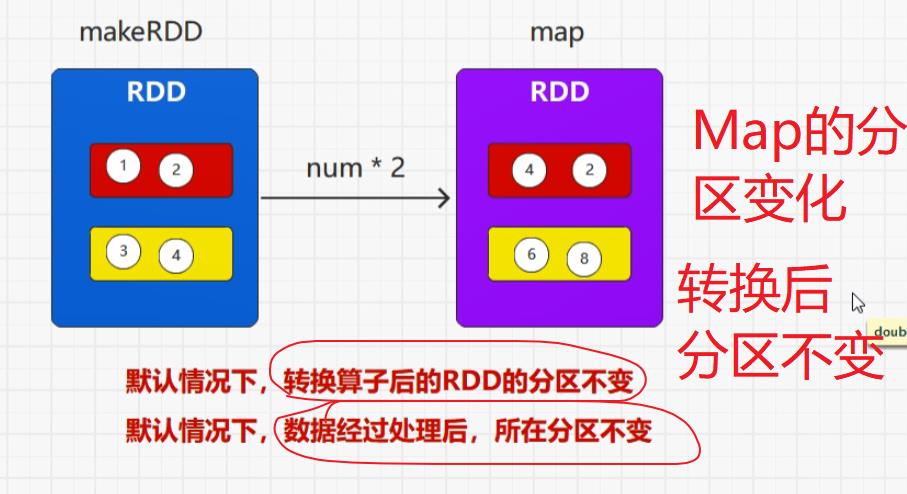
转换算子就是将旧的RDD转换成为新的RDD,因为要组合功能。
flatMap()保留,map()不保留
不在一个分区是无法进行比较的
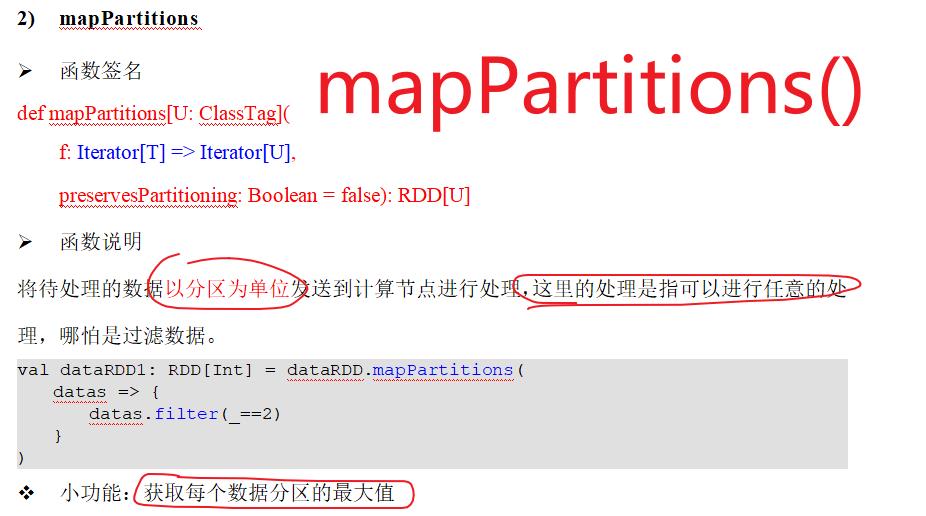
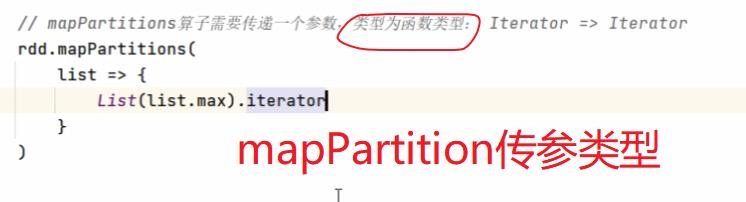
map() VS mapPartitions()
mapPartitions()是批量处理的 因此入参为迭代器 出参也为迭代器,map处理一个返回一个,mapPartitions处理一批返回一批
