Java序列化算法
Posted 鸭子船长
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Java序列化算法相关的知识,希望对你有一定的参考价值。
Serialization(序列化)是一种将对象以一连串的字节描述的过程;反序列化deserialization是一种将这些字节重建成一个对象的过程。java序列化API提供一种处理对象序列化的标准机制。
序列化的必要性
java中,一切都是对象,在分布式环境中经常需要将Object从这一端网络或设备传递到另一端。这就需要有一种可以在两端传输数据的协议。java序列化机制就是为了解决这个问题而产生。
如何序列化一个对象
一个对象能够序列化的前提是实现Serializable接口,Serializable接口没有方法,更像是个标记,有了这个标记的class就能被序列化机制处理。
1 class TestSerial implements Serializable{ 2 public byte version = 100; 3 public byte count = 0; 4 }
然后我们写个程序将对象序列化并输出。ObjectOutputStream能把Object输出成Byte流。我们将Byte流暂时存储到temp.out文件里。
1 public static void main(String args[]) throws IOException { 2 FileOutputStream fos = new FileOutputStream("temp.out"); 3 ObjectOutputStream oos = new ObjectOutputStream(fos); 4 TestSerial ts = new TestSerial(); 5 oos.writeObject(ts); 6 oos.flush(); 7 oos.close(); 8 }
如果要从持久的文件中读取Bytes重建对象,我们可以使用ObjectInputStream。
1 public static void main(String args[]) throws IOException{ 2 FileInputStream fis = new FileInputStream("temp.out"); 3 ObjectInputStream oin = new ObjectInputStream(fis); 4 TestSerial ts = (TestSerial) oin.readObject(); 5 System.out.println("version="+ts.version); 6 }
执行结果是100;
对象序列化格式
将一个对象序列化后是什么样子呢?打开刚才我们将对象序列化输出的temp.out文件
以16进制方式显示。内容应该如下:
AC ED 00 05 73 72 00 0A 53 65 72 69 61 6C 54 65 73 74 A0 0C 34 00 FE B1 DD F9 02 00 02 42 00 05 63 6F 75 6E 74 42 00 07 76 65 72 73 69 6F 6E 78 70 00 64
这些字节就是用来描述序列话以后的TestSerial对象的,我们注意到TestSerial类中只有两个域:
public byte version = 100;
public byte count = 0;
且都是byte型,理论上存储这两个域只需要2个byte,但是实际上temp.out占据空间为51
bytes,也就是说除了数据以外,还包括了对序列化对象的其他描述
java的序列化算法
序列化算法一般会按照步骤做如下事情:
- 将对象实例相关的类元数据输出。
- 递归地输出类的超类描述直到不再有超类。
- 类元数据完了以后,开始从最顶层的超类开始输出对象实例的实际数据值。
- 从上至下递归输出实例的数据
用另一个更完整覆盖所有可能出现的情况的例子来说明:
1 class parent implements Serializable{ 2 int parentVersion = 10; 3 }
class contain implements Serializable{ int containVersion = 11; }
1 public class SerialTest extends parent implements Serializable{ 2 int version = 66; 3 contain con = new contain(); 4 public int getVersion(){ 5 return version; 6 } 7 public static void main(String args[]) throws IOException{ 8 FileOutputStream fos = new FileOutputStream("temp.out"); 9 ObjectOutputStream oos = new ObjectOutputStream(fos); 10 SerialTest st = new SerialTest(); 11 oos.writeObject(st); 12 oos.flush(); 13 oos.close(); 14 } 15 }
-
AC ED: STREAM_MAGIC. 声明使用了序列化协议.
-
00 05: STREAM_VERSION. 序列化协议版本.
-
0x73: TC_OBJECT. 声明这是一个新的对象.
-
0x72: TC_CLASSDESC. 声明这里开始一个新Class。
-
00 0A: Class名字的长度.
-
53 65 72 69 61 6c 54 65 73 74: SerialTest,Class类名.
