挖掘框架常用负载均衡算法实现
Posted 赵广陆
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了挖掘框架常用负载均衡算法实现相关的知识,希望对你有一定的参考价值。
目录
1 负载均衡算法
负载均衡,英文名称为Load Balance,其含义就是指将负载(工作任务)进行平衡、分摊到多个操作单元上进行运行,例如FTP服务器、Web服务器、企业核心应用服务器和其它主要任务服务器等,从而协同完成工作任务。既然涉及到多个机器,就涉及到任务如何分发,这就是负载均衡算法问题。
2 轮询(RoundRobin)
2.1 概述
轮询即排好队,一个接一个。前面调度算法中用到的时间片轮转,就是一种典型的轮询。但是前面使用数组和下标
轮询实现。这里尝试手动写一个双向链表形式实现服务器列表的请求轮询算法。
2.2 实现
package com.oldlu.balance;
public class RR
class Server
Server prev;
Server next;
String name;
public Server(String name)
this.name = name;
//当前服务节点
Server current;
//初始化轮询类,多个服务器ip用逗号隔开
public RR(String serverName)
System.out.println("init server list : "+serverName);
String[] names = serverName.split(",");
for (int i = 0; i < names.length; i++)
Server server = new Server(names[i]);
if (current == null)
//如果当前服务器为空,说明是第一台机器,current就指向新创建的server
this.current = server;
//同时,server的前后均指向自己。
current.prev = current;
current.next = current;
else
//否则说明已经有机器了,按新加处理。
addServer(names[i]);
//添加机器
void addServer(String serverName)
System.out.println("add server : "+serverName);
Server server = new Server(serverName);
Server next = this.current.next;
//在当前节点后插入新节点
this.current.next = server;
server.prev = this.current;
//修改下一节点的prev指针
server.next = next;
next.prev=server;
//将当前服务器移除,同时修改前后节点的指针,让其直接关联
//移除的current会被回收器回收掉
void remove()
System.out.println("remove current = "+current.name);
this.current.prev.next = this.current.next;
this.current.next.prev = this.current.prev;
this.current = current.next;
//请求。由当前节点处理即可
//注意:处理完成后,current指针后移
void request()
System.out.println(this.current.name);
this.current = current.next;
public static void main(String[] args) throws InterruptedException
//初始化两台机器
RR rr = new RR("192.168.0.1,192.168.0.2");
//启动一个额外线程,模拟不停的请求
new Thread(new Runnable()
@Override
public void run()
while (true)
try
Thread.sleep(500);
catch (InterruptedException e)
e.printStackTrace();
rr.request();
).start();
//3s后,3号机器加入清单
Thread.currentThread().sleep(3000);
rr.addServer("192.168.0.3");
//3s后,当前服务节点被移除
Thread.currentThread().sleep(3000);
rr.remove();
2.3 结果分析
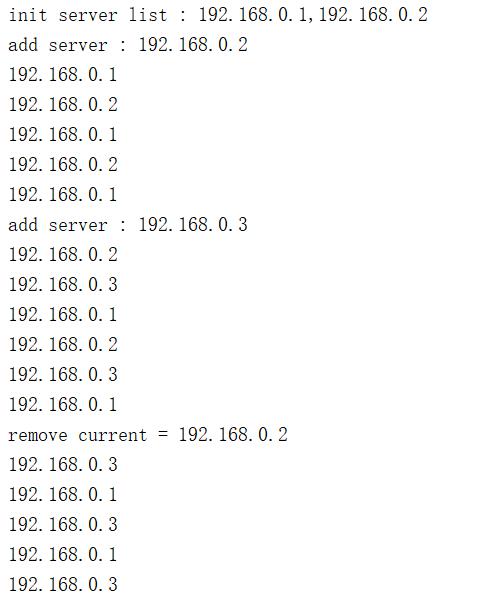
初始化后,只有1,2,两者轮询
3加入后,1,2,3,三者轮询
移除2后,只剩1和3轮询
2.4 优缺点
实现简单,机器列表可以自由加减,且时间复杂度为o(1)
无法针对节点做偏向性定制,节点处理能力的强弱无法区分对待
3 随机(Random)
3.1 概述
从可服务的列表中随机取一个提供响应。随机存取的场景下,适合使用数组更高效的实现下标随机读取。
3.2 实现
定义一个数组,在数组长度内取随机数,作为其下标即可。非常简单
package com.oldlu.balance;
import java.util.ArrayList;
import java.util.Random;
public class Rand
ArrayList<String> ips ;
public Rand(String nodeNames)