迭代器Iterator也是集合















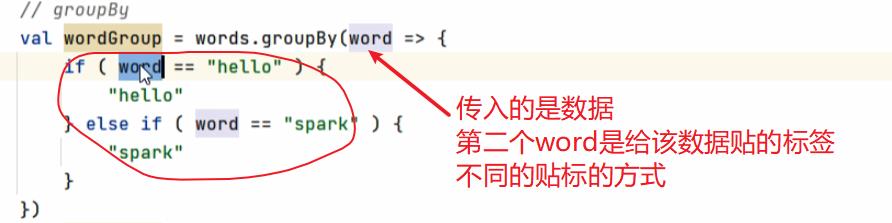
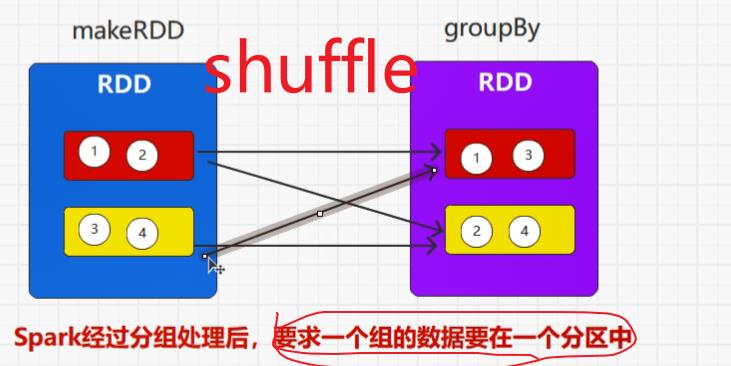
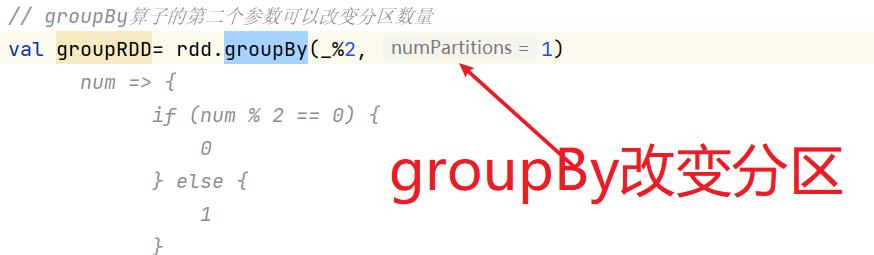
7.1:groupBy()
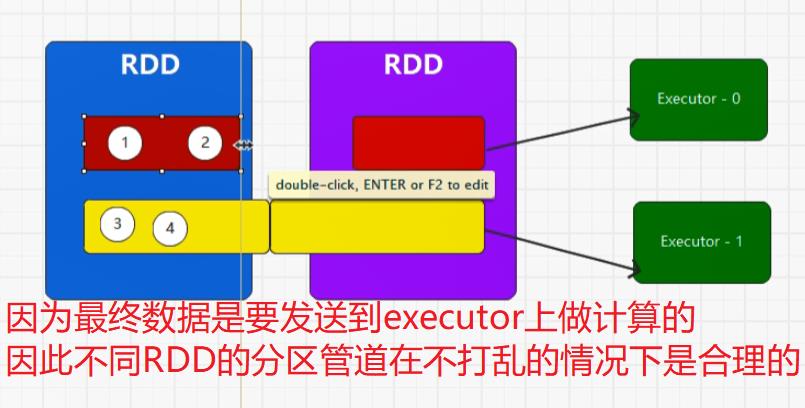
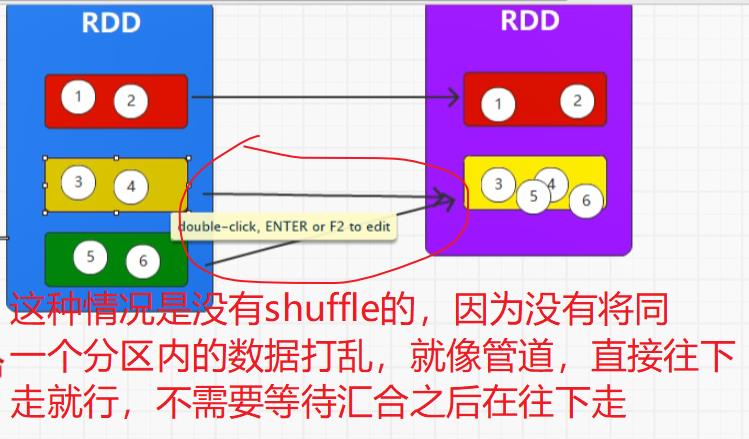
groupBy()引出shuffle
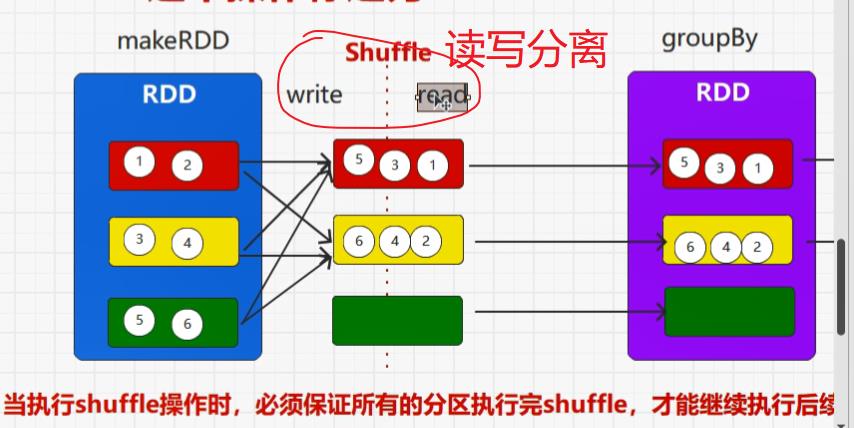
