Swin Transformer代码阅读注释
Posted HollowKnightZ
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Swin Transformer代码阅读注释相关的知识,希望对你有一定的参考价值。
Swin Transformer代码阅读注释
前言
上一篇博文以论文中的内容介绍了Swin Transformer的网络结构和一些细节。本篇博文将从官方代码中的swin_transformer.py去详细介绍Swin Transformer结构,并补充代码中才有而论文中没有的细节。
|| 如果对 Swin Transformer 不了解建议先看论文介绍再看源码 ||
Swin Transformer介绍博客:论文阅读笔记:Swin Transformer
Swin Transformer
代码中实现的网络结构与论文中的结构如如下:
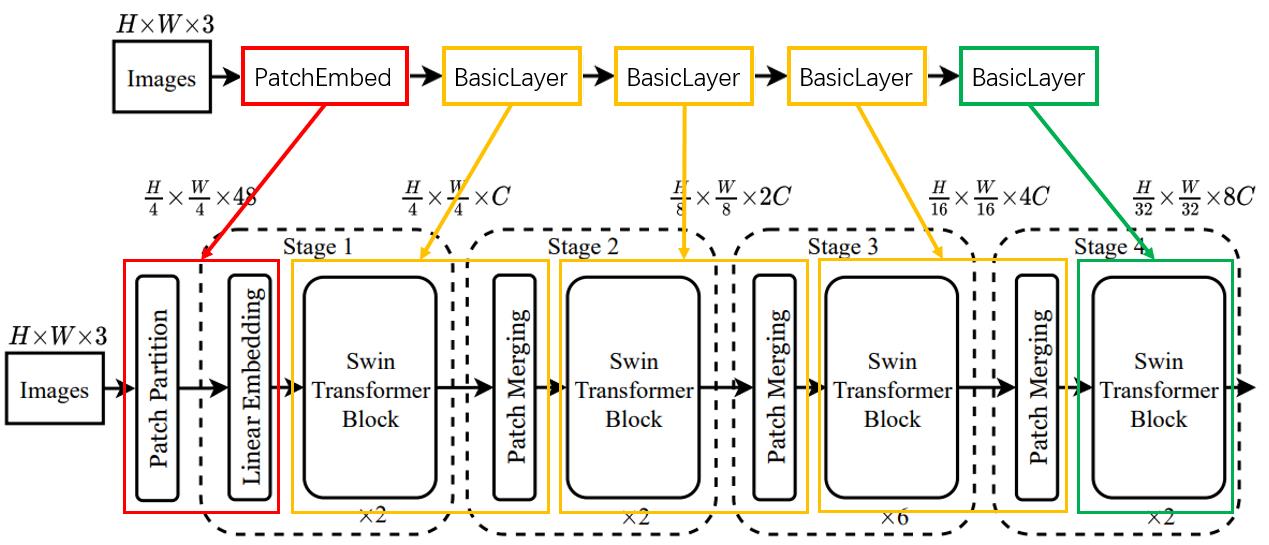
如上图所示,代码中使用PatchEmbed来实现Patch Partition + Linear Embedding,使用BasicLayer来实现Swin Transformer Block + PatchMerging,对于最后一个BasicLayer不使用PatchMerging来降采样。
Swin-T 的配置如下:
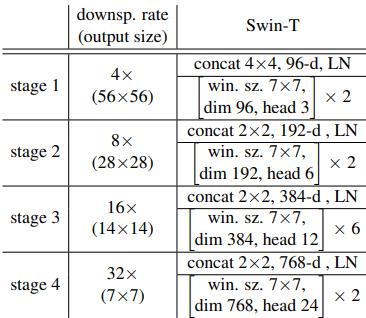
网络结构介绍可看Swin Transformer介绍博客:论文阅读笔记:Swin Transformer
整体结构代码和注释如下(代码大部分和和 Vision Transformer 是一样):
class SwinTransformer(nn.Module):
def __init__(self, img_size=224, patch_size=4, in_chans=3, num_classes=1000,
embed_dim=96, depths=[2, 2, 6, 2], num_heads=[3, 6, 12, 24],
window_size=7, mlp_ratio=4., qkv_bias=True, qk_scale=None,
drop_rate=0., attn_drop_rate=0., drop_path_rate=0.1,
norm_layer=nn.LayerNorm, ape=False, patch_norm=True,
use_checkpoint=False, **kwargs):
'''
img_size(int | tuple(int)): 输入图像尺寸. 默认: 224
patch_size (int | tuple(int)): Patch尺寸. 默认: Swin-T参数配置表中 stage1中的96
in_chans (int): 输入图像通道. 默认: 3
num_classes (int): 分类数. 默认: 1000
embed_dim (int): Patch embedding的输出通道. 默认: 96 (Swin-T参数配置表中 stage 1 中的 96-d)
depths (tuple(int)):Swin Transformer Block 的个数. 默认:[2, 2, 6, 2] (Swin-T参数配置表中的[×2, ×2, ×6, ×2])
num_heads (tuple(int)): 不同层 MSA 计算中的 head 数. 默认:[3, 6, 12, 24] (Swin-T参数配置表中的[head 3,head 6,head 12,head 24])
window_size (int): W-MSA 和 SW-MSA 的 Window 尺寸. 默认: 7 (Swin-T参数配置表中的 “win.sz. 7×7”)
mlp_ratio (float): 通过MLP的输出通道倍数. 默认: 4 (Swin-T参数配置表中的“dim 96”,“dim 192”,“dim 384”,“dim 768”可以看出)
qkv_bias (bool): 使用 Linear 将输入映射到 qkv 时,Linear是否使用偏置. 默认: True
qk_scale (float):qk缩放比例,如果是 None 则使用根号 dim_k 分之一. 默认: None
drop_rate (float): dropout概率. 默认: 0
attn_drop_rate (float): attention 中的 dropout 概率. 默认: 0
drop_path_rate (float): attention 中的 droppath 概率. 默认: 0.1
norm_layer (nn.Module): 归一化方式. 默认: nn.LayerNorm.
ape (bool): 是否在 patch embedding 后使用绝对位置编码. 默认: False
patch_norm (bool): 是否在 patch embedding 后使用归一化. 默认: True
use_checkpoint (bool): 是否 checkpointing 节省内存. 默认: False
'''