System.out.println("init list : "+nodeNames);
String[] nodes = nodeNames.split(",");
//初始化服务器列表,长度取机器数
ips = new ArrayList<>(nodes.length);
for (String node : nodes)
ips.add(node);
//请求
void request()
//下标,随机数,注意因子
int i = new Random().nextInt(ips.size());
System.out.println(ips.get(i));
//添加节点,注意,添加节点会造成内部数组扩容
//可以根据实际情况初始化时预留一定空间
void addnode(String nodeName)
System.out.println("add node : "+nodeName);
ips.add(nodeName);
//移除
void remove(String nodeName)
System.out.println("remove node : "+nodeName);
ips.remove(nodeName);
public static void main(String[] args) throws InterruptedException
Rand rd = new Rand("192.168.0.1,192.168.0.2");
//启动一个额外线程,模拟不停的请求
new Thread(new Runnable()
@Override
public void run()
while (true)
try
Thread.sleep(500);
catch (InterruptedException e)
e.printStackTrace();
rd.request();
).start();
//3s后,3号机器加入清单
Thread.currentThread().sleep(3000);
rd.addnode("192.168.0.3");
//3s后,当前服务节点被移除
Thread.currentThread().sleep(3000);
rd.remove("192.168.0.2");
3.3 结果分析
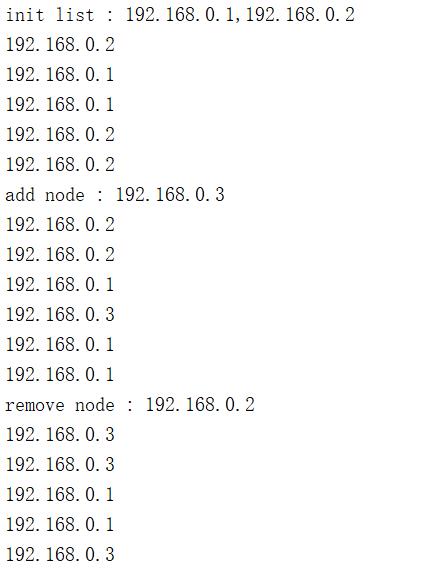
初始化为1,2,两者不按顺序轮询,而是随机出现
3加入服务节点列表
移除2后,只剩1,3,依然是两者随机,无序
4 源地址哈希(Hash)
4.1 概述
对当前访问的ip地址做一个hash值,相同的key被路由到同一台机器去。场景常见于分布式集群环境下,用户登录
时的请求路由和会话保持。
4.2 实现
使用HashMap可以实现请求值到对应节点的服务,其查找时的时间复杂度为o(1)。固定一种算法,将请求映射到
key上即可。举例,将请求的来源ip末尾,按机器数取余作为key:
package com.oldlu.balance;
import java.util.ArrayList;
import java.util.Random;
public class Hash
ArrayList<String> ips ;
public Hash(String nodeNames)
System.out.println("init list : "+nodeNames);
String[] nodes = nodeNames.split(",");
//初始化服务器列表,长度取机器数
ips = new ArrayList<>(nodes.length);
for (String node : nodes)
ips.add(node);
//添加节点,注意,添加节点会造成内部Hash重排,思考为什么呢???
//这是个问题!在一致性hash中会进入详细探讨
void addnode(String nodeName)
System.out.println("add node : "+nodeName);
ips.add(nodeName);
//移除
void remove(String nodeName)
System.out.println("remove node : "+nodeName);
ips.remove(nodeName);
//映射到key的算法,这里取余数做下标
private int hash(String ip)
int last = Integer.valueOf(ip.substring(ip.lastIndexOf(".")+1,ip.length()));
return last % ips.size();
//请求
//注意,这里和来访ip是有关系的,采用一个参数,表示当前的来访ip
void request(String ip)
//下标
int i = hash(ip);
System.out.println(ip+"‐‐>"+ips.get(i));
public static void main(String[] args)
Hash hash = new Hash("192.168.0.1,192.168.0.2");
for (int i = 1; i < 10; i++)
//模拟请求的来源ip
String ip = "192.168.1."+ i;
hash.request(ip);
hash.addnode("192.168.0.3");
for (int i = 1; i < 10; i++)
//模拟请求的来源ip
String ip = "192.168.1."+ i;
hash.request(ip);
4.3 结果分析

