datax实现mysql数据同步
Posted 小码农叔叔
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了datax实现mysql数据同步相关的知识,希望对你有一定的参考价值。
前言
DataX 是阿里内部广泛使用的离线数据同步工具/平台,可以实现包括 mysql、Oracle、HDFS、Hive、OceanBase、HBase、OTS、ODPS 等各种异构数据源之间高效的数据同步功能。DataX采用了框架 + 插件 的模式,目前已开源,代码托管在github
git地址:https://github.com/alibaba/DataX
特性简介
DataX本身作为数据同步框架,将不同数据源的同步抽象为从源头数据源读取数据的Reader插件,以及向目标端写入数据的Writer插件,理论上DataX框架可以支持任意数据源类型的数据同步工作。同时DataX插件体系作为一套生态系统, 每接入一套新数据源该新加入的数据源即可实现和现有的数据源互通。
使用场景
通常是在服务暂停的情况下,短时间将一份数据从一个数据库迁移至其他不同类型的数据库
优点:
- 提供了数据监控
- 丰富的数据转换功能,可以重新定制Reader,Writer插件实现数据脱敏,补全,过滤等数据转换功能
- 可以在配置文件中配置精确的速度控制
- 强劲的同步性能,支持多线程操作,可以快速迁移数据
- 健壮的容错机制,支持线程重试等机制,可以保证迁移过程稳定执行
缺点:
数据一致性问题。这个工具强烈建议在服务暂停或者禁止执行写操作的情况下使用。如果在迁移的过程中还有写操作的话,这些增量数据无法实时从源数据库同步到目的数据库,无法保证迁移前后数据一致性。
前置准备
在上面的github地址中找到安装包,下载并上传到服务器指定目录


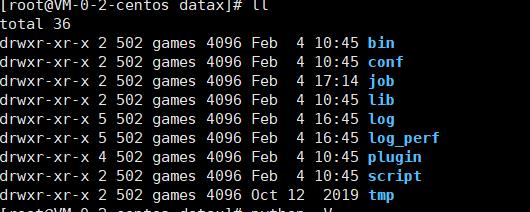
上传到服务器指定目录后进行解压即可,同时需要确保服务器安装了python环境,python的版本应大于2.6

目录简介
- bin ,主要包括3个跟任务启动相关的python脚本
- conf , 任务运行时的核心配置文件,以及日志输出的配置文件
- lib , 任务运行过程中依赖的jar包
- log ,存放日志的位置
- job , 存放使用者自定义读取和写出数据源的配置文件的位置
- plugin , 读取输入数据以及写出数据时各类异构数据源解析器的位置
更详细的参考github官方解释
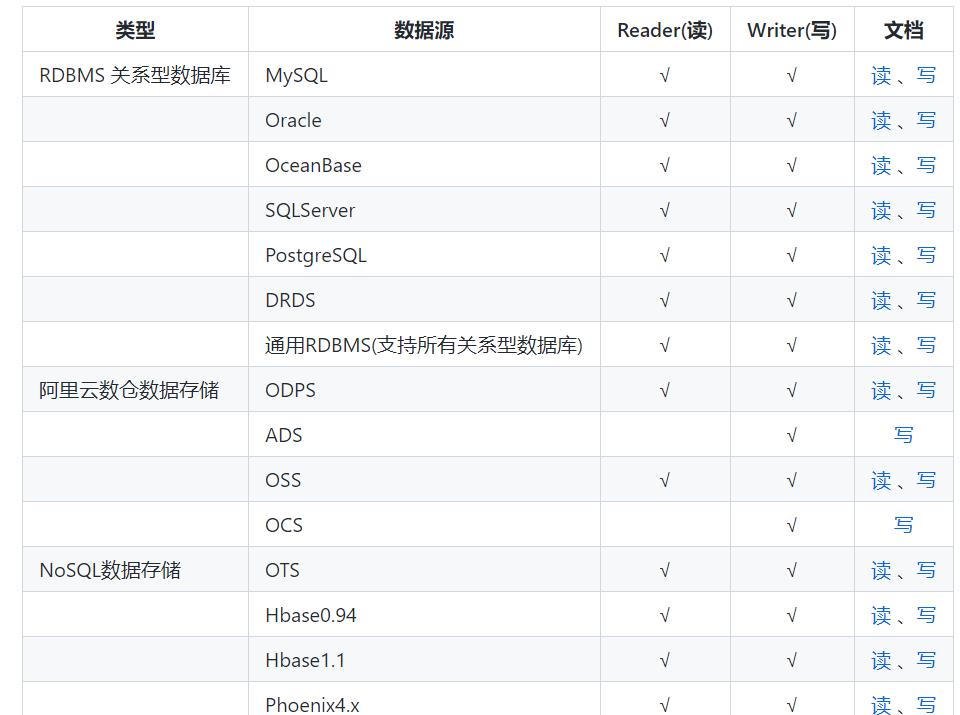