super().__init__()
self.num_classes = num_classes
self.num_layers = len(depths)
self.embed_dim = embed_dim
self.ape = ape
self.patch_norm = patch_norm
'''
经过4个stage后的通道数(从96->768 即:96*2^(4-1)=768)
'''
self.num_features = int(embed_dim * 2 ** (self.num_layers - 1))
self.mlp_ratio = mlp_ratio
'''
将图片划分成没有重叠的多个patch
PatchEmbed代码在下文中介绍
patches_resolution = [img_size[0]//patch_size[0], img_size[1]//patch_size[1]] = [56,56]
num_patches = patches_resolution[0] * patches_resolution[1] = 3136
'''
self.patch_embed = PatchEmbed(
img_size=img_size, patch_size=patch_size, in_chans=in_chans, embed_dim=embed_dim,
norm_layer=norm_layer if self.patch_norm else None)
num_patches = self.patch_embed.num_patches
patches_resolution = self.patch_embed.patches_resolution
self.patches_resolution = patches_resolution
'''
如果使用绝对位置编码则构建可学习的绝对位置编码参数:
self.absolute_pos_embed : [1,3136,96]
默认不使用
'''
if self.ape:
self.absolute_pos_embed = nn.Parameter(torch.zeros(1, num_patches, embed_dim))
trunc_normal_(self.absolute_pos_embed, std=.02)
'''
pos_drop 以 drop_rate 概率进行 Dropout
'''
self.pos_drop = nn.Dropout(p=drop_rate)
'''
构建首项为0,长度为depths(2+2+6+2=12)的等差数列,且最后一项小于drop_path_rate
也就是说 传入 BasicLayer 的 droppath 概率是递增的。
代码这里是让 drop_path_ratio 默认等于0.1
最后利用参数构建 depth(12) 层 BasicLayer 层
BasicLayer 的代码在下文中介绍
'''
dpr = [x.item() for x in torch.linspace(0, drop_path_rate, sum(depths))] # stochastic depth decay rule
# build layers
self.layers = nn.ModuleList()
for i_layer in range(self.num_layers):
layer = BasicLayer(dim=int(embed_dim * 2 ** i_layer), #每个Basiclayer模块后通道数都翻倍
'''
每个Basiclayer都进行了降采样
所以input_resolution每一次都要除以2
'''
input_resolution=(patches_resolution[0] // (2 ** i_layer),
patches_resolution[1] // (2 ** i_layer)),
depth=depths[i_layer],
num_heads=num_heads[i_layer],
window_size=window_size,
mlp_ratio=self.mlp_ratio,
qkv_bias=qkv_bias, qk_scale=qk_scale,
drop=drop_rate, attn_drop=attn_drop_rate,
drop_path=dpr[sum(depths[:i_layer]):sum(depths[:i_layer + 1])],
norm_layer=norm_layer,
'''
如果i_layer 是最后一层则不使用PatchMerging 来降采样
'''
downsample=PatchMerging if (i_layer < self.num_layers - 1) else None,
use_checkpoint=use_checkpoint)
self.layers.append(layer)
'''
进行归一化和平均池化
最后用一个Linear做预测head
'''
self.norm = norm_layer(self.num_features)
self.avgpool = nn.AdaptiveAvgPool1d(1)
