机器学习神器Scikit-learn保姆级入门教程
Posted 尤尔小屋的猫
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习神器Scikit-learn保姆级入门教程相关的知识,希望对你有一定的参考价值。
Scikit-learn保姆级入门教程
Scikit-learn是一个非常知名的Python机器学习库,它广泛地用于统计分析和机器学习建模等数据科学领域。
- 建模无敌:用户通过scikit-learn能够实现各种监督和非监督学习的模型
- 功能多样:同时使用sklearn还能够进行数据的预处理、特征工程、数据集切分、模型评估等工作
- 数据丰富:内置丰富的数据集,比如:泰坦尼克、鸢尾花等,数据不再愁啦
本篇文章通过简明快要的方式来介绍scikit-learn的使用,更多详细内容请参考官网:
- 内置数据集使用
- 数据集切分
- 数据归一化和标准化
- 类型编码
- 建模6部曲

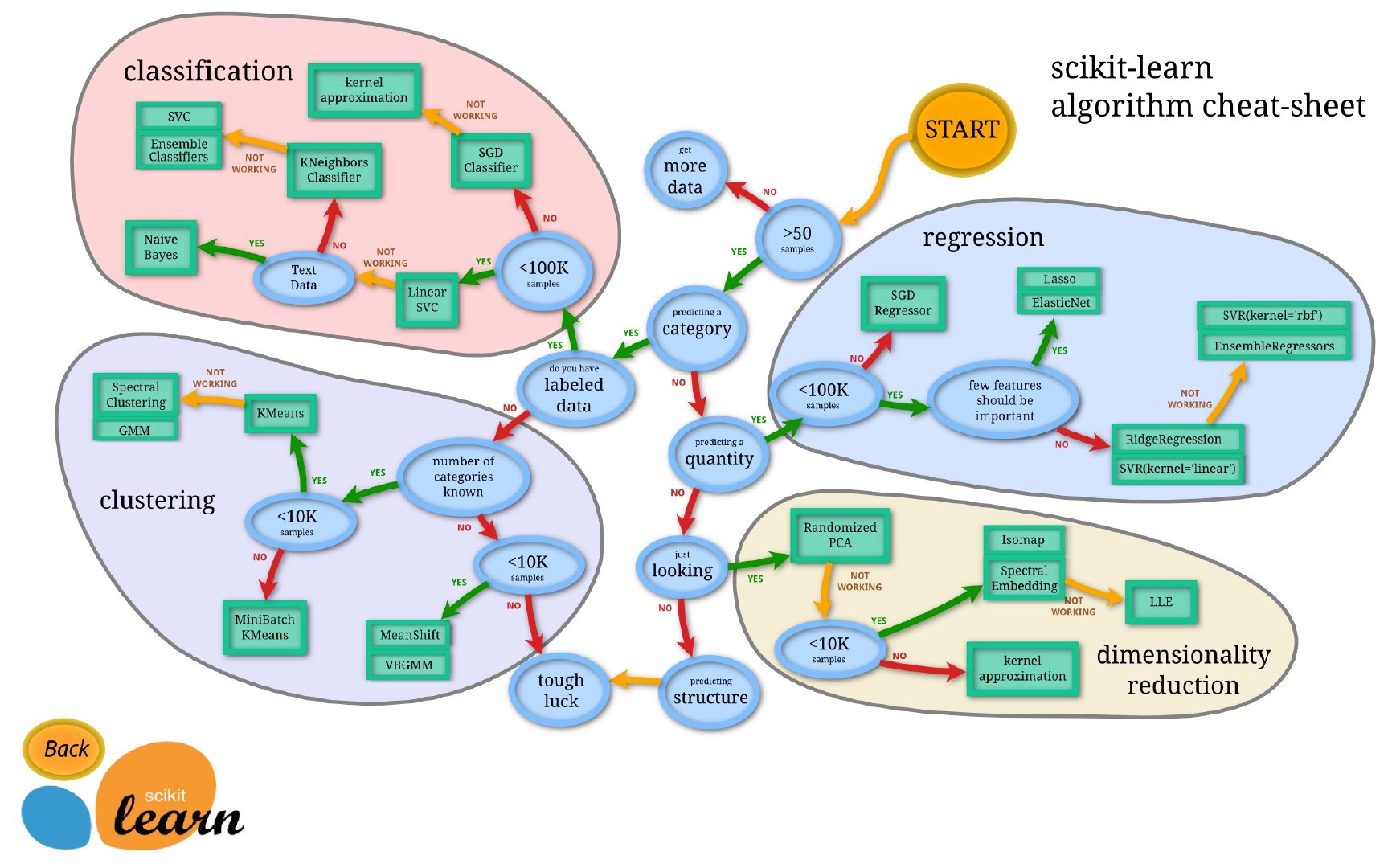
Scikit-learn使用神图
下面这张图是官网提供的,从样本量的大小开始,分为回归、分类、聚类、数据降维共4个方面总结了scikit-learn的使用:
https://scikit-learn.org/stable/tutorial/machine_learning_map/index.html