shuffle一定会落盘,因为RDD不保留数据,因此,在shuffle阶段,一定会存在Write(shuffle左边)和read(shuffle右边)
所有含有shuffle的算子都有改变分区的能力
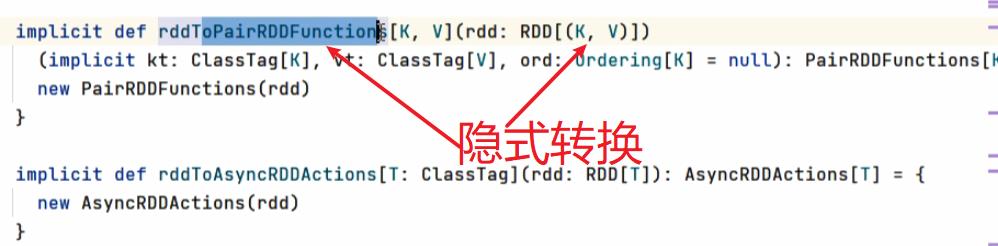
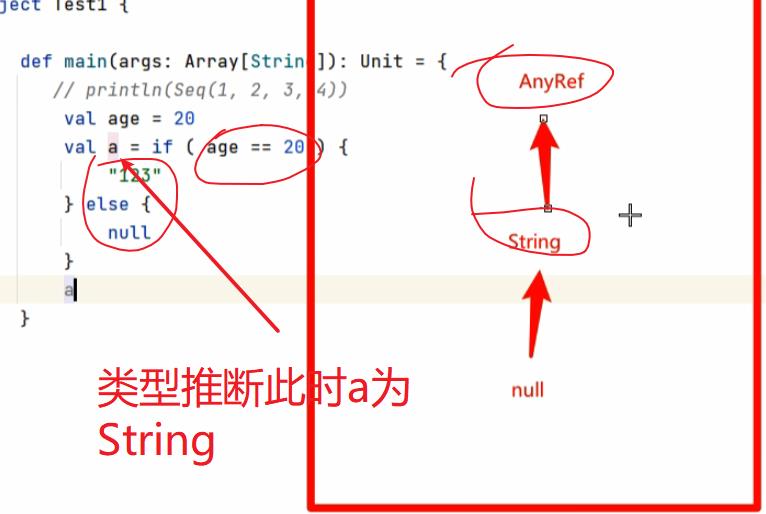
因为隐式转换所以字符串可以直接()写下标









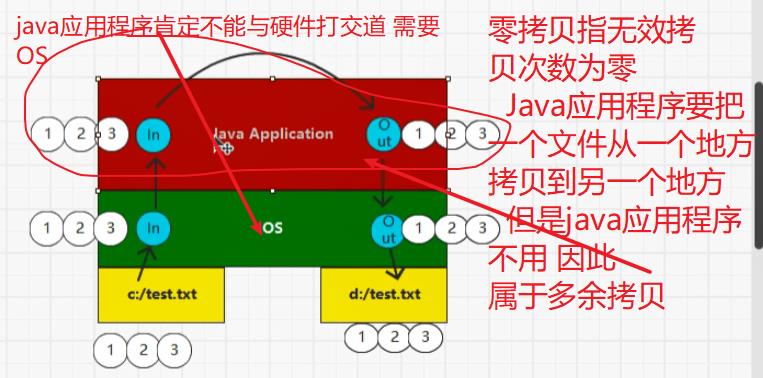
7.2:补充零拷贝(NIO实现)页缓存