self.head = nn.Linear(self.num_features, num_classes) if num_classes > 0 else nn.Identity()
self.apply(self._init_weights)
'''
初始化权重
'''
def _init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
def forward_features(self, x):
'''
如图所示先进行patch embedding
如果使用绝对位置偏置就加上绝对位置编码
'''
x = self.patch_embed(x)
if self.ape:
x = x + self.absolute_pos_embed
x = self.pos_drop(x)
'''
循环执行Blocks
'''
for layer in self.layers:
x = layer(x)
'''
归一化并平均池化
'''
x = self.norm(x) # B L C
x = self.avgpool(x.transpose(1, 2)) # B C 1
x = torch.flatten(x, 1)
return x
def forward(self, x):
x = self.forward_features(x)
'''
对swin transformer的特征提取进行预测
'''
x = self.head(x)
return x
1 PatchEmbed
Swin Transformer中的PatchEmbed模块和 VIT 中的 Linear Projection of Flattened Patches: PatchEmbed模块差不多,可查看博文Vision Transformer(Pytorch版)代码阅读注释 查看,其主要思想是通过感受野大小等于步距大小的卷积来实现,与 VIT 不同的是其使用了nn.LayerNorm。
PatchEmbed代码和注释如下:
class PatchEmbed(nn.Module):
""" Image to Patch Embedding
Args:
img_size (int): 图像尺寸. 默认: 224.
patch_size (int): token尺寸. 默认: 4.
in_chans (int): 图像通道. 默认: 3.
embed_dim (int): patch embed通道. 默认: 96.
norm_layer (nn.Module, optional): 归一化. Default: None
"""
def __init__(self, img_size=224, patch_size=4, in_chans=3, embed_dim=96, norm_layer=None):
super().__init__()
'''
self.image_size = (224,224)
self.patch_size = (4,4)
self.patches_resolution = [56,56]
self.num_patches = 56*56=3136
'''
img_size = to_2tuple(img_size)
patch_size = to_2tuple(patch_size)
patches_resolution = [img_size[0] // patch_size[0], img_size[1] // patch_size[1]]
self.img_size = img_size
self.patch_size = patch_size
self.patches_resolution = patches_resolution
self.num_patches = patches_resolution[0] * patches_resolution[1]
'''
self.in_chans = 3
self.embed_dim = 96
'''
self.in_chans = in_chans
self.embed_dim = embed_dim
'''
self.proj = nn.Conv2d(3,96,(4,4),4)
self.norm = nn.LayerNorm(96)
'''
self.proj = nn.Conv2d(in_chans, embed_dim, kernel_size=patch_size, stride=patch_size)
if norm_layer is not None:
self.norm = norm_layer(embed_dim)
else:
self.norm = None
def forward(self, x):
B, C, H, W = x.shape
# FIXME look at relaxing size constraints
assert H == self.img_size[0] and W == self.img_size[1], \\
f"Input image size (H*W) doesn't match model (self.img_size[0]*self.img_size[1])."