安装
关于安装scikit-learn,建议通过使用anaconda来进行安装,不用担心各种配置和环境问题。当然也可以直接pip来安装:
pip install scikit-learn
数据集生成
sklearn内置了一些优秀的数据集,比如:Iris数据、房价数据、泰坦尼克数据等。
import pandas as pd
import numpy as np
import sklearn
from sklearn import datasets # 导入数据集
分类数据-iris数据
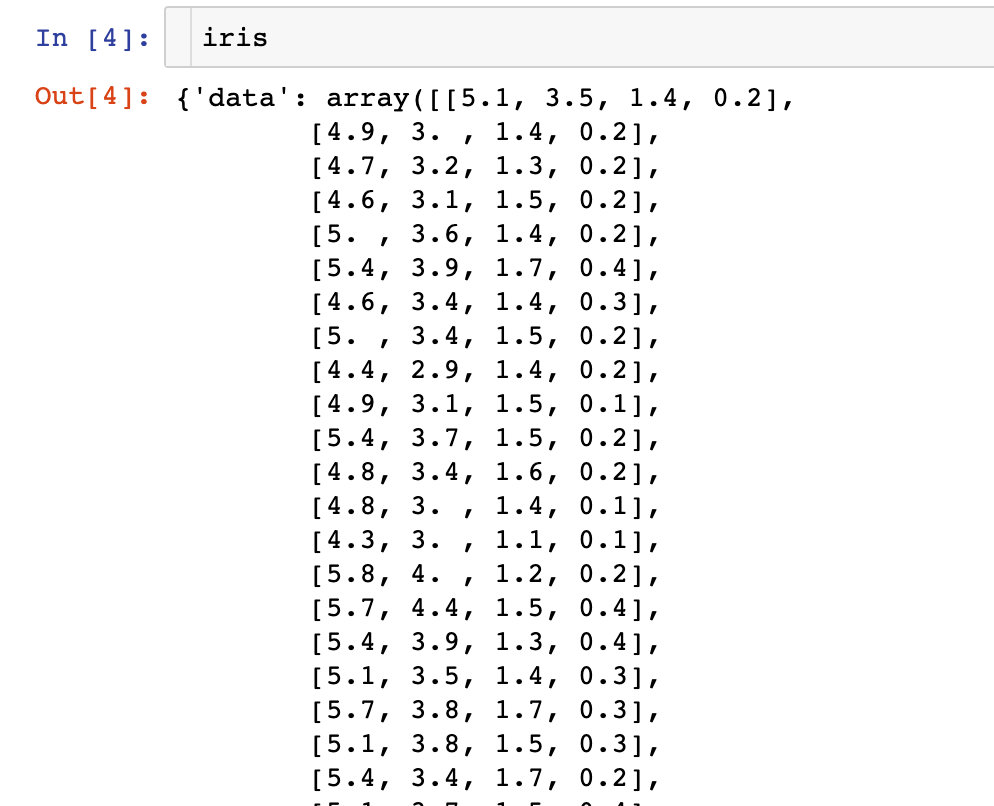
# iris数据
iris = datasets.load_iris()
type(iris)
sklearn.utils.Bunch
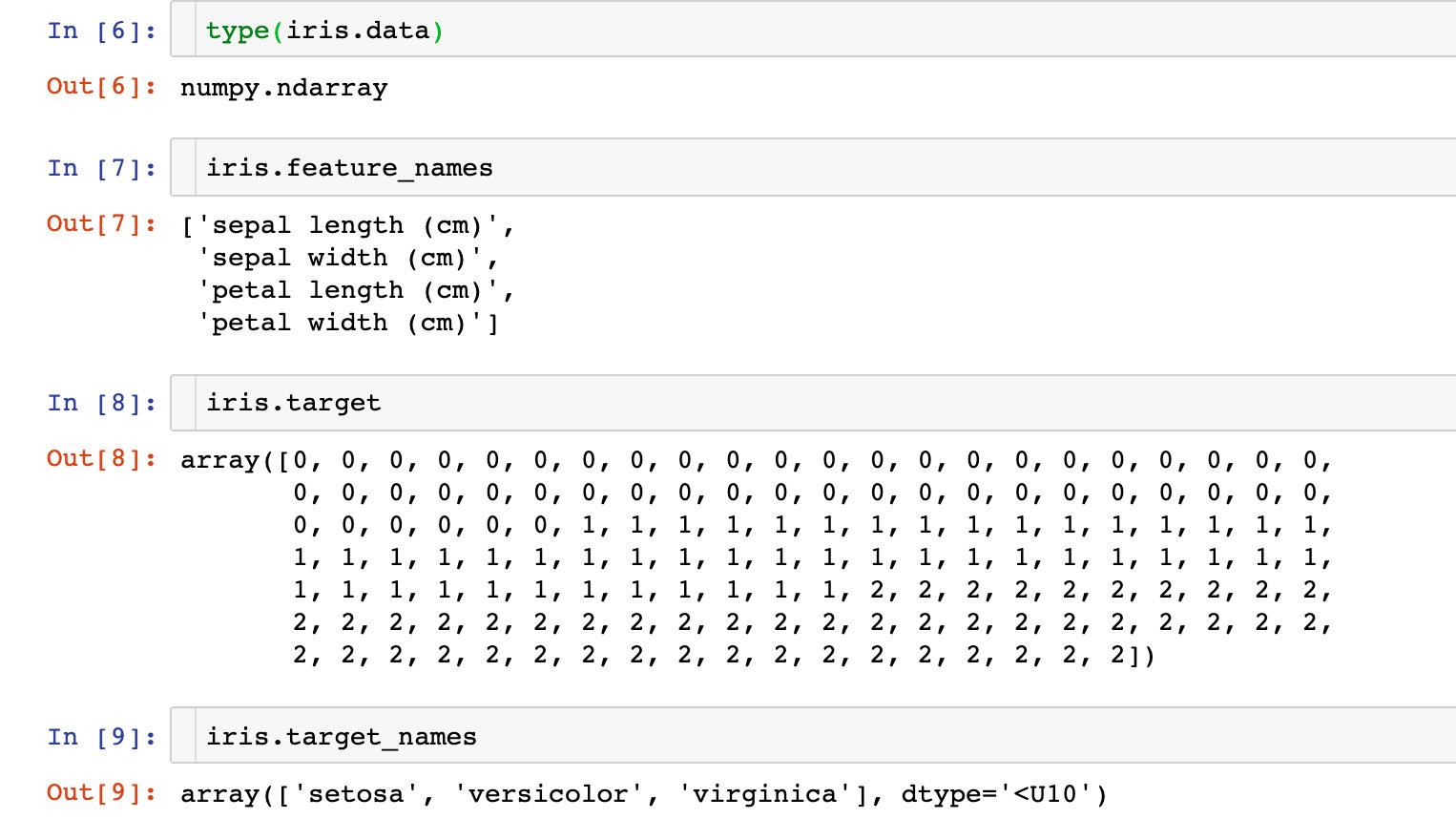
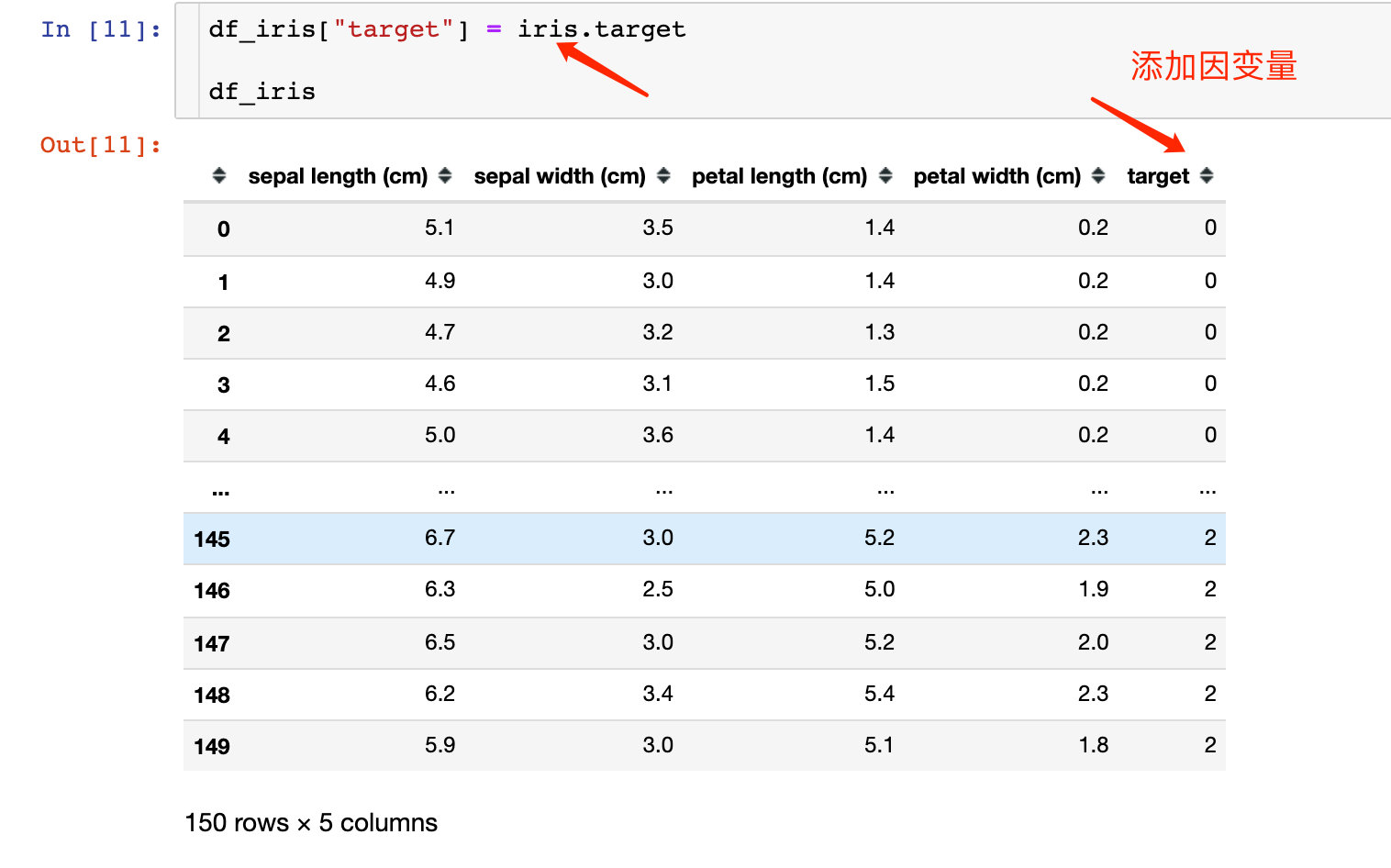
iris数据到底是什么样子?每个内置的数据都存在很多的信息


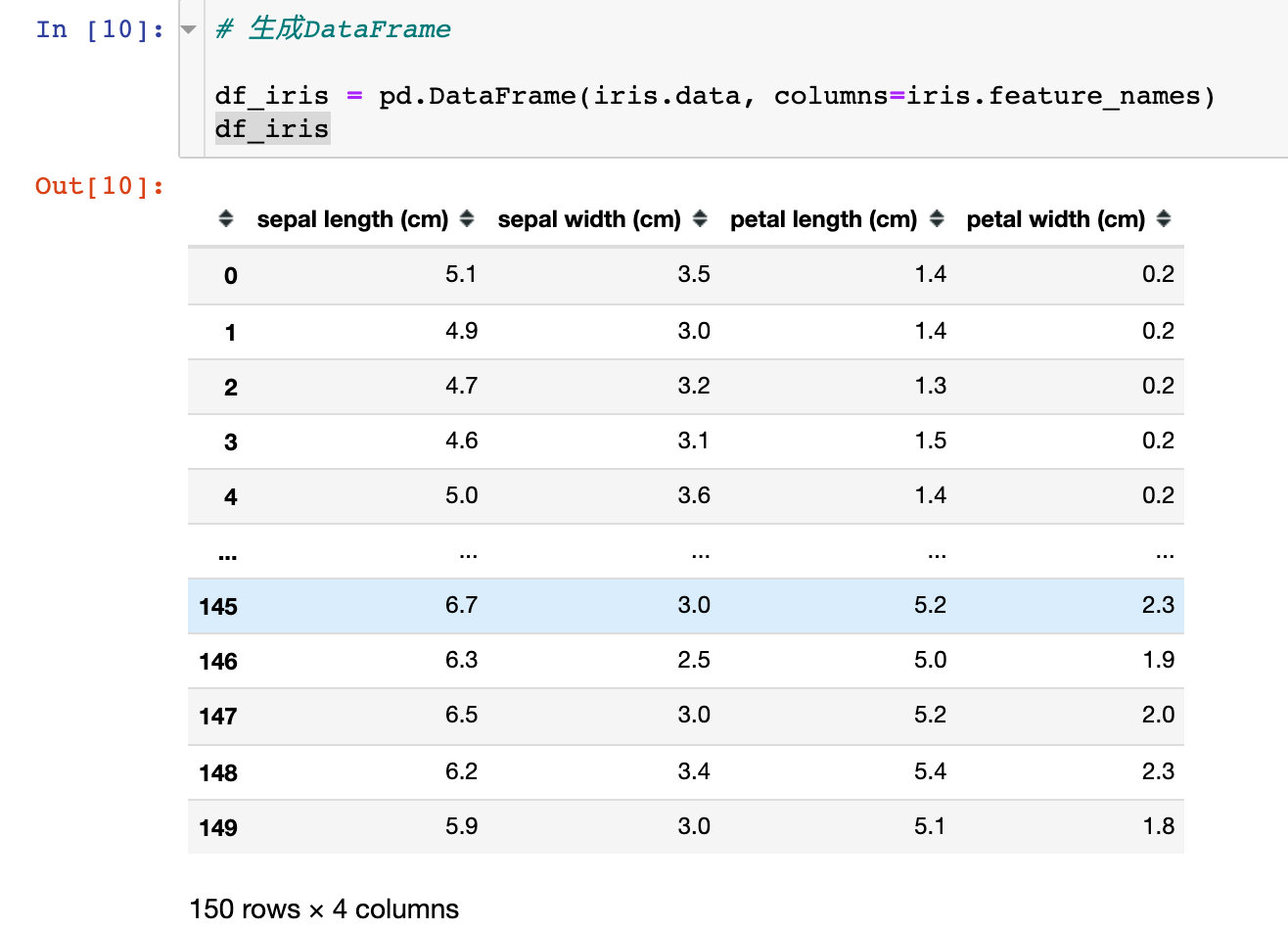
可以将上面的数据生成我们想看到的DataFrame,还可以添加因变量:
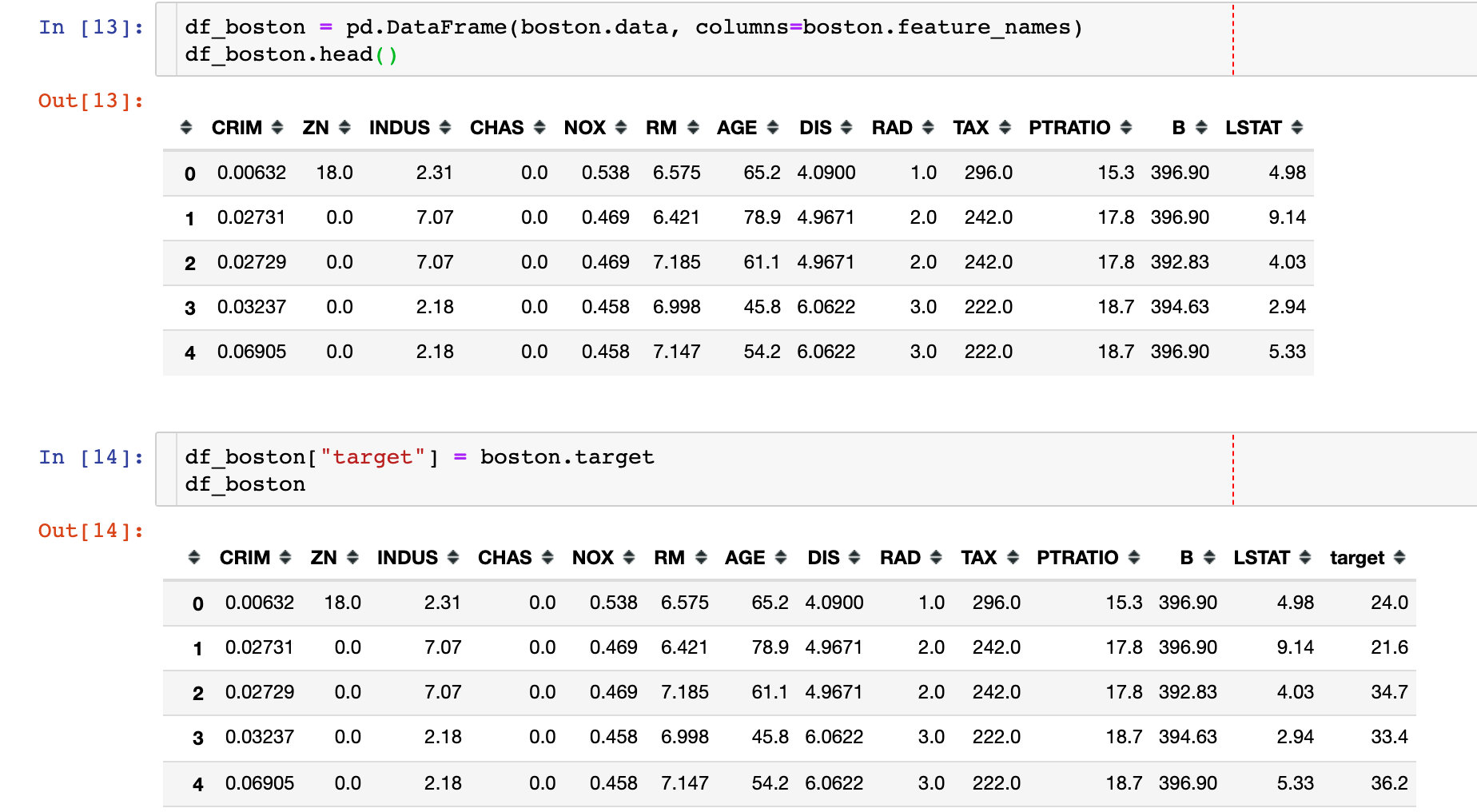