初始化后,只有1,2,下标为末尾ip取余数,多次运行,响应的机器不变,实现了会话保持
3加入后,重新hash,机器分布发生变化
2被移除后,原来hash到2的请求被重新定位给3响应
5 加权轮询(WRR)
5.1 概述
WeightRoundRobin,轮询只是机械的旋转,加权轮询弥补了所有机器一视同仁的缺点。在轮询的基础上,初始化时,机器携带一个比重。
5.2 实现
维护一个链表,每个机器根据权重不同,占据的个数不同。轮询时权重大的,个数多,自然取到的次数变大。举个
例子:a,b,c 三台机器,权重分别为4,2,1,排位后会是a,a,a,a,b,b,c,每次请求时,从列表中依次取节点,下次请求再取下一个。到末尾时,再从头开始。但是这样有一个问题:机器分布不够均匀,扎堆出现了…
解决:为解决机器平滑出现的问题,nginx的源码中使用了一种平滑的加权轮询的算法,规则如下:
每个节点两个权重,weight和currentWeight,weight永远不变是配置时的值,current不停变化变化规律如下:选择前所有current+=weight,选current最大的响应,响应后让它的current-=total
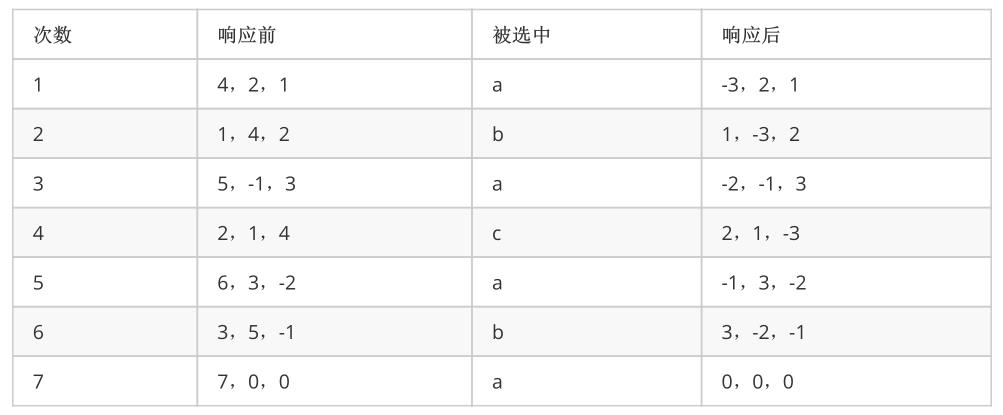
统计:a=4,b=2,c=1 且分布平滑均衡
package com.oldlu.balance;
import java.util.ArrayList;
public class WRR
class Node
int weight,currentWeight;
String name;
public Node(String name,int weight)
this.name = name;
this.weight = weight;
this.currentWeight = 0;
@Override
public String toString()
return String.valueOf(currentWeight);
//所有节点的列表
ArrayList<Node> list ;
//总权重
int total;
//初始化节点列表,格式:a#4,b#2,c#1
public WRR(String nodes)
String[] ns = nodes.split(",");
list = new ArrayList<>(ns.length);
for (String n : ns)
String[] n1 = n.split("#");
int weight = Integer.valueOf(n1[1]);
list.add(new Node(n1[0],weight));
total += weight;
//获取当前节点
Node getCurrent()
//执行前,current加权重
for (Node node : list)
node.currentWeight += node.weight;
//遍历,取权重最高的返回
Node current = list.get(0);
int i = 0;
for (Node node : list)
if (node.currentWeight > i)
i = node.currentWeight;
current = node;
return current;
//响应
void request()
//获取当前节点
Node node = this.getCurrent();
//第一列,执行前的current
System.out.print(list.toString()+"‐‐‐");
//第二列,选中的节点开始响应
System.out.print(node.name+"‐‐‐");
//响应后,current减掉total
node.currentWeight ‐= total;
//第三列,执行后的current
System.out.println(list);
public static void main(String[] args)
WRR wrr = new WRR("a#4,b#2,c#1");
//7次执行请求,看结果
for (int i = 0; i < 7; i++)
wrr.request();
5.3 结果分析
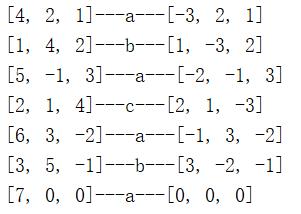
与上述对照,符合预期
6 加权随机(WR)
6.1 概述
WeightRandom,机器随机被筛选,但是做一组加权值,根据权值不同,选中的概率不同。在这个概念上,可以
认为随机是一种等权值的特殊情况。
6.2 实现
设计思路依然相同,根据权值大小,生成不同数量的节点,节点排队后,随机获取。这里的数据结构主要涉及到随机的读取,所以优选为数组。与随机相同的是,同样为数组随机筛选,不同在于,随机只是每台机器1个,加权后变为多个。
package com.oldlu.balance;
import java.util.ArrayList;
import java.util.Random;
public class WR
//所有节点的列表
ArrayList<String> list ;
//初始化节点列表
public WR(String nodes)
String[] ns = nodes.split(",");
list = new ArrayList<>();
for (String n : ns)
String[] n1 = n.split("#");
int weight = Integer.valueOf(n1[1]);
for (int i = 0; i < weight; i++) 以上是关于挖掘框架常用负载均衡算法实现的主要内容,如果未能解决你的问题,请参考以下文章