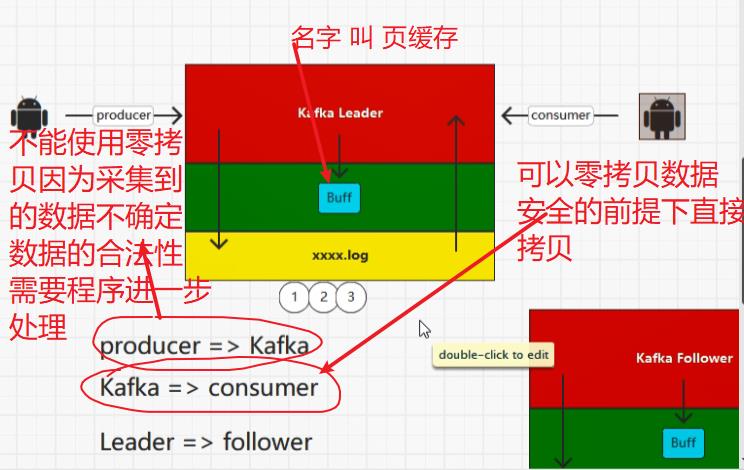
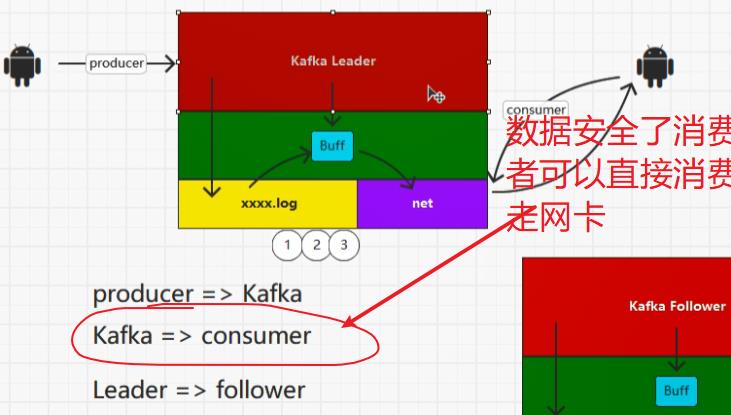

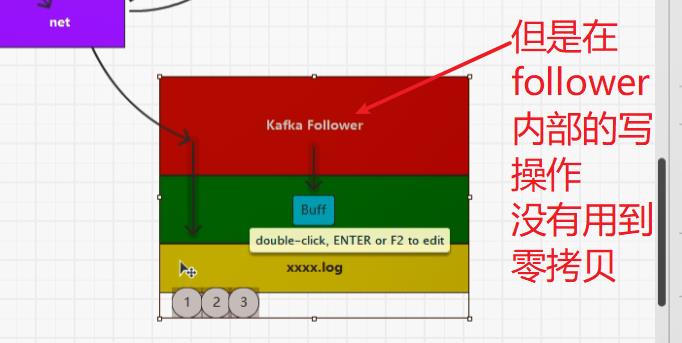
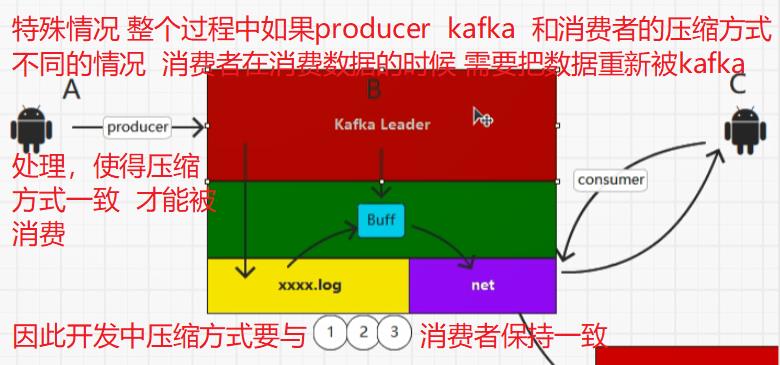
7.3:flatMap()
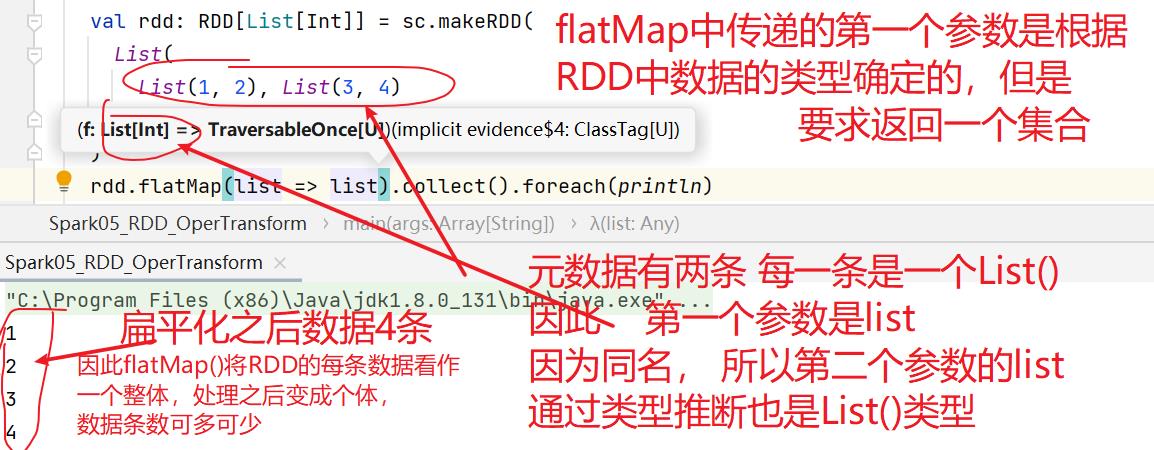


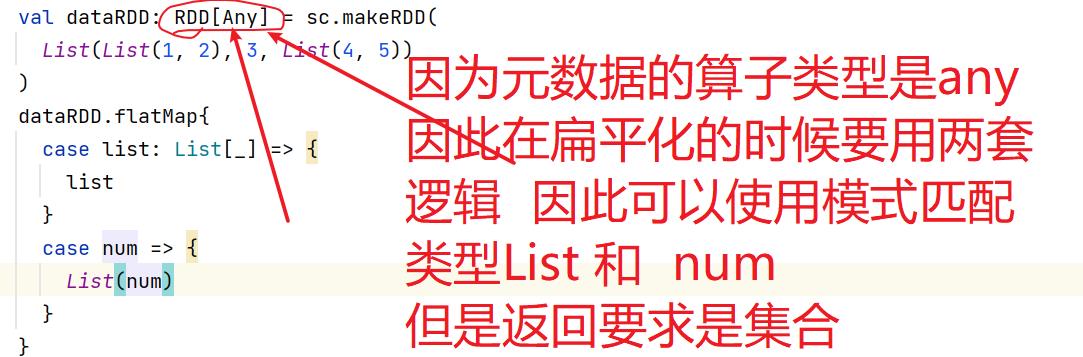
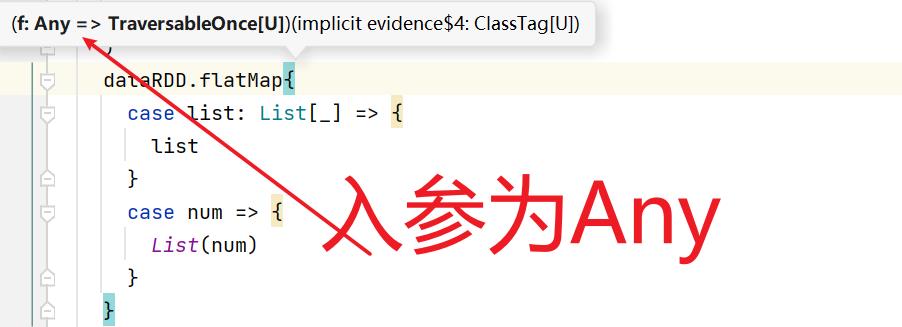
7.4:glom