回归数据-波士顿房价
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-De0fUhf4-1643531202482)(https://tva1.sinaimg.cn/large/008i3skNly1gy91s2w95wj31ak0pqdlw.jpg)]

我们重点关注的属性:
- data
- target、target_names
- feature_names
- filename
同样可以生成DataFrame:
三种方式生成数据
方式1
#调用模块
from sklearn.datasets import load_iris
data = load_iris()
#导入数据和标签
data_X = data.data
data_y = data.target
方式2
from sklearn import datasets
loaded_data = datasets.load_iris() # 导入数据集的属性
#导入样本数据
data_X = loaded_data.data
# 导入标签
data_y = loaded_data.target
方式3
# 直接返回
data_X, data_y = load_iris(return_X_y=True)
数据集使用汇总
from sklearn import datasets # 导入库
boston = datasets.load_boston() # 导入波士顿房价数据
print(boston.keys()) # 查看键(属性) ['data','target','feature_names','DESCR', 'filename']
print(boston.data.shape,boston.target.shape) # 查看数据的形状
print(boston.feature_names) # 查看有哪些特征
print(boston.DESCR) # described 数据集描述信息
print(boston.filename) # 文件路径
数据切分
# 导入模块
from sklearn.model_selection import train_test_split
# 划分为训练集和测试集数据
X_train, X_test, y_train, y_test = train_test_split(
data_X,
data_y,
test_size=0.2,
random_state=111
)
# 150*0.8=120
len(X_train)
数据标准化和归一化
from sklearn.preprocessing import StandardScaler # 标准化
from sklearn.preprocessing import MinMaxScaler # 归一化