使用datax进行异构数据从源头数据源写出到目标数据源步骤是固定的,官方支持的不同数据源之间的互相写入写出有很多种,理论上互相之间都是可以的,可以参考“文档”那一栏的读写进行配置即可
使用案例一:MySql到MySql数据同步
1、在job目录下新增配置文件,格式以 .json结尾
比较好的做法是,从git上拷贝官方提供的模板配置文件,然后结合实际的业务情况,修改源地址连接信息,表,字段等,以及目标地址信息,表,字段等,最后将配置文件上传到 job目录下
"job":
"setting":
"speed":
"channel": 3
,
"errorLimit":
"record": 0,
"percentage": 0.02
,
"content": [
"reader":
"name": "mysqlreader",
"parameter":
"username": "root",
"password": "root",
"column": [
"id",
"name"
],
"connection": [
"table": [
"user_info" #表名
],
"jdbcUrl": [
"jdbc:mysql://IP1:3306/shop001" #源地址
]
]
,
"writer":
"name": "streamwriter",
"parameter":
"print":true, #开启任务运行过程中的打印
"column": [
"id","name" #待同步的字段
],
"connection": [
"jdbcUrl": "jdbc:mysql://IP2:3306/shop001", #目标地址
"table": ["user_info_copy"] #目标表
],
"password": "root",
"username": "root"
]
2、上传上面的配置文件到job目录
或者直接在job目录下创建配置文件进行修改,不建议这么做,配置参数复杂的话容易搞错,配置文件编写完毕后,最好找个可以格式化的地方,检查下配置文件是否是正确的json形式

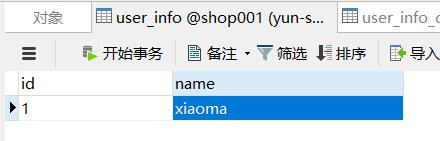
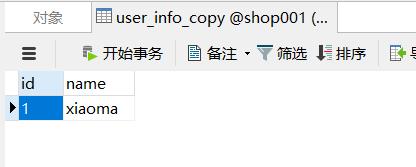
3、在shop001数据库下创建2张表
这个工作可以提前做好,给源表user_info插入一条数据,两个表基本相同,我们的目标是通过上面的配置运行job后,将user_info的数据同步到 user_info_copy中去
4、启动并运行任务
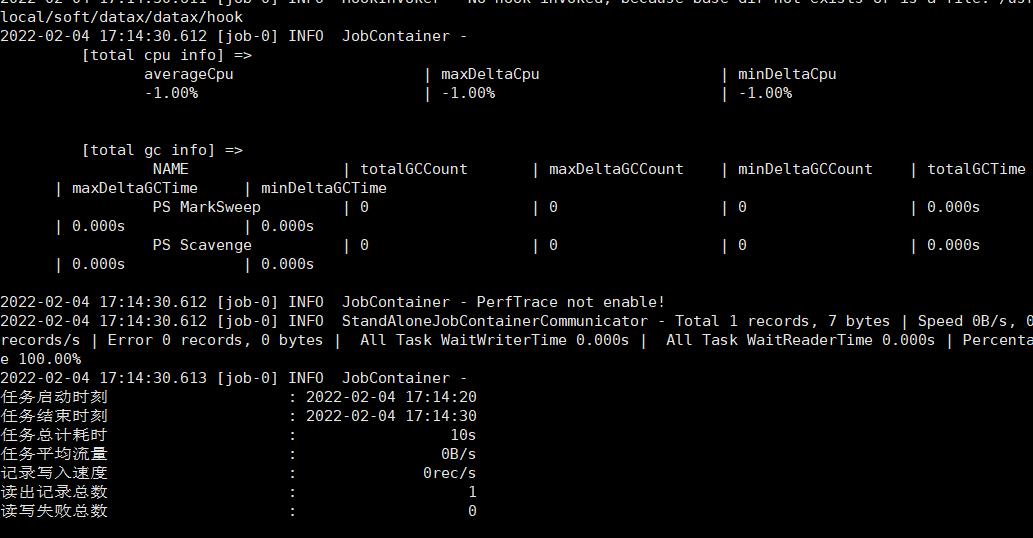