-
05 52 81 5A AC 66 02 F6: SerialVersionUID, 序列化ID,如果没有指定,
则会由算法随机生成一个8byte的ID. -
0x02: 标记号. 该值声明该对象支持序列化。
-
00 02: 该类所包含的域个数。
-
0x49: 域类型. 49 代表"I", 也就是Int.
-
00 07: 域名字的长度.
-
76 65 72 73 69 6F 6E: version,域名字描述.
-
0x4C: 域的类型.
-
00 03: 域名字长度.
-
63 6F 6E: 域名字描述,con
-
0x74: TC_STRING. 代表一个new String.用String来引用对象。
-
00 09: 该String长度.
-
4C 63 6F 6E 74 61 69 6E 3B: Lcontain;, JVM的标准对象签名表示法.
-
0x78: TC_ENDBLOCKDATA,对象数据块结束的标志
-
0x72: TC_CLASSDESC. 声明这个是个新类.
-
00 06: 类名长度.
-
70 61 72 65 6E 74: parent,类名描述。
-
0E DB D2 BD 85 EE 63 7A: SerialVersionUID, 序列化ID.
-
0x02: 标记号. 该值声明该对象支持序列化.
-
00 01: 类中域的个数.
-
0x49: 域类型. 49 代表"I", 也就是Int.
-
00 0D: 域名字长度.
-
70 61 72 65 6E 74 56 65 72 73 69 6F 6E: parentVersion,域名字描述。
-
0x78: TC_ENDBLOCKDATA,对象块结束的标志。
-
0x70: TC_NULL, 说明没有其他超类的标志。.
-
00 00 00 0A: 10, parentVersion域的值.
-
00 00 00 42: 66, version域的值.
-
0x73: TC_OBJECT, 声明这是一个新的对象.
-
0x72: TC_CLASSDESC声明这里开始一个新Class.
-
00 07: 类名的长度.
-
63 6F 6E 74 61 69 6E: contain,类名描述.
-
FC BB E6 0E FB CB 60 C7: SerialVersionUID, 序列化ID.
-
0x02: Various flags. 标记号. 该值声明该对象支持序列化
-
00 01: 类内的域个数。
-
0x49: 域类型. 49 代表"I", 也就是Int..
-
00 0E: 域名字长度.
-
63 6F 6E 74 61 69 6E 56 65 72 73 69 6F 6E: containVersion, 域名字描述.
-
0x78: TC_ENDBLOCKDATA对象块结束的标志.
-
0x70:TC_NULL,没有超类了。
-
00 00 00 0B: 11, containVersion的值.
-
SerialTest类实现了Parent超类,内部还持有一个Container对象。序列化后的格式如下:
AC ED 00 05 73 72 00 0A 53 65 72 69 61 6C 54 65
73 74 05 52 81 5A AC 66 02 F6 02 00 02 49 00 07
76 65 72 73 69 6F 6E 4C 00 03 63 6F 6E 74 00 09
4C 63 6F 6E 74 61 69 6E 3B 78 72 00 06 70 61 72
65 6E 74 0E DB D2 BD 85 EE 63 7A 02 00 01 49 00
0D 70 61 72 65 6E 74 56 65 72 73 69 6F 6E 78 70
00 00 00 0A 00 00 00 42 73 72 00 07 63 6F 6E 74
61 69 6E FC BB E6 0E FB CB 60 C7 02 00 01 49 00
0E 63 6F 6E 74 61 69 6E 56 65 72 73 69 6F 6E 78
70 00 00 00 0B
-
我们来仔细看看这些字节都代表了啥。开头部分,见颜色:
序列化算法的第一步就是输出对象相关类的描述。例子所示对象为SerialTest类实例,
因此接下来输出SerialTest类的描述。见颜色:接下来,算法输出其中的一个域,int version=66;见颜色:
然后,算法输出下一个域,contain con = new contain();这个有点特殊,是个对象。
描述对象类型引用时需要使用JVM的标准对象签名表示法,见颜色:.接下来算法就会输出超类也就是Parent类描述了,见颜色:
下一步,输出parent类的域描述,int parentVersion=100;同见颜色:
到此为止,算法已经对所有的类的描述都做了输出。下一步就是把实例对象的实际值输出了。这时候是从parent Class的域开始的,见颜色:
还有SerialTest类的域:
再往后的bytes比较有意思,算法需要描述contain类的信息,要记住,
现在还没有对contain类进行过描述,见颜色:.输出contain的唯一的域描述,int containVersion=11;