'''
self.proj(x):[B,3,224,224]->[B,96,56,56]
flatten(2):[B,96,56,56]->[B,96,56*56]=[B,96,3136]
transpose(1, 2):[B,96,3136]->[B,3136,96]
self.norm(x):[B,3136,96]->[B,3136,96]
'''
x = self.proj(x).flatten(2).transpose(1, 2) # B Ph*Pw C
if self.norm is not None:
x = self.norm(x)
return x
BasicLayer
代码中使用BasicLayer来实现论文中的Swin Transformer Block + PatchMerging,对于最后一个BasicLayer不使用PatchMerging来降采样。
BasicLayer的代码和注释如下:
class BasicLayer(nn.Module):
""" A basic Swin Transformer layer for one stage.
Args:
dim (int): 输入特征图的通道数.
input_resolution (tuple[int]): 输入特征图的分辨率大小.
depth (int): SwinTransformerBlock的个数.
num_heads (int): Muti-Head Self-Attention 中的head个数.
window_size (int): window 大小.
mlp_ratio (float): patch embedding通过MLP的通道倍数.
qkv_bias (bool): 使用 Linear 将输入映射到 qkv 时,Linear是否使用偏置. 默认: True
qk_scale (float):qk缩放比例,如果是 None 则使用根号 dim_k 分之一. 默认: None
drop (float, optional): dropout概率. 默认: 0
attn_drop (float, optional): attention 中的 dropout 概率. 默认: 0
drop_path (float | tuple[float], optional): attention 中的 droppath 概率. 默认: 0.1
norm_layer (nn.Module): 归一化方式. 默认: nn.LayerNorm.
downsample (nn.Module | None, optional): 降采样层. 默认: None 代码使用PatchMerging
use_checkpoint (bool): 是否 checkpointing 节省内存. 默认: False
"""
def __init__(self, dim, input_resolution, depth, num_heads, window_size,
mlp_ratio=4., qkv_bias=True, qk_scale=None, drop=0., attn_drop=0.,
drop_path=0., norm_layer=nn.LayerNorm, downsample=None, use_checkpoint=False):
super().__init__()
self.dim = dim
self.input_resolution = input_resolution
self.depth = depth
self.use_checkpoint = use_checkpoint
'''
构建SwinTransformerBlock
SwinTransformerBlock代码在下文介绍
'''
self.blocks = nn.ModuleList([
SwinTransformerBlock(dim=dim, input_resolution=input_resolution,
num_heads=num_heads, window_size=window_size,
'''
如果i是偶数,则表示是W-MSA,shift_size =0
如果i是奇数,则表示是SW-MSA,shift_size = window_size // 2
'''
shift_size=0 if (i % 2 == 0) else window_size // 2,
mlp_ratio=mlp_ratio,
qkv_bias=qkv_bias, qk_scale=qk_scale,
drop=drop, attn_drop=attn_drop,
drop_path=drop_path[i] if isinstance(drop_path, list) else drop_path,
norm_layer=norm_layer)
for i in range(depth)])
'''
使用PatchMerging进行降采样
PatchMerging代码在下文介绍
'''
if downsample is not None:
self.downsample = downsample(input_resolution, dim=dim, norm_layer=norm_layer)
else:
self.downsample = None
def forward(self, x):
for blk in self.blocks:
if self.use_checkpoint:
x = checkpoint.checkpoint(blk, x)
else:
x = blk(x)
if self.downsample is not None:
x = self.downsample(x)
return x