进入到datax主目录下,使用下面的命令运行同步任务,看到下面运行完毕的日志后,可以去观察user_info_copy表数据是否同步成功
./bin/datax.py job/mysql2sql.json
使用案例二:本地CSV文件到MySql数据同步
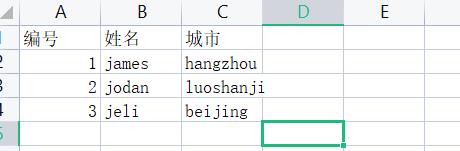
1、提前准备一个csv文件
并上传到服务器指定目录下

2、和上面同步mysql数据一样,提供一个job的配置文件
"job":
"content": [
"reader":
"name": "txtfilereader",
"parameter":
"path": ["/usr/local/soft/datax/datax/job/test.csv"],
"encoding":"utf-8",
"column": [
"index": 0,
"type": "string"
,
"index": 1,
"type": "string"
,
"index": 2,
"type": "string"
],
"skipHeader": "true"
,
"writer":
"name": "mysqlwriter",
"parameter":
"column": [
"id",
"name",
"city"
],
"connection": [
"jdbcUrl": "jdbc:mysql://IP:3306/shop001?useUnicode=true&characterEncoding=utf8",
"table": ["boss_info"]
],
"password": "root",
"username": "root",
"preSql":[""],
"session":["set session sql_mode='ANSI'"],
"writeMode":"insert"
],
"setting":
"speed":
"channel": "1"
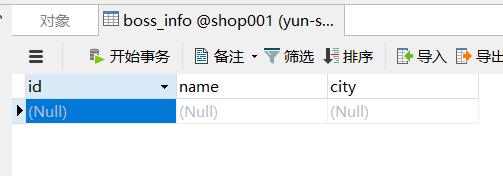
3、在shop001数据库下创建一张boss_info的表
注意字段类型要和上面的配置文件中csv中指定的字段类型一致
最后执行启动job的命令
./bin/datax.py job/csv2mysql.json
注意点:reader中定义的字段类型需要和目标表中的字段类型保持一致
使用案例三:mysql同步数据到mongodb
从mysql同步数据到mongodb 也是实际业务中一种比较常见的场景,这里直接贴出核心的配置