这时,序列化算法会检查contain是否有超类,如果有的话会接着输出。
最后,将contain类实际域值输出。
OK,我们讨论了java序列化的机制和原理,希望能对同学们有所帮助。
SerialTest st = new SerialTest();
oos.writeObject((parent)st);
1 public class A implements Seriallizable{ 2 private static final long serialVersionUID = 1L; 3 private String name; 4 public String getName(){ 5 return name; 6 } 7 8 public void setName(String name){ 9 this.name = name; 10 } 11 } 12 13 public class A implements Serializable{ 14 private static final long serialVersionUID = 2L; 15 private String name; 16 public String getName(){ 17 return namel 18 } 19 20 public void setName(String name){ 21 this.name = name; 22 } 23 }
序列化ID自Eclipse下提供了两种生成策略,一个是固定的1L,一个是随机生成一个不重复的long类型数据(实际上使用JDK工具生成),这里有一个建议,如果没有特殊需求,就使用默认的1L就可以,这样可以确保代码一致时反序列化成功。那么随机生成的序列化ID有什么作用呢?有些时候,通过改变序列化ID可以用来限制某些用户的使用。
特性使用案例
读者应该听过Facade模式,它是为应用程序提供统一的访问接口,案例程序中的Client客户端使用了该模式,案例程序结构图如图1所示。
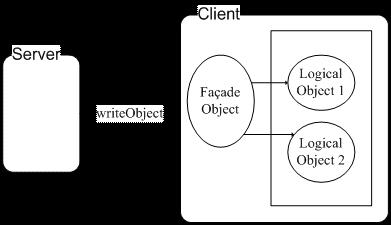
Client端通过Facade Object才可以与业务逻辑对象进行交互。而客户端的Facade Object不能直接由Client生成,而是需要Server端生成,然后序列化后通过网络将二进制对象数据传给Client,Client负责反序列化得到Facade对象。该模式可以使得Client端程序的使用需要服务器端的许可,同时Client端和服务器端的Facade Object类需要保持一致。当服务器端想要进行版本更新时,只要将服务器端的Facade Object类的序列化ID再次生成,当Client端反序列化Facade Object就会失败,也就是强制Client端从服务器端获取最新程序。
静态变量序列化
情境:查看如下代码
1 public class Test implements Serializable{ 2 private static final long serialVersionUID = 1L; 3 public static int staticVar = 5; 4 public static void main(String[] args){ 5 try{ 6 //初始时staticVar为5 7 ObjectOutputStream out = new ObjectOutputStream(new FileOutputStream("result.obj")); 8 out.writeObject(new Test()); 9 out.close(); 10 11 //序列化后修改为10 12 Test.staticVar = 10; 13 14 ObjectInputStream oin = new ObjectInputStream(new FileInputStream("resule.obj")); 15 Test t = (Test) oin.readObject(); 16 oin.close(); 17 18 //再读取,通过t.staticVar打印新值 19 System.out.printlb(t.staticVar); 20 21 }catch (FileNotFoundException e) { 22 e.printStackTrace(); 23 } catch (IOException e) { 24 e.printStackTrace(); 25 } catch (ClassNotFoundException e) { 26 e.printStackTrace(); 27 } 28 } 29 }
main方法将对象序列化后,修改静态变量的数值,再将序列化对象读取处理,然后通过读取出来的对象获得静态变量的数值并打印出来。最后输出是10,之所以打印10的原因在于序列化时,并不保存静态变量。这其实比较容易理解,序列化保存的是对象的状态,静态变量属于类的状态,因此序列化并不保存静态变量。
父类的序列化与Transient关键字
情境:一个子类实现了Serializable接口,它的父类都没有实现Serializable接口,序列化该子类对象,然后反序列化后输出父类定义的某变量的数值,该变量数值与序列化时的数值不同。
