机器学习笔记 时间序列预测(最基本的方法benchmark)
Posted UQI-LIUWJ
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习笔记 时间序列预测(最基本的方法benchmark)相关的知识,希望对你有一定的参考价值。
1 最基本的方法
这些方法将作为这个系列的benchmark
有时,这些简单方法中的一种将是可用的最佳预测方法; 但在许多情况下,这些方法将作为基准而不是选择方法。 也就是说,我们开发的任何预测方法都将与这些简单的方法进行比较,以确保新方法优于这些简单的替代方法。 如果没有,新方法不值得考虑。
1.1 平均法
所有未来值的预测都等于历史数据的平均值(或“平均值”)。
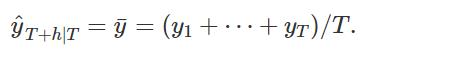
1.1.1 R语言实现
library(forecast)
y<-ts(c(5,3,3.1,3.2,3.3,3.4,3.5,3.3,3.2,4,4.1,4.2,
6,4,4.1,4.2,4.3,4.4,4.5,4.6,4.7,4.8,4.9,5,
10,9,8,8.5,8.4,8.5,8.6,8.7,8.8,8.9,9,9.5),
start = 2020,
frequency = 12)
meanf(y,5) Point Forecast Lo 80 Hi 80 Lo 95 Hi 95
Jan 2023 5.686111 2.571311 8.800911 0.8451045 10.52712
Feb 2023 5.686111 2.571311 8.800911 0.8451045 10.52712
Mar 2023 5.686111 2.571311 8.800911 0.8451045 10.52712
Apr 2023 5.686111 2.571311 8.800911 0.8451045 10.52712
May 2023 5.686111 2.571311 8.800911 0.8451045 10.527121.2 简单复制
对于简单的预测,我们只需将所有预测设置为最后一次观察的值。
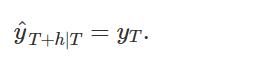
naive(y,5)
Point Forecast Lo 80 Hi 80 Lo 95 Hi 95
Jan 2023 9.5 8.135627 10.86437 7.413371 11.58663
Feb 2023 9.5 7.570485 11.42952 6.549061 12.45094
Mar 2023 9.5 7.136836 11.86316 5.885853 13.11415
Apr 2023 9.5 6.771254 12.22875 5.326743 13.67326
May 2023 9.5 6.449169 12.55083 4.834156 14.165841.3 季节性复制
类似的方法对于高度季节性的数据很有用。
在这种情况下,我们将每个预测设置为同一季节(例如,上一年的同一个月)的最后一个观测值。 形式上,时间 T+h 的预测写为
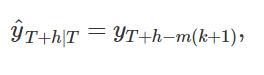
其中m表示周期,k是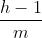 的整数部分(即,时间 T+h 之前预测期内的完整周期数)。
的整数部分(即,时间 T+h 之前预测期内的完整周期数)。
1.3.1 R语言实现
snaive(y,15)
Point Forecast Lo 80 Hi 80 Lo 95 Hi 95
Jan 2023 10.0 6.071882 13.92812 3.9924626 16.00754
Feb 2023 9.0 5.071882 12.92812 2.9924626 15.00754
Mar 2023 8.0 4.071882 11.92812 1.9924626 14.00754
Apr 2023 8.5 4.571882 12.42812 2.4924626 14.50754
May 2023 8.4 4.471882 12.32812 2.3924626 14.40754
Jun 2023 8.5 4.571882 12.42812 2.4924626 14.50754
Jul 2023 8.6 4.671882 12.52812 2.5924626 14.60754
Aug 2023 8.7 4.771882 12.62812 2.6924626 14.70754
Sep 2023 8.8 4.871882 12.72812 2.7924626 14.80754