"job":
"setting":
"speed":
"channel": 2
,
"content": [
"reader":
"name": "mysqlreader",
"parameter":
"username": "root",
"password": "root",
"column": [
"id",
"name"
],
"connection": [
"table": [
"user_info"
],
"jdbcUrl": [
"jdbc:mysql://IP:3306/shop001"
]
]
,
"writer":
"name": "mongodbwriter",
"parameter":
"address": [
"127.0.0.1:27017"
],
"userName": "root",
"userPassword": "123456",
"dbName": "mydb"
"collectionName": "mydb",
"column": [
"name": "id",
"type": "string"
,
"name": "name",
"type": "string"
],
"upsertInfo":
"isUpsert": "true",
"upsertKey": "id"
]
在mysql的user_info表中提前插入了一条数据
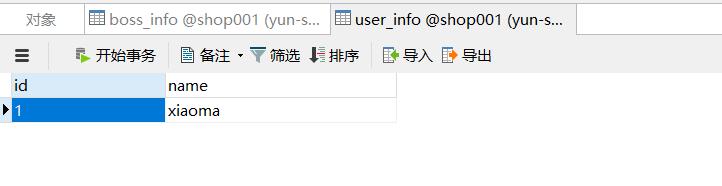
同样,需要在mongodb中创建相关的 DB,Collection以及授权的账户和密码,这里我们预先在mydb这个collection中插入了一条数据
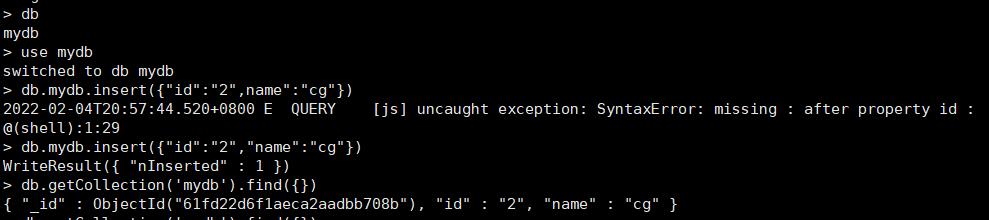
执行下面的命令开始进行数据同步
./bin/datax.py job/mysql2mongo.json
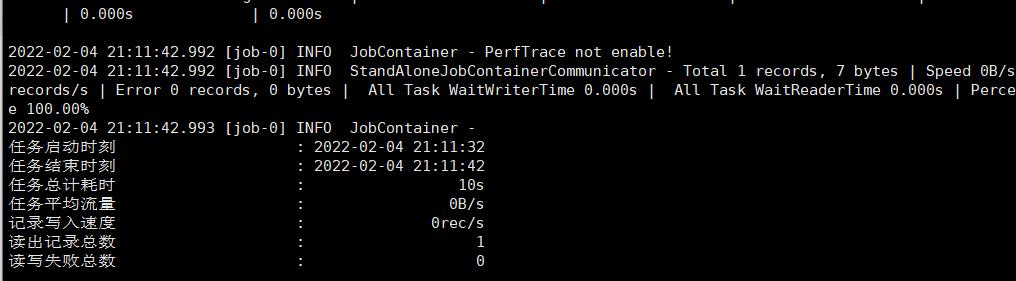
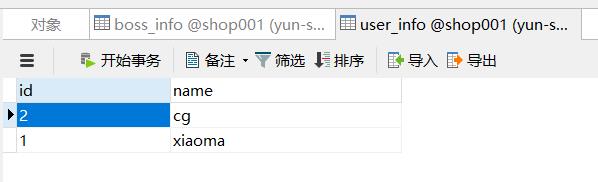
任务执行完毕后,我们再次去查看 mydb这个 collection下的数据,可以看到,mysql中的那条数据就被同步过来了

使用案例四:mongodb同步数据到mysql
我们将上面的顺序调换下,贴出下面的核心配置文件
"job":
"content": [
"reader":
"name": "mongodbreader",
"parameter":
"address": ["IP:27017"],
"dbName": "mydb",