解决:要想将父类对象也序列化,就需要让父类也实现Serializable接口。如果父类不实现的话,就需要有默认的无参构造函数。在父类没有实现Serializable接口时,虚拟机是不会序列化父对象的,而一个java对象的构造必须先有父对象,才有子对象,反序列化也不例外。所以反序列化时,为了构造父对象,只能调用父类的无参构造函数作为默认的父对象。因此当我们取父对象的变量值时,它的值是调用父类无参构造函数后的值。如果你考虑到这种序列化的情况,在父类无参构造函数中对变量进行初始化,否则的话,父类变量值都是默认声明的值,如int型的默认是0,string型的默认是null。
Transient关键字的作用是控制变量的序列话,在变量声明前加上该关键字,可以阻止该变量被序列化到文件中,在被反序列化后,transient 变量的值被设为初始值,如 int 型的是 0,对象型的是 null。
使用案例
我们熟悉使用Transient关键字可以使得字段不被序列化,那么还有别的方法吗?根据父类对象序列化的规则,我们可以将不需要被序列化的字段抽取出来放到父类中,子类实现Serializable接口,父类不实现,根据父类序列化规则,父类的字段数据将不被序列化,形成类图如图所示。
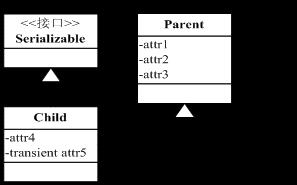
上图中可以看出,attr1、attr2、attr3、attr5都不会被序列化,放在父类中的好处在于当有另外一个Child类时,attr1、attr2、attr3依然不会被序列化,不用重复写transient,代码简洁。
对敏感字段加密
情境:服务端给客户端发送序列化对象数据,对象中有一些数据是敏感的,比如密码字符串等,希望对该密码字段在序列化时,进行加密,而客户端如果拥有解密的秘钥,只有在客户端进行反序列化时,才可以对密码进行读取,这样可以一定程度保证序列化对象的数据安全。
解决:在序列化过程中,虚拟机会试图调用对象类里的writeObject和readObject方法,进行用户自定义的序列化和反序列化,如果没有这样的方法,则默认调用是ObjectOutputStream的defaultWriteObject方法以及ObjectInputStream的defaultReadObject方法。用户自定义的writeObject和readObject方法可以允许用户控制序列化的过程,比如可以在序列化的过程中动态改变序列化的数值。基于这个原理,可以在实际应用中得到使用,用于敏感字段的加密工作。
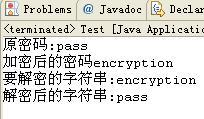
1 private static final long serialVersionUID = 1L; 2 private String password = "pass"; 3 public String getPassword(){ 4 return password; 5 } 6 public void setPassword(String password){ 7 this.password = password; 8 } 9 10 private void writeObject(ObjectOutputStream out){ 11 try{ 12 PubField putFields = out.putFields(); 13 System.out.printlb("原密码:"+password); 14 password = "encryption";//模拟加密 15 putFields.put("password", password); 16 System.out.println("加密后的密码" + password); 17 out.writeFields(); 18 }catch(IOException e){ 19 e.printStackTrace(); 20 } 21 } 22 23 private void readObject(ObjectInputStream in){ 24 try{ 25 GetField readFields = in.readFields(); 26 Object object = readFields.get("password",""); 27 System.out.println("要解密的字符串:“+object.toString()); 28 password = "pass";//模拟解密,需要获得本地的秘钥 29 }catch(IOException e){ 30 e.printStackTrace(); 31 }catch(ClassNotFoundException e){ 32 e.printStackTrace(); 33 } 34 } 35 36 public static void main(String[] args){ 37 try{ 38 ObjectOutputStream out = new ObjectOutputStream(new FileOutputStream("resule.obj")); 39 out.writeObject(new Test()); 40 out.close(); 41 42 ObjectInputStream