JS基础 正则表达式
Posted wgchen~
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了JS基础 正则表达式相关的知识,希望对你有一定的参考价值。
阅读目录
基础知识
正则表达式是用于匹配字符串中字符组合的模式,在 javascript 中,正则表达式也是对象。
- 正则表达式是在宿主环境下运行的,如
js/php/node.js等 - 本章讲解的知识在其他语言中知识也是可用的,会有些函数使用上的区别
对比分析
与普通函数操作字符串来比较,正则表达式可以写出更简洁、功能强大的代码。
下面使用获取字符串中的所有数字来比较函数与正则的差异。
let hd = "wgchen2200blog9988";
let nums = [...hd].filter(a => !Number.isNaN(parseInt(a)));
console.log(nums.join("")); // 22009988
使用正则表达式将简单得多
<script>
let hd = "wgchen2200blog9988";
console.log(hd.match(/\\d/g).join("")); // 22009988
</script>
创建正则
JS 提供字面量与对象两种方式创建正则表达式
字面量创建
使用 // 包裹的字面量创建方式是推荐的作法,但它不能在其中使用变量
let hd = "wgchen.com";
console.log(/u/.test(hd));//false
let hd = "wgchen_u_willem.com";
console.log(/u/.test(hd));//true
下面尝试使用 a 变量时将不可以查询
let hd = "wgchen_u_willem.com";
let a = "u";
console.log(/a/.test(hd)); //false
虽然可以使用 eval 转换为 js 语法来实现将变量解析到正则中,但是比较麻烦,所以有变量时建议使用下面的对象创建方式
let hd = "wgchen_u_willem.com";
let a = "u";
console.log(eval(`/$a/`).test(hd)); //true
对象创建
当正则需要动态创建时使用对象方式
let hd = "csdn.net";
let web = "csdn";
let reg = new RegExp(web);
console.log(reg.test(hd)); //true
根据用户输入高亮显示内容,支持用户输入正则表达式

<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<title>wgchen</title>
</head>
<body>
<div id="content">wgchen.blog.csdn.net</div>
</body>
<script>
const content = prompt("请输入要搜索的内容,支持正则表达式");
const reg = new RegExp(content, "g");
let body = document
.querySelector("#content")
.innerHTML.replace(reg, str =>
return `<span style="color:red">$str</span>`;
);
document.body.innerHTML = body;
</script>
</html>
通过对象创建正则提取标签
<body>
<h1>wgchen.blog.csdn.net</h1>
<h1>willem.name</h1>
</body>
<script>
function element(tag)
const html = document.body.innerHTML;
let reg = new RegExp("<(" + tag + ")>.+</\\\\1>", "g");
return html.match(reg);
console.table(element("h1"));
</script>