SwinTransformerBlock
SwinTransformerBlock的结构如下:

Mlp
此处和 VIT 中MLP一模一样,可查看Vision Transformer(Pytorch版)代码阅读注释 。代码也很简单,就不再做任何赘述了。
Mlp的代码如下:
class Mlp(nn.Module):
def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.fc1 = nn.Linear(in_features, hidden_features)
self.act = act_layer()
self.fc2 = nn.Linear(hidden_features, out_features)
self.drop = nn.Dropout(drop)
def forward(self, x):
x = self.fc1(x)
x = self.act(x)
x = self.drop(x)
x = self.fc2(x)
x = self.drop(x)
return x
window_partition
W-MSA和SW-MSA首先需要将特征图拆分成多个windows。
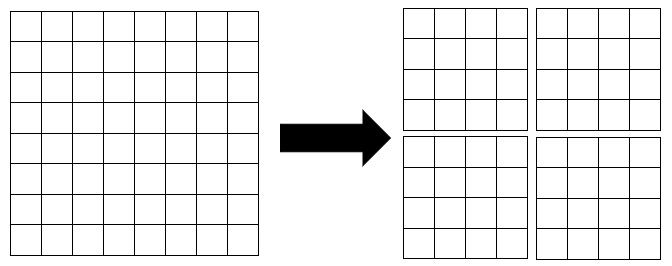
window_partition的代码和注释如下:
def window_partition(x, window_size):
"""
Args:
x: (B, H, W, C)
window_size (int): window size
Returns:
windows: (num_windows*B, window_size, window_size, C)
"""
B, H, W, C = x.shape
'''
[B, H, W, C] -> [BHW//(window_size*window_size), window_size, window_size, C]
'''
x = x.view(B, H // window_size, window_size, W // window_size, window_size, C)
windows = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(-1, window_size, window_size, C)
return windows
window_reverse
在对每一个windows进行WSA计算以后需要将其还原成正常的特征图传入下一模块中。其实就是window_partition的逆过程。
window_reverse的代码和注释如下:
def window_reverse(windows, window_size, H, W):
"""
Args:
windows: (num_windows*B, window_size, window_size, C)
window_size (int): Window size
H (int): Height of image
W (int): Width of image
Returns:
x: (B, H, W, C)
"""
B = int(windows.shape[0] / (H * W / window_size / window_size))
x = windows.view(B, H // window_size, W // window_size, window_size, window_size, -1)
x = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(B, H, W, -1)
return x
WindowAttention
WindowAttention就是在 Vision Transformer 模块的Attention基础上加入了相对位置偏移relative_position_bias_table(即论文中提出的 Relative Position Bias)来提升精度:
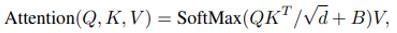
生成相对位置偏置的过程(以一个head为例,假设window_h = 2,window_w = 2,相关代码已在图中标出):
1.随机生成相对位置偏置表relative_position_bias_table:

self.relative_position_bias_table = nn.Parameter(
torch.zeros((2 * window_size[0] - 1) * (2 * window_size[1] - 1), num_heads)) # 2*Wh-1 * 2*Ww-1, nH
2.首先windows内部每个像素都有自己的位置编码,其绝对位置编码的坐标abs_coords如果以左上角为原点,则如下图:

coords_h = torch.arange(self.window_size[0])
coords_w = torch.arange(self.window_size[1])
coords = torch.stack(torch.meshgrid([coords_h, coords_w])) # 2, Wh, Ww
coords_flatten = torch.flatten(coords, 1) # 2, Wh*Ww
3.为了获得每个绝对坐标相对于其他坐标的相对位置,则需要用每个绝对坐标减去其他绝对坐标,即:
- 用
(
0
,
0
)
(0,0)
(0,0) 分别减去
(
0
,
1
)
(0,1)
(0,1),
(
1
,
0
以上是关于Swin Transformer代码阅读注释的主要内容,如果未能解决你的问题,请参考以下文章