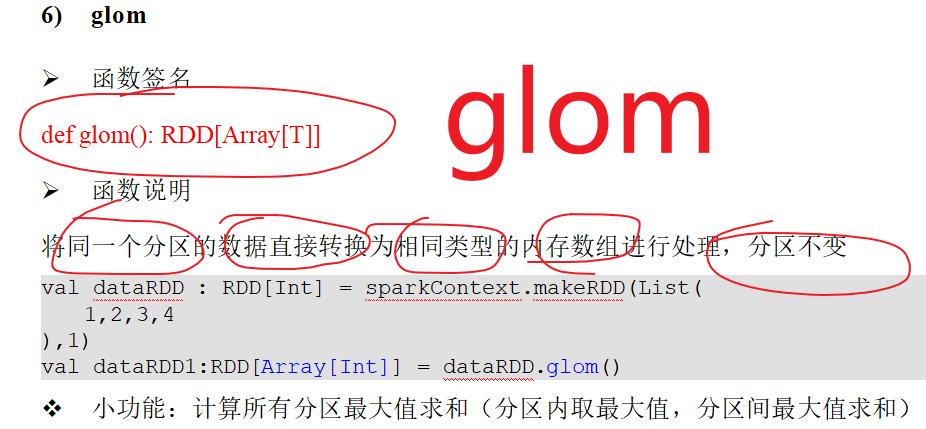






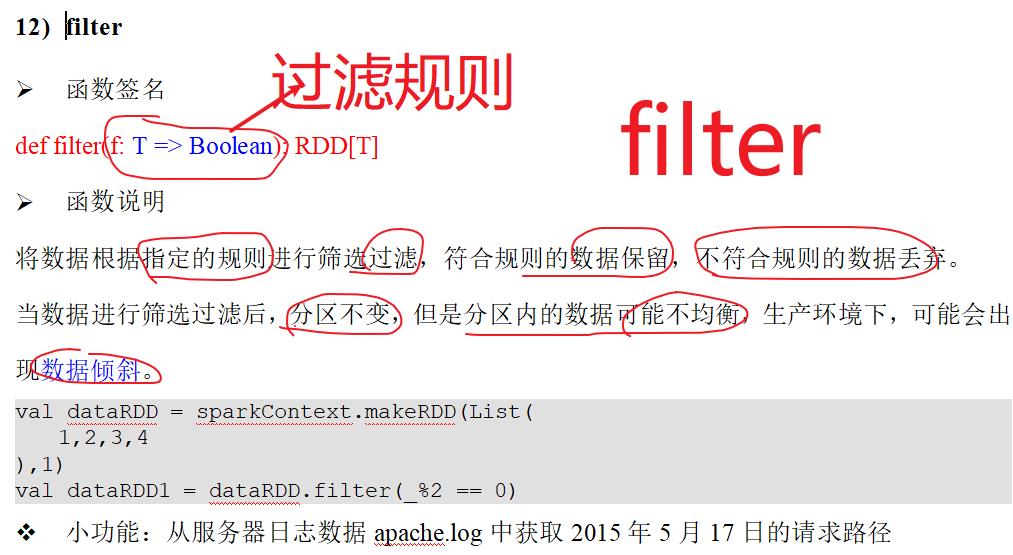
7.5:filter
val fileRDD = sc.textFile("data/apache.log") // filter算子返回的结果为按照规则保留的数据本身 fileRDD.filter( line => val datas = line.split(" ") val time = datas(3) time.startsWith("17/05/2015") ).map( line => val datas = line.split(" ") datas(6) ).collect.foreach(println)

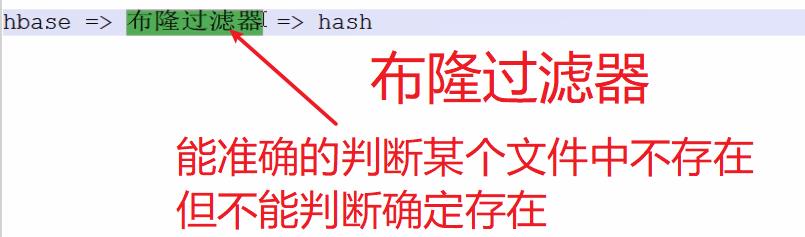
7.6: sample




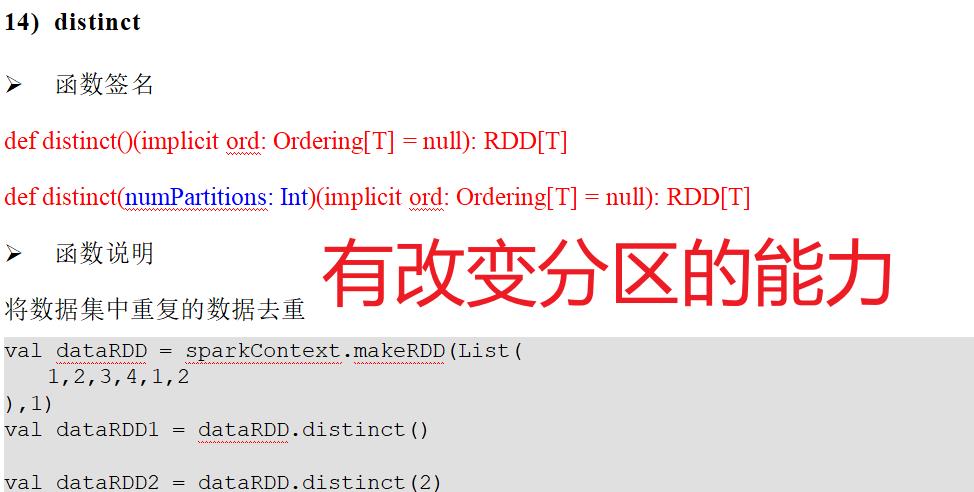
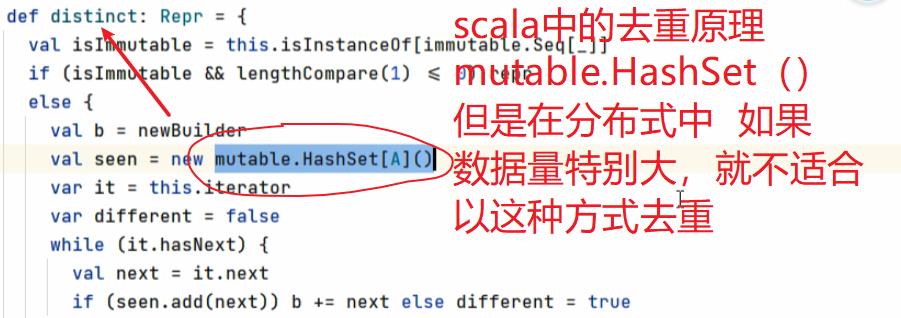
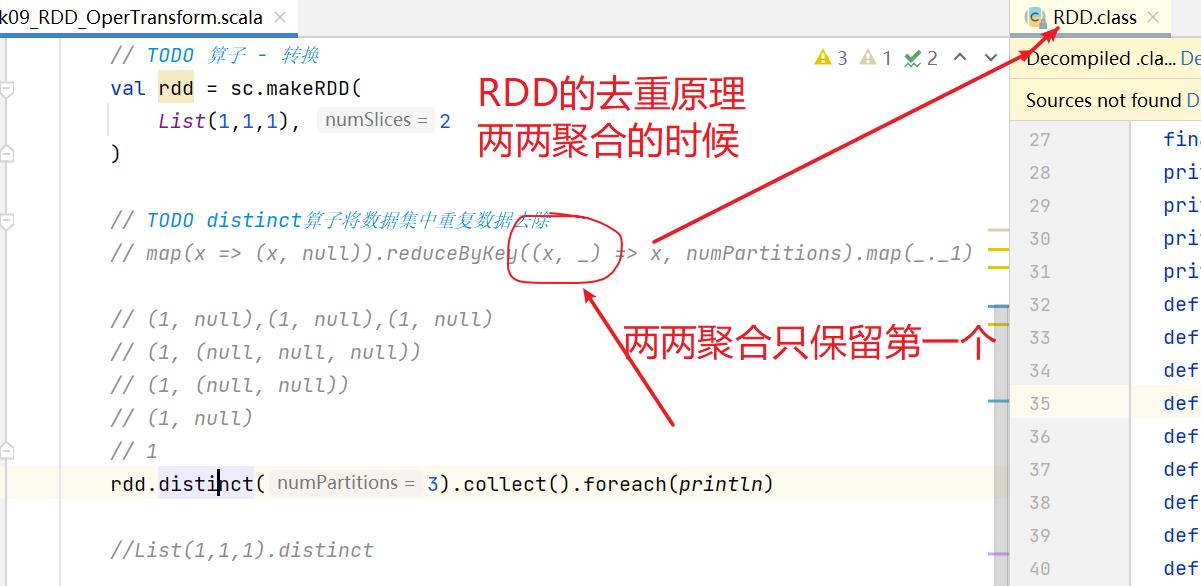
7.7: distinct
scala使用的是单点集合(缺点,单点的资源有限),而RDD使用的是集群去重