选择符
| 这个符号带表选择修释符,也就是 | 左右两侧有一个匹配到就可以。
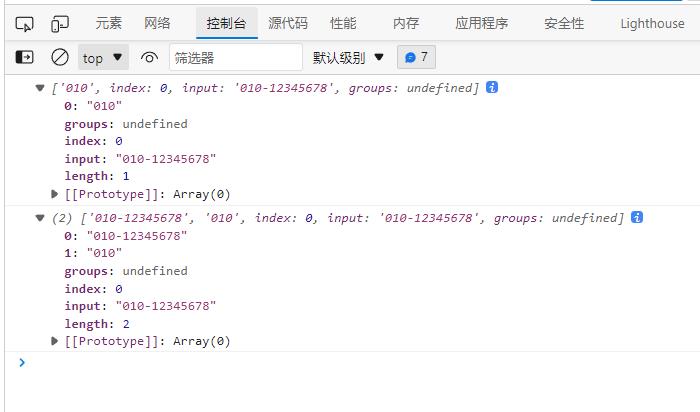
检测电话是否是上海或北京的坐机
let tel = "010-12345678";
//错误结果:只匹配 | 左右两边任一结果
console.log(tel.match(/010|020\\-\\d7,8/));
//正确结果:所以需要放在原子组中使用
console.log(tel.match(/(010|020)\\-\\d7,8/));
匹配字符是否包含 wgchen 或 willem
const hd = "wgchen";
console.log(/wgchen|willem/.test(hd)); //true
字符转义
转义用于改变字符的含义,用来对某个字符有多种语义时的处理。
假如有这样的场景,如果我们想通过正则查找 / 符号,但是 / 在正则中有特殊的意义。如果写成 /// 这会造成解析错误,所以要使用转义语法 /\\// 来匹配。
const url = "https://wgchen.blog.csdn.net";
console.log(/https:\\/\\//.test(url)); //true
使用 RegExp 构建正则时在转义上会有些区别,下面是对象与字面量定义正则时区别
let price = 12.23;
//含义1: . 除换行外任何字符 含义2: .普通点
//含义1: d 字母d 含义2: \\d 数字 0~9
console.log(/\\d+\\.\\d+/.test(price)); // true
//字符串中 \\d 与 d 是一样的,所以在 new RegExp 时\\d 即为 d
console.log("\\d" == "d"); // true
//使用对象定义正则时,可以先把字符串打印一样,结果是字面量一样的定义就对了
console.log("\\\\d+\\\\.\\\\d+"); // \\d+\\.\\d+
let reg = new RegExp("\\\\d+\\\\.\\\\d+");
console.log(reg.test(price)); // true
下面是网址检测中转义符使用
let url = "https://wgchen.blog.csdn.net";
console.log(/https?:\\/\\/\\w+\\.\\w+\\.\\w+/.test(url)); // true
字符边界
使用字符边界符用于控制匹配内容的开始与结束约定。
| 边界符 | 说明 |
|---|---|
| ^ | 匹配字符串的开始 |
| $ | 匹配字符串的结束,忽略换行符 |
匹配内容必须以 www 开始
const hd = "www.wgchen.com";
console.log(/^www/.test(hd)); //true
匹配内容必须以 .com 结束
const hd = "www.wgchen.com";
console.log(/\\.com$/.test(hd)); //true
检测用户名长度为 3~6 位,且只能为字母。如果不使用 ^ 与 $ 限制将得不到正确结果
<body>
<input type="text" name="username" />
</body>
<script>
document
.querySelector(`[name="username"]`)
.addEventListener("keyup", function()
let res = this.value.match(/^[a-z]3,6$/i);
console.log(res);
console.log(res ? "正确" : "失败");
);
</script>
元子字符是正则表达式中的最小元素,只代表单一(一个)字符
字符列表
| 元字符 | 说明 | 示例 |
|---|---|---|
| \\d | 匹配任意一个数字 | [0-9] |
| \\D | 与除了数字以外的任何一个字符匹配 | [^0-9] |
| \\w | 与任意一个英文字母,数字或下划线匹配 | [a-zA-Z_] |
| \\W | 除了字母,数字或下划线外与任何字符匹配 | [^a-zA-Z_] |
| \\s | 任意一个空白字符匹配,如空格,制表符\\t,换行符\\n | [\\n\\f\\r\\t\\v] |
| \\S | 除了空白符外任意一个字符匹配 | [^\\n\\f\\r\\t\\v] |
| . | 匹配除换行符外的任意字符 |
使用体验
匹配任意数字
let hd = "wgchen 2010";
console.log(hd.match(/\\d/g)); //["2", "0", "1", "0"]
匹配所有电话号码
let hd = `
张三:010-99999999,李四:020-88888888
`;
let res = hd.match(/\\d3-\\d7,8/g);
console.log(res); // (2) ['010-99999999', '020-88888888']
获取所有用户名
let hd = `
张三:010-99999999,李四:020-88888888`;
let res = hd.match(/[^:\\d-,]+/g);
console.log(res); // (2) ['\\n张三', '李四']
匹配任意非数字
console.log(/\\D/.test(2029)); //false
匹配字母数字下划线
let hd = "hdcms@";
console.log(hd.match(/\\w/g)); //["h", "d", "c", "m", "s"]
匹配除了字母,数字或下划线外与任何字符匹配
console.log(/\\W/.test("@")); //true
匹配与任意一个空白字符匹配
console.log(/\\s/.test(" ")); //true
console.log(/\\s/.test("\\n")); //true
匹配除了空白符外任意一个字符匹配
let hd = "hdcms@";
console.log(hd.match(/\\S/g)); //["2", "0", "1", "0","@"]
如果要匹配点则需要转义
let hd = `wgchen@com`;
console.log(/wgchen.com/i.test(hd)); //true
console.log(/wgchen\\.com/i.test(hd)); //false
使用 . 匹配除换行符外任意字符
使用 . 匹配除换行符外任意字符,下面匹配不到 willem.com 因为有换行符
const url = `
https://wgchen.blog.csdn.net
willem.com
`;
console.log(url.match(/.+/)[0]);
// https://wgchen.blog.csdn.net
使用 /s 视为单行模式(忽略换行)时,. 可以匹配所有
let hd = `
<span>
wgchen
willem
</span>
`;
let res = hd.match(/<span>.*<\\/span>/s);
console.log(res[0]);