"collectionName": "mydb",
"userName": "root",
"userPassword": "123456",
"column": [
"name":"id",
"type":"string"
,
"name":"name",
"type":"string"
],
"dbName": "mydb"
,
"writer":
"name": "mysqlwriter",
"parameter":
"column": ["id","name"],
"connection": [
"jdbcUrl": "jdbc:mysql://IP:3306/shop001",
"table": ["user_info"]
],
"password": "root",
"username": "root",
"writeMode": "insert"
],
"setting":
"speed":
"channel": "1"
将上面的配置文件上传到job目录下,同时在执行同步任务之前,先清空mysql的user_info表数据
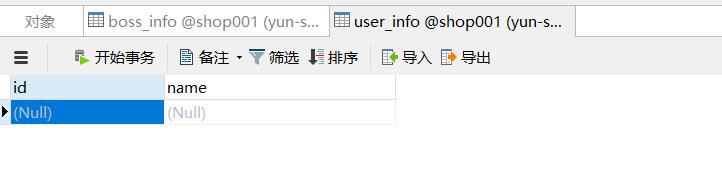
然后执行下面的同步任务命令
./bin/datax.py job/mongo2mysql.json
看到下面执行成功的日志后,去mysql的表看看是否同步成功
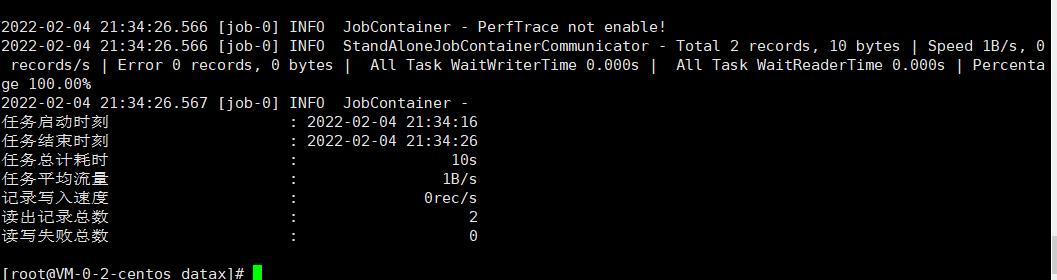
使用过程中的坑
小编在初次使用的时候,比如使用案例一中的执行任务命令执行编写的配置文件之后,报出下面的错误
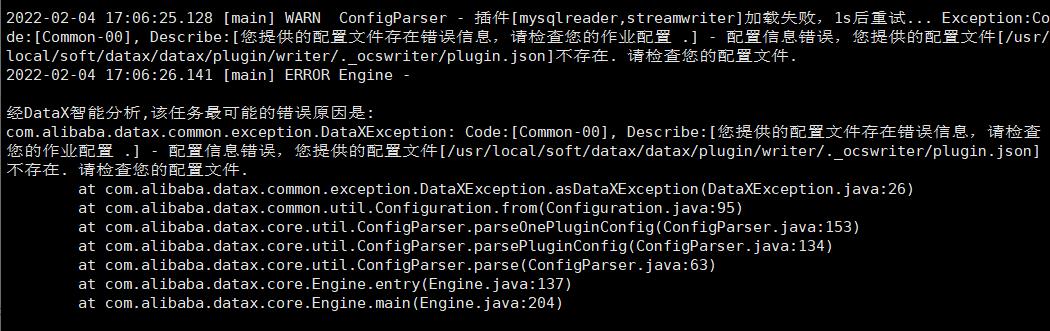
出现这个问题的原因在于,plugin中存在各种读取和写入使用的组件,即reader和writer
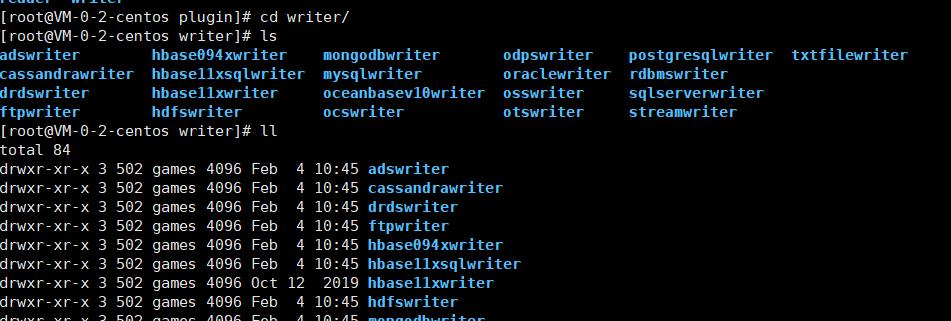
这些reader和writer会解析你的配置文件,只有正确被解析,才能完成数据的同步,这里的解决办法是,分别进入到reader 和 writer两个目录下,删掉那些 “._” 开头的文件
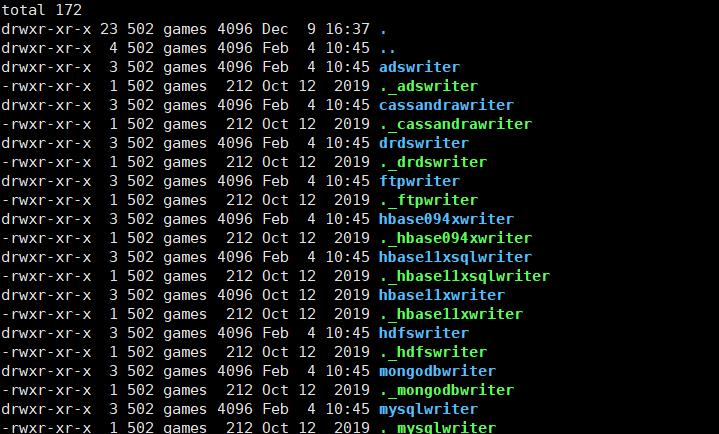
而这些文件是隐藏的,直接使用 ll 或者 ls 是看不到的,需要执行 ls -al 命令查看隐藏文件
找到这些隐藏文件之后,进行删除,删除完毕后再次执行任务就可以成功了,关于这一点,网上大多数关于使用datax的教程中并没有提到,希望看到的同学们可以避开这个坑
以上是关于datax实现mysql数据同步的主要内容,如果未能解决你的问题,请参考以下文章