Oct 2023 8.9 4.971882 12.82812 2.8924626 14.90754
Nov 2023 9.0 5.071882 12.92812 2.9924626 15.00754
Dec 2023 9.5 5.571882 13.42812 3.4924626 15.50754
Jan 2024 10.0 4.444803 15.55520 1.5040591 18.49594
Feb 2024 9.0 3.444803 14.55520 0.5040591 17.49594
Mar 2024 8.0 2.444803 13.55520 -0.4959409 16.49594· 我们在创建时间序列的时候,声明了周期为12(frequency),所以我们这里也是令m=12
1.4 Drift method 漂移法
另一种变体是允许预测随时间增加或减少,其中随时间的变化量(称为漂移)设置为历史数据中看到的平均变化。
因此,时间 T + h 的预测为
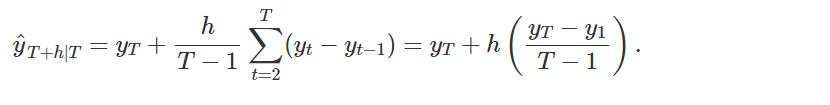
1.4.1 R语言实现
rwf(y,5,drift=TRUE)
Point Forecast Lo 80 Hi 80 Lo 95 Hi 95
Jan 2023 9.628571 8.254411 11.00273 7.526975 11.73017
Feb 2023 9.757143 7.786220 11.72807 6.742876 12.77141
Mar 2023 9.885714 7.438540 12.33289 6.143084 13.62834
Apr 2023 10.014286 7.150601 12.87797 5.634658 14.39391
May 2023 10.142857 6.899307 13.38641 5.182275 15.10344如果不加’drift=TRUE‘的话,rwf(y,5)和naive(y,5)效果是一样的
1.5 四者对比(可视化)
library(forecast)
library(ggplot2)
y<-ts(c(5,3,3.1,3.2,3.3,3.4,3.5,3.3,3.2,4,4.1,4.2,
6,4,4.1,4.2,4.3,4.4,4.5,4.6,4.7,4.8,4.9,5,
10,9,8,8.5,8.4,8.5,8.6,8.7,8.8,8.9,9,9.5),
start = 2020,
frequency = 12)
y_pre=window(y,start=2020,end=c(2022,2))
y_pre
# Jan Feb Mar Apr May Jun Jul Aug
#2020 5.0 3.0 3.1 3.2 3.3 3.4 3.5 3.3
#2021 6.0 4.0 4.1 4.2 4.3 4.4 4.5 4.6
#2022 10.0 9.0
# Sep Oct Nov Dec
#2020 3.2 4.0 4.1 4.2
#2021 4.7 4.8 4.9 5.0
#2022
y_naive=naive(y_pre,h=10)
y_mean=meanf(y_pre,h=10)
y_snaive=snaive(y_pre,h=10)
y_drift=rwf(y_pre,h=10,drift=TRUE)
autoplot(y)+
autolayer(y_mean,series='mean',PI=FALSE)+
autolayer(y_naive,series='naive',PI=FALSE)+
autolayer(y_snaive,series='snaive',PI=FALSE)+
autolayer(y_drift,series'drift',PI=FALSE)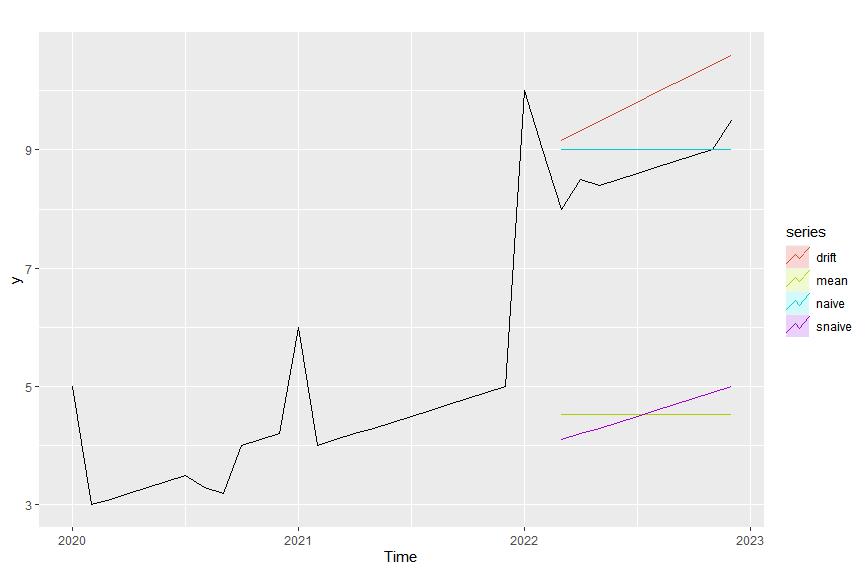
1.5.1 不同评价函数下的对比
accuracy(y_mean,y_test)
# ME RMSE MAE
#Training set 1.025822e-16 1.608336 1.017160
#Test set 4.159231e+00 4.176614 4.159231
# MPE MAPE MASE
#Training set -8.620051 21.37827 0.6717093
#Test set 47.763243 47.76324 2.7466618
# ACF1 Theil's U
#Training set 0.5666206 NA
#Test set 0.4126294 16.59598以上是关于机器学习笔记 时间序列预测(最基本的方法benchmark)的主要内容,如果未能解决你的问题,请参考以下文章