正则中空格会按普通字符对待
let tel = `010 - 999999`;
console.log(/\\d+-\\d+/.test(tel)); //false
console.log(/\\d+ - \\d+/.test(tel)); //true
匹配所有字符
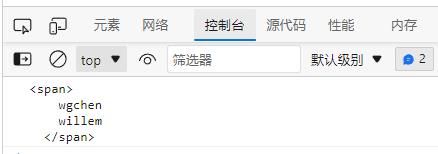
可以使用 [\\s\\S] 或 [\\d\\D] 来匹配所有字符
<script>
let hd = `
<span>
wgchen
willem
</span>
`;
let res = hd.match(/<span>[\\s\\S]+<\\/span>/);
console.log(res[0]);
</script>
模式修饰
正则表达式在执行时会按他们的默认执行方式进行,但有时候默认的处理方式总不能满足我们的需求,所以可以使用模式修正符更改默认方式。
| 修饰符 | 说明 |
|---|---|
| i | 不区分大小写字母的匹配 |
| g | 全局搜索所有匹配内容 |
| m | 视为多行 |
| s | 视为单行忽略换行符,使用. 可以匹配所有字符 |
| y | 从 regexp.lastIndex 开始匹配 |
| u | 正确处理四个字符的 UTF-16 编码 |
i 将所有 wgchen.com 统一为小写
let hd = "wgchen.com WGCHEN.COM";
hd = hd.replace(/wgchen\\.com/gi, "wgchen.com");
console.log(hd); // wgchen.com wgchen.com
g 修饰符可以全局操作内容
let hd = "wgchen_willem";
hd = hd.replace(/e/, "@");
console.log(hd); //没有使用 g 修饰符是,只替换了第一个
// wgch@n_willem
let dh = "wgchen_willem";
dh = dh.replace(/e/g, "@");
console.log(dh); //使用全局修饰符后替换了全部的 u
// wgch@n_will@m
m 用于将内容视为多行匹配,主要是对 ^ 和 $ 的修饰
将下面是将以 # 数字开始的课程解析为对象结构,学习过后面讲到的原子组可以让代码简单些
let hd = `
#1 js,200元 #
#2 php,300元 #
#9 wgchen.com # willem
#3 node.js,180元 #
`;
// [name:'js',price:'200元']
let lessons = hd.match(/^\\s*#\\d+\\s+.+\\s+#$/gm).map(v =>
v = v.replace(/\\s*#\\d+\\s*/, "").replace(/\\s+#/, "");
[name, price] = v.split(",");
return name, price ;
);
console.log(JSON.stringify(lessons, null, 2));

u 正确处理四个字符的 UTF-16 编码
每个字符都有属性,如 L 属性表示是字母,P 表示标点符号,需要结合 u 模式才有效。其他属性简写可以访问属性的别名 (opens new window)网站查看。
//使用\\pL属性匹配字母
let hd = "wgchen2010.不断发布技术博客,加油!";
console.log(hd.match(/\\pL+/u));
//使用\\pP属性匹配标点
console.log(hd.match(/\\pP+/gu));

字符也有 unicode 文字系统属性 Script=文字系统,下面是使用 \\psc=Han 获取中文字符 han 为中文系统,其他语言请查看 文字语言表
let hd = `
张三:010-99999999,李四:020-88888888`;
let res = hd.match(/\\psc=Han+/gu);
console.log(res); // (2) ['张三', '李四']
使用 u 模式可以正确处理四个字符的 UTF-16 字节编码
let str = "𝒳𝒴";
console.table(str.match(/[𝒳𝒴]/)