Parquet文件是怎么被写入的-Row Groups,Pages,需要的内存,以及flush操作
Posted 鸿乃江边鸟
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Parquet文件是怎么被写入的-Row Groups,Pages,需要的内存,以及flush操作相关的知识,希望对你有一定的参考价值。
翻译该文的目的是为了让读者能够更好的理解Parquet文件的写入原理
Parquet文件是最流行的列式文件格式之一,它被用在很多工具上,如Apache Hive,Spark,Presto,Flink等。
对于在各种工作场景下,我们怎么深入的调优Parquet文件写入呢?(此文针对于Parquet 1.10.0,但是很多概念在以后的版本中也适用)
Parquet文件格式结构
一个Parquet文件由一个或者多个Row Groups组成,一个Row Groups由包含每一列的数据块组成,每个数据块包含了一个或者多个page,该page中包含了列数据。

所以,一个Row Group包含了一些行的所有列(在一个文件中是可以变的,下面会提到),对于一个Row Group,首先你看到的是一个列的内容,再者是第二列的内容,以此类推。
如果以后你需要某个Parquet文件的某一列,你需要读取所有Row Group的对应的列快,而不是所有Row Group所有内容。
写一行数据
虽然Parquet文件是列式存储,但是这个只是部内表示,你仍需要需要一行一行的写:InternalParquetRecordWriter.write(row)
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-33xtPrVs-1644330856464)(http://cloudsqale.com/wp-content/uploads/2020/05/parquet_write2.png)]
每一行会被立即切成不同的列,并分别存储到不同的内存Column存储中。最大值/最小值以及null值会被更新到对应的列中。
现在一切的存储还在内存中。
Page
在写了100个数据的时候(对应100行),Parquet writer会检查这100个列值是否超过了指定的Page大小(默认是1MB)。
假如一个列的的原始数据没超过page的大小阈值,然后下一个page的大小会基于当前的实际列的大小进行调整,所以它既不是每一个列数据都检查一下,也不是每100列数据检查一下。因此Page大小不是固定的。
假如原始数据没有超过了Page大小,那么列内容就会被压缩(如果制定了压缩格式的话),并且被flush到列的Page存储中。
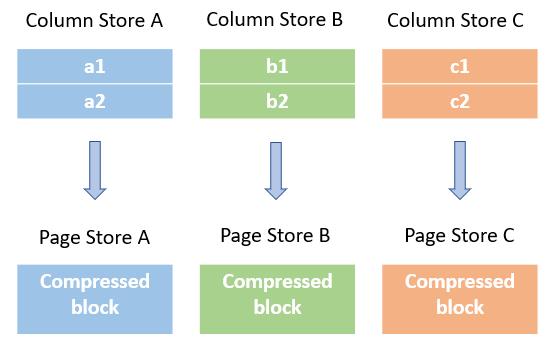
每一Page包含了元数据(Page header),元数据中包含了未压缩的数据大小,值的数量,以及统计信息:在这个page中这个列的最大最小值和null值的数量。
这个时候一切也还是在内存中,但是数据现在是压缩的了。
Row Group(block size)
在写了第一个100行数据到内存中以后,这个Parquet writer会检查数据的大小是否超过了pqrquet指定的Row Group大小(block size)(默认是128MB)。
这个大小包括了每一列在column存储中未压缩的数据大小(还没有被flushed到Page存储中)和每一列已经写入到Page存储中的压缩的数据大小。
假如数据大小没有超过指定的row group大小,Parquet writer将会根据平均的行大小来估算下一个row group大小,有可能是100甚至10000行,所哟row group大小限制也不是很严格。
假如数据大小超过了指定的row group大小,Parquet writer将会flush每一列column存储的数据到Page存储中,然后一列一列的将所有Page存储中数据的写到输出流中。

这是第一次数据被写到外部的流中(HadoopPositionOutputStream),这对外部组件可见,但是对终端用户不可见,例如 S3 Multipart Upload传输线程能够在后台上传数据到S3中。
注意:Row Group内容并不包含任何元数据(如统计信息,offset等),这些元数据信息会被写到footer中。
File Footer
当所有的row groups写到外部流中,并在关闭文件之前,Parquet writer将会在文件的末尾加上footer。
Footer包含了文件的schema(列名字和对应的类型)和关于每一个row group的细节(总的大小,行数,最大最小值,每一列的null值数量)。注意这些列的统计信息是row group级别的,而不是文件级别的。
把所有的元数据写到footer中,可以让Parquet writer不需要保c存整个文件在内存中或者磁盘里,这就是为什么row group能够安全的被flushed。
Logging
你可以通过查看应用日志来看Parquet writer是怎么工作的。这里有好几个重要的info信息。
假如当前的row group大小超过了row group的阈值-–checkBlockSizeReached():
LOG.info("mem size > : flushing records to disk.", memSize, nextRowGroupSize, recordCount);
真实的应用例子如下:
May 29, 2020 1:58:35 PM org.apache.parquet.hadoop.InternalParquetRecordWriter checkBlockSizeReached
INFO: mem size 268641769 > 268435456: flushing 324554 records to disk.
以上日志说明,当前的数据大小是 268,641,769 bytes,然而row group大小是268,435,456 (256 MB),所以324,554行数据被flushed到外部流中。
当一个row group 被flushed之后,你会看到如下日志信息-flushRowGroupToStore():
LOG.info("Flushing mem columnStore to file. allocated memory: ", columnStore.getAllocatedSize());
注意columnStore大小包括了Page存储的大小。
真实的应用例子如下:
May 29, 2020 1:58:35 PM org.apache.parquet.hadoop.InternalParquetRecordWriter flushRowGroupToStore
INFO: Flushing mem columnStore to file. allocated memory: 199496450
本文翻译自How Parquet Files are Written – Row Groups, Pages, Required Memory and Flush Operations
以上是关于Parquet文件是怎么被写入的-Row Groups,Pages,需要的内存,以及flush操作的主要内容,如果未能解决你的问题,请参考以下文章
使用 Spark 通过 s3a 将 parquet 文件写入 s3 非常慢
Azure Databricks - 将 Parquet 文件写入策划区域
Flink实战系列Flink使用StreamingFileSink写入HDFS(parquet格式snappy压缩)
将 Parquet 文件从 Spark RDD 写入动态文件夹