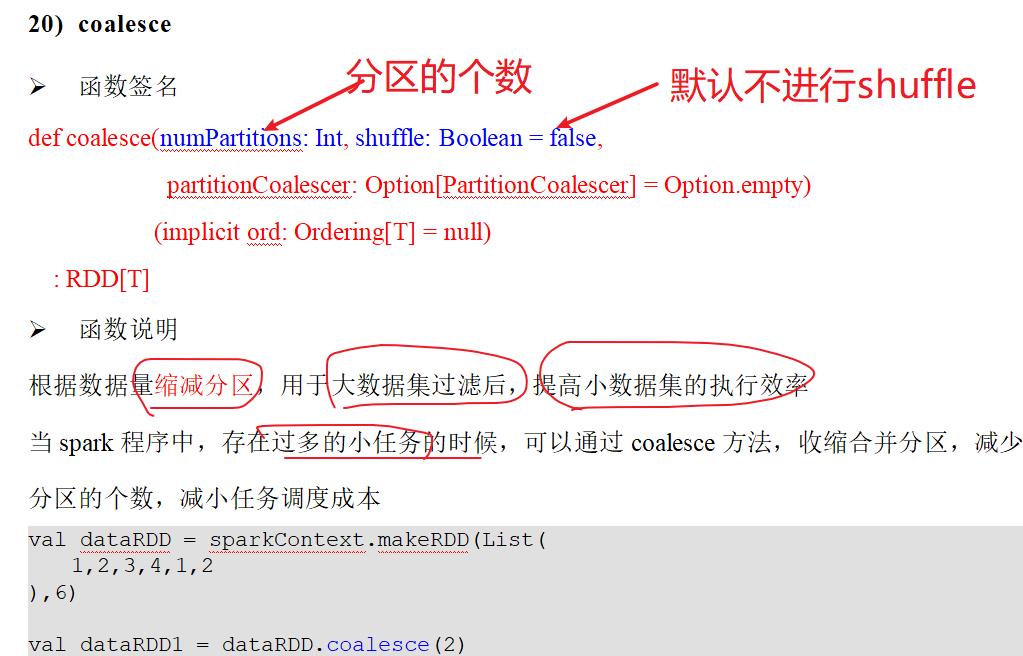
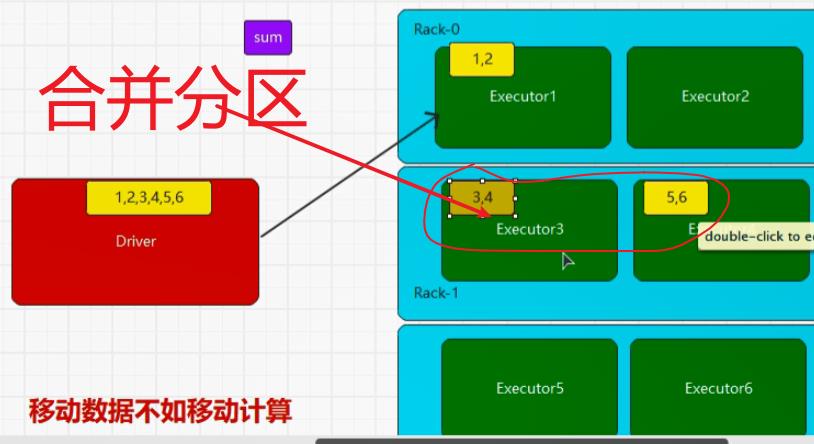
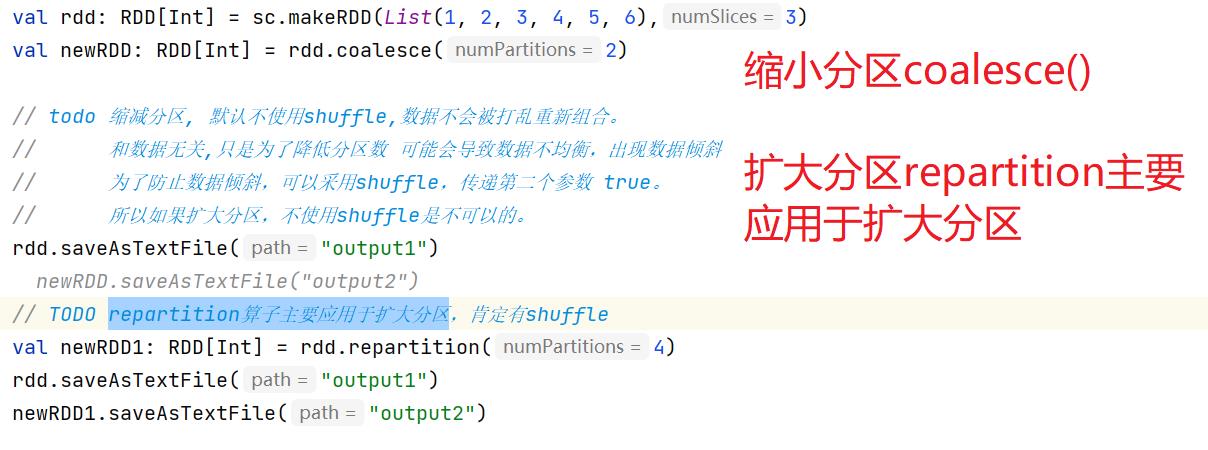
7.8:coalesce(缩小分区) 与 repartition(扩大分区)

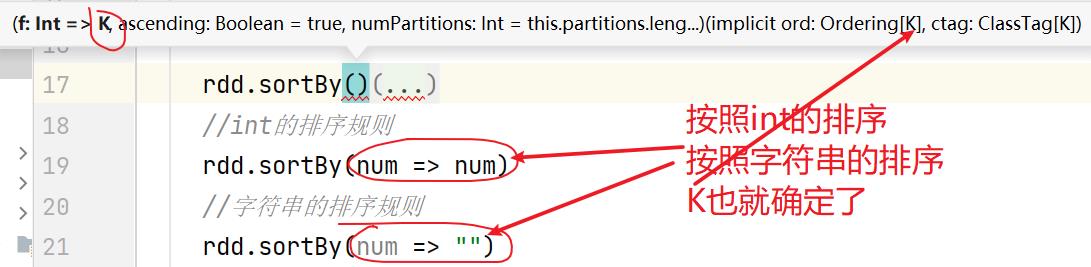
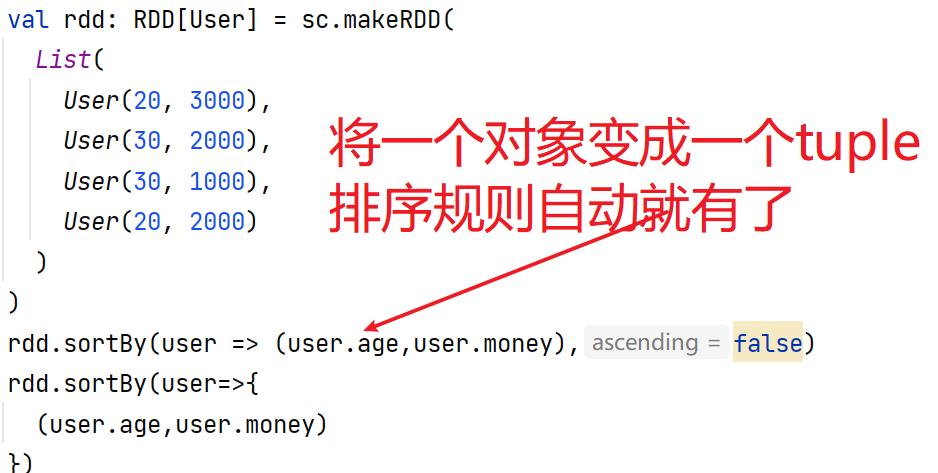
7.9:sortBy()




八:双值类型数据集的算子(交集并集差集拉链)
单Value(单一数据集)数据操作,双Value(多个数据集)数据操作