# 标准化
ss = StandardScaler()
X_scaled = ss.fit_transform(X_train) # 传入待标准化的数据
# 归一化
mm = MinMaxScaler()
X_scaled = mm.fit_transform(X_train)
类型编码
来自官网案例:https://scikit-learn.org/stable/modules/generated/sklearn.preprocessing.LabelEncoder.html
对数字编码

对字符串编码

建模案例
导入模块
from sklearn.neighbors import KNeighborsClassifier, NeighborhoodComponentsAnalysis # 模型
from sklearn.datasets import load_iris # 导入数据
from sklearn.model_selection import train_test_split # 切分数据
from sklearn.model_selection import GridSearchCV # 网格搜索
from sklearn.pipeline import Pipeline # 流水线管道操作
from sklearn.metrics import accuracy_score # 得分验证
模型实例化
# 模型实例化
knn = KNeighborsClassifier(n_neighbors=5)
训练模型
knn.fit(X_train, y_train)
KNeighborsClassifier()
测试集预测
y_pred = knn.predict(X_test)
y_pred # 基于模型的预测值
array([0, 0, 2, 2, 1, 0, 0, 2, 2, 1, 2, 0, 1, 2, 2, 0, 2, 1, 0, 2, 1, 2,
1, 1, 2, 0, 0, 2, 0, 2])
得分验证
模型得分验证的两种方式:
knn.score(X_test,y_test)
0.9333333333333333
accuracy_score(y_pred,y_test)
0.9333333333333333
网格搜索
如何搜索参数
from sklearn.model_selection import GridSearchCV
# 搜索的参数
knn_paras = "n_neighbors":[1,3,5,7]
# 默认的模型
knn_grid = KNeighborsClassifier()
# 网格搜索的实例化对象
grid_search = GridSearchCV(
knn_grid,
knn_paras,
cv=10 # 10折交叉验证
)
grid_search.fit(X_train, y_train)
GridSearchCV(cv=10, estimator=KNeighborsClassifier(),
param_grid='n_neighbors': [1, 3, 5, 7])
# 通过搜索找到的最好参数值
grid_search.best_estimator_
KNeighborsClassifier(n_neighbors=7)
grid_search.best_params_
'n_neighbors': 7
grid_search.best_score_
0.975
基于搜索结果建模
knn1 = KNeighborsClassifier(n_neighbors=7)
knn1.fit(X_train, y_train)
KNeighborsClassifier(n_neighbors=7)
通过下面的结果可以看到:网格搜索之后的建模效果是优于未使用网格搜索的模型
y_pred_1 = knn1.predict(X_test)
knn1.score(X_test,y_test)
1.0
accuracy_score(y_pred_1,y_test)
1.0
以上是关于机器学习神器Scikit-learn保姆级入门教程的主要内容,如果未能解决你的问题,请参考以下文章