花了一周时间,终于把python爬虫入门必学知识整理出来了
Posted 朝阳区靓仔_James
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了花了一周时间,终于把python爬虫入门必学知识整理出来了相关的知识,希望对你有一定的参考价值。
Python是近几年最火热的编程语言,大家既然看到了爬虫的知识,想必也了解到python。
很多都说python与爬虫就是一对相恋多年的恋人,二者如胶似漆 ,形影不离,你中有我、我中有你,有python的地方绝对离不开爬虫,有爬虫的地方,话题永远都绕不开python。
因为小编也正在学习python编程,所以花了一周时间,将关于python爬虫入门知识整理出来了,这些知识个人觉得是非常重要的,所以希望大家可以收藏起来,不要弄丢哦,毕竟辛苦了这么久。

什么是爬虫
爬虫是一个程序,这个程序的目的就是为了抓取万维网信息资源,比如你日常使用的谷歌等搜索引擎,搜索结果就全都依赖爬虫来定时获取。
简单来说,无论你想获得哪些数据,有了爬虫都可以搞定,不论是文字、图片、视频,任何结构化非结构化的都能解决。
爬虫模块
re模块——正则表达式模块:
是用于快速从一大堆字符中快速找出想要的子字符串的一种表达方式,这个模块是初学者必须要弄清楚的,当你刚开始用的时候会觉得有难度,一旦上手了,你就会爱上它,逻辑性是非常强的。
os模块:
对文件文本的操作,可以创建文件夹,访问文件夹内容等,它会自适应于不同的操作系统平台,根据不同的平台进行相应的操作。
比如说我们常见的os.name,“name”顾名思义就是“名字”,这里的名字是指操作系统的名字,主要作用是判断目前正在使用的平台,也要注意到该命令不带括号。
csv模块:
爬取出来的数据可以以csv的格式保存,可以用office办公软件中的Excel表格软件打开,所以一般都是用于读文件、写文件、定义格式。
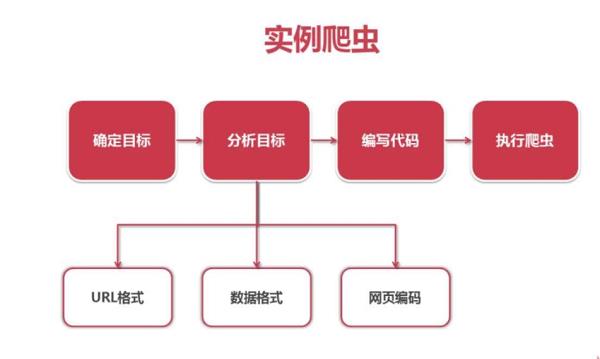
基础的抓取操作
Urllib:
是python内置的HTTP请求库,简单的例子:
import urllib.request
response = urllib.request.urlopen(‘https://blog.csdn.net/weixin_43499626’)
print(response.read().decode(‘utf-8’))
Requests:
requests库是一个非常实用的HTPP客户端库,是抓取操作最常用的一个库。
各种请求方式:常用requests.get()和requests.post()
import requests
r = requests.get(‘https://api.github.com/events’)
r1 = requests.get(‘http://httpbin.org/post’,data=‘key’:‘value’)
Requests它会比urllib更加方便,可以节约我们大量的工作。

需要登录的接口
post请求:
直接上代码,就能看懂的解释
import requests
url = “http://test”
data = “key”:“value”
res = requests.post(url=url,data=data)print(res.text)
get请求:
@classmethod
def send_get(cls, url, params, headers):
response = cls.SessionRequest.get(url=url, params=params, headers=headers)
return response.json()
常见的反爬有哪些
从功能上来讲,爬虫一般分为数据采集,处理,储存三个部分。这里我们只讨论数据采集部分。
通过Headers:
反爬虫从用户请求的Headers反爬虫是最常见的反爬虫策略,果遇到了这类反爬虫机制,可以直接在爬虫中添加Headers,将浏览器的User-Agent复制到爬虫的Headers中;或者将Referer值修改为目标网站域名。
基于用户行为反爬虫:
同一IP短时间内多次访问同一页面,或者同一账户短时间内多次进行相同操作。[这种防爬,需要有足够多的ip来应对],对于这种情况,使用IP代理就可以解决。可以专门写一个爬虫,爬取网上公开的代理ip,检测后全部保存起来。
动态页面的反爬虫:
上述的几种情况大多都是出现在静态页面,还有一部分网站,我们需要爬取的数据是通过ajax请求得到,。首先用Firebug或者HttpFox对网络请求进行分析,如果能够找到ajax请求,也能分析出具体的参数和响应的具体含义,我们就能采用上面的方法,直接利用requests或者urllib2模拟ajax请求,对响应的json进行分析得到需要的数据。
关于Python技术储备
学好 Python 不论是就业还是做副业赚钱都不错,但要学会 Python 还是要有一个学习规划。最后大家分享一份全套的 Python 学习资料,给那些想学习 Python 的小伙伴们一点帮助!
一、Python所有方向的学习路线
Python所有方向路线就是把Python常用的技术点做整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。
二、学习软件
工欲善其事必先利其器。学习Python常用的开发软件都在这里了,给大家节省了很多时间。
三、入门学习视频
我们在看视频学习的时候,不能光动眼动脑不动手,比较科学的学习方法是在理解之后运用它们,这时候练手项目就很适合了。
四、实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。
五、面试资料
我们学习Python必然是为了找到高薪的工作,下面这些面试题是来自阿里、腾讯、字节等一线互联网大厂最新的面试资料,并且有阿里大佬给出了权威的解答,刷完这一套面试资料相信大家都能找到满意的工作。
这份完整版的Python全套学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

以上是关于花了一周时间,终于把python爬虫入门必学知识整理出来了的主要内容,如果未能解决你的问题,请参考以下文章