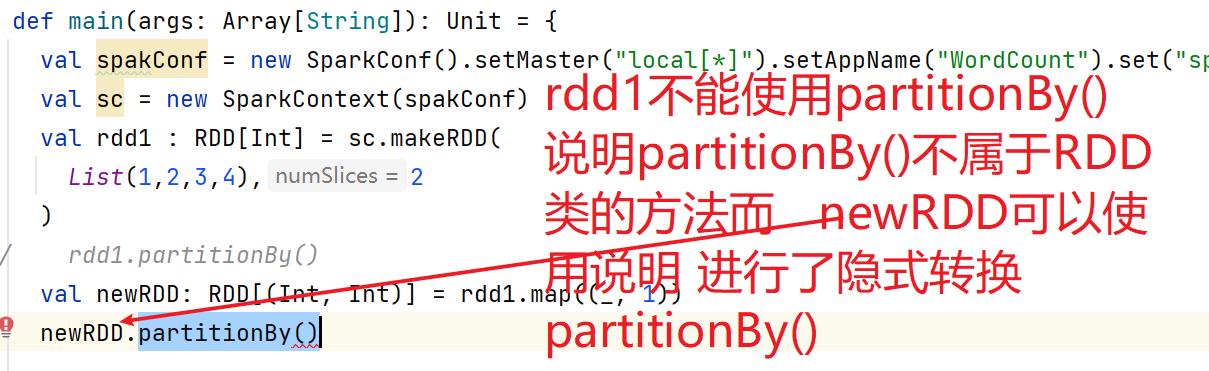
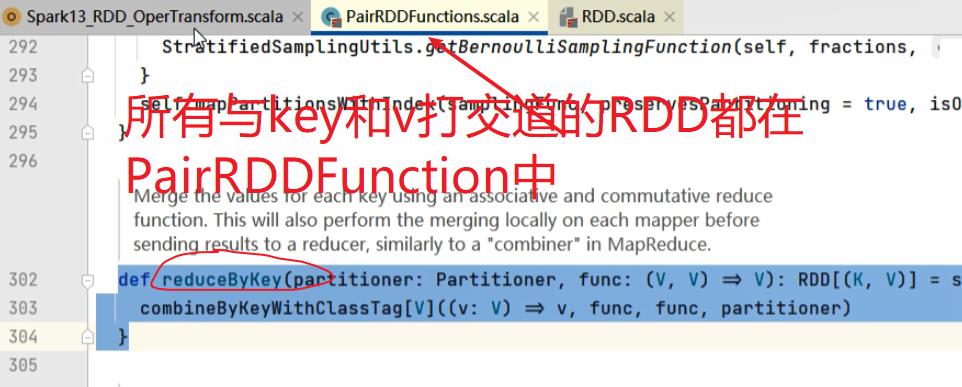
九:Key - Value类型算子(隐式转换rddToPairRDDFunction)
9.1:partitionBy()
repartition : 重分区(分区数量)
partitionBy : 重分区(数据的位置 数据进入到哪个分区), 数据路由(Hash定位),分区器 如果想要让数据重新进行分区,那么需要传递
以上是关于Spark详细总结的主要内容,如果未能解决你的问题,请参考以下文章