oin = new ObjectInputStream(new FileInputStream("resule.obj")); 43 Test t = (Test)oin.readObject(); 44 System.out.println("解密后的字符串:”+t.getPassword()); 45 oin.close(); 46 }catch(FileNotFonudException e){ 47 e.printStackTrace(); 48 }catch(IOException e){ 49 e.printStackTrace(); 50 }catch(ClassNotFoundException e){ 51 e.printStackTrace(); 52 } 53 }
在writeObject方法中,对密码进行了加密,在readObject中则对password进行解密,只有用于秘钥的客户端,才可以正确的解析出密码,确保了数据的安全。执行后控制台输出如下:
使用案例:RMI技术是完全基于Java序列化技术的,服务器端接口调用所需要的参数对象来自于客户端,它们通过网络相互传输。这就涉及RMI的安全传输的问题。一些敏感的字段,如用户名密码(用户登陆时需要对密码进行传输),我们希望对其进行加密,这时,就可以采用本节介绍的方法在客户端对密码进行加密,服务器端进行解密,确保数据传输的安全性。
序列化存储规则
ObjectOutputStream out = new ObjectOutputStream(new FileOutputStream("result.obj")); Test test = new Test(); //试图将对象两次写入文件 out.writeObject(text); out.flush(); System.ut.println(new File("result.obj").length()); out.writeObject(text); out.close(); System.out.println(new File("result.obj").length()); ObjectInputStream oin = new ObjectInputStream(new FileInputStream("result.obj")); //从文件依次读出两个文件 Test t1 = (Test) oin.readObject(); Test t2 = (Test) oin.readObject(); oin.close(); //判断两个引用是否指向同一个对象 System.out.println(t1==t2);
对同一对象两次写入文件,打印出写入一次对象后的存储大小和写入两次后的存储大小,然后从文件中反序列化出两个对象,比较这两个对象是否为同一对象。一般的思维是,两次写入对象,文件大小会变成两倍的大小,反序列化时,由于从文件读取,生成了两个对象,判断相等时应该是输入false才对,但是最后结果输出如图所示
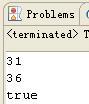
可以看到,第二次写入对象时文件只增加了5字节,并且两个对象是相等的,这时为什么呢?
解答:Java序列化机制为了节省磁盘空间,具有特定的存储规则,当写入文件的为同一对象时,并不会再将对象的内容进行存储,而只是再次存储一份引用,上面增加的5字节的存储空间就是新增引用和一些控制信息的空间。反序列化时,恢复引用关系,使得t1和t2指向唯一的对象,二者相等,输出true。该存储规则极大的节省了存储空间。
案例分析:
1 ObjectOutputStream out = new ObjectOutputStream(new FileOutputStream("result.obj")); 2 Test test = new Test(); 3 test.i = 1; 4 out.writeObject(test); 5 out.flush(); 6 test.i = 2; 7 out.writeObject(test); 8 out.close(); 9 ObjectInputStream oin = new ObjectInputStream(new FileInputStream("result.obj")); 10 Test t1 = (Test)oin.readObject(); 11 Test t2 = (Test)oin.readObject(); 12 System.out.println(t1.i); 13 System.out.println(t2.i);
该程序的目的是希望将test对象两次保存到result.obj文件中,写入一次以后修改对象属性值再次保存第二次,然后从result.obj 中再依次读出两个对象,输出这两个对象的i属性值。案例代码的目的原本是希望一次性传输对象修改前后的状态。
结果两个输出都是1,原因就是第一次写入对象以后,第二次再试图写时,虚拟机根据引用关系知道已经有一个相同对象已经写入文件,因此只保存第二次写的引用,所以读取时,都是第一次保存的对象。读者在使用一个文件多次writeObject时需要特别注意这个问题。
以上是关于Java序列化算法的主要内容,如果未能解决你的问题,请参考以下文章